XPath简单教程
本文参考:https://www.runoob.com/xpath/xpath-tutorial.html
分析标准xml文档可以使用SAX,DOM方法,但是针对Html文档例如网站源文件,因为格式不是完全标准的xml文档,使用的SAX和DOM方法经常在导入的时候报格式错误。分析html文档可以使用XPath
本文通过示例来分析XPath简单应用
XPath简介
XPath是一门在XML文档中查找信息的语言。
在学习前应该具备的知识
在您继续学习之前,应该对下面的知识有基本的了解:
- HTML / XHTML
- XML / XML Namespaces
什么是XPath
- XPath使用路径表达式在XML文档中进行导航
- XPath包含一个标准函数库
- XPath是XSLT中的主要元素
- XPtah是一个W3C标准
XPath节点
节点
在XPath中,有七种类型的节点:元素,属性,文档,命名空间,注释以及文档(跟)节点。XML文档是被作为节点树来对待的。树的跟被称为文档节点或者根节点。
请看下面这个XML文档:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
上面的XML文档中的节点例子
<bookstore> (文档节点) <author>J K. Rowling</author> (元素节点) lang="en" (属性节点)
基本值
是无父或无子的节点
基本值的例子
J K. Rowling "en"
项目(item)
项目是基本值或者节点
节点关系
父(Parent)
每个元素以及属性都有一个父
在下面的列子中,book 元素是 title、author、year 以及 price 元素的父:
<book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book>
子(Children)
元素节点可有零个、一个或多个子。
在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
<book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book>
同胞(Sibling)
拥有相同的父的节点
在下面的例子中,title、author、year 以及 price 元素都是同胞:
<book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book>
先辈(Ancestor)
某节点的父、父的父,等等。
在下面的例子中,title 元素的先辈是 book 元素和 bookstore 元素:
<bookstore> <book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> </bookstore>
后代(Descendant)
某个节点的子,子的子,等等。
在下面的例子中,bookstore 的后代是 book、title、author、year 以及 price 元素:
<bookstore> <book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> </bookstore>
XML实例文档
<?xml version="1.0" encoding="UTF-8"?> <bookstore> <book> <title lang="eng">Harry Potter</title> <price>29.99</price> </book> <book> <title lang="eng">Learning XML</title> <price>39.95</price> </book> </bookstore>
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。 下面列出了最有用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取(取子节点)。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(取子孙节点)。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| ookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore |
选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]//title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用"|"运算符,您可以选取若干个路径。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
XPath运算符
下面列出了可用在 XPath 表达式中的运算符:
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | | 计算两个节点集 | //book | //cd | 返回所有拥有 book 和 cd 元素的节点集 |
| + | 加法 | 6 + 4 | 10 |
| - | 减法 | 6 - 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 |
如果 price 是 9.80,则返回 true。 如果 price 是 9.90,则返回 false。 |
| != | 不等于 | price!=9.80 |
如果 price 是 9.90,则返回 true。 如果 price 是 9.80,则返回 false。 |
| < | 小于 | price<9.80 |
如果 price 是 9.00,则返回 true。 如果 price 是 9.90,则返回 false。 |
| <= | 小于或等于 | price<=9.80 |
如果 price 是 9.00,则返回 true。 如果 price 是 9.90,则返回 false。 |
| > | 大于 | price>9.80 |
如果 price 是 9.90,则返回 true。 如果 price 是 9.80,则返回 false。 |
| >= | 大于或等于 | price>=9.80 |
如果 price 是 9.90,则返回 true。 如果 price 是 9.70,则返回 false。 |
| or | 或 | price=9.80 or price=9.70 |
如果 price 是 9.80,则返回 true。 如果 price 是 9.50,则返回 false。 |
| and | 与 | price>9.00 and price<9.90 |
如果 price 是 9.80,则返回 true。 如果 price 是 8.50,则返回 false。 |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
XPath实例
下面通过一个实例来演示XPath的用法,把演示xml作为一个字符串放到一个python文档里面
books.xml
<?xml version="1.0" encoding="UTF-8"?> <bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">XQuery Kick Start</title> <author>James McGovern</author> <author>Per Bothner</author> <author>Kurt Cagle</author> <author>James Linn</author> <author>Vaidyanathan Nagarajan</author> <year>2003</year> <price>49.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore>
选取所有title
use_xpath.py
books = '''
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
'''
from lxml import etree
html = etree.HTML(books)
# 选取所有title
all_title = html.xpath('//bookstore/book/title')
print(all_title)
注意:本次把xml文档作为字符串导入到python文件,多行文档使用''' ''' 且符号'''需要单独占一行不能和文档在同一行
以下语句导入模块并且把文档转换成xpath可以分析的lxml.etree._Element对象
from lxml import etree html = etree.HTML(books)
代码解析
html.xpath('//bookstore/book/title')
/ #第一个/代码从根目录开始查找
/bookstore/book/title # 查找所有title节点
输出如下,返回一个list分别为本次查到的4个title节点,也是一个lxml.etree._Element对象,如果没有匹配到则返回空list
[<Element title at 0x2893c8b5308>, <Element title at 0x2893c8b5548>, <Element title at 0x2893c8b5588>, <Element title at 0x2893c8b55c8>]
选取第一个book的title
first_book_title = html.xpath('//bookstore/book[1]/title')
print(first_book_title)
代码解析
//bookstore/book[1]/title book[1] # 代表在bookstore下找到的第一个book title # 在第一个book下继续查找所有title本次只有1个
返回list只有一个元素
[<Element title at 0x14290f15308>]
本次找的的是下面这个title
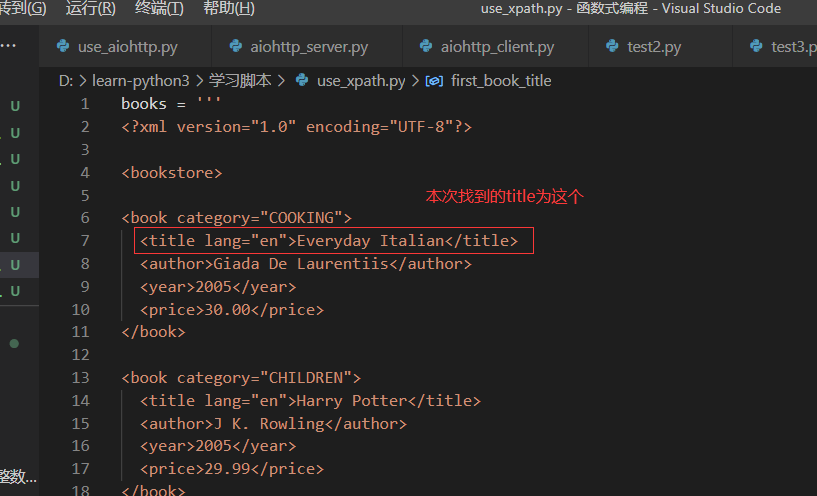
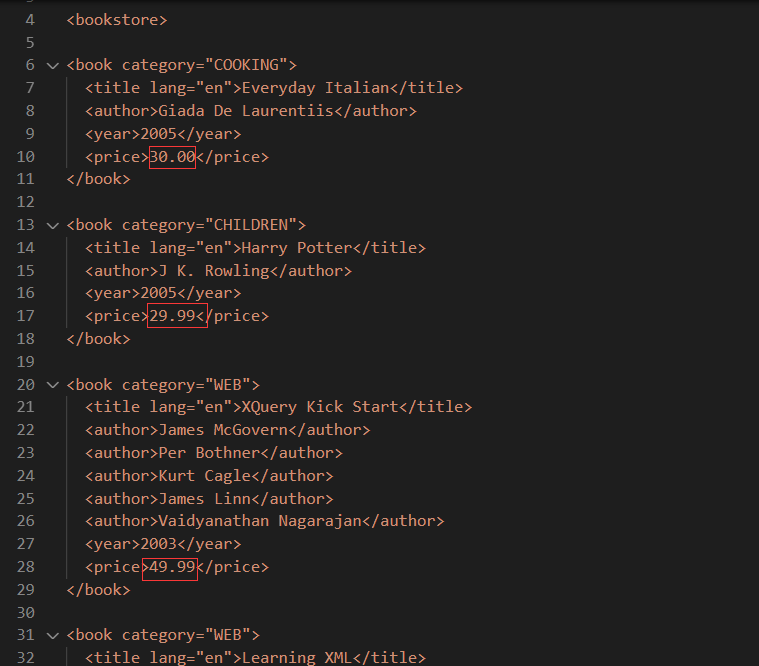
选取所有价格
# 获取所有book的price值即书的价格
price_all_text = html.xpath('//bookstore/book/price/text()')
print(price_all_text)
代码解析
html.xpath('//bookstore/book/price/text()')
//bookstore/book/price # 从根目录下找到所有price
text() # 找对应的price内部的值
输出如下,返回一个list值为几本书的价格
['30.00', '29.99', '49.99', '39.95']
即以下几个值
找书的种类
# 找所有书的种类
book_category = html.xpath('//bookstore/book/@category')
print(book_category)
代码解析
//bookstore/book/@category @category # @关键字用于选取属性
即找一下对应属性

以上分析xml为一个标准xml,如果是使用xpath分析html源码原理也是一样的,把获取到的html网页源码使用etree.HTML(html)转换成xpath可以分析的lxml.etree._Element对象然后再使用xpath分析即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号