本地文生图模型flux搭建
参考
https://blog.csdn.net/engchina/article/details/140892356
引言
2024年8月1日,blackforestlabs.ai发布了 FLUX.1 模型套件。
FLUX.1 文本到图像模型套件,该套件定义了文本到图像合成的图像细节、提示依从性、样式多样性和场景复杂性的新技术。
为了在可访问性和模型功能之间取得平衡,FLUX.1 有三种变体:FLUX.1 [pro]、FLUX.1 [dev] 和 FLUX.1 [schnell]:
- FLUX.1 [pro]:FLUX.1 的佼佼者,提供最先进的性能图像生成,具有顶级的提示跟随、视觉质量、图像细节和输出多样性。在此处通过我们的 API 注册 FLUX.1 [pro] 访问权限。FLUX.1 [pro] 也可通过 Replicate 和 fal.ai 获得。
- FLUX.1 [dev]:FLUX.1 [dev] 是一个用于非商业应用的开放权重、指导蒸馏模型。FLUX.1 [dev] 直接从 FLUX.1 [pro] 蒸馏而来,获得了相似的质量和快速粘附能力,同时比相同尺寸的标准模型效率更高。FLUX.1 [dev] 权重在 HuggingFace 上可用,可以直接在 Replicate 或 Fal.ai 上试用。
- FLUX.1 [schnell]:我们最快的模型是为本地开发和个人使用量身定制的。FLUX.1 [schnell] 在 Apache2.0 许可下公开可用。类似,FLUX.1 [dev],权重在Hugging Face上可用,推理代码可以在GitHub和HuggingFace的Diffusers中找到。
1. 本地部署
1.1 创建虚拟环境
前提已经安装好conda
# conda create -n flux python=3.11 -y
# conda activate flux
1.2 安装依赖模块
下载代码并安装依赖模块
# git clone https://github.com/black-forest-labs/flux; cd flux
# pip install -e '.[all]'
# pip install accelerate
# pip install git+https://github.com/huggingface/diffusers.git
# pip install optimum-quanto
# pip install gradio
1.3 创建Web UI
python文件如下
# cat flux_on_potato.py
import torch
import gradio as gr
from optimum.quanto import freeze, qfloat8, quantize
from diffusers import FlowMatchEulerDiscreteScheduler, AutoencoderKL
from diffusers.models.transformers.transformer_flux import FluxTransformer2DModel
from diffusers.pipelines.flux.pipeline_flux import FluxPipeline
from transformers import CLIPTextModel, CLIPTokenizer,T5EncoderModel, T5TokenizerFast
dtype = torch.bfloat16
# schnell is the distilled turbo model. For the CFG distilled model, use:
# bfl_repo = "black-forest-labs/FLUX.1-dev"
# revision = "refs/pr/3"
#
# The undistilled model that uses CFG ("pro") which can use negative prompts
# was not released.
bfl_repo = "black-forest-labs/FLUX.1-schnell"
revision = "refs/pr/1"
# bfl_repo = "black-forest-labs/FLUX.1-dev"
# revision = "main"
scheduler = FlowMatchEulerDiscreteScheduler.from_pretrained(bfl_repo, subfolder="scheduler", revision=revision)
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14", torch_dtype=dtype)
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14", torch_dtype=dtype)
text_encoder_2 = T5EncoderModel.from_pretrained(bfl_repo, subfolder="text_encoder_2", torch_dtype=dtype, revision=revision)
tokenizer_2 = T5TokenizerFast.from_pretrained(bfl_repo, subfolder="tokenizer_2", torch_dtype=dtype, revision=revision)
vae = AutoencoderKL.from_pretrained(bfl_repo, subfolder="vae", torch_dtype=dtype, revision=revision)
transformer = FluxTransformer2DModel.from_pretrained(bfl_repo, subfolder="transformer", torch_dtype=dtype, revision=revision)
# Experimental: Try this to load in 4-bit for <16GB cards.
#
# from optimum.quanto import qint4
# quantize(transformer, weights=qint4, exclude=["proj_out", "x_embedder", "norm_out", "context_embedder"])
# freeze(transformer)
quantize(transformer, weights=qfloat8)
freeze(transformer)
quantize(text_encoder_2, weights=qfloat8)
freeze(text_encoder_2)
pipe = FluxPipeline(
scheduler=scheduler,
text_encoder=text_encoder,
tokenizer=tokenizer,
text_encoder_2=None,
tokenizer_2=tokenizer_2,
vae=vae,
transformer=None,
)
pipe.text_encoder_2 = text_encoder_2
pipe.transformer = transformer
pipe.enable_model_cpu_offload()
def generate(prompt, steps, guidance, width, height, seed):
if seed == -1:
seed = torch.seed()
generator = torch.Generator().manual_seed(int(seed))
image = pipe(
prompt=prompt,
width=width,
height=height,
num_inference_steps=steps,
generator=generator,
guidance_scale=guidance,
).images[0]
return image
demo = gr.Interface(fn=generate, inputs=["textbox", gr.Number(value=4), gr.Number(value=3.5), gr.Slider(0, 1920, value=1024, step=2), gr.Slider(0, 1920, value=1024, step=2), gr.Number(value=-1)], outputs="image")
demo.launch(server_name="0.0.0.0")
默认使用模型FLUX.1-schnell启动如果需要使用FLUX.1-dev则修改
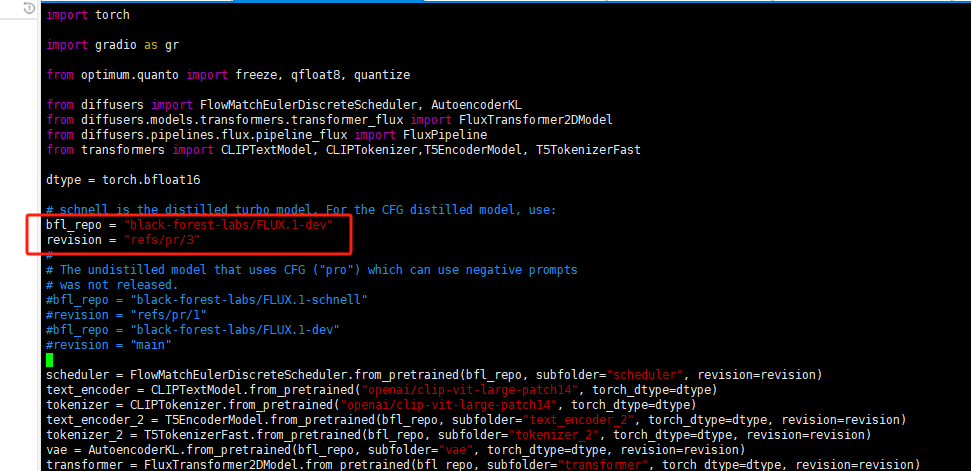
会提示无法下载模型需要注册huggingface.co账号并获取一个token
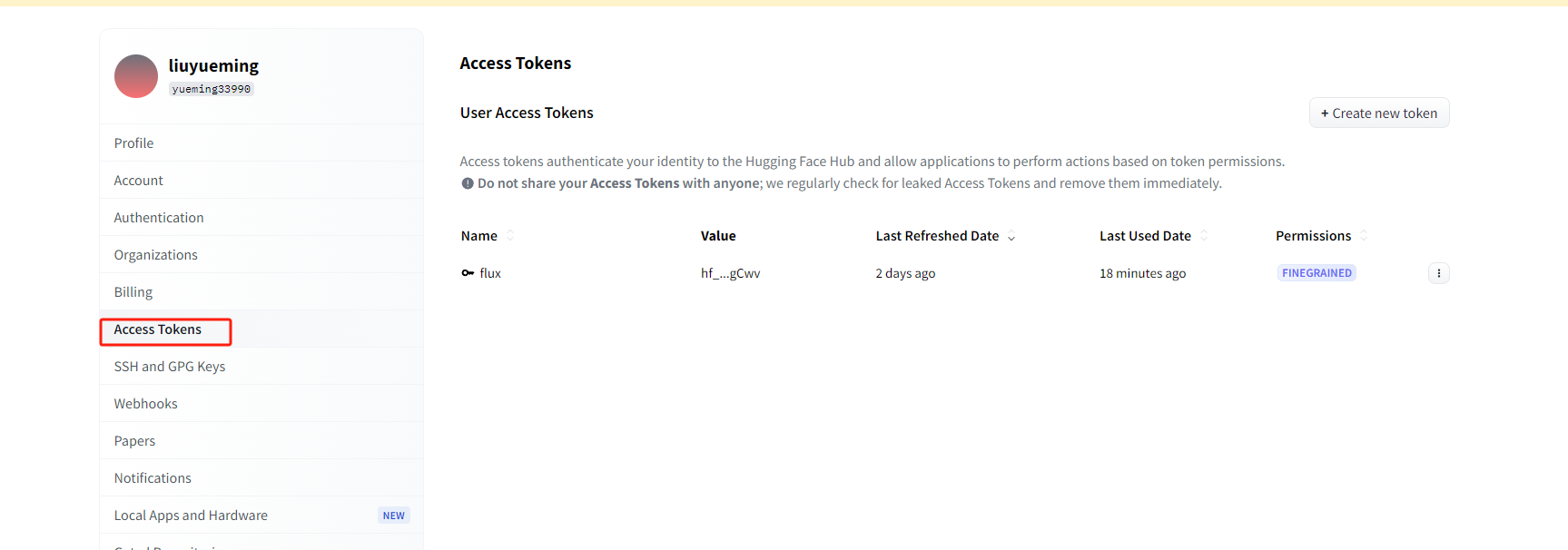
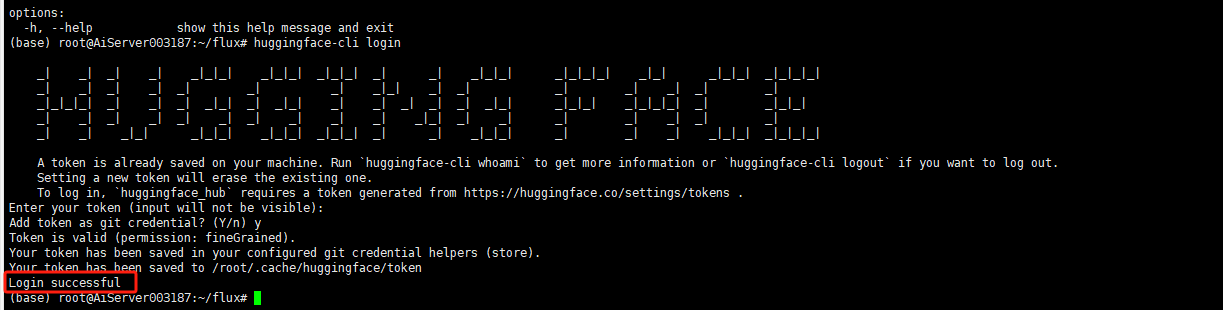
使用token登录
# huggingface-cli login

登录成功即可下载
1.4 启动Web UI
# python flux_on_potato.py
自动下载权重,需要较长时间
1.5 访问Web UI
# http://ip:7860

 浙公网安备 33010602011771号
浙公网安备 33010602011771号