Python全栈day10(基本数据类型及其常用方法)
一,数字
1,int 将字符串转化成数字
a = '123'
b=int(a)
b=123
2,以进制方式进行转换
num="a"
>>> num = "a"
>>> int (num,base=16)
10
默认base为10不需要加
3,bit_length 当前是数字的二进制位数
>>> age = 3
>>> age.bit_length()
2
>>> age = 8
>>> age.bit_length()
4
PS:在python3里不管数字多大都是int类型
二,字符串
1,capitalize首字母大写
>>> test="zhangsan"
>>> test.capitalize()
'Zhangsan'
2,casefold,lower把大写变成小写 casefold很多未知的对应关系也适用
>>> test="ZHANGSAN"
>>> test.casefold()
'zhangsan'
3,center最少多少个字符,不够字符使用空格代替,也可以使用其他符号代替空格
>>> test.center(8)
'ZHANGSAN'
>>> test.center(9)
' ZHANGSAN'
>>> test.center(10)
' ZHANGSAN '
>>> test.center(11)
' ZHANGSAN '
>>> test.center(10,'*')
'*ZHANGSAN*'
4,count计算子序列在字符串中出现的次数,可以加数字代表从第几位开始寻找
>>> test.count('Z')
1
5,endswith判断是否已上门结尾 startswith
>>> test.endswith('a')
False
>>> test.endswith('N')
True
6,find从开始往后找,找到以后获取位置号(以0开始)
>>> test.find('H')
1
>>> test.find('A')
2
7,format字符串格式化,将字符串中的占位符替换成指定的值
>>> test = 'i am {name}'
>>> test.format(name='zhangsan')
'i am zhangsan'
>>> test = 'i am {0},age={1}'
>>> test.format('zhangsan',19)
'i am zhangsan,age=19'
8,format_map以字典方式格式
>>> test
'i am {name}'
>>> test.format_map({"name":"zhangshan"})
'i am zhangshan'
9.index 功能类似于find如果与find不同的是如果没有找到直接报错
10,isalnum判断字符串是否只是包含字母和数字
>>> 'asd'.isalnum()
True
>>> 'asd_+'.isalnum()
False
10,expandtabs以指定的数为分割数遇到tab使用分割的数用空格补齐
test = "12345678\t9"
v = test.expandtabs(6)
print(v,len(v))
12345678 9 13
说明:以6个单位分割123456为一组,78遇到tab了使用空格补齐4位 然后是9总长度是13,用途产生一个对齐的表格
vim day10-3.py
test = "username\tmail\tpassword\nlaiying\tying@qq.com\t123\nlaiying\tying@qq.com\t123\nlaiying\tying@qq.com\t123" v = test.expandtabs(20) print(v)
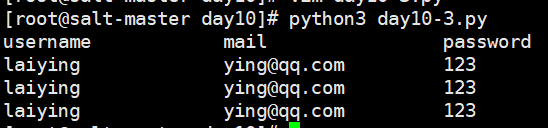
\n是换行因为所有对应的字符串长度不超过20使用该方法生成一个对齐的表格
11,isalpha判断是否是字母,如果全是字母返回True如果包含数字或者其他字符返回False
12,isdecimal 和isdigit判断是否为数字
test = "111"
v1 = test.isdecimal()
v2 = test.isdigit()
print(v1,v2)
isdigit可以识别非纯数字例如②③这样的
13,isidentifier判断字符串是否是合法的标识符,如果是是数字字母下划线但是不能以数字开头的字符串及为True否则为False
14,islower是否全是小写
15,isnumeric判断是否是数字支持中文的
test = "二" v1 = test.isdecimal() v2 = test.isdigit() v3 = test.isnumeric() print(v1,v2,v3) False False True
16,isprintable 判断是否存在不可显示的字符 如果里面是全字符不包含\t \n等则返回True否则返回False
17,isspace是否为空格如果是全部空格或者为空返回True否则返回False
18,istitle判断是否为标题,全部首字母为大写就认为是标题,不支持中文
test ="I Love You" v =test.istitle() print(v)
True
19,join(重要)将字符串中的每一个元素安装指定分隔符进行拼接,join在内部循环字符串一个个拿到然后加入对应的字符
test ="我爱北京天安门" t = '*' v = t.join(test) print(v)
我*爱*北*京*天*安*门
20,ljust和rjust使用指定字符填充一个是把原字符串放左边一个是把原字符串放右边
test ="zhangsan" v1 = test.ljust(20,"*") v2 = test.rjust(20,"*") print(v1,v2) zhangsan************ ************zhangsan
21,lstrip,rstrip,strip(重要)去除字符串里面左边,右边,所有的空格,可以去除制表符换行的空格,默认是去除空格也可以加参数去掉对应的字符,优先最多匹配
test ="xxzhangsan "
v1 = test.lstrip('x')
print(v1)
zhangsan
22,maketrans按照对应关系进行替换
v = "wo ai ni "
m = str.maketrans("aeiou","12345")
new_v = v.translate(m)
print(new_v)
w4 13 n3
23,partition,rpartition使用指定的字符或者字符串分割成三分形成元祖,只能分成三段,r代表从右往左
test ="testasdsddfg"
v1 = test.partition('s')
v2 = test.rpartition('s')
print(v1,v2)
('testasdsddfg', '', '') ('testasd', 's', 'ddfg')
24,split使用指定字符或者字符串分割字符串形成列表,但是不包含这个字符本身,可以加参数分割几次
test ="testasdsddfg"
v1 = test.partition('s')
v2 = test.rpartition('s')
v3 = test.split('s')
print(v1,v2,v3)
('te', 's', 'tasdsddfg') ('testasd', 's', 'ddfg') ['te', 'ta', 'd', 'ddfg']
25,splitlines使用换行符分割,加参数True转换的包含换行符\n False去掉换行符
test ="testasdsddfg\nasjdg\nakjshd" v = test.splitlines() ['testasdsddfg', 'asjdg', 'akjshd']
test ="testasdsddfg\nasjdg\nakjshd" v = test.splitlines(True) print(v) ['testasdsddfg\n', 'asjdg\n', 'akjshd']
26,startwith,endwith判断字符串是否以什么开头或者以什么结尾
test ="backend 1.1.1."
v = test.startswith('a')
print(v)
False
27,swapcase大小写互相转换
test ="I Love U" v = test.swapcase() print(v) i lOVE u
28,title把一串字符串转换成标题,及首字母大写
test ="who are U" v = test.title() print(v) Who Are U
29,replace把指定字符串替换成指定字符串
test = 'abcd'
v = test.replace("a","b")
print(v)
bbcd
七个重要的
join split find strip upper lower replace
字符串的索引或者下标,获取字符串中的某一个字符
索引是以0开始的,如果需要取一串可以使用类似0:2这种索引方式 -1代表最后一位
test = "abcd" v1 = test[0] v2 = test[0:2] v3 = test[0:-1] print(v1,v2,v3) a ab abc
len取字符串的长度(python3支持中文python2.7取的不准确)len可以计算列表计算的是以逗号分隔的个数
range生成一段顺序数字,python2和python3不同,在2里面直接生成一串在3里面不创建,只有在使用循环的时候才创建
python2
>>> range(100) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]
python3
>>> range(100) range(0, 100)
字符串的特点
一个字符串一旦创建在内存里就无法修改,如果修改或者拼接会开辟新的空间重新生成字符串
使用id可以查看占用的内存地址
name = "zhangsan" age = "18" info = name + age print(info) print(id(name),id(age),id(info)) 2266215383344 2266213210016 2266215383408
三,列表
#中括号括起来以,号分割
#列表元素可以是数字,字符串也可以是列表
#可以使用索引取值,切片取值为列表
#列表元素不同于字符串是可以被修改的,在内存里面是连续的
1,修改列表
li[0] = xxx 修改多个 li[1:3] = [120,90]
2,删除
del li[1]
3,list 把字符串转换成列表,把字符串的每一个字符转换成列表的元素
s = 'akjsdhsajkdhjkahsda' new_li = list(s) print(new_li) ['a', 'k', 'j', 's', 'd', 'h', 's', 'a', 'j', 'k', 'd', 'h', 'j', 'k', 'a', 'h', 's', 'd', 'a']
列表转换成字符串(使用for循环实现)
li = [11,22,33,'123','zhangsan'] s = '' for item in li: s += str(item) print(s)
112233123zhangsan
如果列表里面没有数字则可以使用join方法
li = ['11','22','33','123','zhangsan'] v = ''.join(li) print(v) 112233123zhangsan
4,append在列表尾部添加一个元素,在原值后面追加不会有返回值所以返回为None原列表追加了
li = [1,2,3] v = li.append(4) print(v) print(li) None [1,2,3,4]
5,clear清空列表
li = [1,2,3] v = li.clear() print(li) []
6,copy拷贝,浅拷贝
li = [1,2,3] v = li.copy() print(v) [1,2,3]
7,count计算里面包含元素的个数,2出现了1次
li = [1,2,3] v = li.count(2) print(v) 1
8,extend可迭代追加(对象可以是字符串,列表,元祖等所有可迭代的对象)
li = [1,2,3,4] li.extend([5,6]) print(li) [1,2,3,4,5,6]
于append不同在于该方法把对象迭代后追加,看对比,append把所有当成是一个元素追加
li = [1,2,3,4] li.append([5,6]) print(li) [1, 2, 3, 4, [5, 6]]
9,index查找索引位置(从左优先)
li = [11,22,33,22,44] v = li.index(22) print(v) 1
10,insert在指定索引位置插入元素
li = [11,22,33,22,44] li.insert(0,99) print(li) [99, 11, 22, 33, 22, 44]
10,pop删除元素,不加参数默认删除最后一个,返回值为删除的值,加参数代表删除某一个索引li = [11,22,33,22,44]v = li.pop()
print(li) print(v)
[11, 22, 33, 22]
44
11,remove根据value删除(从左优先),没有返回值
li = [11,22,33,22,44] v = li.remove(33) print(li) print(v) [11, 22, 22, 44] None
12,reverse反转
li = [11,22,33,22,44] v = li.reverse() print(li) print(v) [44, 22, 33, 22, 11] None
13,sort排序,
li = [11,22,33,22,44] v = li.sort() print(li) print(v) [11, 22, 22, 33, 44] None
从大往小排序
li = [11,22,33,22,44] v = li.sort(reverse=True) print(li) print(v) [44, 33, 22, 22, 11] None
PS:列表是有序的可以被修改的
四,元祖
#对应的类是tuple
#是对列表的加工
#元素不可被修改,增加或者删除
#一般在定义元祖的时候在最后加一个,(推荐)
#元祖同列表一样可以通过索引及切片取元素,也可以通过for循环迭代
1,字符串和列表转换成元祖
s = 'asdasd' li = ['asdf',123] v1 = tuple(s) v2 = tuple(li) print(v1,v2) ('a', 's', 'd', 'a', 's', 'd') ('asdf', 123)
2,元祖转换成列表
tu = ("asdf","as") v = list(tu) print(v) ['asdf', 'as']
3,元祖如果里面没有保护数字可以使用join方法转换成字符串,如果有数字需要通过for循环转换成字符串
4,元祖元素不能修改,但是元素里面如果包含可修改的元素则可以修改
tu = ("asdf","12",[1,2]) tu[2][0] = 2 print(tu) ('asdf', '12', [2, 2])
5,元祖因为不能修改方法比列表少,count统计里面包含元素的个数,index获取索引位置
五,字典
#创建一个字典对象
info = {'k1':'v1','k2':'v2'}
#k1和v1组成一个键值对,key对应value 字典的value可以是任何值
#key可以是字符串,数字,元祖并且同一个字典key是唯一的
#布尔值True和False也可以作为key但是如果有其他key的值为1则会重复
info = { 'k1':'1', 'k2':2, True:3, False:4 } print (info) {False: 4, 'k1': '1', 'k2': 2, True: 3}
#字典是无序的,获取元素的方法是通过key不是通过有序的数字索引,因为是无序的所以不能通过切片方式取元素
1,删除del del info['k1']
info = {
'k1':'1',
'k2':2
}
del info['k1']
print(info)
{'k2': 2}
2,字典是可以使用for循环的,默认循环是所有key,如果需要循环value可以循环for item in info.values()
需要循环key和value则是info.items()
info = { 'k1':'1', 'k2':2 } for item in info: print(item)
k1
k2
3,clear清除
4,copy复制,浅复制
5,fromkeys格式化生成字典,每一个元素迭代作为key,并且指定统一的value
v = dict.fromkeys(['k1', 'k2', 'k3'], 123) print(v) {'k3': 123, 'k1': 123, 'k2': 123}
6,get取的key存在则返回对应的value,当key不存在时可以指定返回值,默认是None
dic = { "k1":"v1" } v = dic.get('k1') print (v) v1
7,pop根据key删除返回为删除的value,pop需要加参数
dic = { "k1":"v1" } v = dic.pop('k1') print (v,dic) v1 {}
8,popitem随机删除一个键值对,返回值为删除的键值对组成的元祖
dic = { "k1":"v1", "k2":"v2" } v = dic.popitem() print (v,dic)
('k1', 'v1') {'k2': 'v2'}
9,setdefault设置值如果已经存在则不设置并且获取当前key对应的值,如果不存在新加一个键值对
dic = { "k1":"v1", "k2":"v2" } v = dic.setdefault('k1',123) print (dic,v) {'k2': 'v2', 'k1': 'v1'} v1
10,update更新已经存在的更新,不存在的新建键值对
dic = { "k1":"v1", "k2":"v2" } v = dic.update({'k1':123,'k3':123}) print (dic,v) {'k3': 123, 'k2': 'v2', 'k1': 123} None
以上的另外一种更加方便的写法,直接使用key等于value赋值,效果是一样的
dic = { "k1":"v1", "k2":"v2" } v = dic.update(k1=123,k3=123) print (dic,v)
11,字典里面用的最多是是keys,values,items,update
小结整理:
#数字
#int(..)
#字符串
replace/find/join/strip/startwith/split/upper/lower/format
tempalte = "I am {name},age:{age}" v1 = tempalte.format(name='zhangsan',age=19) v2 = tempalte.format(**{"name":'zhangsan','age':19}) print (v1,v2)
#列表
#apend,extend,insert
#索引,切片,循环
#元祖
#字典
get/update/keys/values/items
字典可以使用in判断是否在里面,默认是key如果是要判断value则使用values
六,布尔值
使用bool(..)转换成布尔值
假的False None ,“ ”,(),[],{},0这些都是False其他的都是真的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号