华为ctf2020题目复现
1.首先通过查看官方的WP,得知程序中实现了一个brainfuck语言的解释器。但是在自己去分析的时候就怎么也看不出来哪里实现了解释器,更不用说提取出其中的bf程序了。
2.在热心师兄的帮助下,找到了程序的分析方法。
3.首先程序的解释器:https://github.com/HexHive/printbf/blob/master/src/pbf_pre.c
可以看到程序中实现的解释器和这个github上的解释器大致一样


然后在这个仓库上还有另一个py文件:https://github.com/HexHive/printbf/blob/master/src/toker.py
通过运行这个脚本可以得知,这个py文件的作用就是把brainfuck源码转换成解释器可以用的opcode。
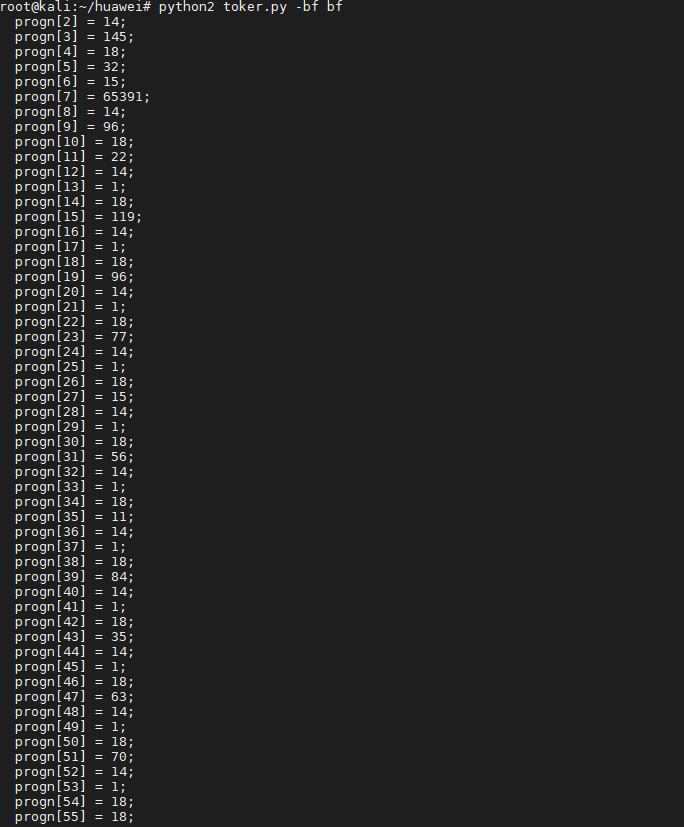
其中转换后的bf代码中以元组的形式储存转换前的bf代码。元组的第一个值代表转换前符号,第二个值代表出现的次数。
3.那这样就有了分析的思路。
在main函数中


首先setup()函数初始化了bf解释器,然后在progn段存储转换后的bf代码,最后在loop()函数中执行。
4.官方WP:https://www.xctf.org.cn/library/details/55599c9c17ea0e8ca0b094adbe075a03a7321599/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号