

【大数据】HBase集群部署
HBase集群部署
快速部署摘要
静态IP
位置
vi /etc/sysconfig/network-scripts/ifcfg-ens33
内容
BOOTPROTO=static
ONBOOT=yes
DNS1=192.168.56.1
GATEWAY=192.168.56.1
IPADDR=192.168.56.101
BOOTPROTO:IP获取方式,ONBOOT:是否启用,DNS1:网关IP,GATEWAY:网关IP,IPADDR:本机IP
重启服务
service network restart
查看IP
ip addr
防火墙
临时关闭
systemctl stop firewalld
查看状态
systemctl status firewalld
永久关闭
systemctl disable firewalld
查看状态
systemctl list-unit-files | grep firewalld
一般使用临时关闭+永久关闭
主机名
查看
hostname
临时修改
hostname slave0
永久修改
vi /etc/hostname
/etc/hostname中单存一个主机名,一般使用临时关闭+永久关闭
域名解析
文件
vi /etc/hosts
追加
192.168.25.10 slave0
192.168.25.11 slave1
192.168.25.12 slave2
格式:IP(空格)域名
免密登录
生成秘钥
ssh-keygen -t rsa
试验(配置免密登录自己)
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
分发到要免密登录的虚拟机上
scp ~/.ssh/id_rsa.pub slave1:~
scp ~/.ssh/id_rsa.pub slave2:~
要免密登录的虚拟机将公钥追加到authorized_keys 文件中
mkdir .ssh
cd .ssh
touch authorized_keys
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
是生成秘钥的主机能免密登录到接收公钥的主机上
SSH免DNS验证
配置文件
vi /etc/ssh/sshd_config
将UseDNS设置为no,并取消注释
重启SSH服务
service sshd restart
时间同步
安装ntpdate
yum install -y ntpdate
同步时间
ntpdate -u ntp.aliyun.com
设置定时任务
查看路径
which ntpdate
文件
vi /etc/crontab
定时任务配置,10分钟同步一次(追加)
*/10 * * * * root /usr/sbin/ntpdate -u ntp.aliyun.com
禁用邮件提醒
文件
vi /etc/profile
配置(追加)
unset MAILCHECK
更新
source /etc/profile
不用./直接执行程序
文件
vi /etc/profile
配置(追加)
## 文件可以直接执行
export PATH=.:$PATH
更新
source /etc/profile
Java
创建目录/opt/software和/opt/module
mkdir -p /opt/software
mkdir -p /opt/module
上传安装包到/opt/software
解压
tar -zxvf jdk-7u79-linux-x64.tar.gz -C /opt/module/
环境变量/etc/profile(追加)
## JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.7.0_79
export PATH=$PATH:$JAVA_HOME/bin
更新
source /etc/profile
验证
java -version
Hadoop
规划
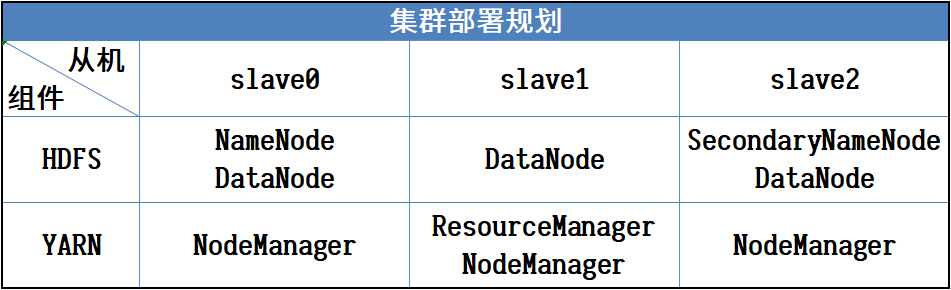
上传安装包到/opt/software
解压
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
环境变量/etc/profile(追加)
## HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
更新
source /etc/profile
配置文件
配置目录:安装目录/etc/hadoop/
hadoop-env.sh(末尾插入)
yarn-env.sh(前面插入)
mapred-env.sh(前面插入)
export JAVA_HOME=/opt/module/jdk1.7.0_79
core-site.xml
<configuration>
<!-- 指定HDFS中NameNode进程所在的节点信息 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://slave0:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- 指定HDFS文件副本数量(集群中有3个从节点,默认为3) -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定HDFS中SecondaryNameNode进程所在的节点信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:50090</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- 设置Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager进程所在的节点信息 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
</configuration>
mapred-site.xml
复制
cat mapred-site.xml.template >> mapred-site.xml
配置
<configuration>
<!-- 指定MapReduce运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
slaves 文件(添加集群的所有主机的域名)
slave0
slave1
slave2
分发运行
分发
scp -rq /opt/module/hadoop-2.7.2/ slave1:/opt/module/
scp -rq /opt/module/hadoop-2.7.2/ slave2:/opt/module/
格式化(第一次)
bin/hdfs namenode -format
启动
slave0 : HDFS
sbin/start-dfs.sh
slave1 : YARN
sbin/start-yarn.sh
停止
slave1 : YARN
sbin/stop-yarn.sh
slave0 : HDFS
sbin/stop-dfs.sh
ZooKeeper
上传安装包到/opt/software
解压
tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
环境变量/etc/profile(追加)
## ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
更新
source /etc/profile
创建文件夹
在/opt/module/zookeeper-3.4.10/目录下创建data/zkData目录
mkdir -p data/zkData
配置文件
在安装目录/conf文件夹下
复制模板文件
cat zoo_sample.cfg >> zoo.cfg
zoo.cfg
修改
dataDir=/opt/module/zookeeper-3.4.10/data/zkData
在末尾追加
## 集群
server.1=slave0:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
在/opt/module/zookeeper-3.4.10/data/zkData/目录下创建myid文件
cd /opt/module/zookeeper-3.4.10/data/zkData/
touch myid
分发运行
分发时修改/opt/module/zookeeper-3.4.10/data/zkData/目录下的myid文件,就一个编号,分别与zoo.cfg中追加的内容对应,比如:slave0的myid内容就是1,slave1的myid内容就是2
vi /opt/module/zookeeper-3.4.10/data/zkData/myid
分发
scp -rq /opt/module/zookeeper-3.4.10/ slave1:/opt/module/
scp -rq /opt/module/zookeeper-3.4.10/ slave2:/opt/module/
运行
分别在三台虚拟机上ZooKeeper的安装目录里执行
bin/zkServer.sh start
停止
分别在三台虚拟机上ZooKeeper的安装目录里执行
bin/zkServer.sh stop
HBase
上传安装包到/opt/software
解压
tar -zvxf hbase-1.3.3-bin.tar.gz -C /opt/module/
环境变量/etc/profile(追加)
## HBASE_HOME
export HBASE_HOME=/opt/module/hbase-1.3.3
export PATH=$PATH:$HBASE_HOME/bin
更新
source /etc/profile
配置
跳转到/opt/module/hbase-1.3.3/conf/目录
cd /opt/module/hbase-1.3.3/conf/
hbase-env.sh(前面插入)
## JDK路径
export JAVA_HOME=/opt/module/jdk1.7.0_79
## 设置使用外置的ZooKeeper
export HBASE_MANAGES_ZK=false
hbase-site.xml
<configuration>
<!-- 设置最大时钟偏移,以降低对时间同步的要求 -->
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<!-- 指定HDFS实例地址 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://slave0:9000/hbase</value>
</property>
<!-- 启用分布式集群 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- ZooKeeper配置:设置ZooKeeper集群节点 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>slave0,slave1,slave2</value>
</property>
<!-- ZooKeeper配置:设置ZooKeeper数据目录 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4.10/data/zkData</value>
</property>
</configuration>
regionservers 文件(添加集群的所有主机的域名)
slave0
slave1
slave2
复制Hadoop的core-site.xml和hdfs-site.xml到HBase的conf目录下
cp /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml /opt/module/hbase-1.3.3/conf/
cp /opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml /opt/module/hbase-1.3.3/conf/
分发和运行
分发
scp -rq /opt/module/hbase-1.3.3/ slave1:/opt/module/
scp -rq /opt/module/hbase-1.3.3/ slave2:/opt/module/
运行(在NameNode节点主机上,slave0,HBase安装目录下)
bin/start-hbase.sh
停止
bin/stop-hbase.sh
虚拟机软件安装
分别演示VirtualBox 6.1.30和VMware Workstation Pro 15.5.6的下载和安装。
VirtualBox虚拟机
下载
- 用浏览器打开 virtualbox.org 网站
点击“Downloads”
- 往下翻,找到“VirtualBox older builds”
点击“VirtualBox older builds”
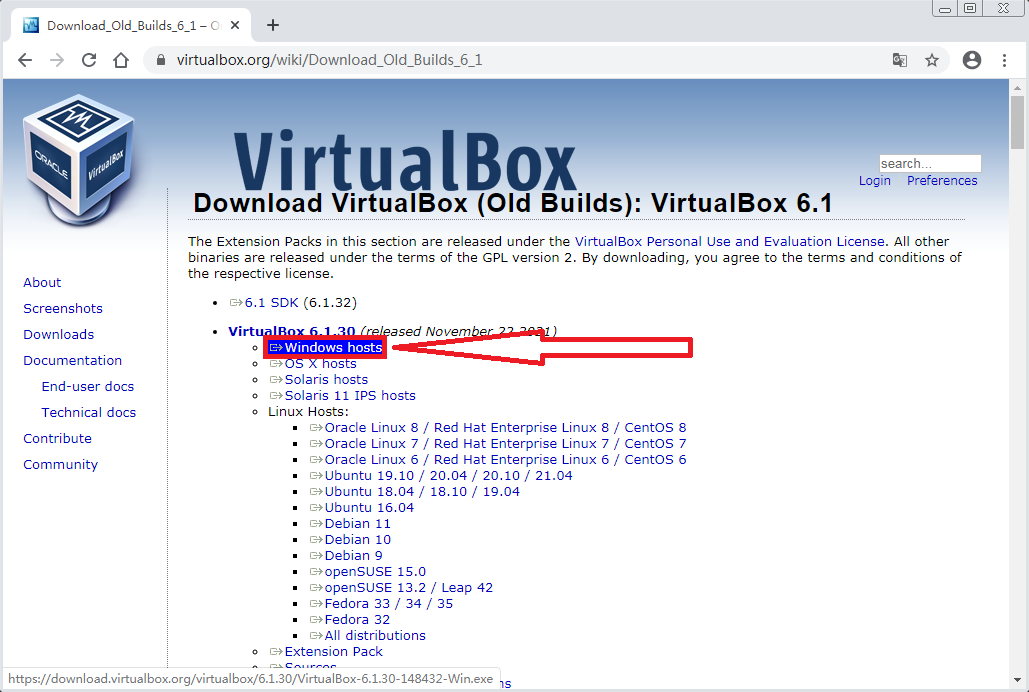
- 找到“VirtualBox 6.1”,点击“VirtualBox 6.1”
- 找到“VirtualBox 6.1.30”下的“Windows hosts”,点击“Windows hosts”以下载VirtualBox 6.1.30版本的安装包
安装
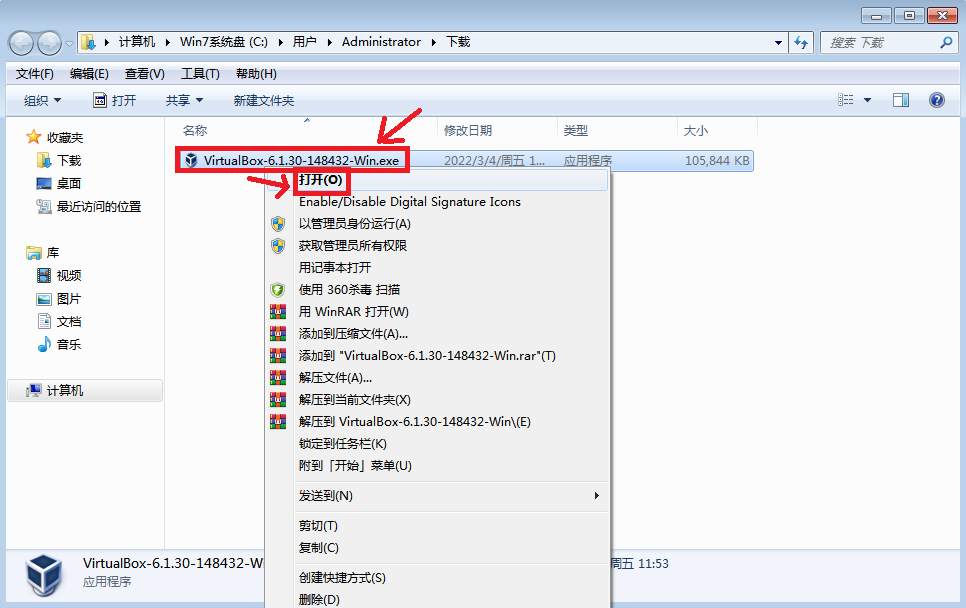
- 下载之后鼠标右键,打开安装程序
- 下一步
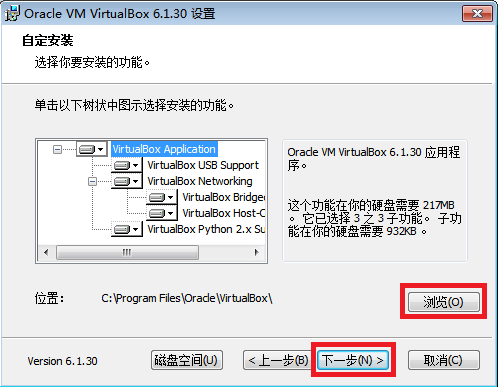
- 可以点击“浏览”选择一个合适的安装位置,这边保持默认位置,然后点“下一步”
- 前面3个选项按需勾选,“注册文件关联”建议勾选,下一步
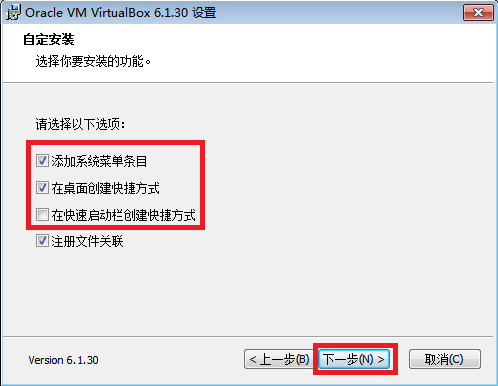
- 安装时会短暂断网,准备好之后点击“是”
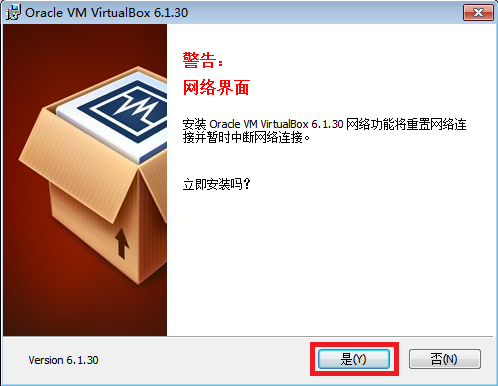
- 点“安装”,开始安装VirtualBox
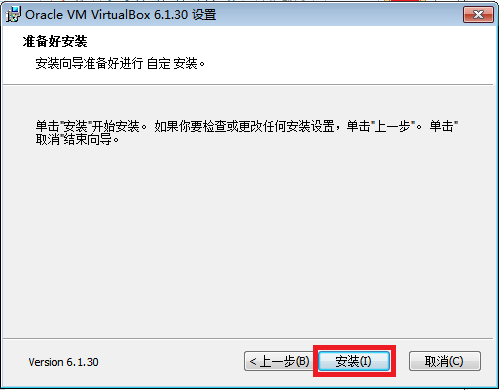
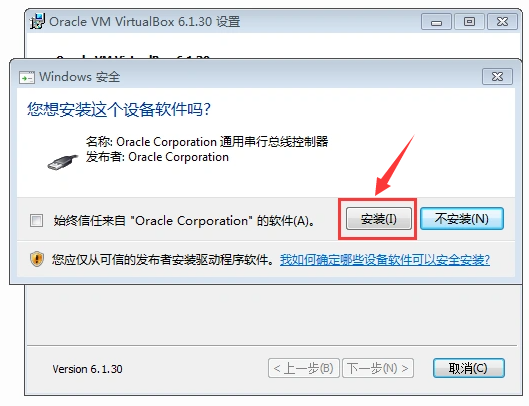
- 中间会弹出三个Windows安全提示,都点击“安装”按钮
- 点击完成,完成VirtualBox6.1.30的安装
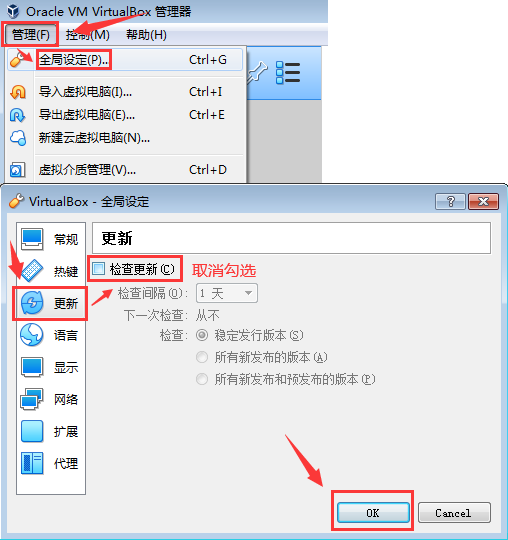
- 更新提示不必理会,在“管理”→“全局设定”→“更新”里取消勾选“检查更新”即可
VMware虚拟机
下载
- 用浏览器打开 vmware.com 网站
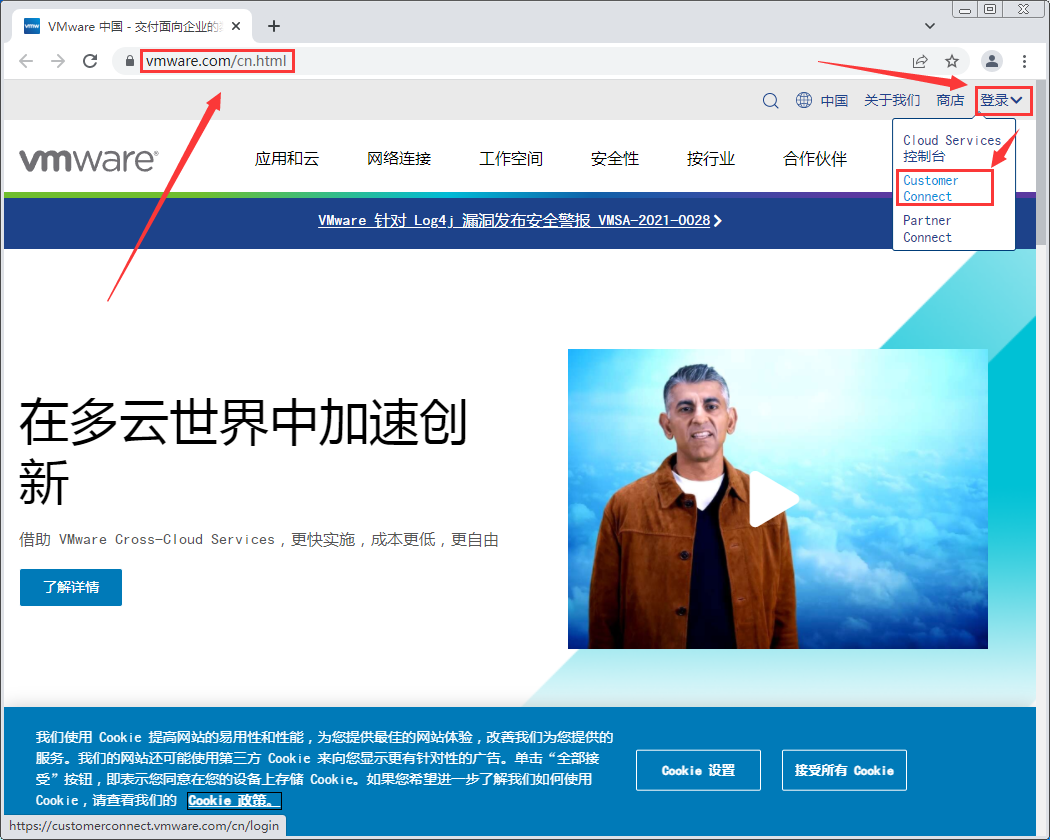
点击“登录”→“Customer Connect”
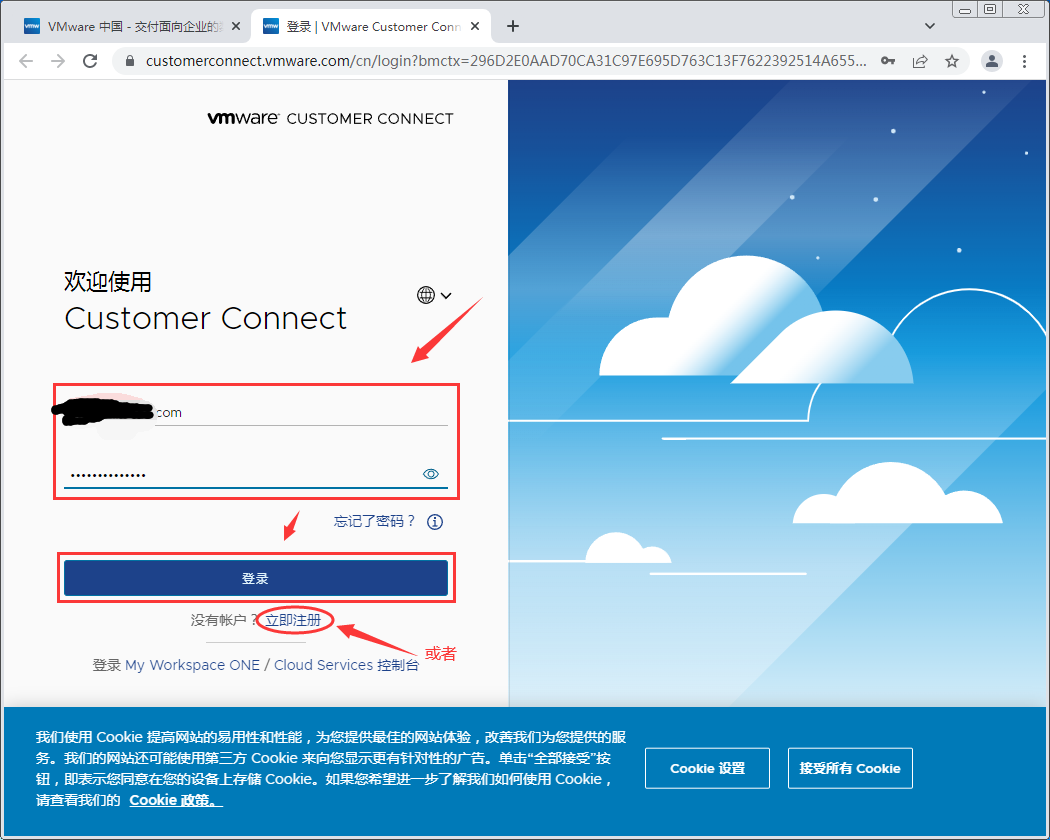
- 登录上你自己的VMware账号,如果没有可以注册一个,或者尝试直接进入网址:
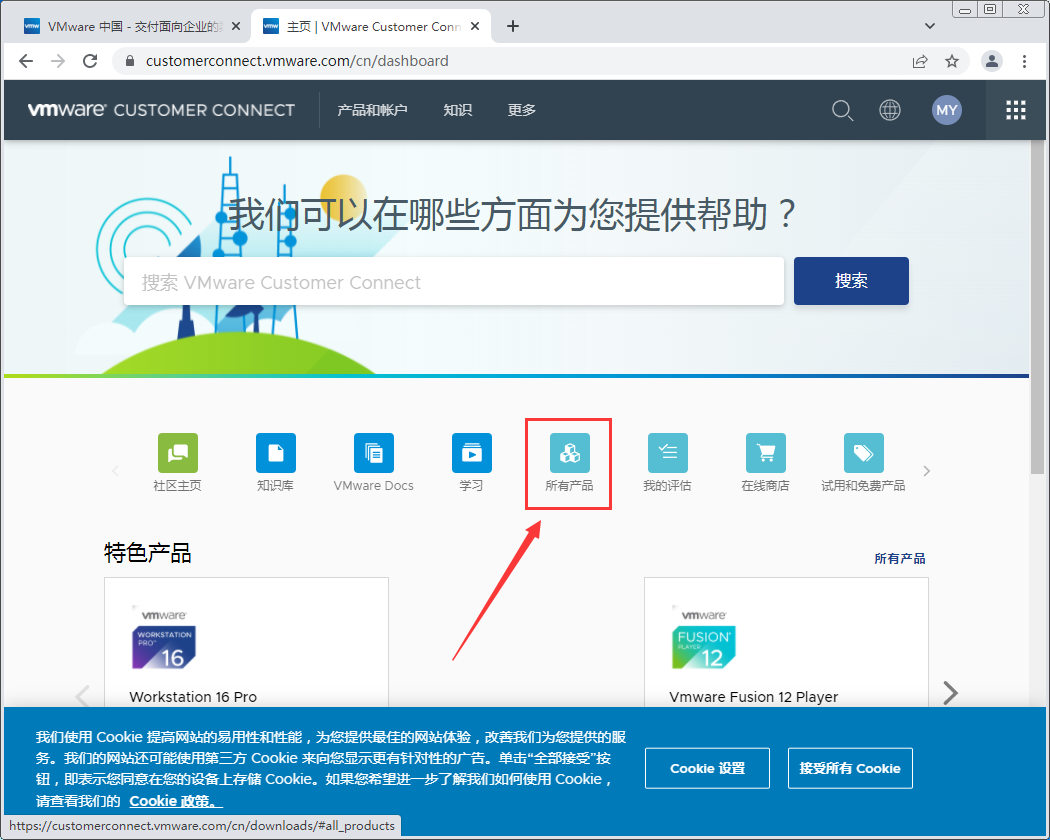
- 来到“CUSTOMER CONNECT 主页”后点击所有产品
- 翻到下面,找到“VMware Workstation Pro”,点击“查看下载组件”
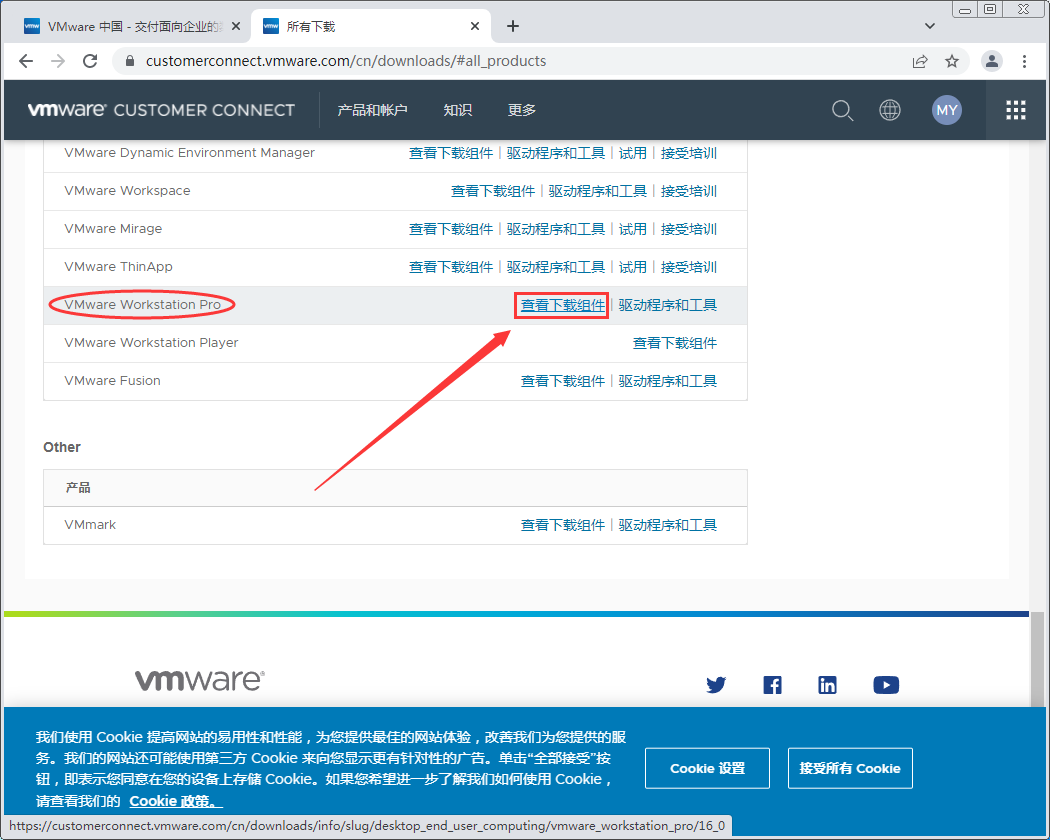
- 选择版本选择为15.0的版本,在产品中找到Windows版的VMware Workstation Pro,点击右边的“转至下载”
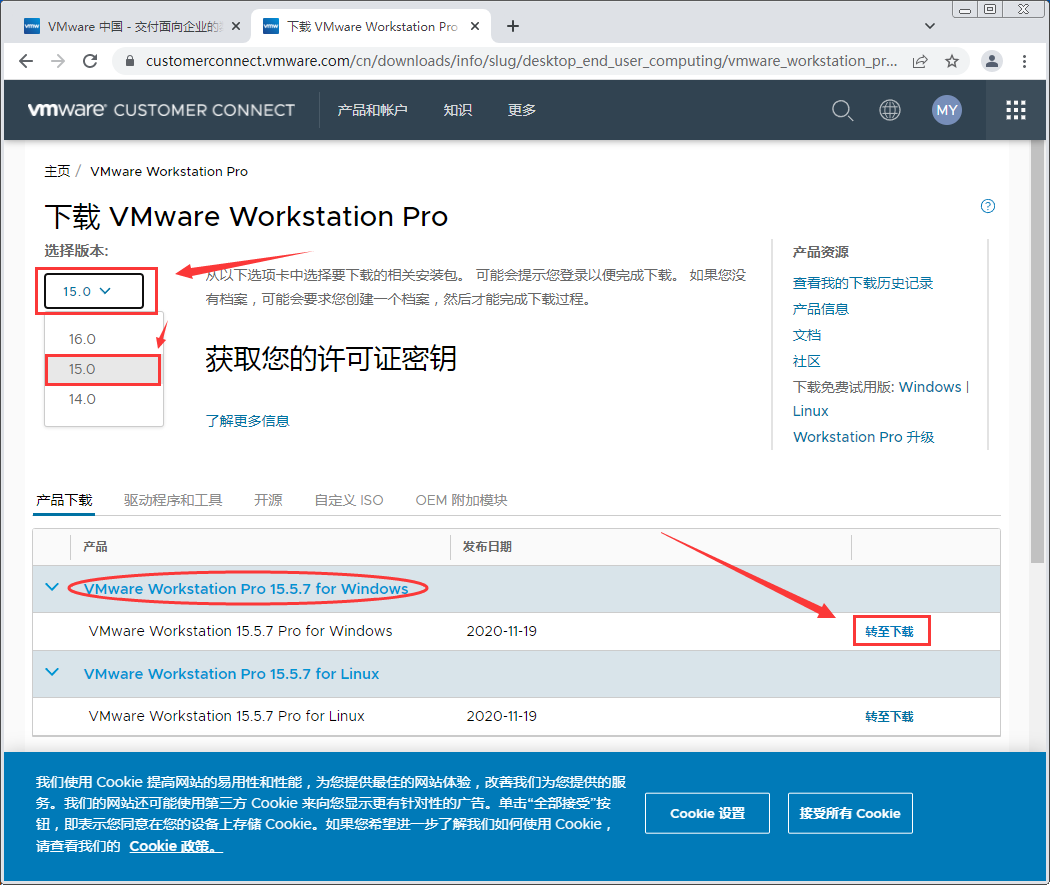
6.选择15.5.6版本,在下面文件点右边点“立即下载”
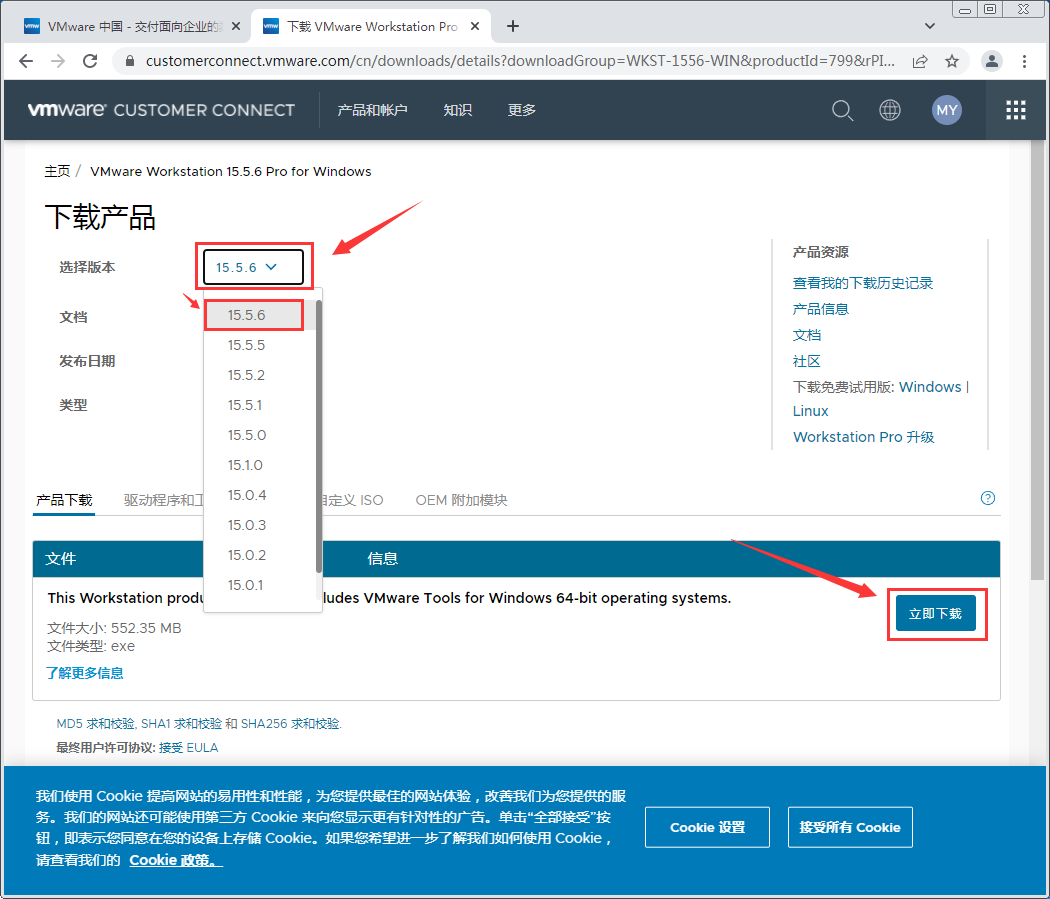
7.勾选“我同意最终用户许可协议中所列的各项条款和条件”后点击“接受”以下载VMware Workstation Pro 15.5.6的安装包
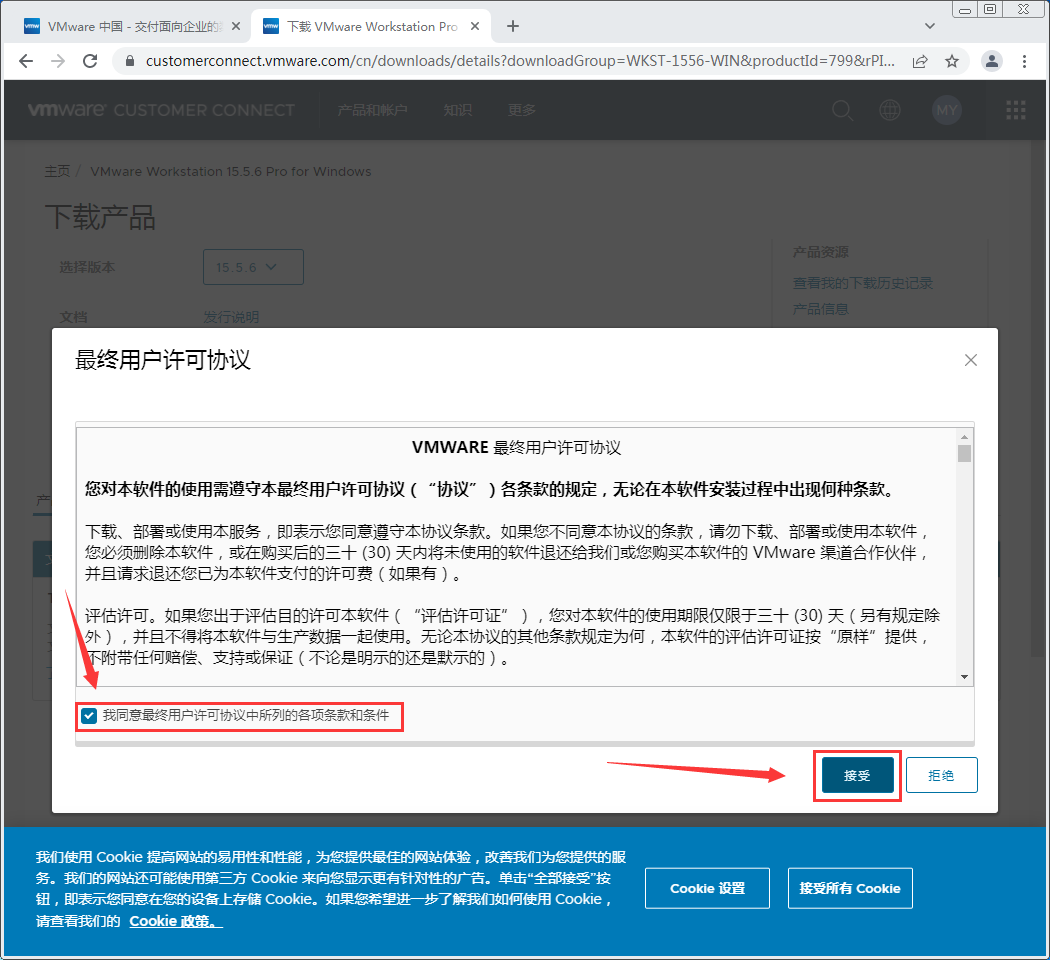
安装
- 下载完成后得到一个文件,鼠标右键→打开
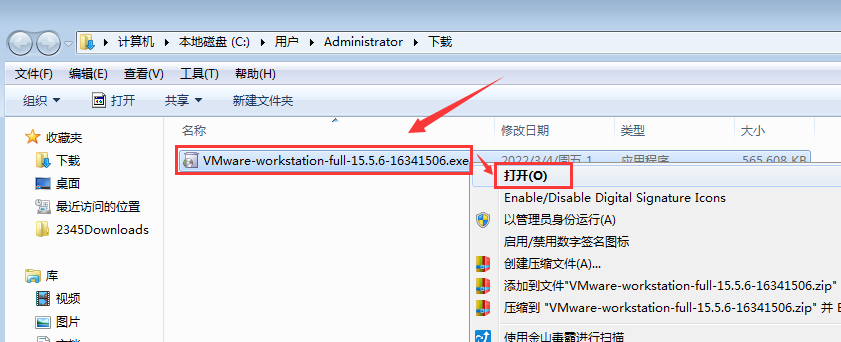
- 点击“下一步”
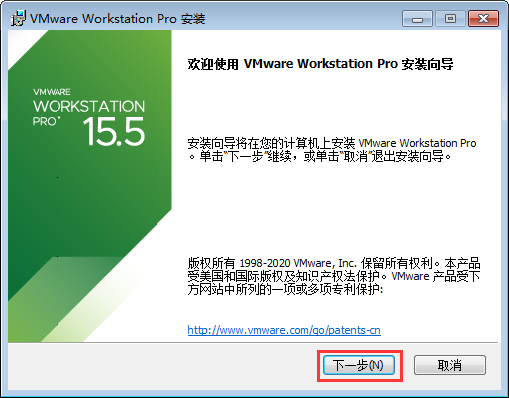
- 勾选“我接受许可协议中的条款(A)”,点击“下一步”
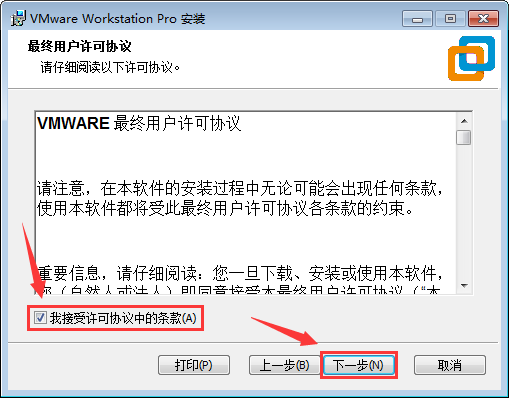
- 可以点击上面的“更改...”选择一个合适的安装位置,这边保持默认位置,然后点“下一步”
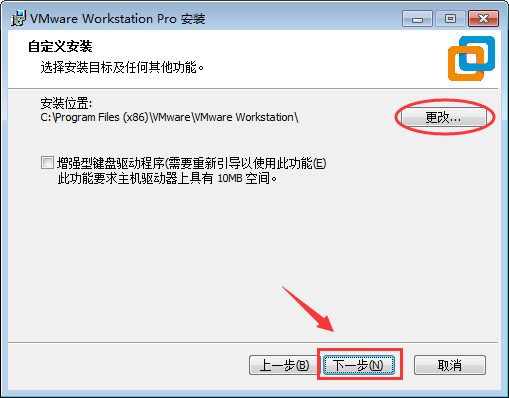
- 可以按需勾选上面的两个选项,这边全部取消掉,点击“下一步”
- 可以按需勾选上面的两个选项,这边保持默认,点击“下一步”
- 点击安装以开始安装VMware Workstation Pro 15.5.6
- 安装完成,点击“完成”退出安装程序
注册
- 打开VMware Workstation Pro,点击“帮助”→“输入许可证密钥”
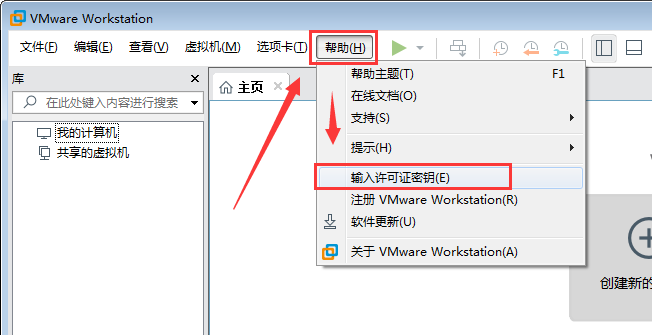
- 搜索“VMwareWorkstation 15 Pro 密钥”找一些密钥,或者自己购买,这边提供互联网上找到的几个密钥:
VMware Workstation 15 Pro 的密钥:
UG5J2-0ME12-M89WY-NPWXX-WQH88
GA590-86Y05-4806Y-X4PEE-ZV8E0
YA18K-0WY8P-H85DY-L4NZG-X7RAD
UA5DR-2ZD4H-089FY-6YQ5T-YPRX6
B806Y-86Y05-GA590-X4PEE-ZV8E0
ZF582-0NW5N-H8D2P-0XZEE-Z22VA
YG5H2-ANZ0H-M8ERY-TXZZZ-YKRV8
UG5J2-0ME12-M89WY-NPWXX-WQH88
UA5DR-2ZD4H-089FY-6YQ5T-YPRX6
GA590-86Y05-4806Y-X4PEE-ZV8E0
ZF582-0NW5N-H8D2P-0XZEE-Z22VA
YA18K-0WY8P-H85DY-L4NZG-X7RAD
不保证每个密匙都有效,每个密钥都有时效和次数限制。
把得到的密钥输入到“许可证密钥”输入框中,点击“确定”

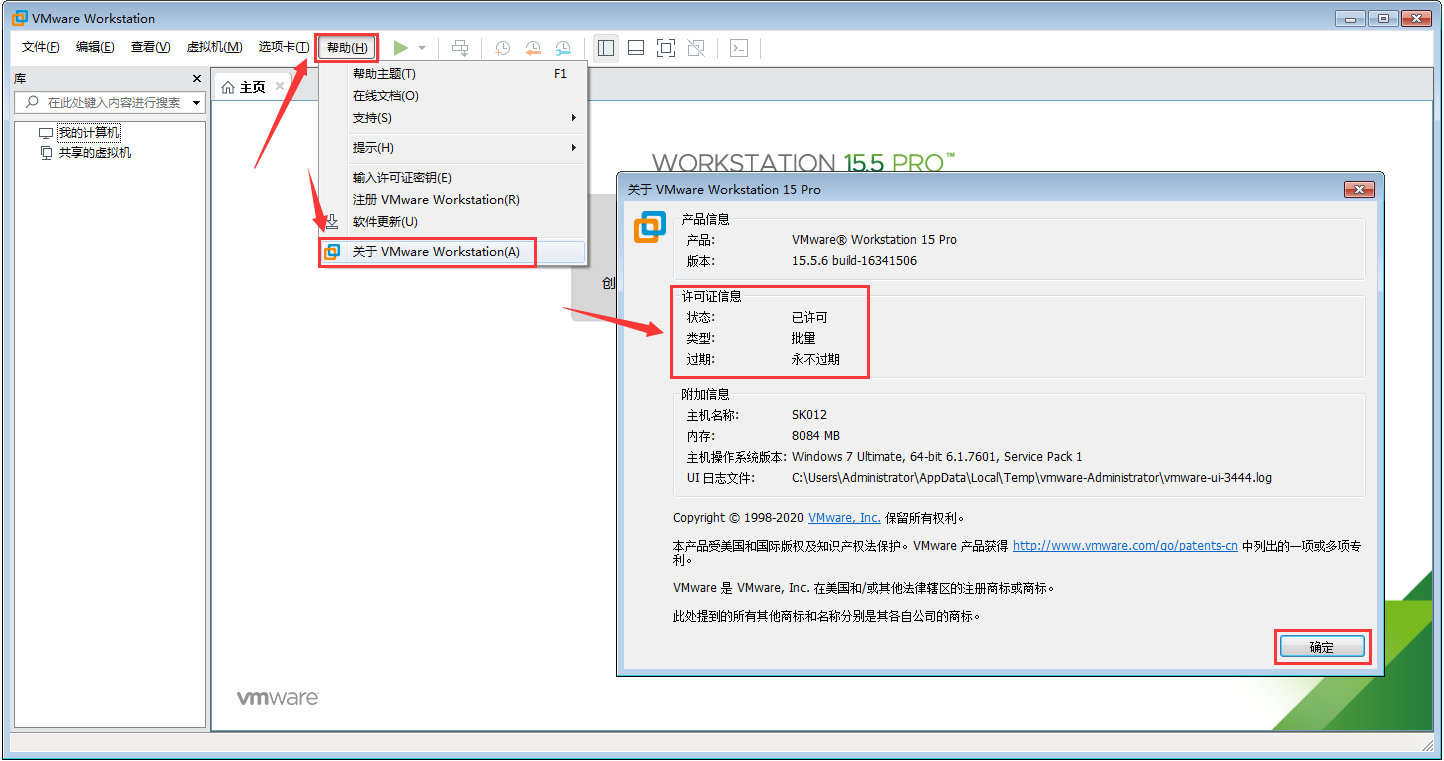
- 激活后在“帮助”→“关于WMware Workstation(A)”打开的窗口中可以看到相关的许可证信息
安装Linux集群
使用CentOS7 - 1810系统,3台虚拟机组成集群。
CentOS7 - 1810下载
- 打开网站:centos.org
点击“Download”按钮进入下载页面
- 往下翻,找到并点击“Older Versions”下面的“then click here”标签
- 往下翻,找到“Archived Versions”下的“Base Distribution”面板,找到“7 (1810)”点击右边的“Tree”标签
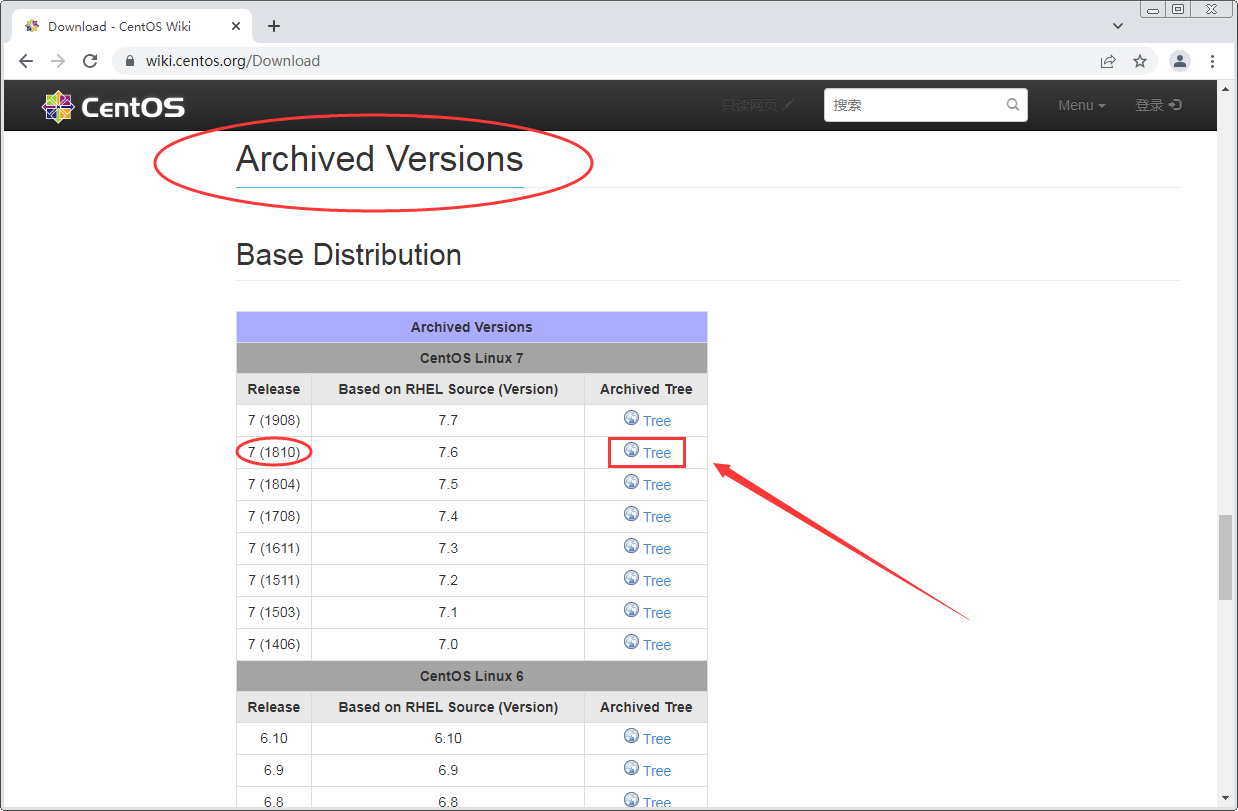
- 往下翻,找到“isos”文件夹,点进去
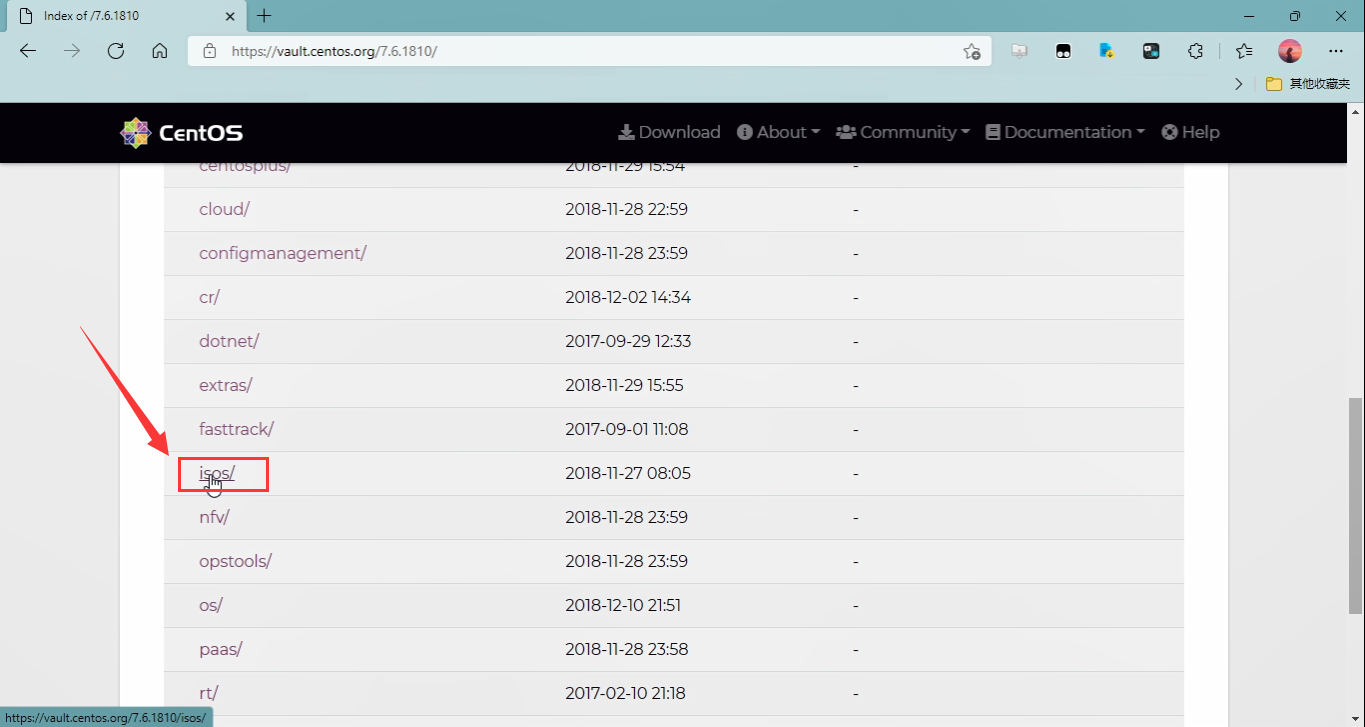
- 点击“x86_64”文件夹
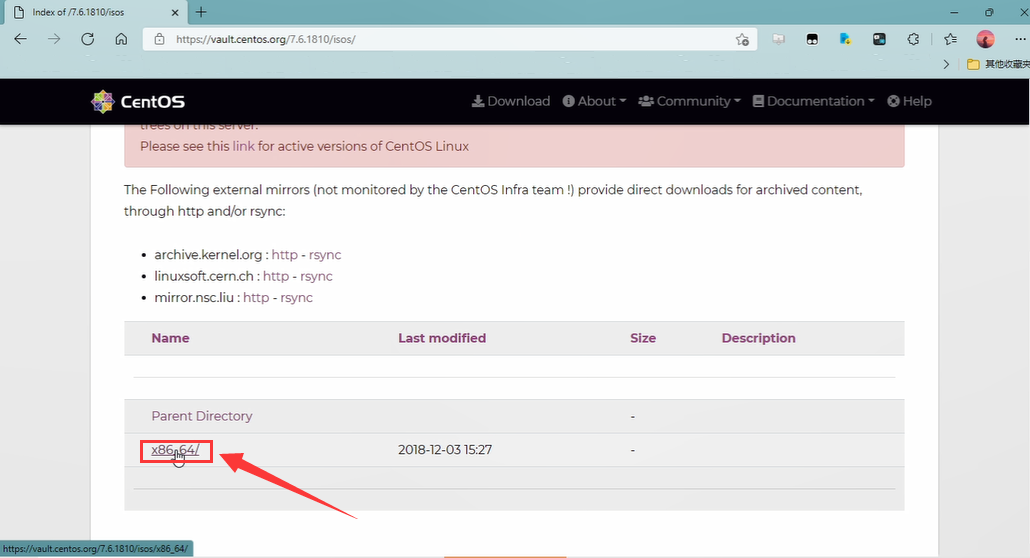
- 我们选择下载“CentOS-7-x86_64-Minimal-1810.iso”文件
- 下载完成后,我们得到这样一个文件
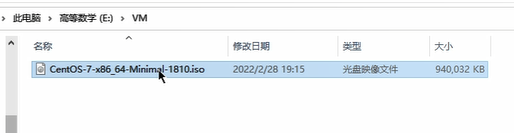
- (可选)为了确保下载的时候没出错,可以用SHA256工具来计算一下这个文件的SHA256值,与官方给出的
38d5d51d9d100fd73df031ffd6bd8b1297ce24660dc8c13a3b8b4534a4bd291c对比一下看是否一致,若不一致,则可能下载过程中出现了错误,需要重新下载
VirtualBox虚拟机安装Linux集群
- 打开VirtualBox,点击主页上的“新建”
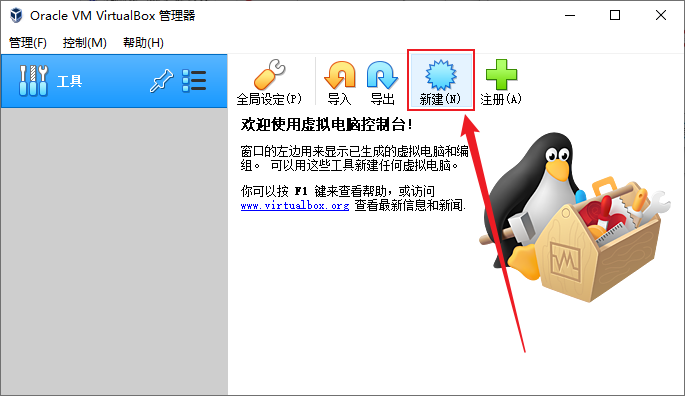
- 给虚拟机起个名字,方便以后操作,“slave0”(slave:从机),文件夹是存放虚拟机的位置,尽量选容量大点的磁盘,类型选择“Linux”,版本选择“Other Linux (64-bit)”或者“RedHat (64-bit)”,下一步
- 设置虚拟机运行内存大小,根据自己的电脑内存大小和同时需要启动的虚拟机数量来决定,可以使用推荐的512M,但最好使用2G及以上,后面不够用了也可以调整,这边使用2G,下一步
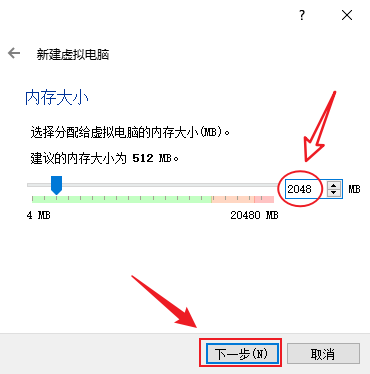
- 选择“现在创建虚拟硬盘”,点击“创建”
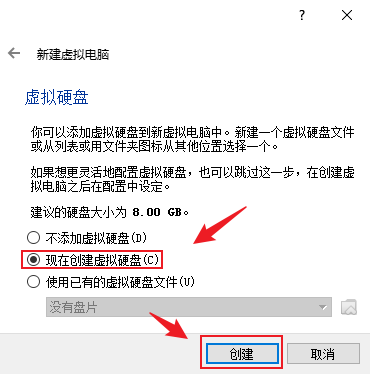
- 保持默认“VDI(VirtualBox 磁盘映像)”,下一步
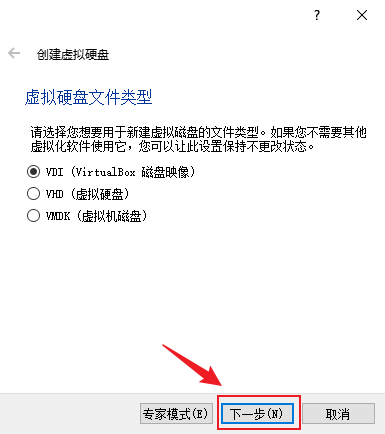
- 虚拟硬盘分配方式建议使用“动态分配”以节省硬盘空间,下一步
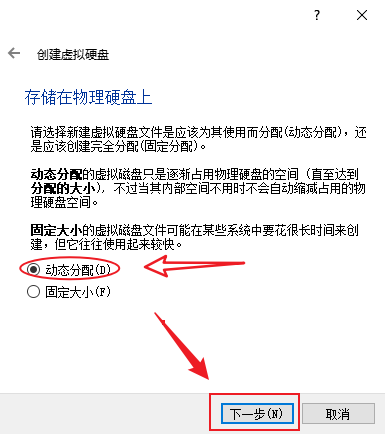
- 位置保持默认,硬盘大小建议50G及以上,这是它最大占用的空间,点击“创建”
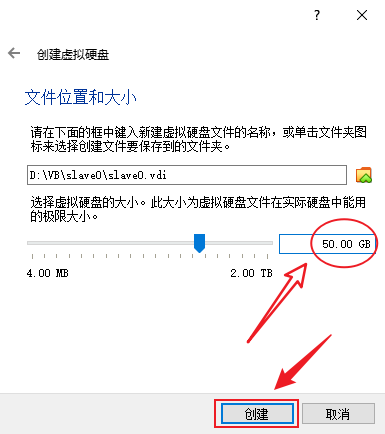
- 创建完成后在启动之前,还需要做一些配置,点击虚拟电脑条目,点击主页上的“设置”,在新打开的设置窗口中点击“存储”→“没有盘片”→ 分配光驱右边的光盘图标 →“选择虚拟盘”
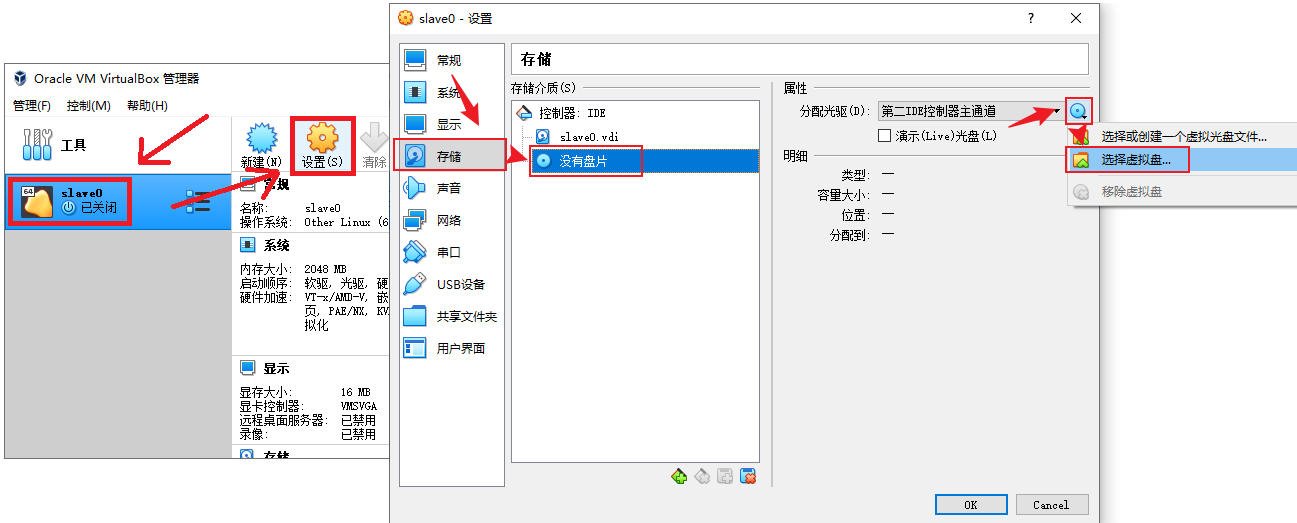
- 选择我们刚刚下载的磁盘映像,打开
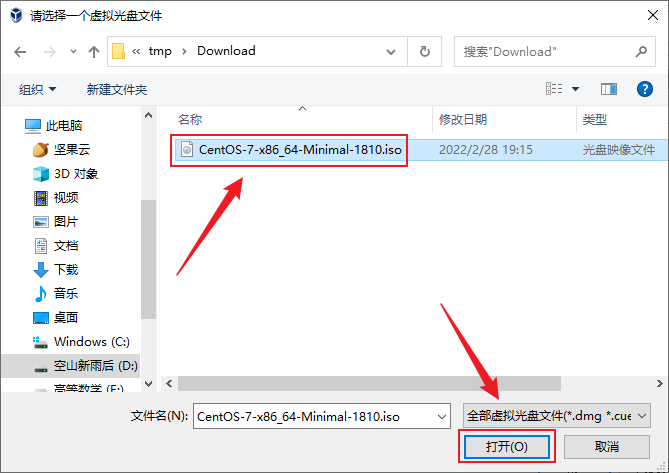
- VirtualBox的NAT网络不能从宿主机主动连接到虚拟机,所以虚拟机还需要加个网卡来专门做与宿主机的互联,点击“网络”→“网卡2”→“启用网络连接”,连接方式选择“仅主机 (Host-Only)网络”,界面名称保持默认,OK
- 选中虚拟机,点击启动按钮
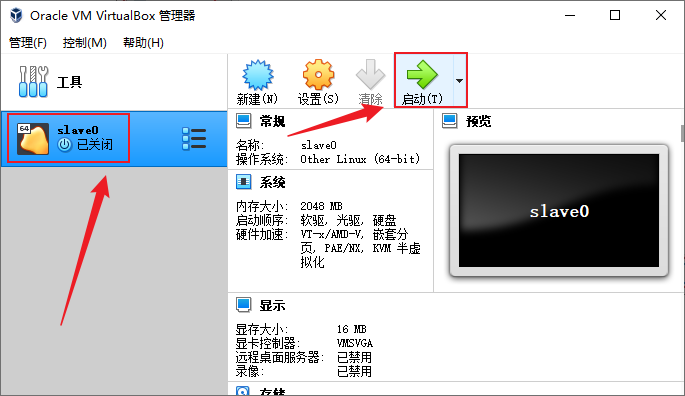
- 在新打开的窗口中点击虚拟机界面,会弹出提示,键鼠会被虚拟机捕获独占,退出按右边的Ctrl键,可以勾选不要再提示,点击捕获按钮开始操作操作虚拟机
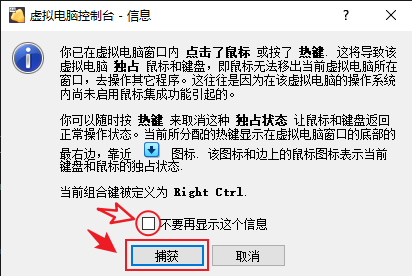
- 可以把这个消息提示关了(提示你控制虚拟机键鼠会被独占),进入控制虚拟机后,按下向上箭头“↑”调整选项到“Install CentOS 7”选项,回车
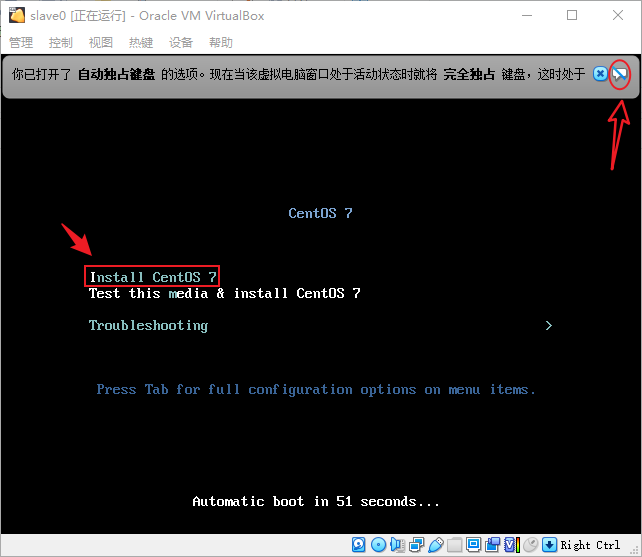
- 可以把这个消息提示关了(提示你虚拟机支持鼠标自动切换,即不会独占),选择一种自己喜欢的语言,点“继续(C)”
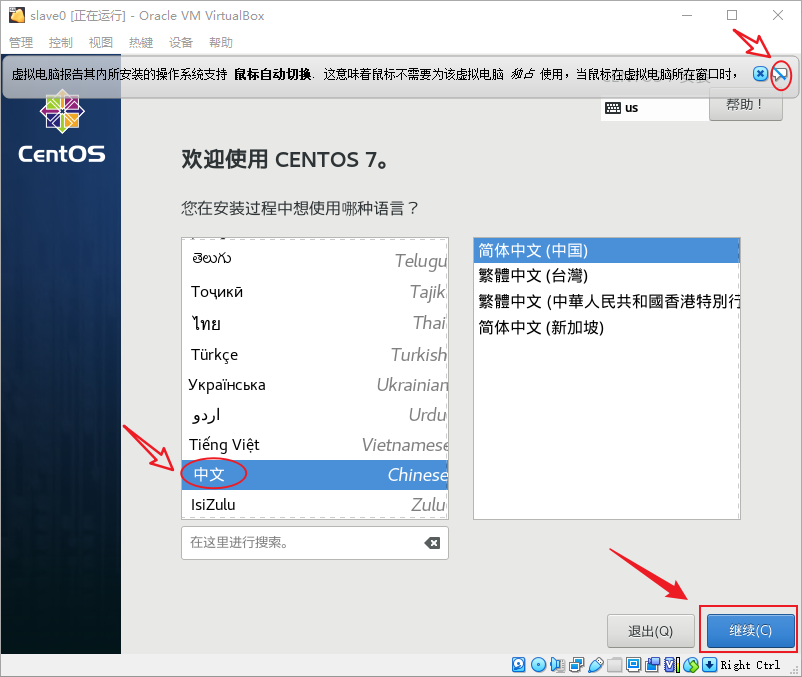
- 确认一下“日期和时间”设置得对不对,如果不对,需要手动更改一下,然后点击“安装位置(D)”以选择一个安装位置
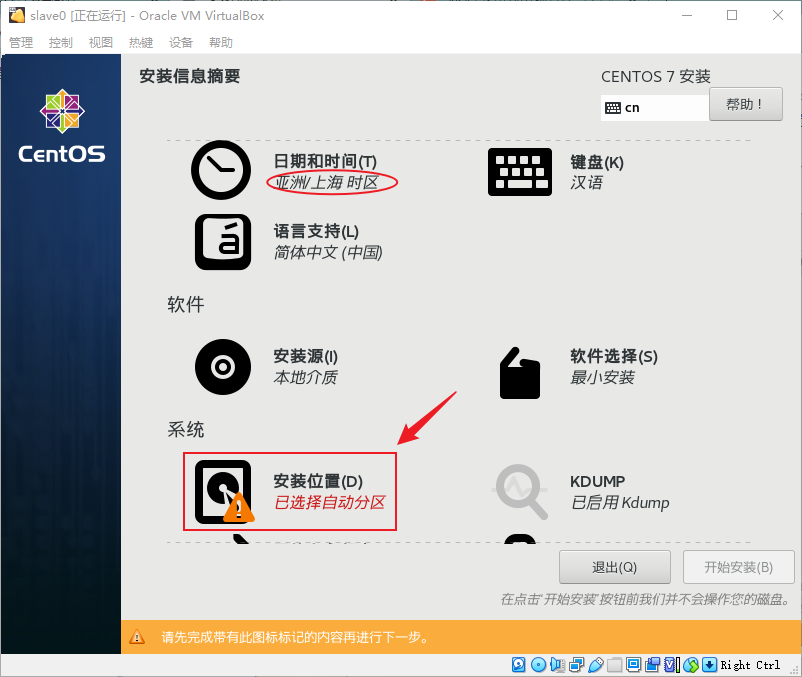
- 根据自己的需求选择磁盘,这边我保持默认,直接点击“完成(D)”
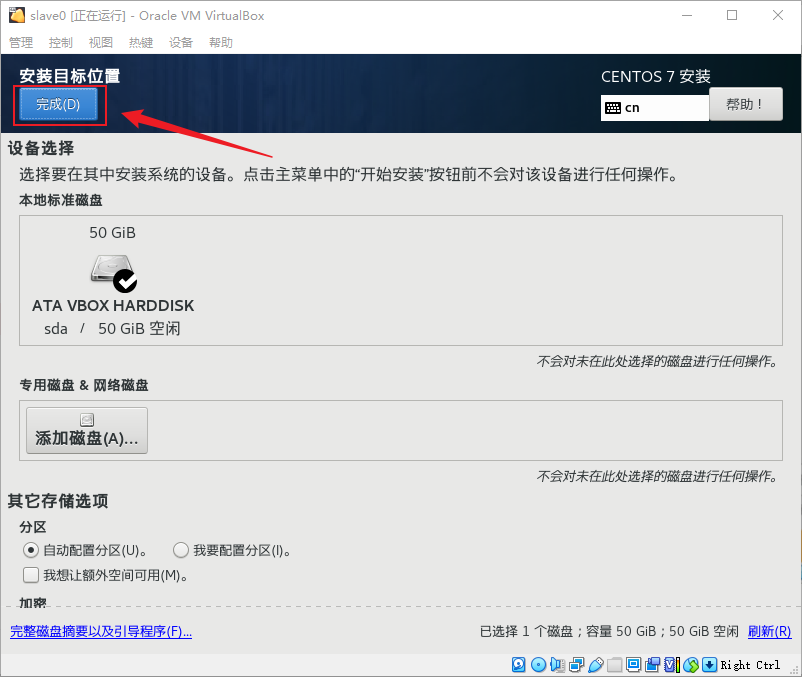
- 出来之后点击“开始安装”以开始安装CentOS
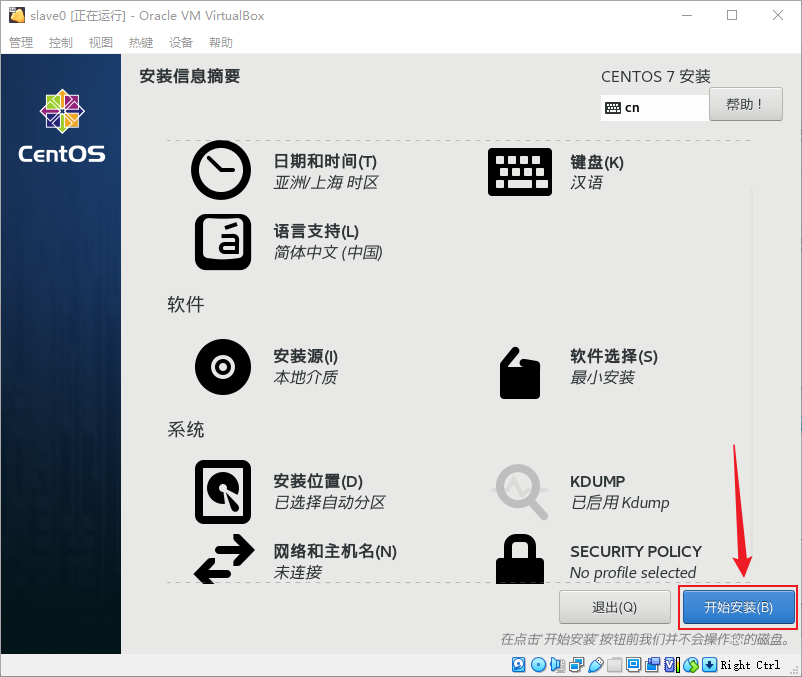
- 安装过程中点击“ROOT密码”来设置一下root的密码
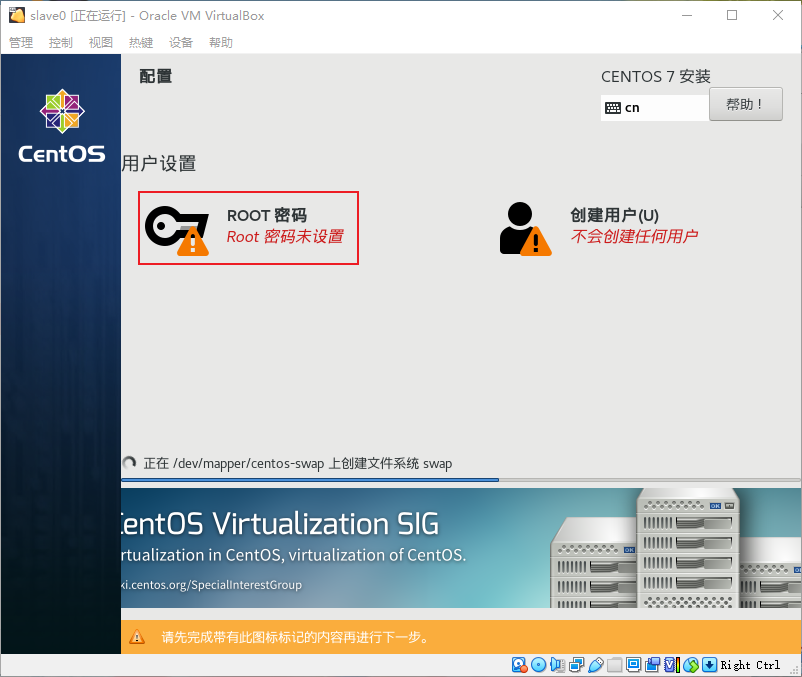
- 输入两次密码,如果密码太短,需要按两次“完成(D)”才能完成设置
- 安装完成后点击“重启(R)”以重启虚拟机
- 重启后看到这个登录界面,说明系统已经安装成功了
- 点击上面菜单栏的控制,选择“正常关机”来关闭虚拟机
- 关机后,在主面板中找到“slave0”,右键→“复制”以进入复制向导
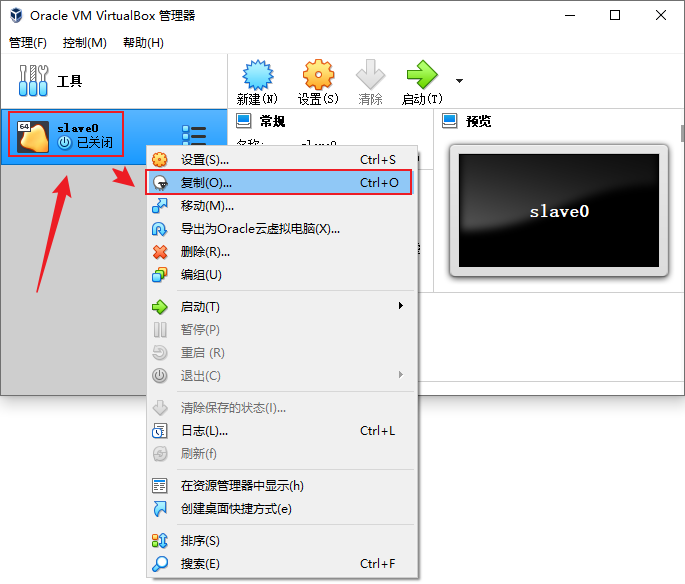
- 更改一下名称、调整到合适的路径,MAC地址设定选择为“为所有网卡重新生成MAC地址”,下一步
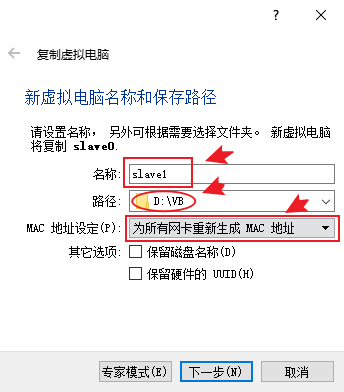
25.副本类型选择“完全复制”,点击复制即可开始复制
- 复制之后我们得到“slave1”
- 按同样的方法复制出“slave2”,可以根据自己的需求可以克隆自己需要的台数,这边三台即可
VMware Workstation Pro 安装Linux集群
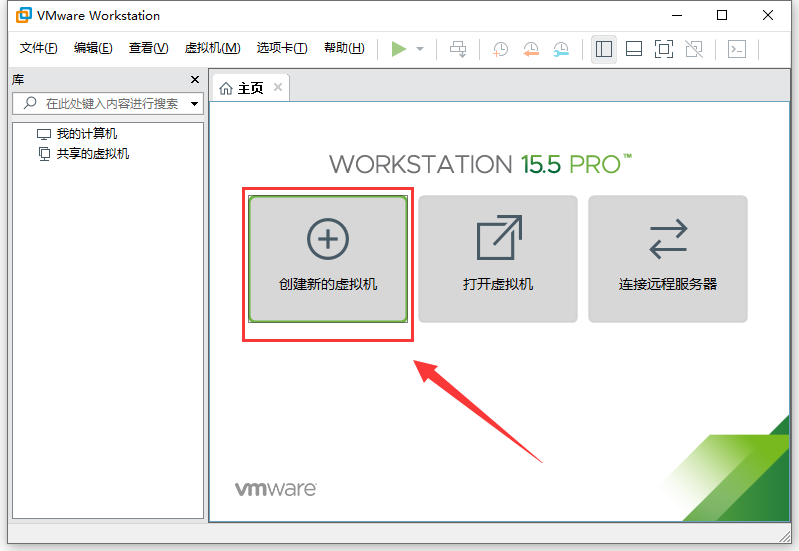
- 打开VMware Workstation Pro,点击主页上的“创建新的虚拟机”
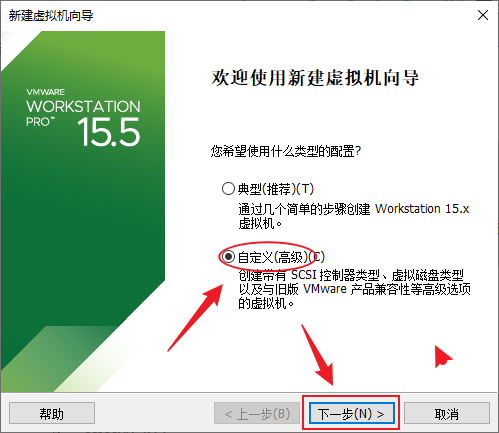
- 选择“自定义(高级)(C)”选项,下一步
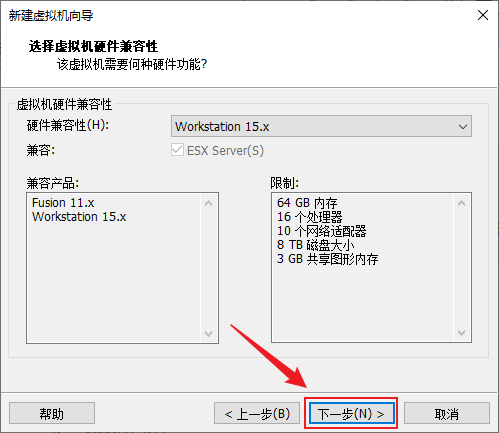
- 虚拟机硬件兼容性保持默认,下一步
- 选择“稍后安装操作系统”,下一步
- 客户机操作系统选择“Linux”,版本选择“CentOS 7 64位”,下一步
- 可以给虚拟机起个名字,方便以后操作,“slave0”(slave:从机),然后选择一下虚拟机的保存位置,尽量选容量大点的磁盘,下一步
- 处理器配置先保持默认,后面随时可以更改,下一步
- 设置虚拟机运行内存大小,根据自己的电脑内存大小和同时需要启动的虚拟机数量来决定,可以使用推荐的1G,但最好使用2G及以上,后面不够用了也可以调整,这边使用2G,下一步
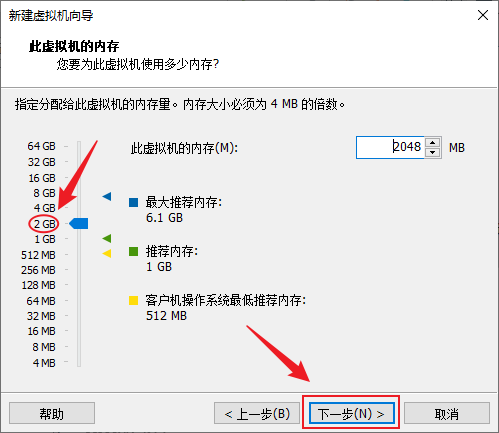
- 网络类型建议选择NAT类型,这样宿主机可以连接到虚拟机上,虚拟机也能连接到网络,而且IP地址比较稳定,下一步
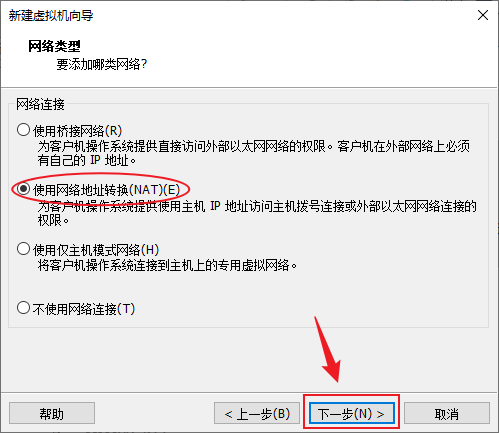
- IO控制器保持默认,下一步
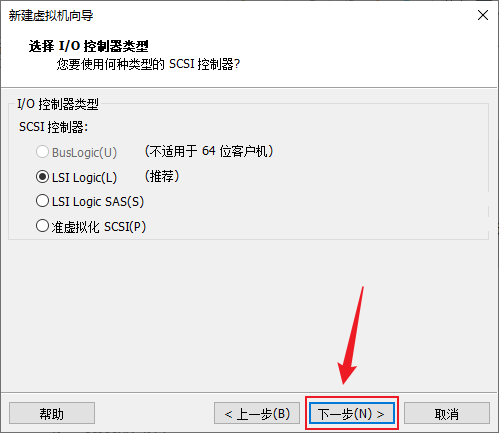
- 磁盘类型保持默认,下一步
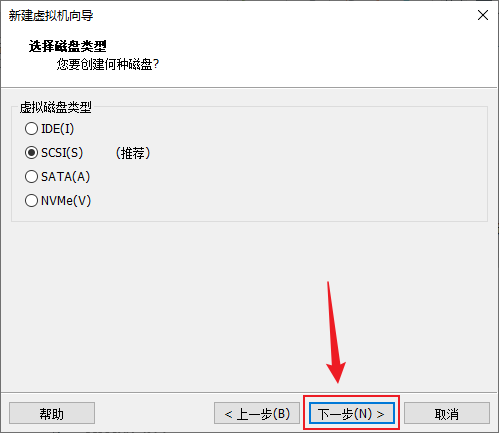
- 需要创建一个新的磁盘,选择“创建新虚拟磁盘(V)”,下一步
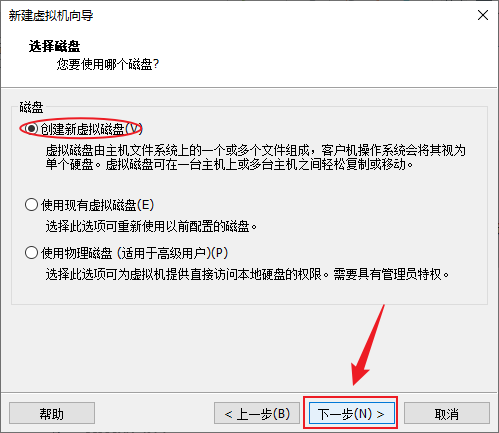
- 设置一下虚拟机的磁盘大小,按自己的需求来,建议50GB及以上,下一步
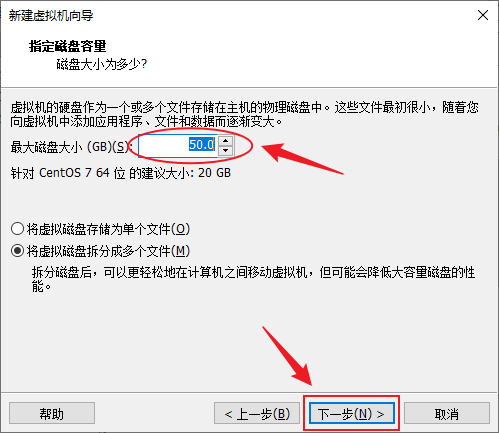
- 磁盘文件名保持默认,下一步
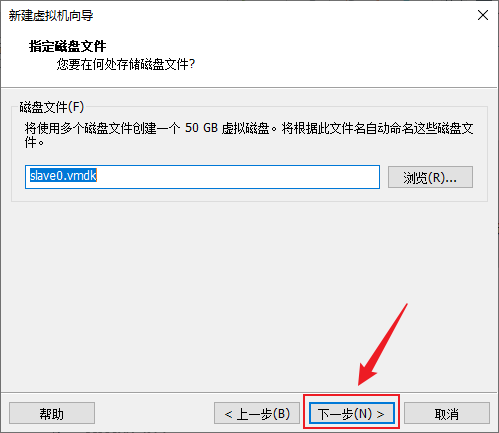
- 确认配置信息没问题后点完成以创建虚拟机
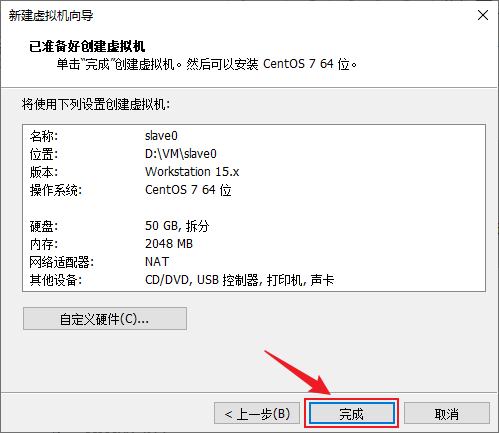
- 创建完成后需要再做一些配置来安装操作系统,在slave0虚拟机主页点击“编辑虚拟机设置”
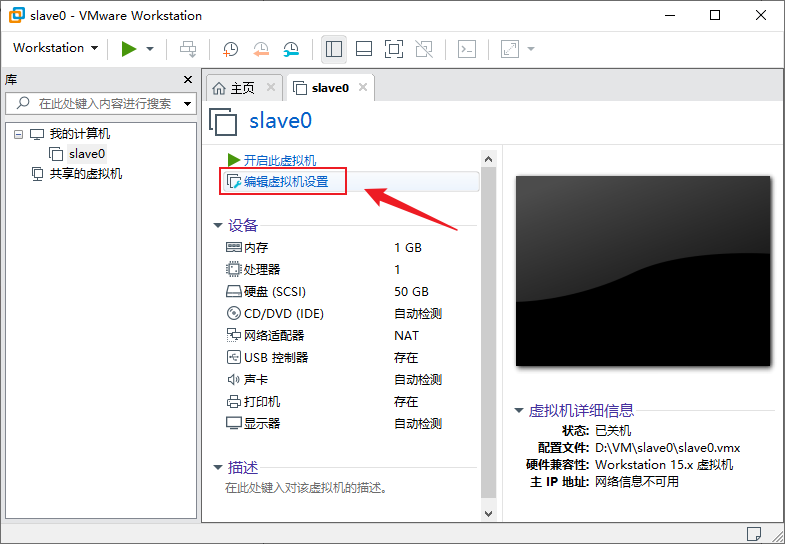
- 在虚拟机设置 → “硬件”→“CD/DVD (IDE)”中选择“使用ISO映像文件(M)”,点击“浏览(B)...”,选择到刚刚下载好的“CentOS-7-x86_64-Minimal-1810.iso”,打开,确定
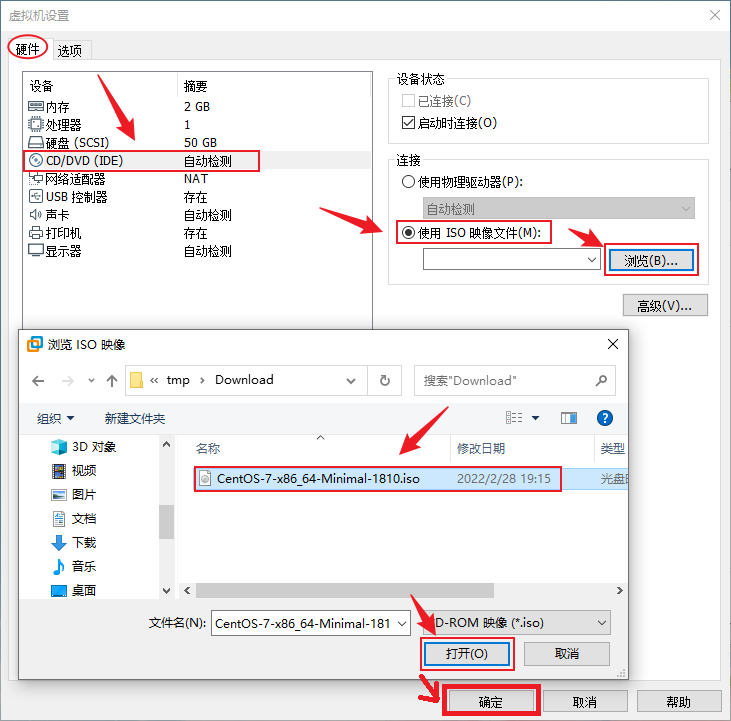
- 回到“slave0主页”后点击“开启此虚拟机”以启动虚拟机
- 虚拟机启动后,鼠标点击虚拟机黑色界面进入控制虚拟机,按下向上箭头“↑”调整选项到“Install CentOS 7”选项,回车

- 选择一种自己喜欢的语言,点“继续(C)”
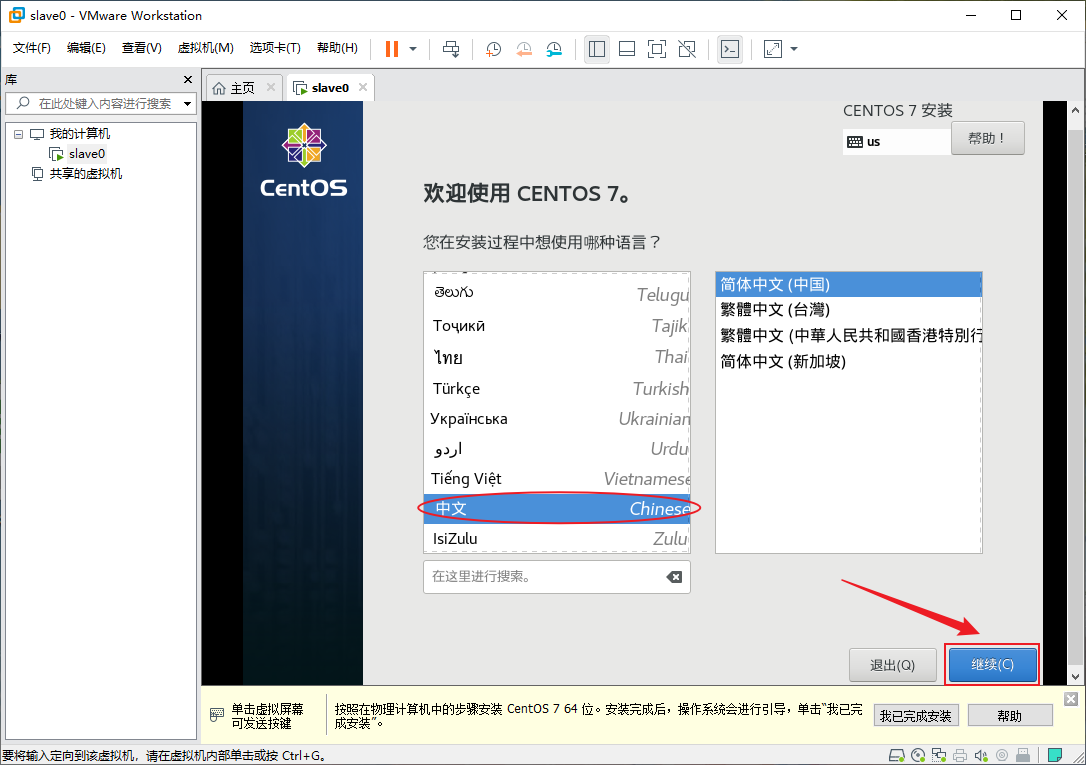
- 确认一下“日期和时间”设置得对不对,如果不对,需要手动更改一下,然后点击“安装位置(D)”以选择一个安装位置
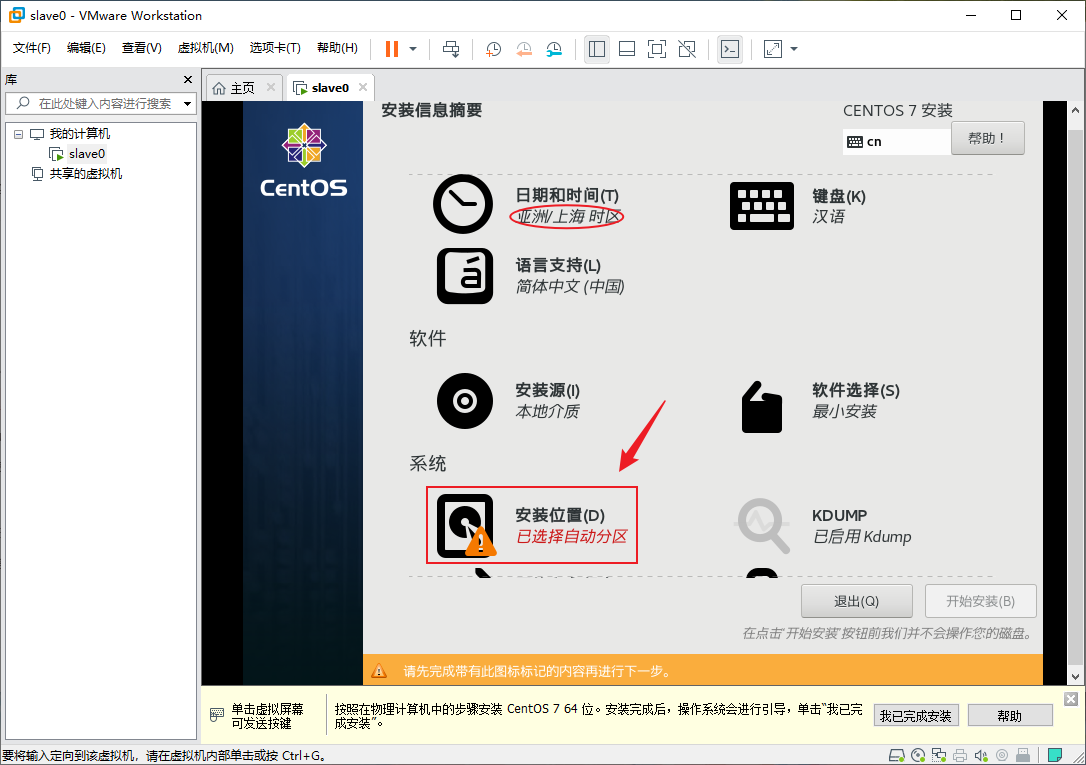
- 根据自己的需求选择磁盘,这边我保持默认,直接点击“完成(D)”
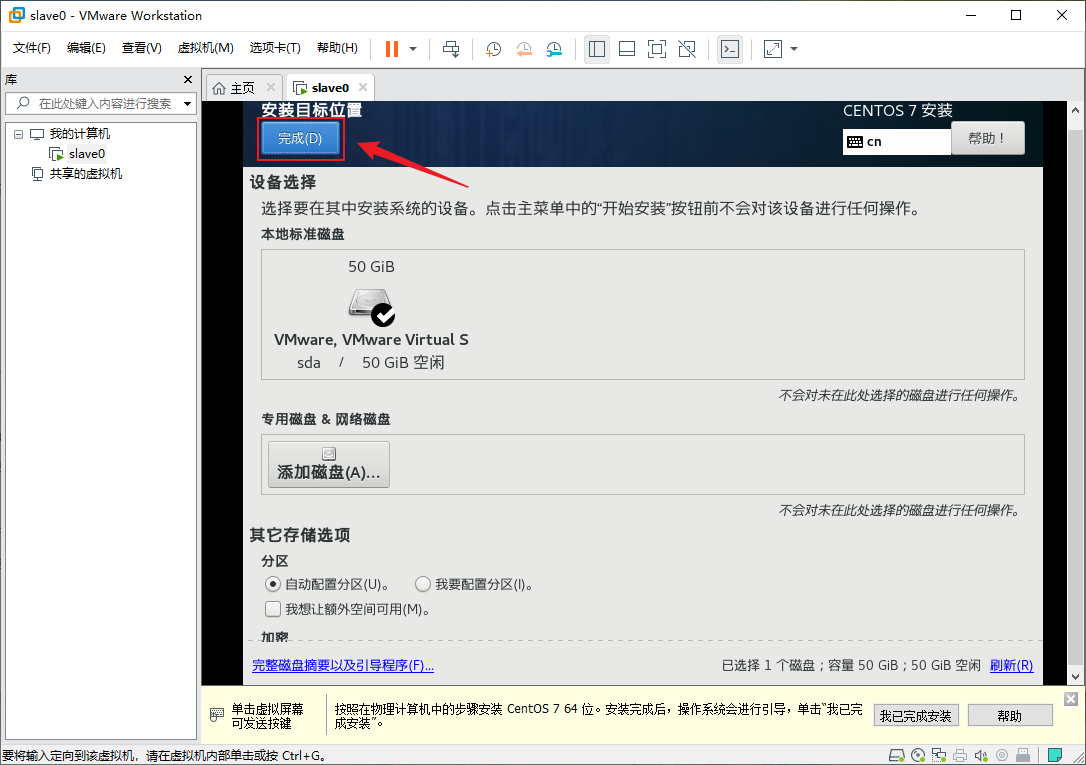
- 出来之后点击“开始安装”以开始安装CentOS
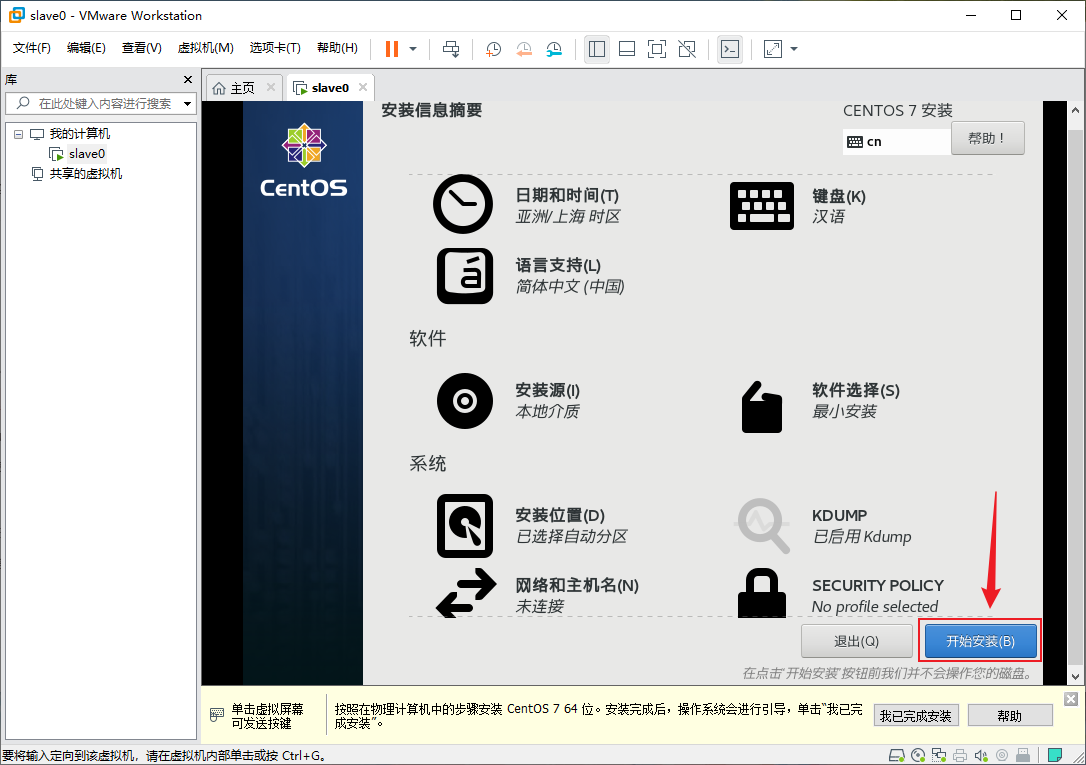
- 安装过程中点击“ROOT密码”来设置一下root的密码
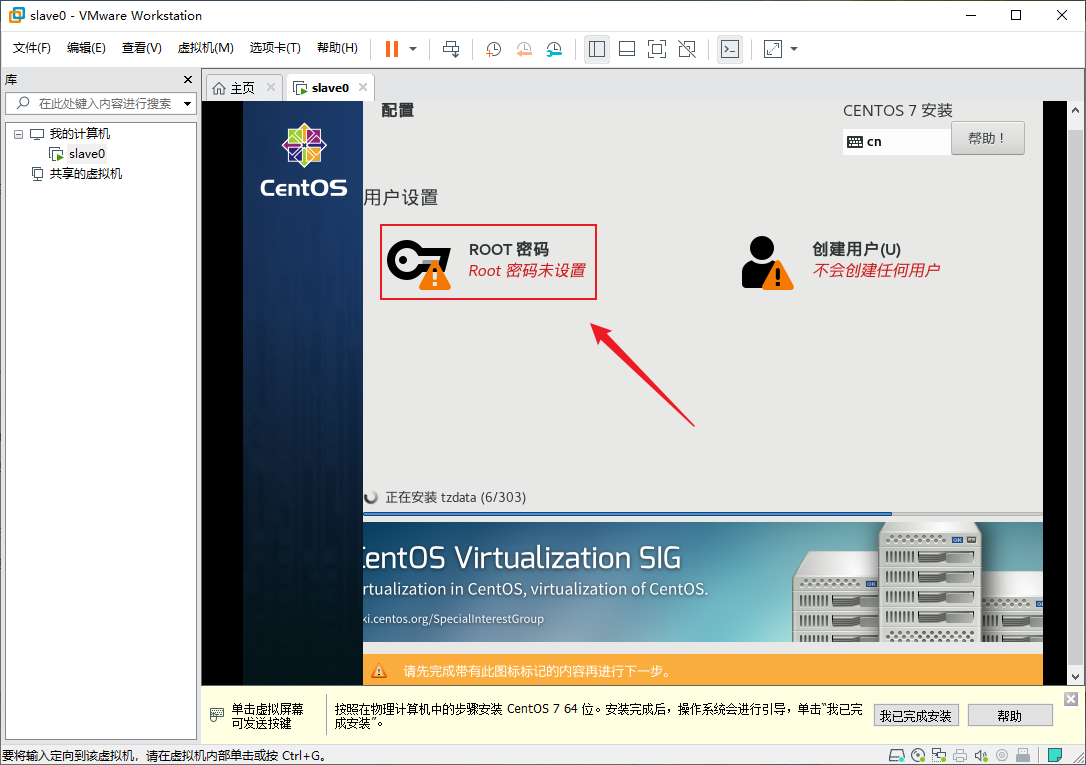
- 输入两次密码,如果密码太短,需要按两次“完成(D)”才能完成设置
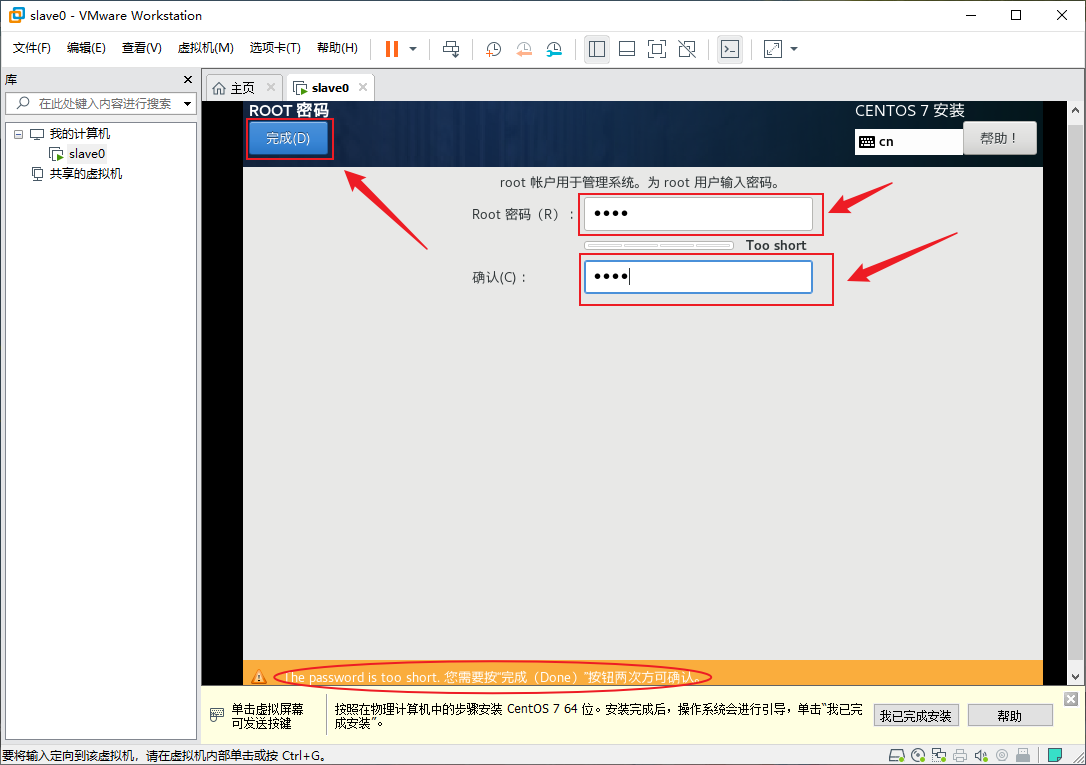
- 安装完成后点击“重启(R)”以重启虚拟机
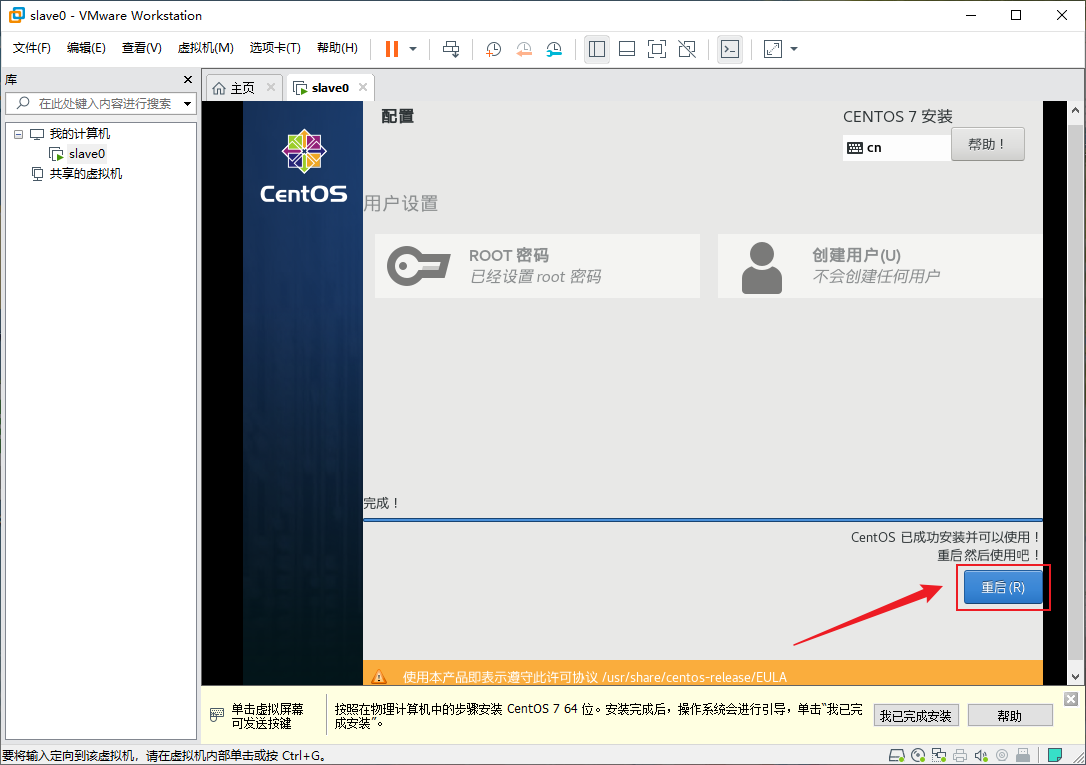
- 重启后看到这个登录界面,说明系统已经安装成功了
- 点击VMware上的暂停按钮右边的三角形,选择“关闭客户机(D)”来关闭虚拟机
- 点击“关机”确认关机,可以根据自己的需求勾选“不再显示此消息”
- 关机后,在“库”面板中找到“slave0”,右键→“管理”→“克隆”以进入克隆向导
- 下一页
- 克隆源保持默认,下一页
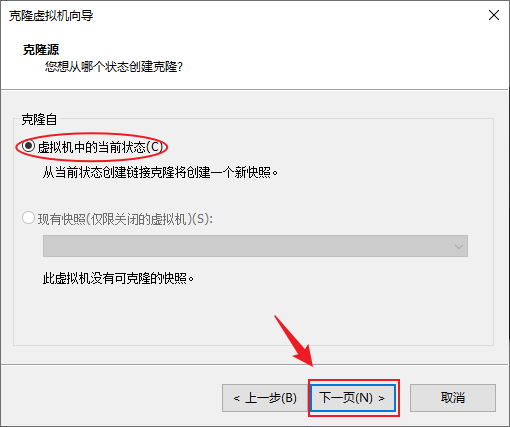
- 克隆类型建议选择“创建完整克隆(F)”,下一步
- 更改一下后的虚拟机名称和存储的位置,完成
- 完成后点“关闭”以关闭克隆虚拟机向导
- 这样,我们就得到了另外一台已经安装好系统的虚拟机“slave1”
- 以同样的方式再克隆一台虚拟机,可以根据自己的需求可以克隆自己需要的台数,这边三台即可
Linux集群网络配置
VirtualBox虚拟机网络配置
查看网络信息
- 点击“管理”菜单,选择“主机网络管理器”
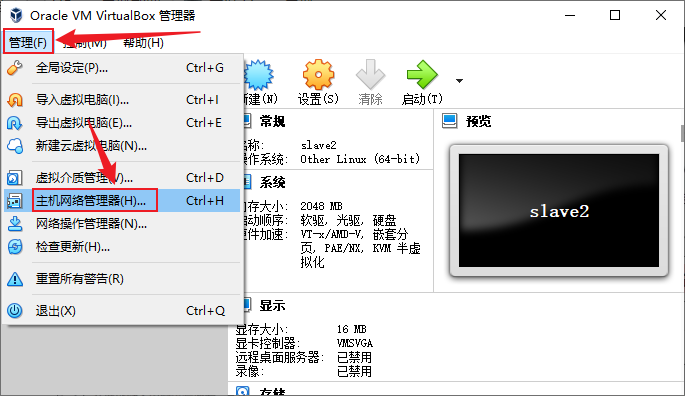
- 点击里面唯一的网卡,点击“属性”,选择“DHCP服务器”选项卡,可以看到所有的网络信息
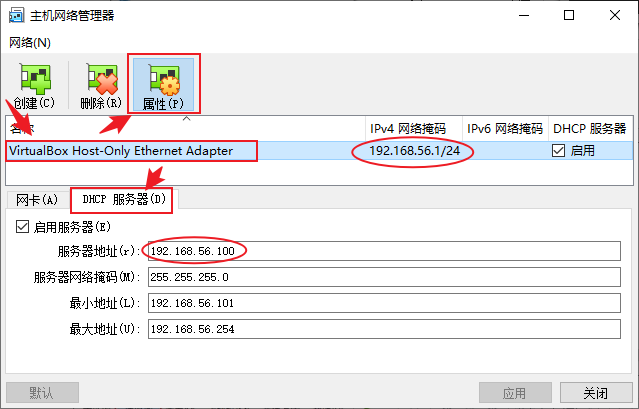
这边我的子网IP为192.168.56.0,子网掩码24位,网关是192.168.56.100,接下来将根据这些信息设置我虚拟机的网络。
启用网卡
- 启动虚拟机并登陆进去
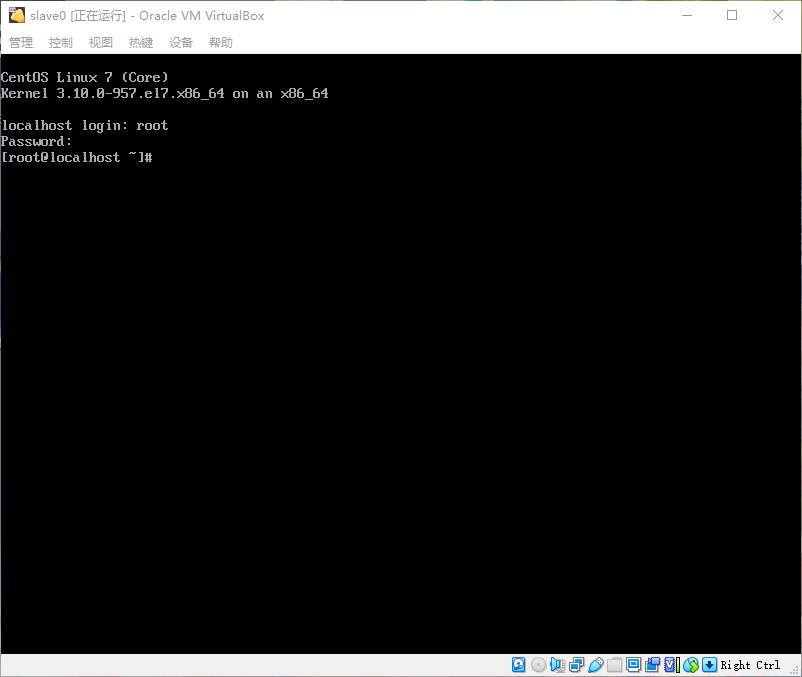
- 使用
ip addr命令查询网卡名称,我这里查询到的网卡名称是“enp0s3”和“enp0s8”
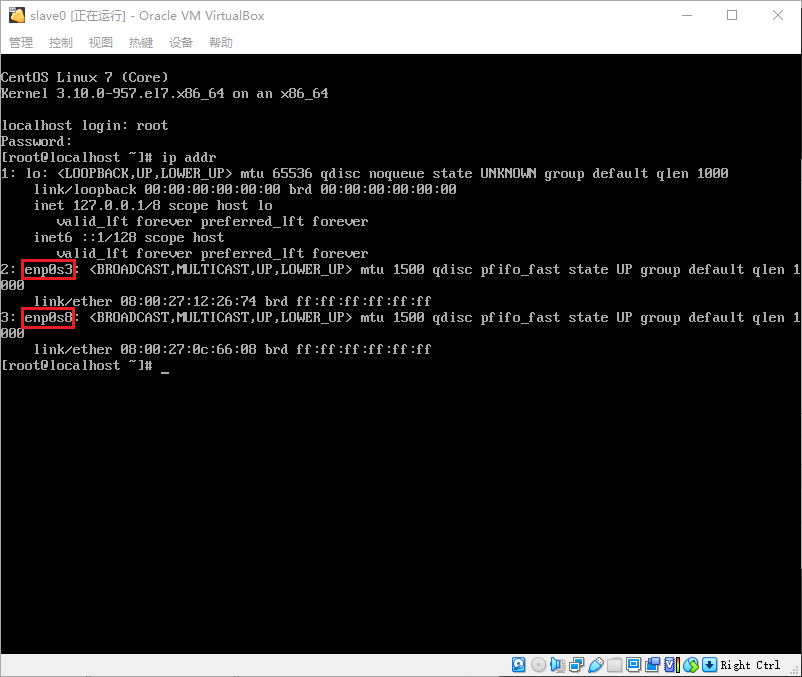
- 启用网卡,输入命令
ifup enp0s8和ifup enp0s3即ifup 网卡名以启用网卡

- 再次使用
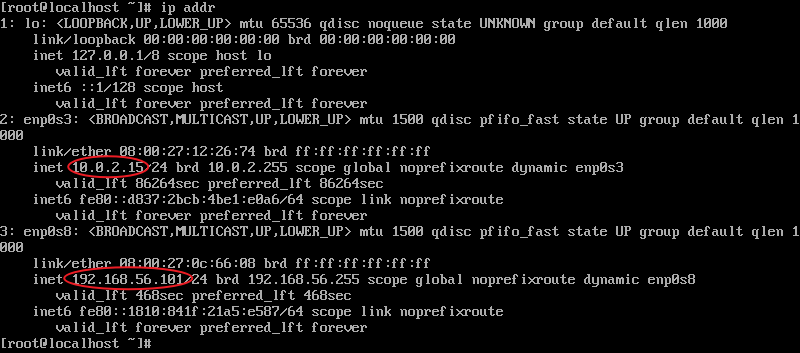
ip addr命令查看网卡对应的IP地址,可以看到,“enp0s8”的网段与主机网络管理器中的网段为同一网段,则虚拟机是通过“enp0s8”与主机联通,而“enp0s3”则通过NAT与外网联通,因此我们为方便后期操作,只需要配置“enp0s8”为静态IP即可
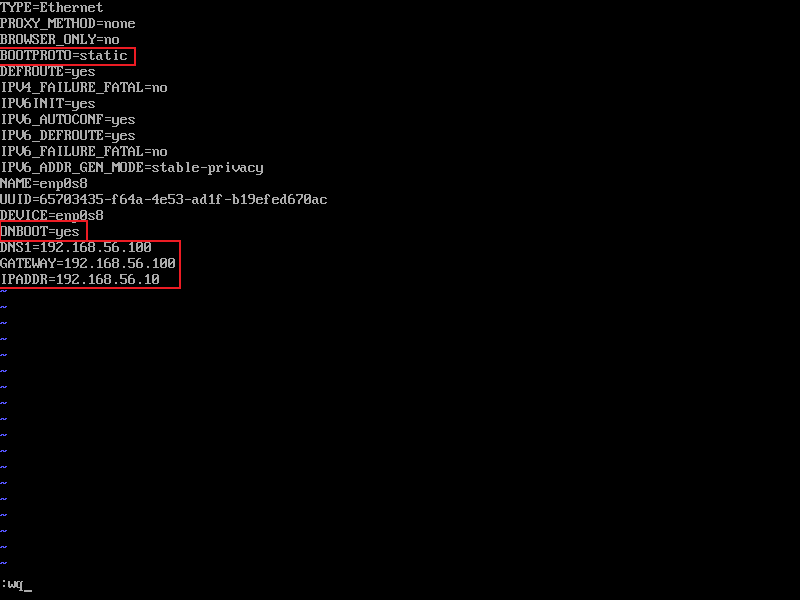
- 配置主机网卡,使用vi编辑网卡配置文件,命令:
vi /etc/sysconfig/network-scripts/ifcfg-enp0s8即vi /etc/sysconfig/network-scripts/ifcfg-网卡名,进入编辑界面后(按i开始编辑),需要修改BOOTPROTO的值为static(静态IP),ONBOOT的值为yes(启用),再添加DNS1,GATEWAY和IPADDR,其中,DNS1和GATEWAY均为虚拟网络编辑器中查询到的网关地址,IPADDR设置为与虚拟网络编辑器中网关的IP同一网段的不冲突的IP地址,我的的配置如下,保存并退出(Esc→:wq→回车)
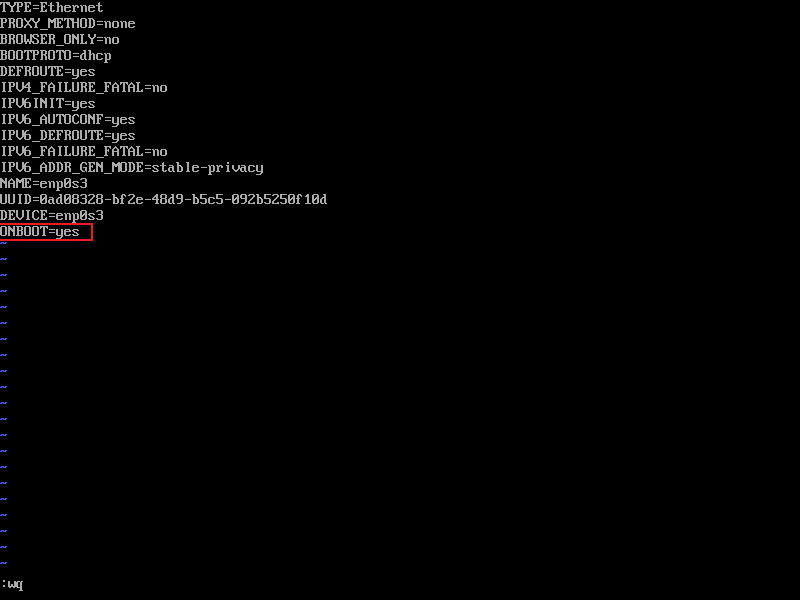
- 按配置主机网卡的方式编辑NAT网卡的配置,此处只需要把ONBOOT的值为yes(启用)即可,保存并退出
- 重启网络服务,输入命令
service network restart以重启网络服务

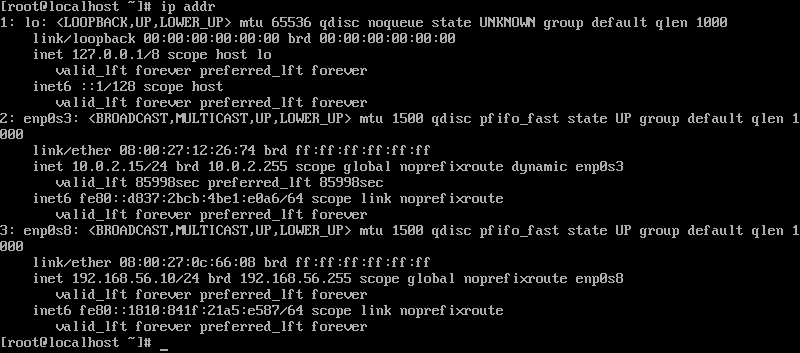
- 检查IP地址是否配置成功,使用
ip addr命令查看当前IP地址,可以看到,我这边配置成功
- 用同样的方式配置另外三台主机,分别设置好启用网卡和静态IP,我这边的IP规划为:
slave0:192.168.56.10
slave1:192.168.56.11
slave2:192.168.56.12
VMware虚拟机网络配置
查看网络信息
- 打开VMware,在菜单栏中选择“编辑”→“虚拟网络编辑器”以打开虚拟网络编辑器
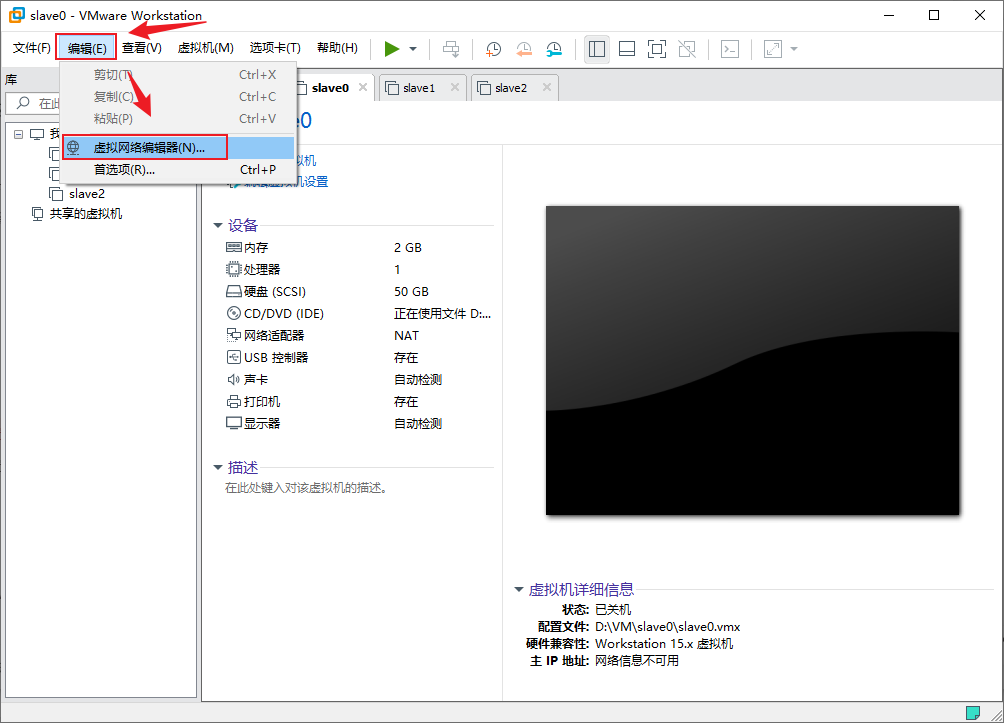
- 在虚拟网络编辑器中找到并点击选择NAT模式的那张虚拟网卡,点击“NAT设置(S)...”可以在新弹出的NAT设置窗口中看到子网IP、子网掩码和网关IP
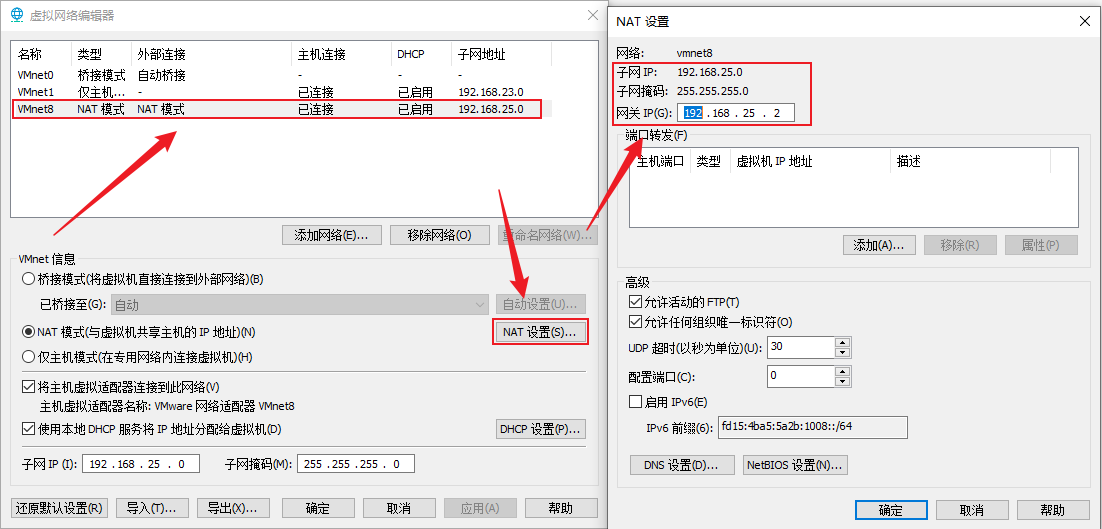
这边我的子网IP为192.168.25.0,子网掩码24位,网关是192.168.25.2,接下来将根据这些信息设置我虚拟机的网络。
启用网卡
- 启动虚拟机并登陆进去
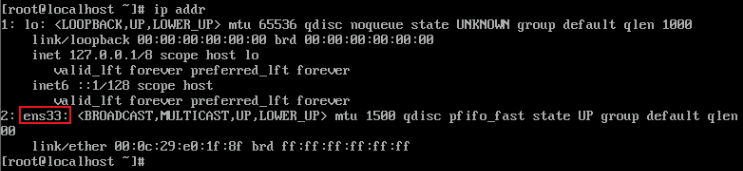
- 使用
ip addr命令查询网卡名称,我这里查询到的网卡名称是“ens33”
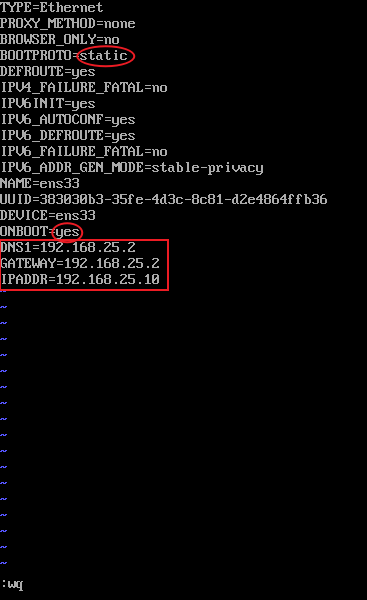
- 配置网卡,使用vi编辑网卡配置文件,命令:
vi /etc/sysconfig/network-scripts/ifcfg-ens33即vi /etc/sysconfig/network-scripts/ifcfg-网卡名,进入编辑界面后(按i开始编辑),需要修改BOOTPROTO的值为static(静态IP),ONBOOT的值为yes(启用),再添加DNS1,GATEWAY和IPADDR,其中,DNS1和GATEWAY均为虚拟网络编辑器中查询到的网关地址,IPADDR设置为与虚拟网络编辑器中网关的IP同一网段的不冲突的IP地址,我的的配置如下,保存并退出(Esc→:wq→回车)

- 重启网络服务,输入命令
service network restart以重启网络服务

- 检查IP地址是否配置成功,使用
ip addr命令查看当前IP地址,可以看到,我这边配置成功
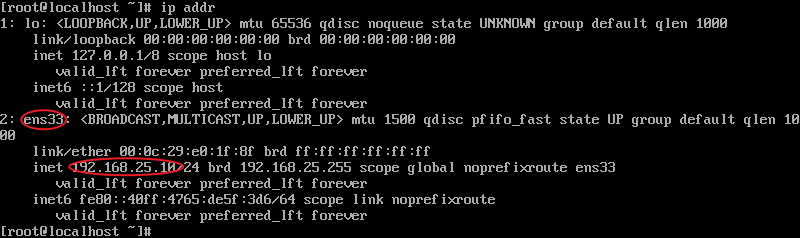
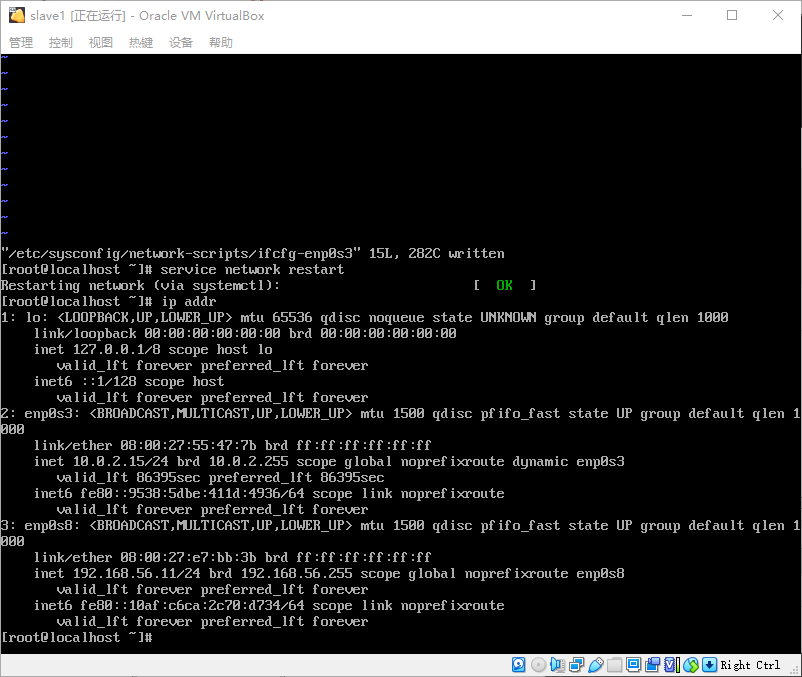
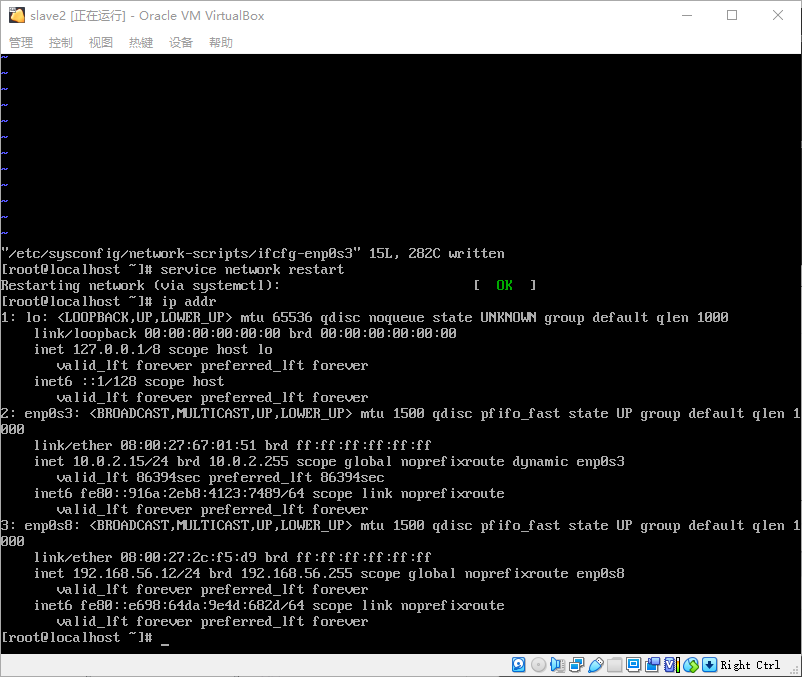
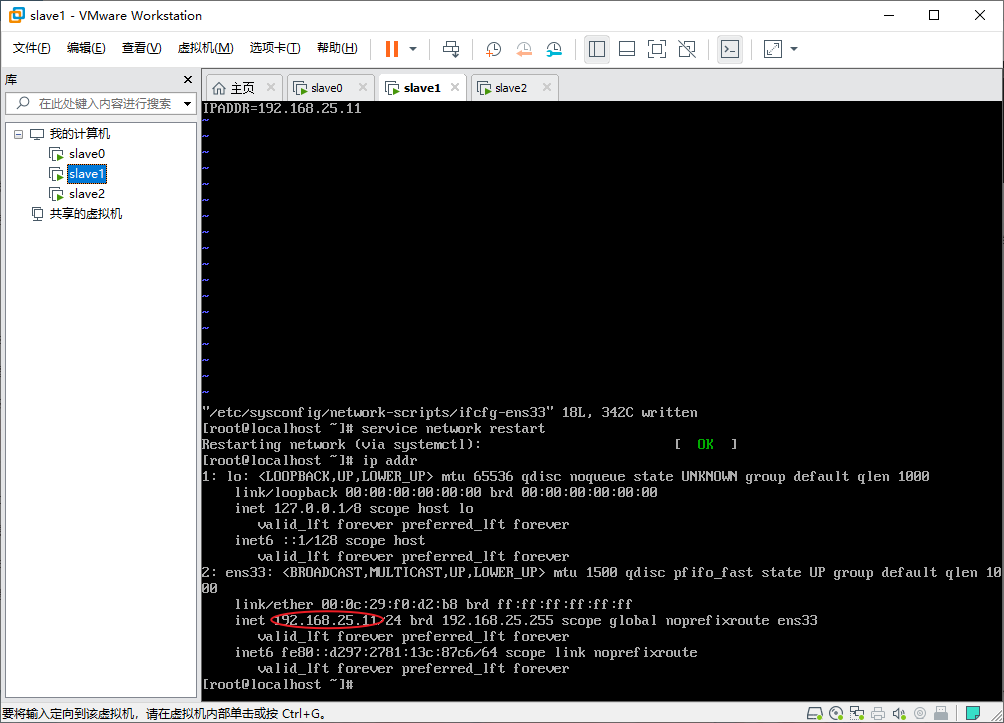
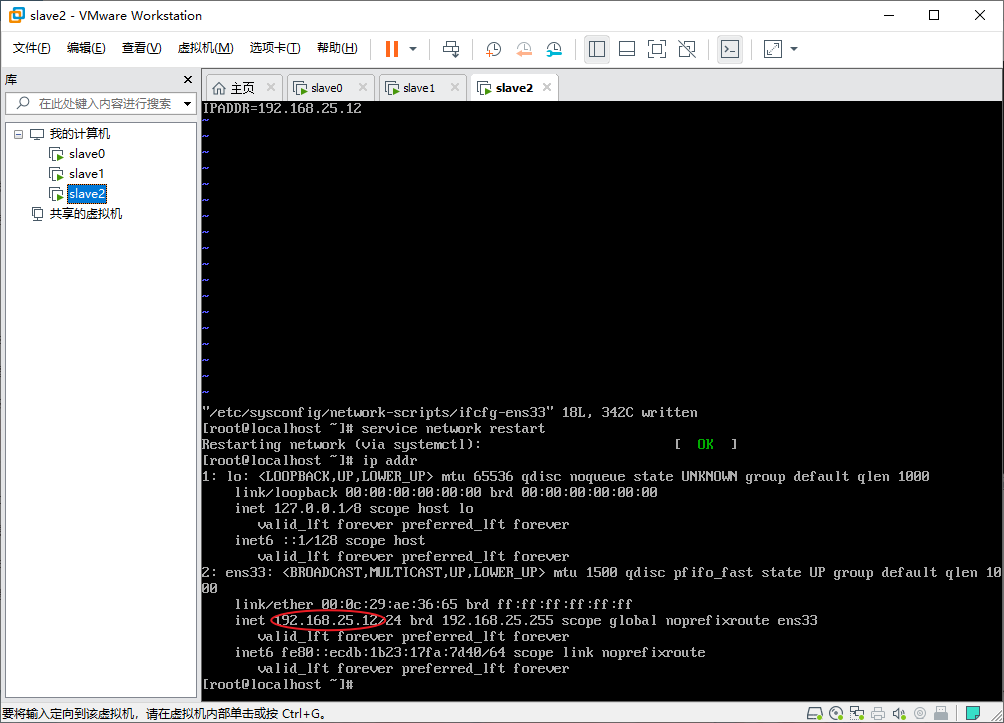
- 用同样的方式配置另外三台主机,分别设置好启用网卡和静态IP,我这边的IP规划为:
slave0:192.168.25.10
slave1:192.168.25.11
slave2:192.168.25.12
远程连接Linux虚拟机
远程连接Linux虚拟机的软件有很多,这边使用MobaXterm演示
软件下载
- 打开mobaxterm.mobatek.net,点击“Download”按钮
- 找到并点击“HomeEdition”下面的“Download now”按钮以下载免费个人版
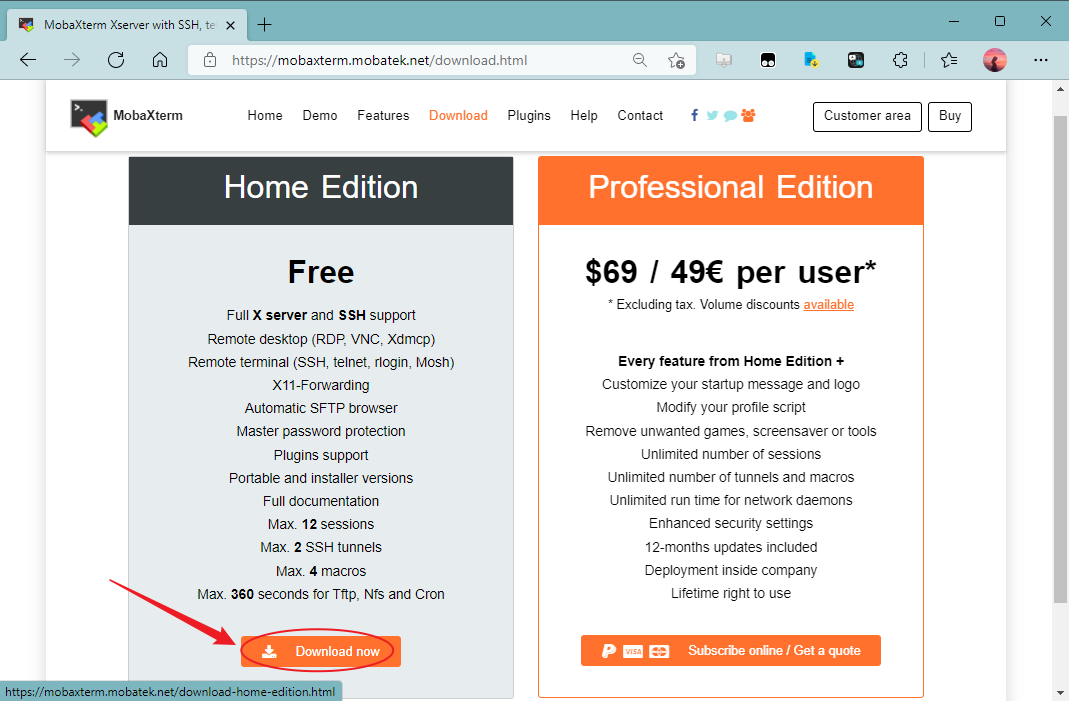
3.点击“MobaXterm Portable v21.5”下载版本为21.5的MobaXterm免安装版,或者你也可以下载最新的免安装版,改动应该不会太大的
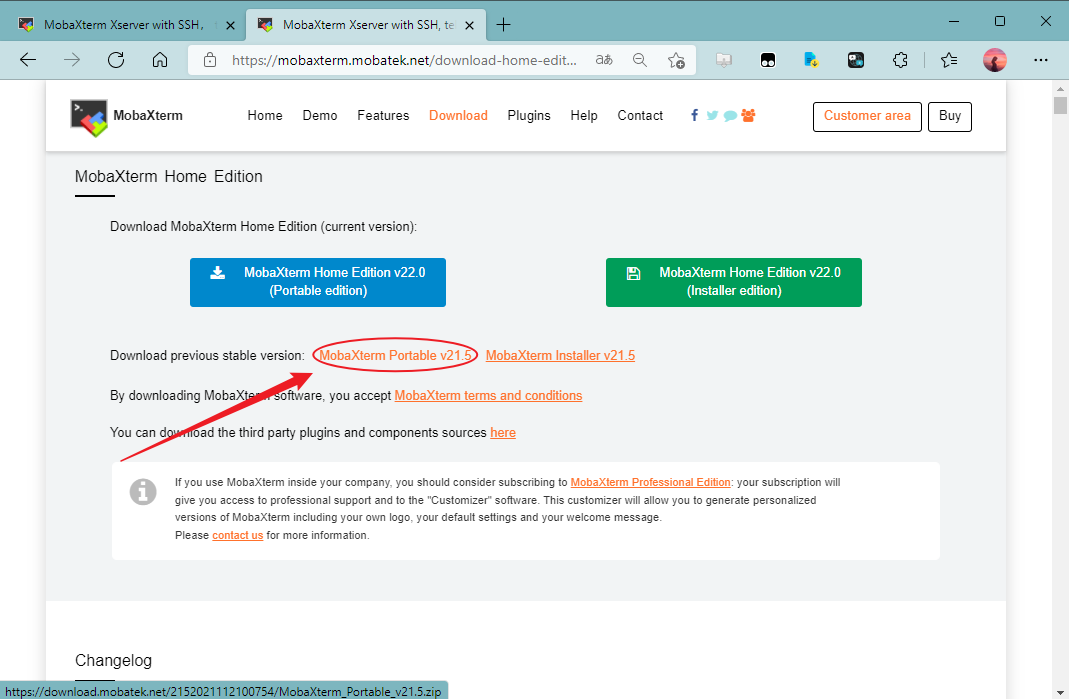
- 下载完成后,右键,解压到当前文件夹
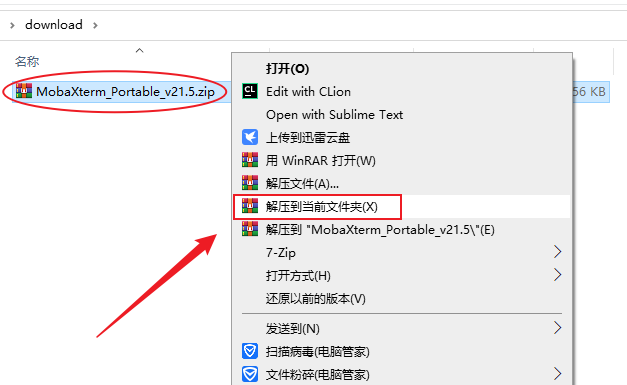
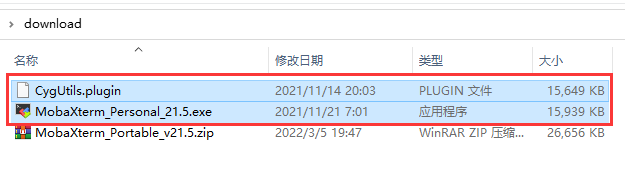
- 解压后得到的这两个文件就是MobaXterm的程序了,你可以把“MobaXterm_Personal_21.5.exe”固定到开始菜单或者发送到桌面快捷方式方便使用,刚刚下载得到的压缩包可以删除了
连接Linux虚拟机
- 打开“MobaXterm_Personal_21.5.exe”进入到MobaXterm的主界面
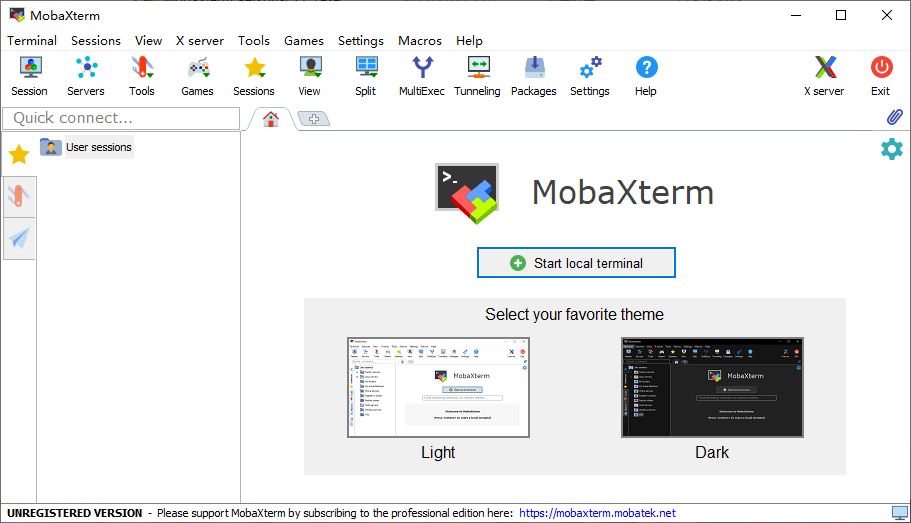
- 点击主界面上的“Session”图标,创建一个新的会话,会话类型选择SSH,在下面的“Remote host”输入框中输入Linux主机的IP地址,为了方便,可以勾选“Specify username”(指定用户名)并输入root,以后就不用每次连接都输入用户名了
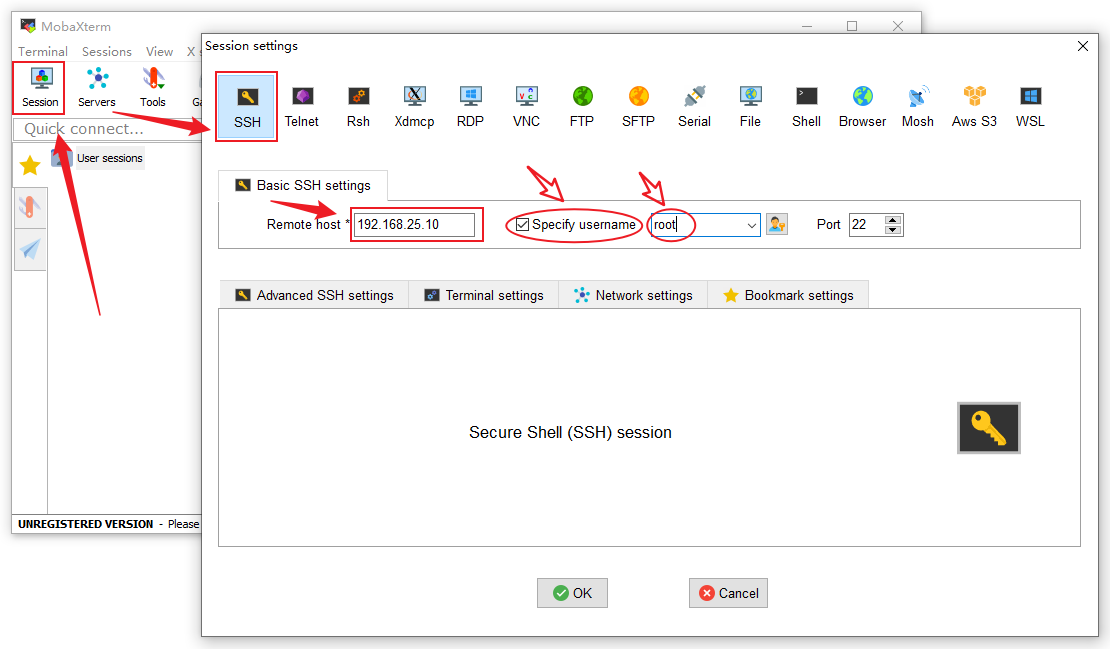
设置字体:在“Session setting”窗口点击“Terminal setting”→“Terminal font setting”,在弹出的“Terminal font selection”窗口中的Size输入框中可以指定字体的大小,默认为10,我这边基于个人习惯,设置为18,设置完成后,点OK关闭“Terminal font selection”窗口
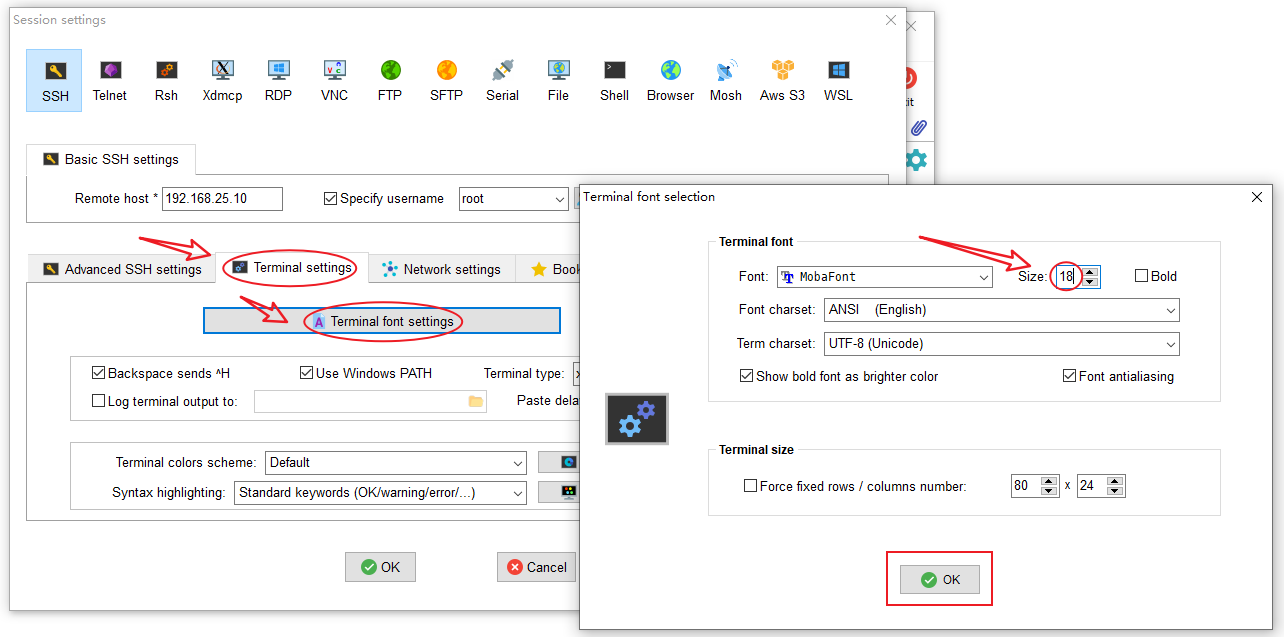
设置会话别名:在“Session setting”窗口点击“Bookmark setting”标签,可以更改“Session name”(会话名字),为了方便,我这边改为跟主机虚拟机一样的名字(slave0),默认是192.168.25.10 (root),不方便识别,设置完成后点OK完成会话的创建
- MobaXterm会自动打开新添加的会话(若没有自动打开需要自己点左边的星星,然后双击打开对应名称的会话),打开后会让你输入密码,如果上一步没勾选指定用户名,还会让你输入用户名的。这边输入密码之后按回车确定
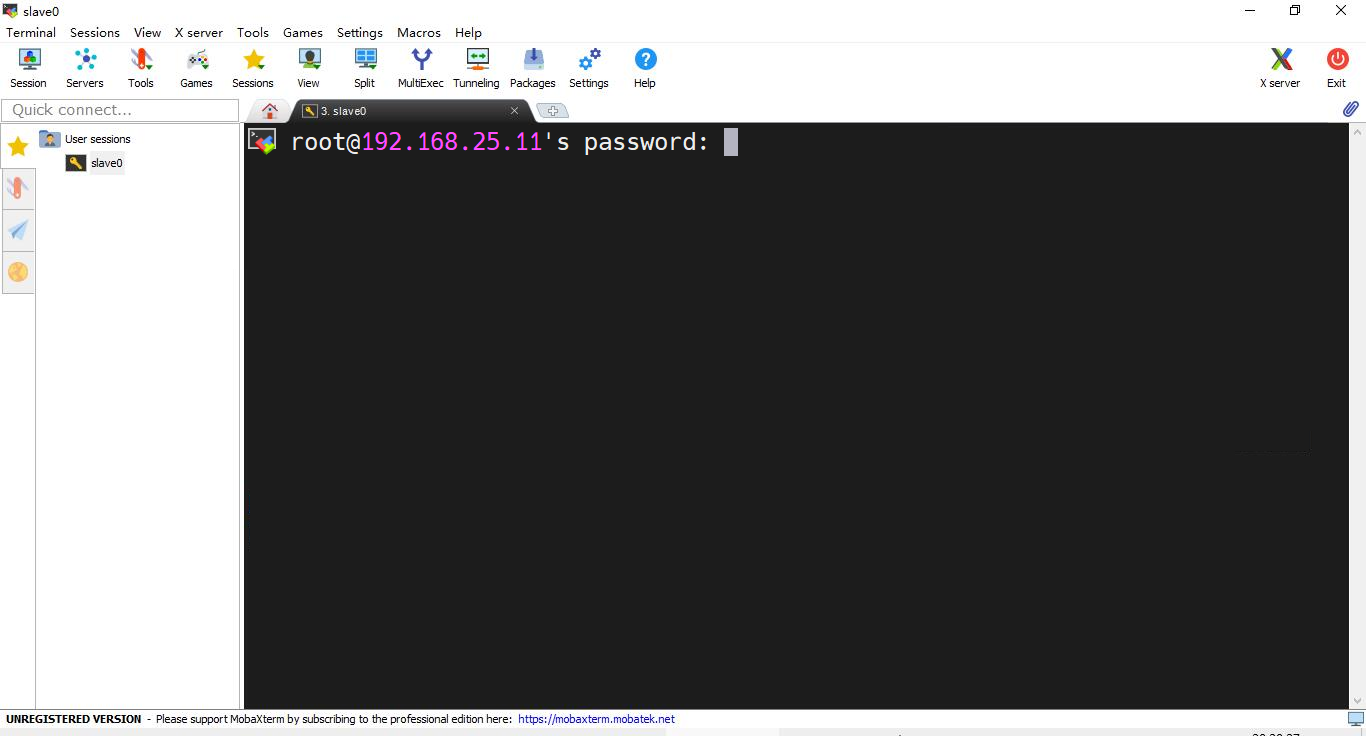
- 连接后会询问你是否保存密码,你可以选择保存或者不保存,为了方便,我这边选择“Yes”来保存密码
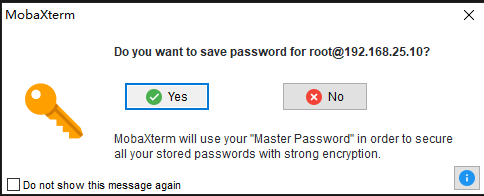
- 如果是第一次保存密码,还会让你设置一个主密码来加密保存你的信息,这个主密码尽量设置得复杂一点,但我为了方便,设置得简单一点。下面的“Prompt me for my master password”(何时让我输入主密码)为了方便你可以选择第一个选项,为了安全你可以选择最后一个,但比较麻烦,这边我就选择第一个选项,点OK设置主密码
- 连接完成,接下来就可以通过MobaXterm与Linux虚拟机进行交互了
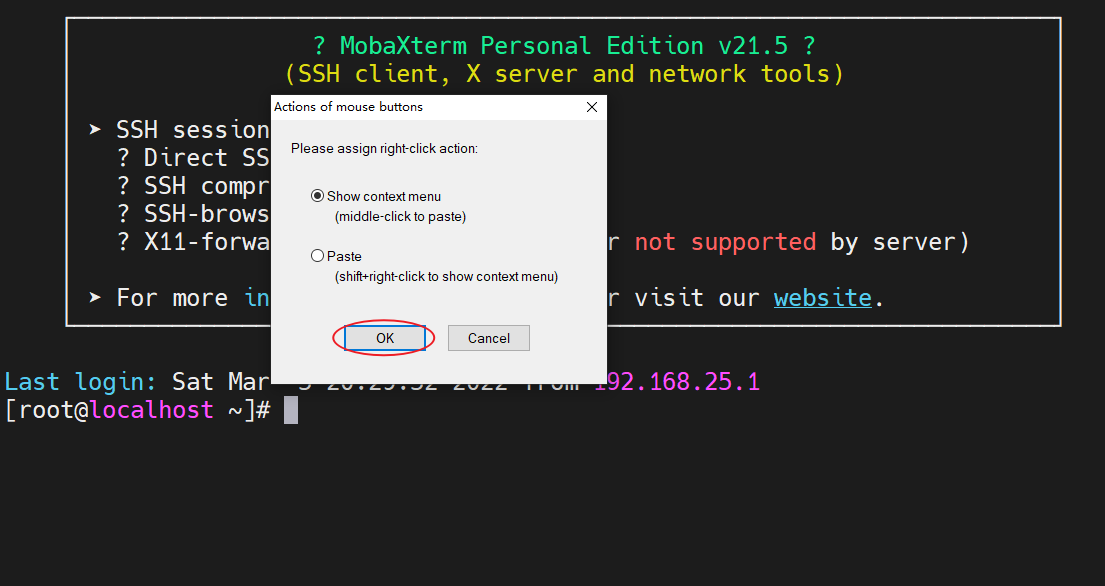
- 鼠标右键功能设置:在窗口中点击鼠标右键,第一次会弹出一个框,第一个选项“Show context menu”是显示右键菜单的意思,第二个选项“Paste”是粘贴的意思,看个人习惯来,选择第一个需要粘贴时使用鼠标中键粘贴,选择第二个如果你要打开菜单得按住shift键点击鼠标右键,这边根据我的习惯,我选择第一个选项,OK
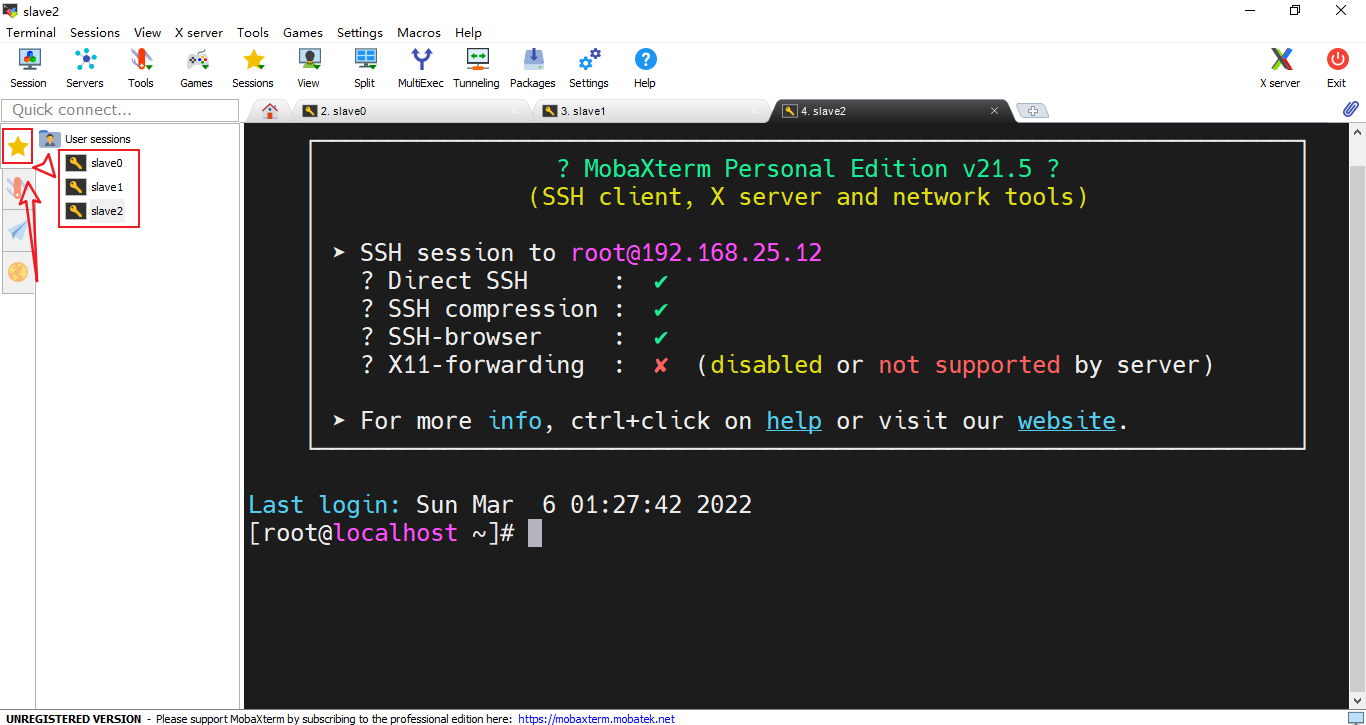
- 把另外两个虚拟机也按以上步骤添加进MobaXterm的会话列表中,最终可以在左边的星星面板里看到三个会话
Linux集群其他配置
关闭防火墙
为了方便Linux虚拟机之间的互联互通,最简单的方式就是把内网的防火墙关掉
临时关闭防火墙(立即生效,但重启后失效)
使用命令systemctl stop firewalld关闭防火墙,使用命令 systemctl status firewalld可以查看防火墙关闭情况
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: inactive (dead) since 日 2022-03-06 13:18:37 CST; 51s ago
Docs: man:firewalld(1)
Process: 6425 ExecStart=/usr/sbin/firewalld --nofork --nopid $FIREWALLD_ARGS (code=exited, status=0/SUCCESS)
Main PID: 6425 (code=exited, status=0/SUCCESS)
3月 06 13:18:00 localhost.localdomain systemd[1]: Starting firewalld - dyn...
3月 06 13:18:02 localhost.localdomain systemd[1]: Started firewalld - dyna...
3月 06 13:18:36 localhost.localdomain systemd[1]: Stopping firewalld - dyn...
3月 06 13:18:37 localhost.localdomain systemd[1]: Stopped firewalld - dyna...
Hint: Some lines were ellipsized, use -l to show in full.
[root@localhost ~]#
可以看到上面防火墙已被停掉了,成功
永久关闭防火墙(重启后生效)
永久关闭防火墙(重启后生效)
使用命令systemctl disable firewalld禁用防火墙,使用命令systemctl list-unit-files | grep firewalld可以查看防火墙是否被禁用成功
[root@localhost ~]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
[root@localhost ~]# systemctl list-unit-files | grep firewalld
firewalld.service disabled
[root@localhost ~]#
可以看到,防火墙已经被成功禁用了,成功
其他两台虚拟机使用同样的方法把防火墙给关掉
修改主机名
为了方便区分虚拟机,需要修改其主机名
使用命令hostname查看当前主机名
临时修改主机名(立即生效,但重启后失效)
使用命令hostnam 新的主机名临时修改主机名
[root@localhost ~]# hostname
localhost.localdomain
[root@localhost ~]# hostname slave0
[root@localhost ~]# hostname
slave0
[root@localhost ~]#
可以看到,修改后再查询主机名马上生效了
永久修改主机名(重启后生效)
主机名信息保存在/etc/hostname中,Linux每次开机从这个文件中读取主机名,所以我们要想达到永久修改的效果,只需要修改此文件的内容即可
[root@slave0 ~]# vi /etc/hostname
slave0
~
~
~
"/etc/hostname" 1L, 7C written
[root@slave0 ~]#
其他两台虚拟机使用同样的方法把主机名配置好,这边三台我分别配置为slave0、slave1和slave2
配置域名解析文件
从一台Linux连接到另外一台Linux时需要输入IP地址,然而IP地址不太方便记忆,也不方便识别,我们可以用域名来代替IP地址(浏览器通过网址而不是IP访问网站也是这个原理),每个Linux主机上有一个host文件作为本机的域名解析配置,我们可以把IP和对应的域名写入这个文件中关联起来,以后我们就可以通过域名而不是IP去连接另外的Linux虚拟机了
host文件所在路径:/etc/hosts
IP绑定域名格式:IP地址(空格)域名
[root@slave0 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.25.10 slave0
192.168.25.11 slave1
192.168.25.12 slave2
~
~
~
"/etc/hosts" 6L, 222C written
[root@slave0 ~]#
通过以上操作,我们就成功把IP与域名绑定了,以后的slave0、slave1、slave2就分别表示192.168.25.10、192.168.25.11和192.168.25.10了
我们可以通过ping操作验证是否可用
[root@slave0 ~]# ping slave0
PING slave0 (192.168.25.10) 56(84) bytes of data.
64 bytes from slave0 (192.168.25.10): icmp_seq=1 ttl=64 time=0.016 ms
64 bytes from slave0 (192.168.25.10): icmp_seq=2 ttl=64 time=0.026 ms
64 bytes from slave0 (192.168.25.10): icmp_seq=3 ttl=64 time=0.030 ms
^C
--- slave0 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2006ms
rtt min/avg/max/mdev = 0.016/0.024/0.030/0.005 ms
[root@slave0 ~]# ping slave1
PING slave1 (192.168.25.11) 56(84) bytes of data.
64 bytes from slave1 (192.168.25.11): icmp_seq=1 ttl=64 time=0.578 ms
64 bytes from slave1 (192.168.25.11): icmp_seq=2 ttl=64 time=0.317 ms
64 bytes from slave1 (192.168.25.11): icmp_seq=3 ttl=64 time=0.728 ms
^C
--- slave1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2013ms
rtt min/avg/max/mdev = 0.317/0.541/0.728/0.169 ms
[root@slave0 ~]# ping slave2
PING slave2 (192.168.25.12) 56(84) bytes of data.
64 bytes from slave2 (192.168.25.12): icmp_seq=1 ttl=64 time=0.458 ms
64 bytes from slave2 (192.168.25.12): icmp_seq=2 ttl=64 time=0.326 ms
64 bytes from slave2 (192.168.25.12): icmp_seq=3 ttl=64 time=1.02 ms
^C
--- slave2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2011ms
rtt min/avg/max/mdev = 0.326/0.603/1.027/0.305 ms
[root@slave0 ~]#
成功
配置免密码登录
我们可以通过ssh 域名/IP地址的方式连接到另外一台虚拟机,例如从slave0连接到slave1
[root@slave0 ~]# ssh slave1
The authenticity of host 'slave1 (192.168.25.11)' can't be established.
ECDSA key fingerprint is SHA256:brSII1Ii+yIXjzvMWG1Rxn+3vOTolPZq/rJomBVxl00.
ECDSA key fingerprint is MD5:49:0b:71:88:b6:21:4a:b3:c7:ad:79:88:78:0a:1e:5a.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'slave1,192.168.25.11' (ECDSA) to the list of known hosts.
root@slave1's password:
Last login: Sun Mar 6 13:35:22 2022 from 192.168.25.1
[root@slave1 ~]# exit
登出
Connection to slave1 closed.
[root@slave0 ~]# ssh slave1
root@slave1's password:
Last login: Sun Mar 6 13:50:28 2022 from 192.168.25.10
[root@slave1 ~]# exit
登出
Connection to slave1 closed.
[root@slave0 ~]#
比较麻烦,第一次需要输入yes,后面每次都需要输入密码
为了方便各个虚拟机之间的互联互通,我们可以配置免密码登录
生成公钥和私钥
在slave0上使用命令ssh-keygen -t rsa生成一对秘钥(配置全保持默认,即按三次回车)
[root@slave0 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:qckAgde752zoURXjtNkmCHTTZiLKrUf1tLQPTmAa0mY root@slave0
The key's randomart image is:
+---[RSA 2048]----+
| ..+o o.+ |
|. o.Eo==** |
| o.* B.O*oo |
| o.= .*+ |
| o...oSo |
| . o+.o. . |
| ..=+ |
| ..+ |
| ... |
+----[SHA256]-----+
[root@slave0 ~]#
查看我们生成的秘钥对
[root@slave0 ~]# cd .ssh/
[root@slave0 .ssh]# ll
总用量 8
-rw-------. 1 root root 1679 3月 6 14:22 id_rsa
-rw-r--r--. 1 root root 393 3月 6 14:22 id_rsa.pub
[root@slave0 .ssh]#
可以看到,一个名为id_rsa另一个名为id_rsa.pub,其中带pub的是公钥,将id_rsa.pub追加到~/.ssh/authorized_keys文件中,配置免密登录自己,同时验证是否能用
[root@slave0 .ssh]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[root@slave0 .ssh]# ssh slave0
Last login: Sun Mar 6 14:20:19 2022 from 192.168.25.1
[root@slave0 ~]# exit
登出
Connection to slave0 closed.
[root@slave0 .ssh]#
能正常使用,把公钥分发给需要免密登录的机器上去
使用命令scp 文件名 域名/IP地址:目标机器文件存放位置把公钥分别传到slave1和slave2上的root用户目录下
[root@slave0 .ssh]# scp ~/.ssh/id_rsa.pub slave1:~
root@slave1's password:
id_rsa.pub 100% 393 322.5KB/s 00:00
[root@slave0 .ssh]# scp ~/.ssh/id_rsa.pub slave2:~
The authenticity of host 'slave2 (192.168.25.12)' can't be established.
ECDSA key fingerprint is SHA256:brSII1Ii+yIXjzvMWG1Rxn+3vOTolPZq/rJomBVxl00.
ECDSA key fingerprint is MD5:49:0b:71:88:b6:21:4a:b3:c7:ad:79:88:78:0a:1e:5a.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'slave2,192.168.25.12' (ECDSA) to the list of known hosts.
root@slave2's password:
id_rsa.pub 100% 393 385.9KB/s 00:00
[root@slave0 .ssh]#
然后分别到slave1和slave2上启用这个公钥(即把公钥内容追加到~/.ssh/authorized_keys这个文件中,文件默认没有需要先创建)
slave1
[root@slave1 ~]# ls
anaconda-ks.cfg id_rsa.pub
[root@slave1 ~]# mkdir .ssh
[root@slave1 ~]# cd .ssh/
[root@slave1 .ssh]# touch authorized_keys
[root@slave1 .ssh]# cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
[root@slave1 .ssh]#
slave2
[root@slave2 ~]# ls
anaconda-ks.cfg id_rsa.pub
[root@slave2 ~]# mkdir .ssh
[root@slave2 ~]# cd .ssh/
[root@slave2 .ssh]# touch authorized_keys
[root@slave2 .ssh]# cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
[root@slave2 .ssh]#
完成以上操作后,slave0就可以免密码登录到自己、slave1和slave2了
[root@slave0 .ssh]# ssh slave0
Last login: Sun Mar 6 14:21:19 2022 from 192.168.25.1
[root@slave0 ~]# exit
登出
Connection to slave0 closed.
[root@slave0 .ssh]# ssh slave1
Last login: Sun Mar 6 14:17:58 2022 from 192.168.25.1
[root@slave1 ~]# exit
登出
Connection to slave1 closed.
[root@slave0 .ssh]# ssh slave2
Last login: Sun Mar 6 14:18:04 2022 from 192.168.25.1
[root@slave2 ~]# exit
登出
Connection to slave2 closed.
[root@slave0 .ssh]#
按自己的需要看是否需要配置slave1和slave2免密码登录到另外两台机器上,这边我为了方便,配置slave1免密码登录到slave0和slave2,slave2免密码登录到slave0和slave1
配置SSH
如果在刚刚的免密码配置过程中发现用SSH登录到另外的虚拟机会很慢,可以配置一下SSH
会慢的主要原因是CentOS在被远程登录时会去请求DNS验证登录IP以确保安全,但我们在内网使用不必太担心这个问题,反而登录慢会影响效率,这边给它关闭一下SSH的DNS验证
修改文件
修改SSH的配置文件,SSH配置文件路径:/etc/ssh/sshd_config
[root@slave0 ~]# vi /etc/ssh/sshd_config
.
.
.
##ShowPatchLevel no
UseDNS no
##PidFile /var/run/sshd.pid
##MaxStartups 10:30:100
.
.
.
"/etc/ssh/sshd_config" 139L, 3905C written
[root@slave0 ~]#
使用vi的查找功能,把文件中的#UseDNS yes改为UseDNS no
重启SSH
使用命令service sshd restart重启SSH服务
[root@slave0 ~]# service sshd restart
Redirecting to /bin/systemctl restart sshd.service
[root@slave0 ~]#
使用同样的方式按需配置另外两台虚拟机
配置时间同步
运行在Linux上的服务器程序一般对时间的要求比较严格,至少一个集群中的时间应该是同步的
安装ntpdate
配置时间同步需要用到ntpdate,使用命令yum install -y ntpdate安装ntpdate(需要连上互联网)
[root@slave0 ~]# yum install -y ntpdate
已加载插件:fastestmirror
Determining fastest mirrors
* base: mirrors.ustc.edu.cn
.
.
.
已安装:
ntpdate.x86_64 0:4.2.6p5-29.el7.centos.2
完毕!
[root@slave0 ~]#
安装完成
同步时间
使用命令ntpdate -u ntp服务器地址来同步时间,ntp服务器可以在搜索引擎上查询到
下面是我查询到的一部分ntp服务器
国家授时中心 NTP 服务器 ntp.ntsc.ac.cn
中国 NTP 快速授时服务 cn.ntp.org.cn
国际 NTP 快速授时服务 cn.pool.ntp.org
阿里云公共 NTP 服务器 ntp.aliyun.com
腾讯云公共 NTP 服务器 time1.cloud.tencent.com
教育网(高校自建) ntp.sjtu.edu.cn
微软 Windows NTP 服务器 time.windows.com
这边我使用阿里云的ntp.aliyun.com
[root@slave0 ~]# ntpdate -u ntp.aliyun.com
6 Mar 15:02:57 ntpdate[8252]: adjust time server 203.107.6.88 offset 0.017084 sec
[root@slave0 ~]#
同步成功
设置定时任务
每次都手动同步太麻烦了,我们可以设置定时任务,让它每隔一段时间同步一下
向crontab中添加定时任务
在此之前,我们得知道ntpdate的全路径,使用which ntpdate获取ntpdate的全路径
[root@slave0 ~]# which ntpdate
/usr/sbin/ntpdate
[root@slave0 ~]#
写入/etc/crontab,设置10分钟执行一次(时间自定)
[root@slave0 ~]# vi /etc/crontab
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
## For details see man 4 crontabs
## Example of job definition:
## .---------------- minute (0 - 59)
## | .------------- hour (0 - 23)
## | | .---------- day of month (1 - 31)
## | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
## | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
## | | | | |
## * * * * * user-name command to be executed
*/10 * * * * root /usr/sbin/ntpdate -u ntp.aliyun.com
~
~
~
"/etc/crontab" 17L, 503C written
[root@slave0 ~]#
完成
根据以上步骤配置另外两台虚拟机自动同步时间
禁用邮件提醒
配置好时间同步后会发现有这样的一条语句提示您在 /var/spool/mail/root 中有新邮件(或者英文的)
[root@slave0 ~]# ls
anaconda-ks.cfg id_rsa.pub
您在 /var/spool/mail/root 中有新邮件
[root@slave0 ~]#
去掉提醒需要在/etc/profile末尾追加一行unset MAILCHECK,然后更新下环境变量
[root@slave0 ~]# vi /etc/profile
.
.
.
unset i
unset -f pathmunge
unset MAILCHECK
"/etc/profile" 78L, 1836C written
您在 /var/spool/mail/root 中有新邮件
[root@slave0 ~]# source /etc/profile
[root@slave0 ~]#
完成,之后不再提醒有邮件
[root@slave0 ~]# ls
anaconda-ks.cfg id_rsa.pub
[root@slave0 ~]#
其他两台虚拟机按需配置邮件提醒
配置不用./直接执行程序
我们执行程序时需要默认加上./才能执行,不能直接执行
[root@slave0 ~]# vi hello.sh
name=luckydog
echo $name
~
~
~
"hello.sh" [New] 2L, 25C written
[root@slave0 ~]# chmod +x hello.sh
[root@slave0 ~]# hello.sh
-bash: hello.sh: 未找到命令
[root@slave0 ~]# ./hello.sh
luckydog
[root@slave0 ~]#
为了方便,配置文件可以直接执行
- 编辑
/etc/profile文件,在末尾加入环境变量export PATH=.:$PATH
[root@slave0 ~]# vi /etc/profile
.
.
.
unset i
unset -f pathmunge
unset MAILCHECK
## 文件可以直接执行
export PATH=.:$PATH
"/etc/profile" 81L, 1884C written
[root@slave0 ~]#
- 更新环境变量
source /etc/profile
[root@slave0 ~]# source /etc/profile
[root@slave0 ~]#
- 查看效果
[root@slave0 ~]# hello.sh
luckydog
[root@slave0 ~]#
成功
按自己的需要配置另外两台虚拟机
Java环境配置
服务程序大多由Java编写,所以运行时需要有Java环境,这边我使用的是JDK7u79
软件下载
- 打开Oracle官网oracle.com,点击“Products”→“Hardware and Software”→“Java”
- 点击“Download Java”按钮
- 切换到“Java archive”面板
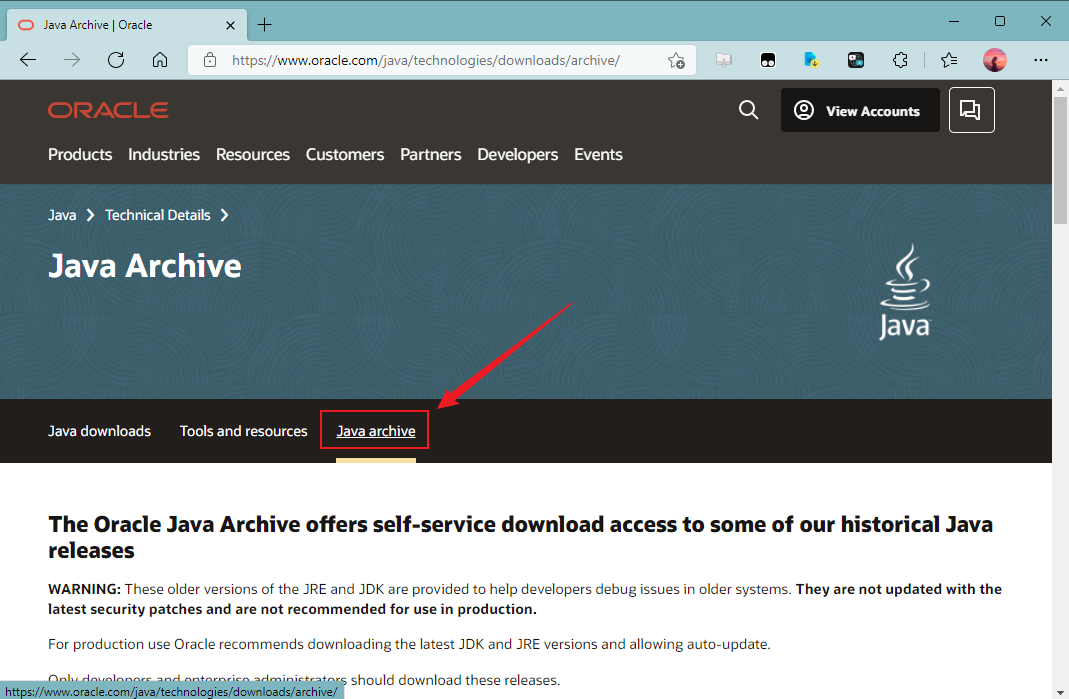
- 往下翻,找到并点击“Java SE 7”
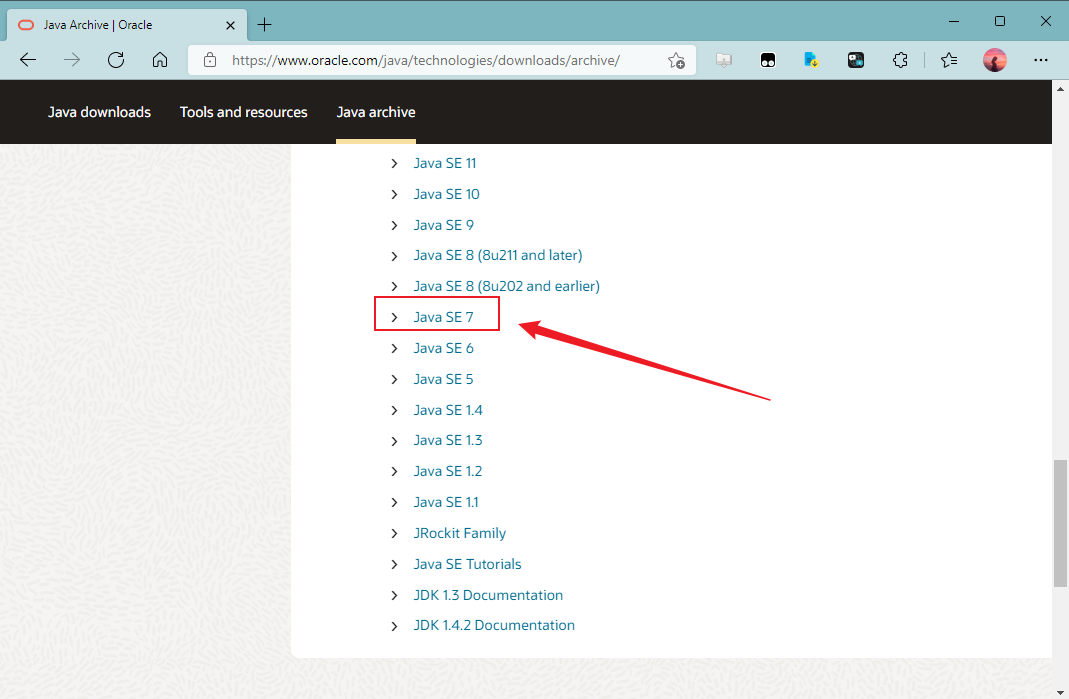
- 找到“Java SE Development Kit 7u79”面板,点击“jdk-7u79-linux-x64.tar.gz”以下载Linux 64位的gz压缩包
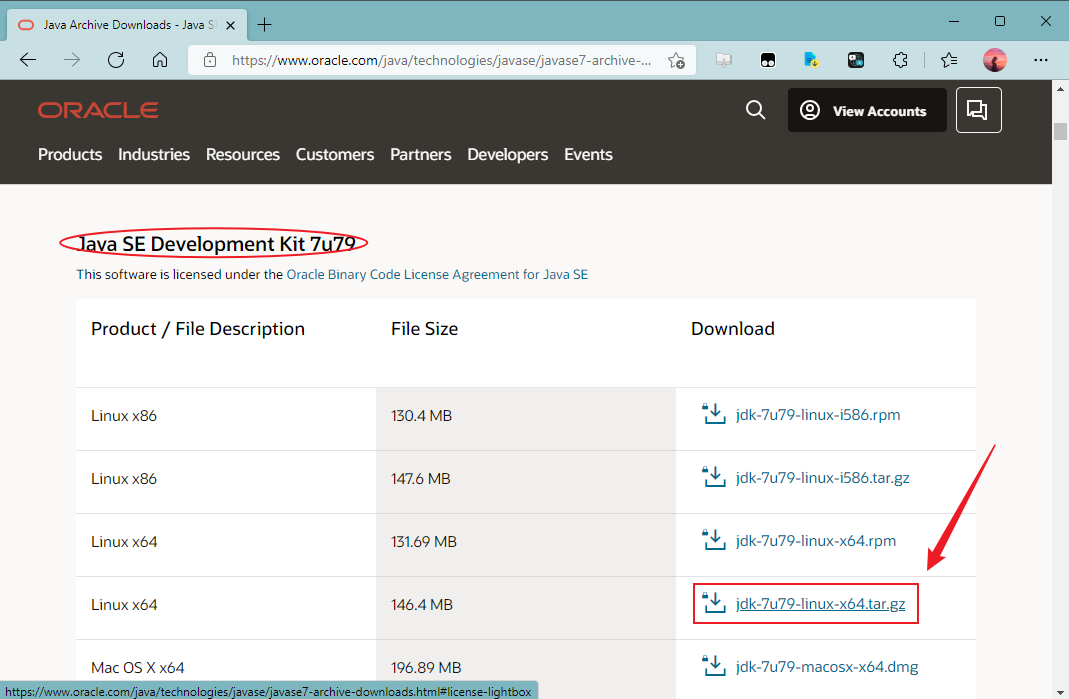
- 勾选“l reviewed and accept the Oracle Binary Code License Agreement for Java SE”(我阅读并接受了Oracle的Java SE二进制代码许可协议)后点击“Download jdk-7u79-linux-x64.tar.gz”
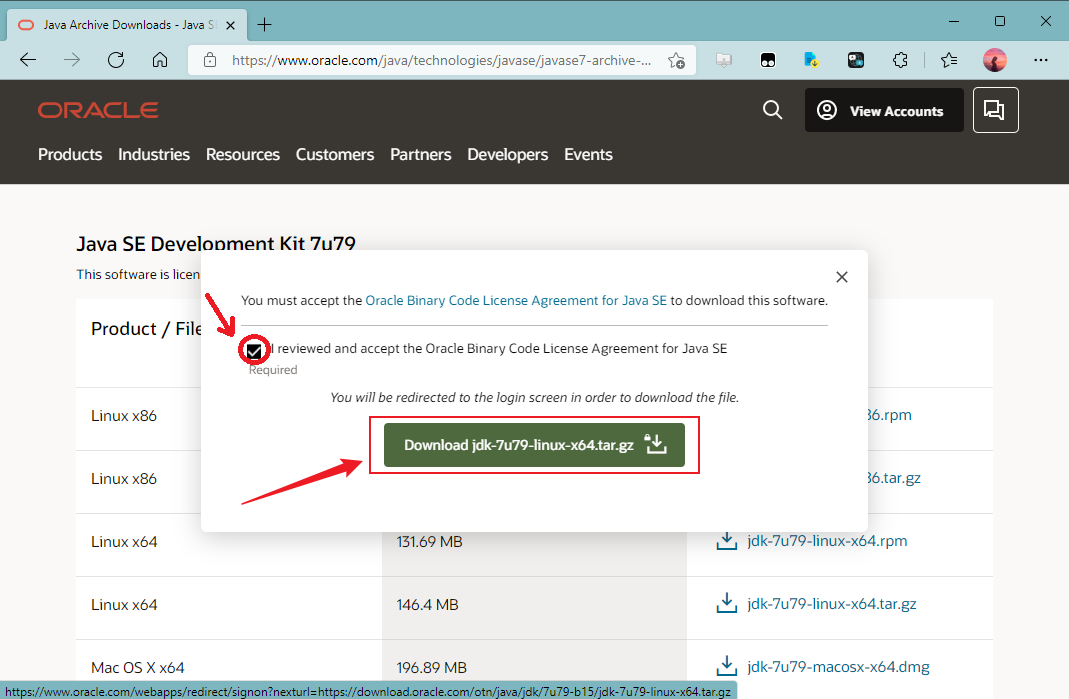
- 需要登录一下,若没有账号可以注册一下
- 之后下载得到一个这样的文件
软件安装
复制安装包到Linux虚拟机上
首先得将软件上传到Linux虚拟机中
- 首先得创建软件存放的目录,计划软件安装包放在
/opt/software中,软件程序放在/opt/module中
[root@slave0 ~]# mkdir -p /opt/software
[root@slave0 ~]# mkdir -p /opt/module
[root@slave0 ~]#
- 在MobaXterm中点击右边的“黄色的地球”在上面的输入框中输入软件存放路径,点击输入框右边的绿色勾勾转到软件存放目录下,把刚刚下载好的JDK的安装包拖进去,拖入时会有一个上传进度条,等其上传完成
- 上传完成后转到软件安装包存放目录查看安装包是否存在(若不存在得重新上传)
[root@slave0 ~]# cd /opt/software/
[root@slave0 software]# ls
jdk-7u79-linux-x64.tar.gz
[root@slave0 software]#
- 解压
jdk-7u79-linux-x64.tar.gz到程序存放目录/opt/module(z:有gzip属性,x:解压,v:显示过程,f:使用档案名,-C:解压到指定目录)
[root@slave0 software]# tar -zxvf jdk-7u79-linux-x64.tar.gz -C /opt/module/
.
.
.
jdk1.7.0_79/db/bin/stopNetworkServer
jdk1.7.0_79/db/README-JDK.html
jdk1.7.0_79/db/NOTICE
jdk1.7.0_79/README.html
jdk1.7.0_79/THIRDPARTYLICENSEREADME.txt
[root@slave0 software]#
环境配置
- 编辑
/etc/profile加入export JAVA_HOME=/opt/module/jdk1.7.0_79和export PATH=$PATH:$JAVA_HOME/bin
[root@slave0 software]# vi /etc/profile
.
.
.
## 文件可以直接执行
export PATH=.:$PATH
## JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.7.0_79
export PATH=$PATH:$JAVA_HOME/bin
"/etc/profile" 85L, 1971C written
[root@slave0 software]#
- 更新环境变量
[root@slave0 software]# source /etc/profile
[root@slave0 software]#
验证
使用命令java -version查看Java版本,若版本正确显示,则配置成功,若无法显示Java版本,则配置失败,需要检查一下
[root@slave0 software]# java -version
java version "1.7.0_79"
Java(TM) SE Runtime Environment (build 1.7.0_79-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)
[root@slave0 software]#
成功
另外两台虚拟机也按如上步骤配置好Java环境
Hadoop集群部署
使用的Hadoop版本为hadoop-2.7.2
需要用到3台虚拟机,节点功能规划如下:
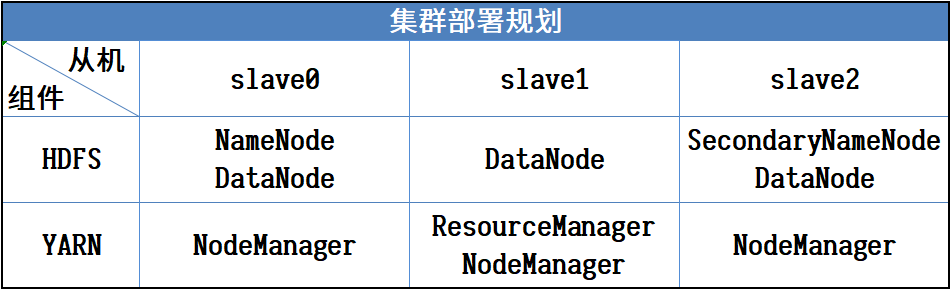
HDFS的NameNode进程运行在slave0上,SecondaryNameNode进程运行在slave2上,三个节点都运行DataNode进程
YARN的ResourceManager进程运行在slave1上,三个节点都运行NodeManager进程
下载
- 打开网址hadoop.apache.org,点击“Download”
- 往下翻,找到并点击“Apache release archive”
- 找到并点击“hadoop-2.7.2/”
- 点击“hadoop-2.7.2.tar.gz”以开始下载Hadoop2.7.2

- 下载后得到这样一个文件
- (可选)为了确保下载正确,可以使用SHA256校验一下
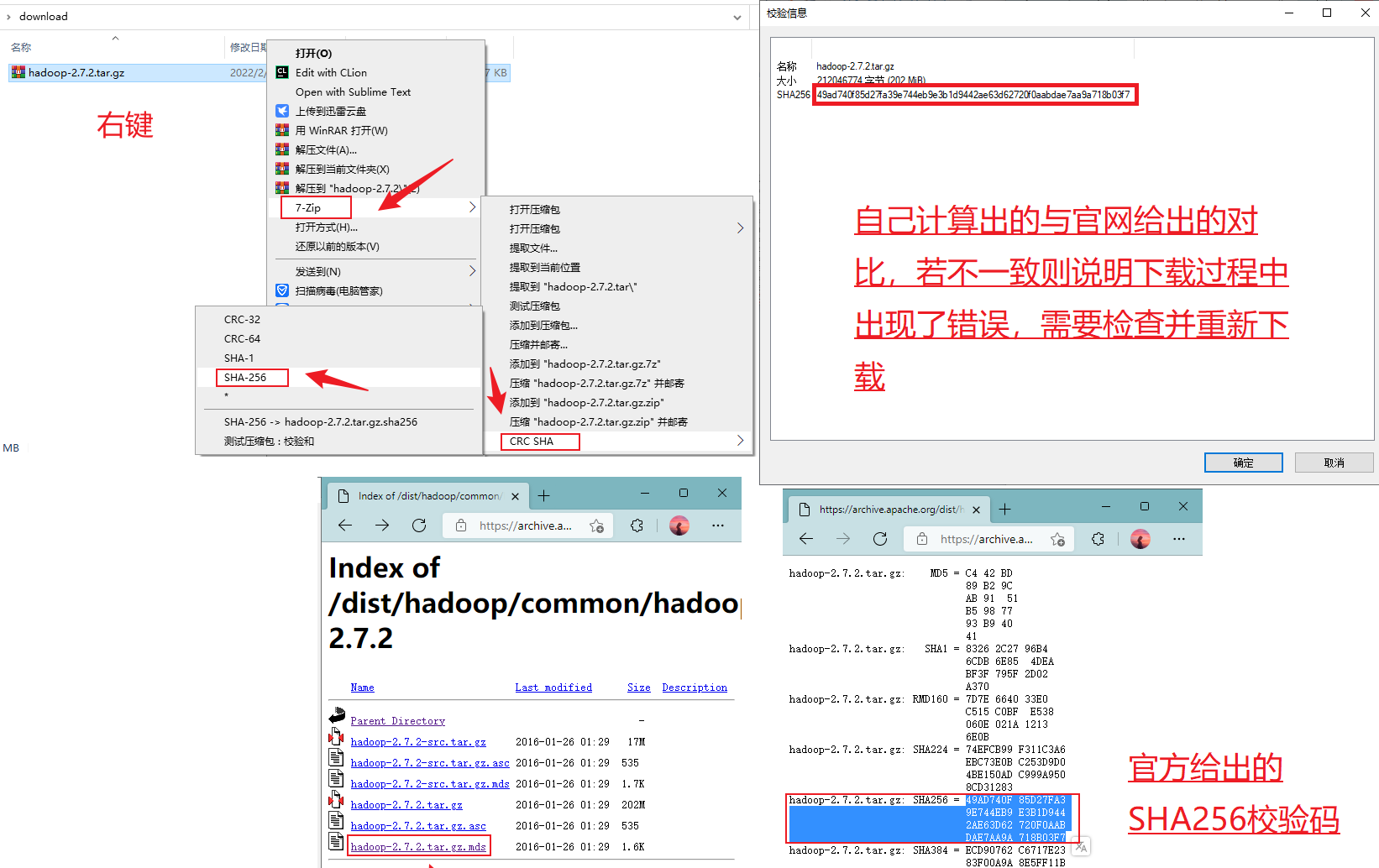
安装
计划软件安装包放在/opt/software中,软件程序放在/opt/module中
- 在MobaXterm中点击右边的“黄色的地球”在上面的输入框中输入软件存放路径,点击输入框右边的绿色勾勾转到软件存放目录下,把刚刚下载好的Hadoop安装包拖进去,拖入时会有一个上传进度条,等其上传完成
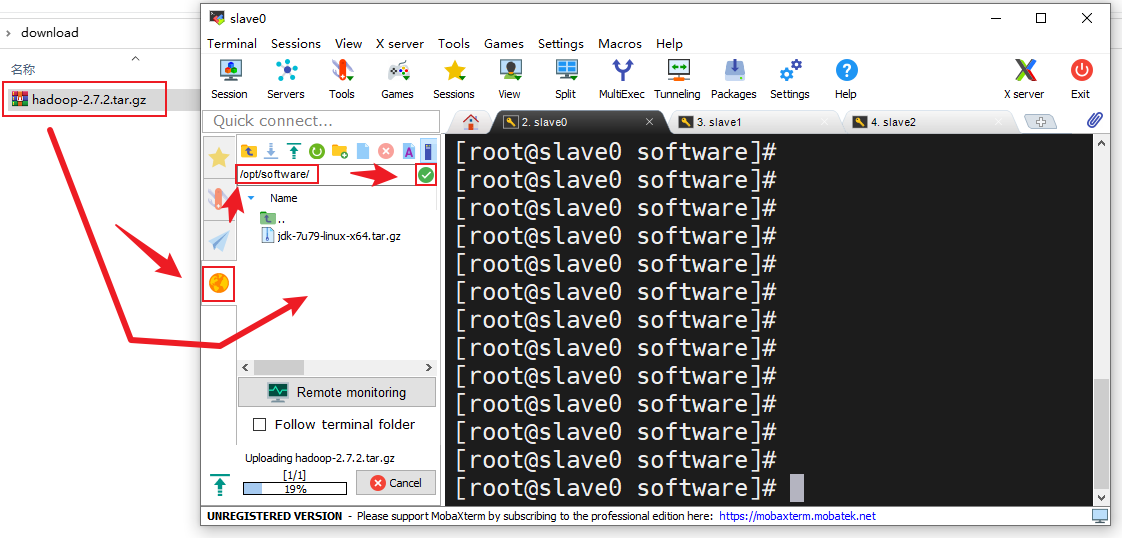
- 上传完成后转到软件安装包存放目录查看安装包是否存在(若不存在得重新上传)
[root@slave0 software]# ls
hadoop-2.7.2.tar.gz
jdk-7u79-linux-x64.tar.gz
[root@slave0 software]#
- 解压
hadoop-2.7.2.tar.gz到程序存放目录/opt/module(z:有gzip属性,x:解压,v:显示过程,f:使用档案名,-C:解压到指定目录)
[root@slave0 software]# tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
.
.
.
hadoop-2.7.2/lib/native/libhadoop.a
hadoop-2.7.2/lib/native/libhdfs.a
hadoop-2.7.2/lib/native/libhadoop.so
hadoop-2.7.2/lib/native/libhadooppipes.a
hadoop-2.7.2/LICENSE.txt
[root@slave0 software]#
配置
环境变量
- 编辑
/etc/profile加入export HADOOP_HOME=/opt/module/hadoop-2.7.2、export PATH=$PATH:$HADOOP_HOME/bin和export PATH=$PATH:$HADOOP_HOME/sbin
[root@slave0 software]# vi /etc/profile
.
.
.
export PATH=$PATH:$JAVA_HOME/bin
## HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
"/etc/profile" 90L, 2101C written
[root@slave0 software]#
- 更新环境变量
[root@slave0 software]# source /etc/profile
[root@slave0 software]#
Hadoop配置
- Hadoop的配置文件都在
/opt/module/hadoop-2.7.2/etc/hadoop/目录下,先跳转到这个目录下
[root@slave0 software]# cd /opt/module/hadoop-2.7.2/etc/hadoop/
[root@slave0 hadoop]#
- 编辑
hadoop-env.sh,在末尾追加Java环境变量配置export JAVA_HOME=/opt/module/jdk1.7.0_79
[root@slave0 hadoop]# vi hadoop-env.sh
.
.
.
## A string representing this instance of hadoop. $USER by default.
export HADOOP_IDENT_STRING=$USER
export JAVA_HOME=/opt/module/jdk1.7.0_79
"hadoop-env.sh" 100L, 4266C written
[root@slave0 hadoop]#
- 编辑
yarn-env.sh,在第一个export语句之前加上Java环境变量配置export JAVA_HOME=/opt/module/jdk1.7.0_79
[root@slave0 hadoop]# vi yarn-env.sh
.
.
.
## WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
## See the License for the specific language governing permissions and
## limitations under the License.
export JAVA_HOME=/opt/module/jdk1.7.0_79
## User for YARN daemons
export HADOOP_YARN_USER=${HADOOP_YARN_USER:-yarn}
.
.
.
"yarn-env.sh" 123L, 4609C written
[root@slave0 hadoop]#
- 编辑
mapred-env.sh,在第一个export语句之前加上Java环境变量配置export JAVA_HOME=/opt/module/jdk1.7.0_79
[root@slave0 hadoop]# vi mapred-env.sh
.
.
.
## See the License for the specific language governing permissions and
## limitations under the License.
export JAVA_HOME=/opt/module/jdk1.7.0_79
## export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
.
.
.
"mapred-env.sh" 29L, 1425C written
[root@slave0 hadoop]#
- 编辑
core-site.xml,在末尾的configuration标签中加入如下配置:
<!-- 指定HDFS中NameNode进程所在的节点信息 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://slave0:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
操作:
[root@slave0 hadoop]# vi core-site.xml
.
.
.
<configuration>
<!-- 指定HDFS中NameNode进程所在的节点信息 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://slave0:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
"core-site.xml" 30L, 1129C written
[root@slave0 hadoop]#
- 编辑
hdfs-site.xml,在末尾的configuration标签中加入如下配置:
<!-- 指定HDFS文件副本数量(集群中有3个从节点,默认为3) -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定HDFS中SecondaryNameNode进程所在的节点信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:50090</value>
</property>
操作:
[root@slave0 hadoop]# vi hdfs-site.xml
.
.
.
<configuration>
<!-- 指定HDFS文件副本数量(集群中有3个从节点,默认为3) -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定HDFS中SecondaryNameNode进程所在的节点信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:50090</value>
</property>
</configuration>
"hdfs-site.xml" 30L, 1146C written
[root@slave0 hadoop]#
- 编辑
yarn-site.xml,在末尾的configuration标签中加入如下配置:
<!-- 设置Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager进程所在的节点信息 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
操作:
[root@slave0 hadoop]# vi yarn-site.xml
.
.
.
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 设置Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager进程所在的节点信息 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
</configuration>
~
~
"yarn-site.xml" 28L, 1041C written
[root@slave0 hadoop]#
- 将
mapred-site.xml.template文件内容写入到mapred-site.xml中
[root@slave0 hadoop]# cat mapred-site.xml.template >> mapred-site.xml
[root@slave0 hadoop]#
- 编辑
mapred-site.xml,在末尾的configuration标签中加入如下配置:
<!-- 指定MapReduce运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
操作:
[root@slave0 hadoop]# vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定MapReduce运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
~
~
~
"mapred-site.xml" 25L, 907C written
[root@slave0 hadoop]#
- 编辑
slaves文件,加入DataNode节点域名
slave0
slave1
slave2
操作:
[root@slave0 hadoop]# vi slaves
slave0
slave1
slave2
~
~
~
"slaves" 3L, 21C written
[root@slave0 hadoop]#
完成
分发
使用命令scp -rq 文件夹 域名/IP地址:目标主机保存位置复制已经配置好的Hadoop到另外两台虚拟机上
[root@slave0 hadoop]# cd /opt/module/
[root@slave0 module]# scp -rq hadoop-2.7.2/ slave1:/opt/module/
[root@slave0 module]# scp -rq hadoop-2.7.2/ slave2:/opt/module/
[root@slave0 module]#
在另外两台虚拟机上检查复制情况
slave1
[root@slave1 ~]# cd /opt/module/
[root@slave1 module]# ll
总用量 0
drwxr-xr-x. 9 root root 149 3月 6 20:37 hadoop-2.7.2
drwxr-xr-x. 8 10 143 233 4月 11 2015 jdk1.7.0_79
[root@slave1 module]#
slave2
[root@slave2 ~]# cd /opt/module/
[root@slave2 module]# ll
总用量 0
drwxr-xr-x. 9 root root 149 3月 6 20:37 hadoop-2.7.2
drwxr-xr-x. 8 10 143 233 4月 11 2015 jdk1.7.0_79
[root@slave2 module]#
完成
启动
- 第一次启动,需要格式化NameNode,在规划好的NameNode主机上的hadoop安装目录下运行命令
bin/hdfs namenode -format
[root@slave0 module]# cd /opt/module/hadoop-2.7.2/
[root@slave0 hadoop-2.7.2]# bin/hdfs namenode -format
22/03/06 20:43:16 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = slave0/192.168.25.10
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.2
.
.
.
22/03/06 20:43:19 INFO namenode.FSImage: Allocated new BlockPoolId: BP-453973894-192.168.25.10-1646570598969
22/03/06 20:43:19 INFO common.Storage: Storage directory /opt/module/hadoop-2.7.2/data/tmp/dfs/name has been successfully formatted.
22/03/06 20:43:19 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
22/03/06 20:43:19 INFO util.ExitUtil: Exiting with status 0
22/03/06 20:43:19 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at slave0/192.168.25.10
************************************************************/
[root@slave0 hadoop-2.7.2]#
如果看到如上的信息有“successfully formatted”即说明格式化成功
22/03/06 20:43:19 INFO common.Storage: Storage directory /opt/module/hadoop-2.7.2/data/tmp/dfs/name has been successfully formatted.
- 在需要启动NameNode进程的虚拟机上启动Hadoop的HDFS,这边是slave0
[root@slave0 hadoop-2.7.2]# cd /opt/module/hadoop-2.7.2/
[root@slave0 hadoop-2.7.2]# sbin/start-dfs.sh
Starting namenodes on [slave0]
slave0: starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-namenode-slave0.out
slave2: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-slave2.out
slave1: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-slave1.out
slave0: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-slave0.out
Starting secondary namenodes [slave2]
slave2: starting secondarynamenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-slave2.out
[root@slave0 hadoop-2.7.2]#
- 在需要启动ResourceManager进程的虚拟机上启动Hadoop的YARN,这边是slave1
[root@slave1 module]# cd /opt/module/hadoop-2.7.2/
[root@slave1 hadoop-2.7.2]# sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-resourcemanager-slave1.out
slave2: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-slave2.out
slave0: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-slave0.out
slave1: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-slave1.out
[root@slave1 hadoop-2.7.2]#
- 分别在三台虚拟机上使用命令
jps检查进程信息是否符合集群部署规划表
slave0
[root@slave0 hadoop-2.7.2]# jps
11911 NameNode
12283 NodeManager
12008 DataNode
12392 Jps
[root@slave0 hadoop-2.7.2]#
slave1
[root@slave1 hadoop-2.7.2]# jps
11076 NodeManager
10974 ResourceManager
11367 Jps
10847 DataNode
[root@slave1 hadoop-2.7.2]#
slave2
[root@slave2 module]# jps
10954 NodeManager
11074 Jps
10766 DataNode
10840 SecondaryNameNode
[root@slave2 module]#
符合集群部署规划表,集群部署成功
ZooKeeper部署
使用的ZooKeeper版本为3.4.10
下载
- 打开网址zookeeper.apache.org,点击Getting Started下的“Download”标签
- 找到“Older releases are available in the archive.”,点击“in the archive”标签
- 往下翻,找到并点击“zookeeper-3.4.10/”
- 点击“zookeeper-3.4.10.tar.gz”以开始下载ZooKeeper 3.4.10
- 下载后得到一个这样的文件

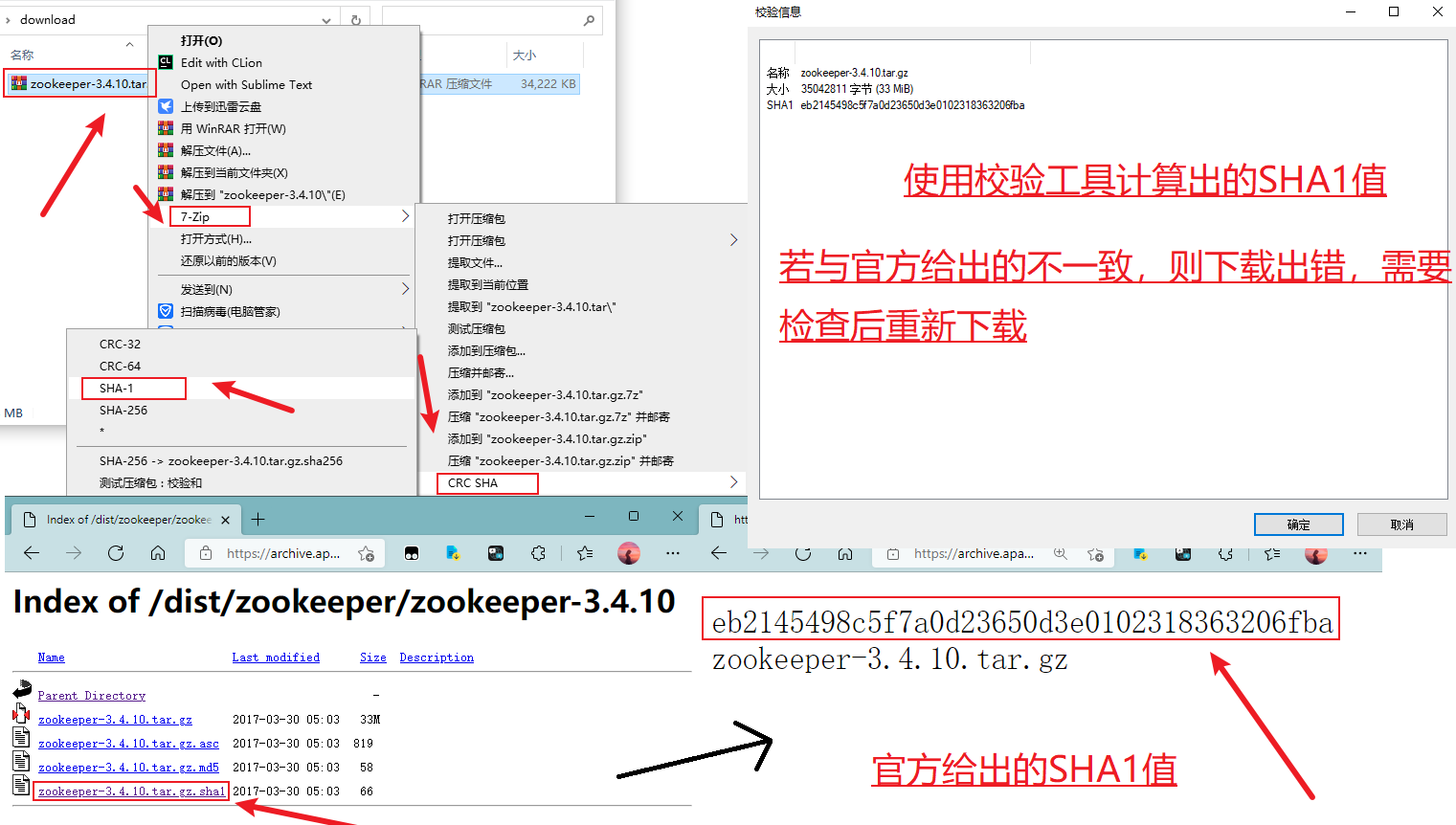
- (可选)为了确保下载正确,可以使用SHA1校验一下
安装
计划软件安装包放在/opt/software中,软件程序放在/opt/module中
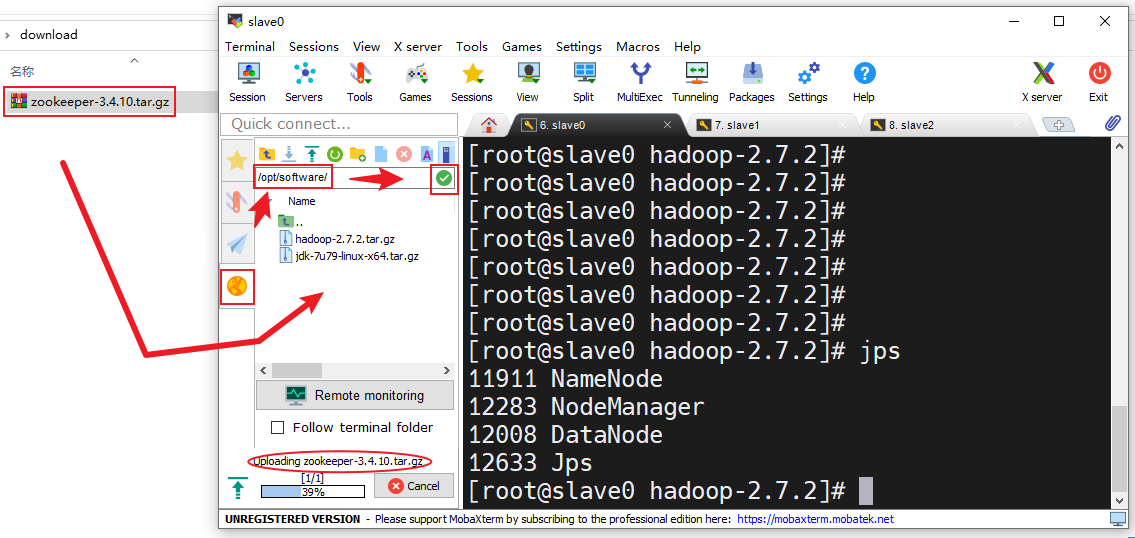
- 在MobaXterm中点击右边的“黄色的地球”在上面的输入框中输入软件存放路径,点击输入框右边的绿色勾勾转到软件存放目录下,把刚刚下载好的ZooKeeper安装包拖进去,拖入时会有一个上传进度条,等其上传完成
- 上传完成后转到软件安装包存放目录查看安装包是否存在(若不存在得重新上传)
[root@slave0 hadoop-2.7.2]# cd /opt/software/
[root@slave0 software]# ll
总用量 391220
-rw-r--r--. 1 root root 212046774 3月 6 17:39 hadoop-2.7.2.tar.gz
-rw-r--r--. 1 root root 153512879 3月 6 16:06 jdk-7u79-linux-x64.tar.gz
-rw-r--r--. 1 root root 35042811 3月 6 21:36 zookeeper-3.4.10.tar.gz
[root@slave0 software]#
- 解压
zookeeper-3.4.10.tar.gz到程序存放目录/opt/module(z:有gzip属性,x:解压,v:显示过程,f:使用档案名,-C:解压到指定目录)
[root@slave0 software]# tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
.
.
.
zookeeper-3.4.10/bin/zkServer.sh
zookeeper-3.4.10/bin/zkCli.cmd
zookeeper-3.4.10/bin/zkEnv.cmd
zookeeper-3.4.10/ivysettings.xml
[root@slave0 software]#
配置
环境变量
- 编辑
/etc/profile加入export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.10和export PATH=$PATH:$ZOOKEEPER_HOME/bin
[root@slave0 software]# vi /etc/profile
.
.
.
export PATH=$PATH:$HADOOP_HOME/sbin
## ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
"/etc/profile" 94L, 2203C written
[root@slave0 software]#
- 更新环境变量
[root@slave0 software]# source /etc/profile
[root@slave0 software]#
ZooKeeper配置
- 创建数据目录,在
/opt/module/zookeeper-3.4.10/目录下创建data/zkData目录
[root@slave0 software]# cd /opt/module/zookeeper-3.4.10/
[root@slave0 zookeeper-3.4.10]# mkdir -p data/zkData
[root@slave0 zookeeper-3.4.10]#
- 复制配置模板文件
/opt/module/zookeeper-3.4.10/conf/zoo_sample.cfg内容到同目录下的zoo.cfg文件中
[root@slave0 zookeeper-3.4.10]# cd conf/
[root@slave0 conf]# cat zoo_sample.cfg >> zoo.cfg
[root@slave0 conf]#
- 修改
zoo.cfg,将其中的dataDir的值改为/opt/module/zookeeper-3.4.10/data/zkData,然后追加如下内容:
## 集群
server.1=slave0:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
操作:
[root@slave0 conf]# vi zoo.cfg
.
.
.
## do not use /tmp for storage, /tmp here is just
## example sakes.
dataDir=/opt/module/zookeeper-3.4.10/data/zkData
## the port at which the clients will connect
clientPort=2181
.
.
.
## 集群
server.1=slave0:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
"zoo.cfg" 33L, 1036C written
[root@slave0 conf]#
- 在
/opt/module/zookeeper-3.4.10/data/zkData/目录下创建一个名为myid的文件,不同的机器给上对应编号,参照刚刚在/opt/module/zookeeper-3.4.10/conf/zoo.cfg文件中追加的关于集群的内容
[root@slave0 conf]# cd /opt/module/zookeeper-3.4.10/data/zkData/
[root@slave0 zkData]# touch myid
[root@slave0 zkData]# vi myid
1
~
~
~
"myid" 1L, 2C written
[root@slave0 zkData]#
比如我的slave0的编号是1,slave1的编号是2,slave2的编号是3
分发
使用命令scp -rq 文件夹 域名/IP地址:目标主机保存位置复制已经配置好的ZooKeeper到另外两台虚拟机上
[root@slave0 zkData]# cd /opt/module/
[root@slave0 module]# scp -rq zookeeper-3.4.10/ slave1:/opt/module/
[root@slave0 module]# scp -rq zookeeper-3.4.10/ slave2:/opt/module/
[root@slave0 module]#
在另外两台虚拟机上检查复制情况,并修改myid文件中的编号
slave1
[root@slave1 hadoop-2.7.2]# cd /opt/module/
[root@slave1 module]# ll
总用量 4
drwxr-xr-x. 11 root root 173 3月 6 20:48 hadoop-2.7.2
drwxr-xr-x. 8 10 143 233 4月 11 2015 jdk1.7.0_79
drwxr-xr-x. 11 root root 4096 3月 6 22:21 zookeeper-3.4.10
[root@slave1 module]# vi /opt/module/zookeeper-3.4.10/data/zkData/myid
2
~
~
~
"zookeeper-3.4.10/data/zkData/myid" 1L, 2C written
[root@slave1 module]#
slave2
[root@slave2 module]# ll
总用量 4
drwxr-xr-x. 11 root root 173 3月 6 20:48 hadoop-2.7.2
drwxr-xr-x. 8 10 143 233 4月 11 2015 jdk1.7.0_79
drwxr-xr-x. 11 root root 4096 3月 6 22:21 zookeeper-3.4.10
[root@slave2 module]# vi /opt/module/zookeeper-3.4.10/data/zkData/myid
3
~
~
~
"zookeeper-3.4.10/data/zkData/myid" 1L, 2C written
[root@slave2 module]#
完成
启动
- 分别在slave0、slave1、slave2上启动ZooKeeper:
slave0
[root@slave0 module]# cd /opt/module/zookeeper-3.4.10/
[root@slave0 zookeeper-3.4.10]# bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@slave0 zookeeper-3.4.10]#
slave1
[root@slave1 module]# cd /opt/module/zookeeper-3.4.10/
[root@slave1 zookeeper-3.4.10]# bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@slave1 zookeeper-3.4.10]#
slave2
[root@slave2 module]# cd /opt/module/zookeeper-3.4.10/
[root@slave2 zookeeper-3.4.10]# bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@slave2 zookeeper-3.4.10]#
- 分别在三台虚拟机上使用命令jps检查进程信息
slave0
[root@slave0 zookeeper-3.4.10]# jps
11911 NameNode
12283 NodeManager
12008 DataNode
13100 Jps
13046 QuorumPeerMain
[root@slave0 zookeeper-3.4.10]#
slave1
[root@slave1 zookeeper-3.4.10]# jps
11076 NodeManager
10974 ResourceManager
11966 QuorumPeerMain
12010 Jps
10847 DataNode
[root@slave1 zookeeper-3.4.10]#
slave2
[root@slave2 zookeeper-3.4.10]# jps
11836 QuorumPeerMain
10954 NodeManager
10766 DataNode
11873 Jps
10840 SecondaryNameNode
[root@slave2 zookeeper-3.4.10]#
都存在QuorumPeerMain进程,成功
HBase部署
使用的HBase版本为1.3.3
下载
- 打开网站:hbase.apache.org,找到并点击“Download”下面的“here”标签
- 翻到网页末尾,找到并点击“Apache Archive”标签
- 往下翻找到并点击“1.3.3/”
- 点击“hbase-1.3.3-bin.tar.gz”以开始下载HBase 1.3.3版安装包
- 下载后得到这样一个文件
安装
计划软件安装包放在/opt/software中,软件程序放在/opt/module中
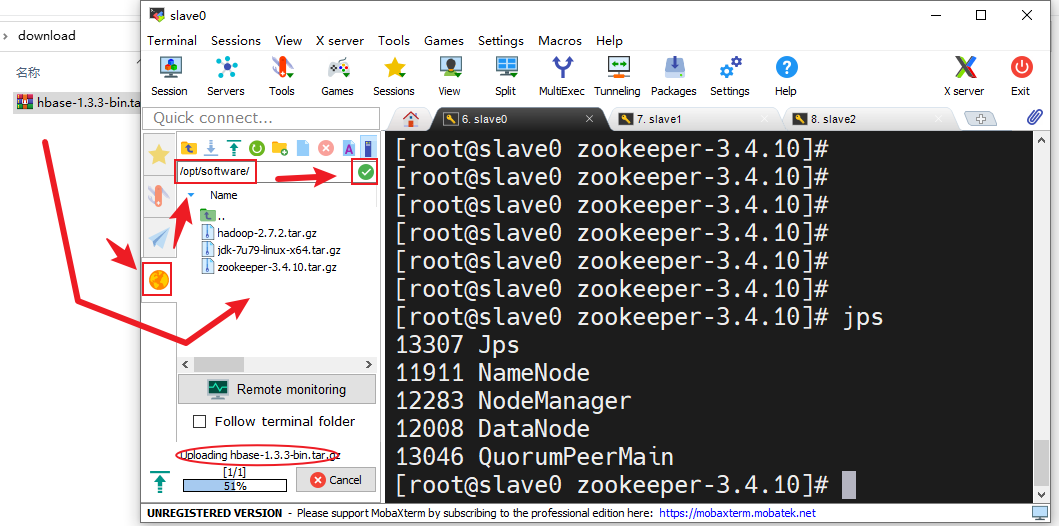
- 在MobaXterm中点击右边的“黄色的地球”在上面的输入框中输入软件存放路径,点击输入框右边的绿色勾勾转到软件存放目录下,把刚刚下载好的HBase安装包拖进去,拖入时会有一个上传进度条,等其上传完成
- 上传完成后转到软件安装包存放目录查看安装包是否存在(若不存在得重新上传)
[root@slave0 zookeeper-3.4.10]# cd /opt/software/
[root@slave0 software]# ll
总用量 496104
-rw-r--r--. 1 root root 212046774 3月 6 17:39 hadoop-2.7.2.tar.gz
-rw-r--r--. 1 root root 107398278 3月 6 22:58 hbase-1.3.3-bin.tar.gz
-rw-r--r--. 1 root root 153512879 3月 6 16:06 jdk-7u79-linux-x64.tar.gz
-rw-r--r--. 1 root root 35042811 3月 6 21:36 zookeeper-3.4.10.tar.gz
[root@slave0 software]#
- 解压
hbase-1.3.3-bin.tar.gz到程序存放目录/opt/module(z:有gzip属性,x:解压,v:显示过程,f:使用档案名,-C:解压到指定目录)
[root@slave0 software]# tar -zvxf hbase-1.3.3-bin.tar.gz -C /opt/module/
.
.
.
hbase-1.3.3/lib/hbase-server-1.3.3-tests.jar
hbase-1.3.3/lib/hbase-it-1.3.3-tests.jar
hbase-1.3.3/lib/hbase-annotations-1.3.3-tests.jar
[root@slave0 software]#
配置
环境变量
- 编辑
/etc/profile加入export HBASE_HOME=/opt/module/hbase-1.3.3和export PATH=$PATH:$HBASE_HOME/bin
[root@slave0 software]# vi /etc/profile
.
.
.
export PATH=$PATH:$ZOOKEEPER_HOME/bin
## HBASE_HOME
export HBASE_HOME=/opt/module/hbase-1.3.3
export PATH=$PATH:$HBASE_HOME/bin
"/etc/profile" 98L, 2298C written
[root@slave0 software]#
- 更新环境变量
[root@slave0 software]# source /etc/profile
[root@slave0 software]#
HBase配置
所有配置文件在/opt/module/hbase-1.3.3/conf/目录,先跳转到这个目录中
[root@slave0 software]# cd /opt/module/hbase-1.3.3/conf/
[root@slave0 conf]#
- 编辑
hbase-env.sh,在文件开始的位置加入export JAVA_HOME=/opt/module/jdk1.7.0_79和export HBASE_MANAGES_ZK=false
[root@slave0 conf]# vi hbase-env.sh
.
.
.
## * See the License for the specific language governing permissions and
## * limitations under the License.
## */
## JDK路径
export JAVA_HOME=/opt/module/jdk1.7.0_79
## 设置使用外置的ZooKeeper
export HBASE_MANAGES_ZK=false
## Set environment variables here.
.
.
.
"hbase-env.sh" 140L, 7628C written
[root@slave0 conf]#
- 编辑
hbase-site.xml,在末尾的configuration标签中加入如下配置:
<!-- 设置最大时钟偏移,以降低对时间同步的要求 -->
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<!-- 指定HDFS实例地址 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://slave0:9000/hbase</value>
</property>
<!-- 启用分布式集群 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- ZooKeeper配置:设置ZooKeeper集群节点 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>slave0,slave1,slave2</value>
</property>
<!-- ZooKeeper配置:设置ZooKeeper数据目录 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4.10/data/zkData</value>
</property>
操作:
[root@slave0 conf]# vi hbase-site.xml
.
.
.
-->
<configuration>
<!-- 设置最大时钟偏移,以降低对时间同步的要求 -->
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<!-- 指定HDFS实例地址 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://slave0:9000/hbase</value>
</property>
<!-- 启用分布式集群 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- ZooKeeper配置:设置ZooKeeper集群节点 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>slave0,slave1,slave2</value>
</property>
<!-- ZooKeeper配置:设置ZooKeeper数据目录 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4.10/data/zkData</value>
</property>
</configuration>
"hbase-site.xml" 49L, 1723C written
[root@slave0 conf]#
- 编辑
regionservers文件,加入HRegionServer节点域名
slave0
slave1
slave2
操作:
[root@slave0 conf]# vi regionservers
slave0
slave1
slave2
~
~
~
"regionservers" 3L, 21C written
[root@slave0 conf]#
- 复制Hadoop的
core-site.xml和hdfs-site.xml这两个配置文件到HBase的conf目录下
[root@slave0 conf]# cd /opt/module/hadoop-2.7.2/etc/hadoop/
[root@slave0 hadoop]# cp core-site.xml /opt/module/hbase-1.3.3/conf/
[root@slave0 hadoop]# cp hdfs-site.xml /opt/module/hbase-1.3.3/conf/
[root@slave0 hadoop]#
完成
分发
使用命令scp -rq 文件夹 域名/IP地址:目标主机保存位置复制已经配置好的HBase到另外两台虚拟机上
[root@slave0 hadoop]# cd /opt/module/
[root@slave0 module]# scp -rq hbase-1.3.3/ slave1:/opt/module/
[root@slave0 module]# scp -rq hbase-1.3.3/ slave2:/opt/module/
[root@slave0 module]#
在另外两台虚拟机上检查复制情况
slave1
[root@slave1 zookeeper-3.4.10]# cd /opt/module/
[root@slave1 module]# ll
总用量 4
drwxr-xr-x. 11 root root 173 3月 6 20:48 hadoop-2.7.2
drwxr-xr-x. 7 root root 160 3月 6 23:40 hbase-1.3.3
drwxr-xr-x. 8 10 143 233 4月 11 2015 jdk1.7.0_79
drwxr-xr-x. 11 root root 4096 3月 6 22:27 zookeeper-3.4.10
[root@slave1 module]#
slave2
[root@slave2 zookeeper-3.4.10]# cd /opt/module/
[root@slave2 module]# ll
总用量 4
drwxr-xr-x. 11 root root 173 3月 6 20:48 hadoop-2.7.2
drwxr-xr-x. 7 root root 160 3月 6 23:40 hbase-1.3.3
drwxr-xr-x. 8 10 143 233 4月 11 2015 jdk1.7.0_79
drwxr-xr-x. 11 root root 4096 3月 6 22:28 zookeeper-3.4.10
[root@slave2 module]#
完成
启动
- 在HBase安装目录下使用命令
bin/start-hbase.sh启动HBase集群
[root@slave0 hbase-1.3.3]# bin/start-hbase.sh
starting master, logging to /opt/module/hbase-1.3.3/logs/hbase-root-master-slave0.out
slave1: starting regionserver, logging to /opt/module/hbase-1.3.3/bin/../logs/hbase-root-regionserver-slave1.out
slave2: starting regionserver, logging to /opt/module/hbase-1.3.3/bin/../logs/hbase-root-regionserver-slave2.out
slave0: starting regionserver, logging to /opt/module/hbase-1.3.3/bin/../logs/hbase-root-regionserver-slave0.out
[root@slave0 hbase-1.3.3]#
- 分别在三台虚拟机上使用命令
jps检查进程信息
slave0
[root@slave0 hbase-1.3.3]# jps
11911 NameNode
13896 HMaster
14685 Jps
12283 NodeManager
12008 DataNode
14456 HRegionServer
13046 QuorumPeerMain
[root@slave0 hbase-1.3.3]#
slave1
[root@slave1 module]# jps
12663 HRegionServer
11076 NodeManager
10974 ResourceManager
12819 Jps
11966 QuorumPeerMain
10847 DataNode
[root@slave1 module]#
slave2
[root@slave2 module]# jps
12852 Jps
11836 QuorumPeerMain
10954 NodeManager
10766 DataNode
10840 SecondaryNameNode
12676 HRegionServer
[root@slave2 module]#
三台虚拟机都有HRegionServer进程,slave0有HMaster进程,成功
