Python怎么通过url下载网络文件到本地
以下代码演示Python怎么从网络下载一个文件至本地并保存在当前文件夹download
import os
import requests
from urllib.parse import urlparse
def download_file(url):
response = requests.get(url, stream=True)
response.raise_for_status()
download_dir = 'download'
os.makedirs(download_dir, exist_ok=True)
file_name = os.path.basename(urlparse(url).path)
print("下载文件名是",file_name)
file_path = os.path.join(download_dir, file_name)
print("下载文件路径是",file_path)
with open(file_path, 'wb') as file:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
file.write(chunk)
print(f'文件下载完成: {file_path}')
url = 'https://www.example.com/example.pdf'
file_path = 'download'
download_file(url)
在这个示例代码中,我们使用了urllib.parse.urlparse函数来解析URL,然后使用os.path.basename函数提取URL路径中的文件名。
然后,我们将文件保存到以文件名命名的文件路径中,并将其放在一个名为download的文件夹下。
请注意,使用这种方法来提取文件名并不总是可靠的,因为URL可能不包含文件扩展名,或者URL可能没有明确的文件名。在某些情况下,你可能需要进一步处理文件名以确保正确性。
注意:如果下载https链接并且对方的证书不是权威证书则会出现以下报错
requests.exceptions.SSLError: HTTPSConnectionPool(host='192.168.8.97', port=443): Max retries exceeded with url: /start_read_original.wav (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate (_ssl.c:1002)')))
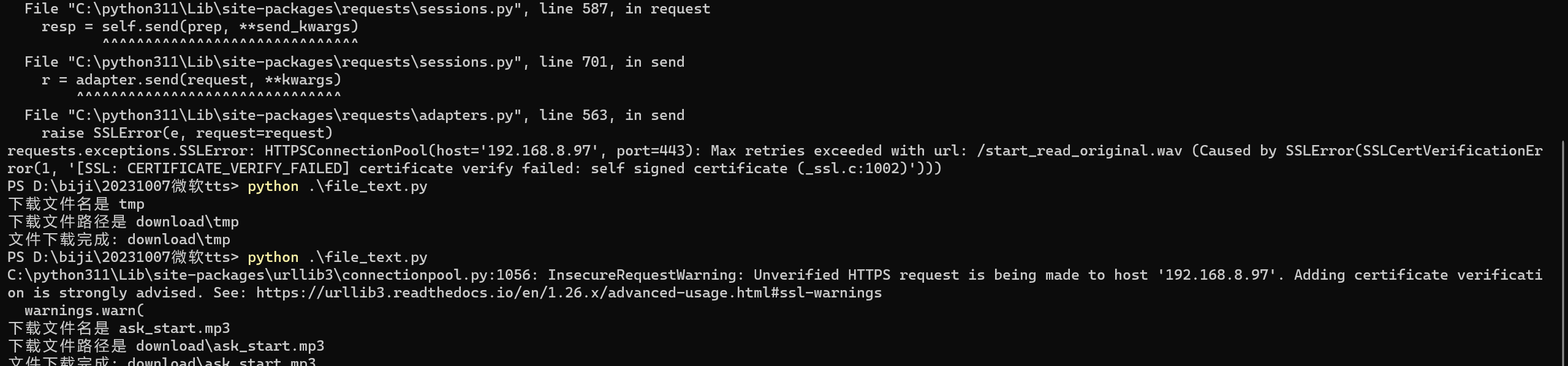
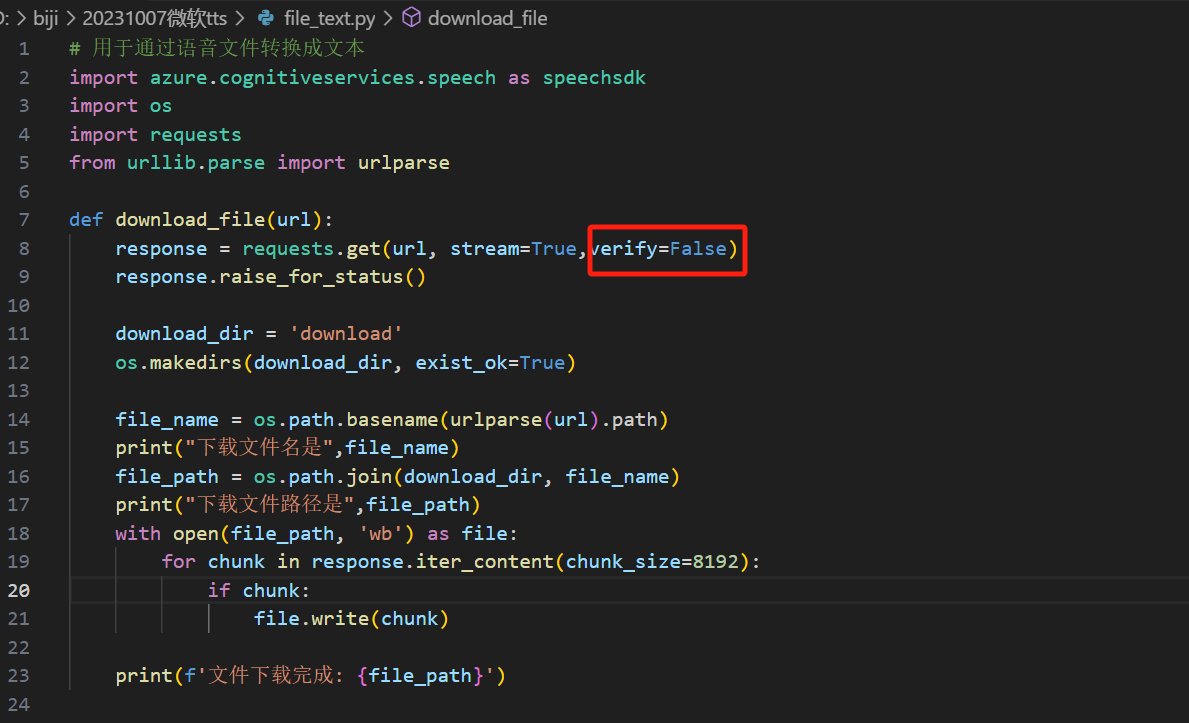
解决方法
在下载参数添加,参数verify=False
response = requests.get(url, stream=True,verify=False)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号