

HBase集群快速部署摘要
HBase快速部署摘要
相关软件版本
系统:CentOS-7-1810
JDK:7u79
Hadoop:2.7.2
ZooKeeper:3.4.10
HBase:1.3.3
静态IP
位置
vi /etc/sysconfig/network-scripts/ifcfg-ens33
内容
BOOTPROTO=static
ONBOOT=yes
DNS1=192.168.56.1
GATEWAY=192.168.56.1
IPADDR=192.168.56.101
BOOTPROTO:IP获取方式,ONBOOT:是否启用,DNS1:网关IP,GATEWAY:网关IP,IPADDR:本机IP
重启服务
service network restart
查看IP
ip addr
防火墙
临时关闭
systemctl stop firewalld
查看状态
systemctl status firewalld
永久关闭
systemctl disable firewalld
查看状态
systemctl list-unit-files | grep firewalld
一般使用临时关闭+永久关闭
主机名
查看
hostname
临时修改
hostname slave0
永久修改
vi /etc/hostname
/etc/hostname中单存一个主机名,一般使用临时关闭+永久关闭
域名解析
文件
vi /etc/hosts
追加
192.168.25.10 slave0
192.168.25.11 slave1
192.168.25.12 slave2
格式:IP(空格)域名
免密登录
生成秘钥
ssh-keygen -t rsa
试验(配置免密登录自己)
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
分发到要免密登录的虚拟机上
scp ~/.ssh/id_rsa.pub slave1:~
scp ~/.ssh/id_rsa.pub slave2:~
要免密登录的虚拟机将公钥追加到authorized_keys 文件中
mkdir .ssh
cd .ssh
touch authorized_keys
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
是生成秘钥的主机能免密登录到接收公钥的主机上
SSH免DNS验证
配置文件
vi /etc/ssh/sshd_config
将UseDNS设置为no,并取消注释
重启SSH服务
service sshd restart
时间同步
安装ntpdate
yum install -y ntpdate
同步时间
ntpdate -u ntp.aliyun.com
设置定时任务
查看路径
which ntpdate
文件
vi /etc/crontab
定时任务配置,10分钟同步一次(追加)
*/10 * * * * root /usr/sbin/ntpdate -u ntp.aliyun.com
禁用邮件提醒
文件
vi /etc/profile
配置(追加)
unset MAILCHECK
更新
source /etc/profile
不用./直接执行程序
文件
vi /etc/profile
配置(追加)
# 文件可以直接执行
export PATH=.:$PATH
更新
source /etc/profile
Java
创建目录/opt/software和/opt/module
mkdir -p /opt/software
mkdir -p /opt/module
上传安装包到/opt/software
解压
tar -zxvf jdk-7u79-linux-x64.tar.gz -C /opt/module/
环境变量/etc/profile(追加)
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.7.0_79
export PATH=$PATH:$JAVA_HOME/bin
更新
source /etc/profile
验证
java -version
Hadoop
规划
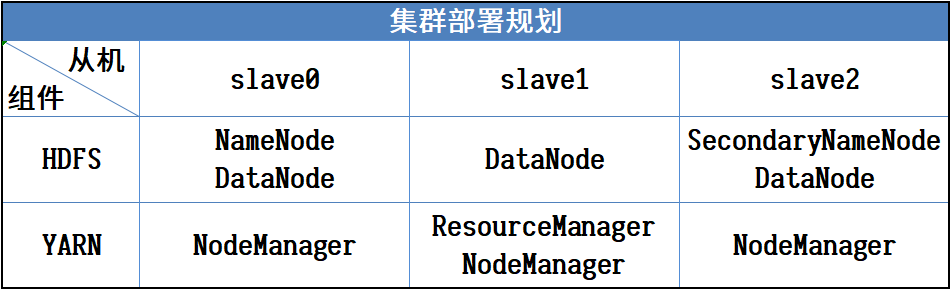
上传安装包到/opt/software
解压
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
环境变量/etc/profile(追加)
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
更新
source /etc/profile
配置文件
配置目录:安装目录/etc/hadoop/
hadoop-env.sh(末尾插入)
yarn-env.sh(前面插入)
mapred-env.sh(前面插入)
export JAVA_HOME=/opt/module/jdk1.7.0_79
core-site.xml
<configuration>
<!-- 指定HDFS中NameNode进程所在的节点信息 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://slave0:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- 指定HDFS文件副本数量(集群中有3个从节点,默认为3) -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定HDFS中SecondaryNameNode进程所在的节点信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:50090</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- 设置Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager进程所在的节点信息 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
</configuration>
mapred-site.xml
复制
cat mapred-site.xml.template >> mapred-site.xml
配置
<configuration>
<!-- 指定MapReduce运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
slaves 文件(添加集群的所有主机的域名)
slave0
slave1
slave2
分发运行
分发
scp -rq /opt/module/hadoop-2.7.2/ slave1:/opt/module/
scp -rq /opt/module/hadoop-2.7.2/ slave2:/opt/module/
格式化(第一次)
bin/hdfs namenode -format
启动
slave0 : HDFS
sbin/start-dfs.sh
slave1 : YARN
sbin/start-yarn.sh
停止
slave1 : YARN
sbin/stop-yarn.sh
slave0 : HDFS
sbin/stop-dfs.sh
ZooKeeper
上传安装包到/opt/software
解压
tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
环境变量/etc/profile(追加)
# ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
更新
source /etc/profile
创建文件夹
在/opt/module/zookeeper-3.4.10/目录下创建data/zkData目录
mkdir -p data/zkData
配置文件
在安装目录/conf文件夹下
复制模板文件
cat zoo_sample.cfg >> zoo.cfg
zoo.cfg
修改
dataDir=/opt/module/zookeeper-3.4.10/data/zkData
在末尾追加
# 集群
server.1=slave0:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
在/opt/module/zookeeper-3.4.10/data/zkData/目录下创建myid文件
cd /opt/module/zookeeper-3.4.10/data/zkData/
touch myid
分发运行
分发时修改/opt/module/zookeeper-3.4.10/data/zkData/目录下的myid文件,就一个编号,分别与zoo.cfg中追加的内容对应,比如:slave0的myid内容就是1,slave1的myid内容就是2
vi /opt/module/zookeeper-3.4.10/data/zkData/myid
分发
scp -rq /opt/module/zookeeper-3.4.10/ slave1:/opt/module/
scp -rq /opt/module/zookeeper-3.4.10/ slave2:/opt/module/
运行
分别在三台虚拟机上ZooKeeper的安装目录里执行
bin/zkServer.sh start
停止
分别在三台虚拟机上ZooKeeper的安装目录里执行
bin/zkServer.sh stop
HBase
上传安装包到/opt/software
解压
tar -zvxf hbase-1.3.3-bin.tar.gz -C /opt/module/
环境变量/etc/profile(追加)
# HBASE_HOME
export HBASE_HOME=/opt/module/hbase-1.3.3
export PATH=$PATH:$HBASE_HOME/bin
更新
source /etc/profile
配置
跳转到/opt/module/hbase-1.3.3/conf/目录
cd /opt/module/hbase-1.3.3/conf/
hbase-env.sh(前面插入)
# JDK路径
export JAVA_HOME=/opt/module/jdk1.7.0_79
# 设置使用外置的ZooKeeper
export HBASE_MANAGES_ZK=false
hbase-site.xml
<configuration>
<!-- 设置最大时钟偏移,以降低对时间同步的要求 -->
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<!-- 指定HDFS实例地址 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://slave0:9000/hbase</value>
</property>
<!-- 启用分布式集群 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- ZooKeeper配置:设置ZooKeeper集群节点 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>slave0,slave1,slave2</value>
</property>
<!-- ZooKeeper配置:设置ZooKeeper数据目录 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4.10/data/zkData</value>
</property>
</configuration>
regionservers 文件(添加集群的所有主机的域名)
slave0
slave1
slave2
复制Hadoop的core-site.xml和hdfs-site.xml到HBase的conf目录下
cp /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml /opt/module/hbase-1.3.3/conf/
cp /opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml /opt/module/hbase-1.3.3/conf/
分发和运行
分发
scp -rq /opt/module/hbase-1.3.3/ slave1:/opt/module/
scp -rq /opt/module/hbase-1.3.3/ slave2:/opt/module/
运行(在NameNode节点主机上,slave0,HBase安装目录下)
bin/start-hbase.sh
停止
bin/stop-hbase.sh
