

第七讲: prometheus数学理论基础学习
上篇留下一个比较难的计算CPU使用率的公式
1 | (1-((sum(increase(node_cpu{mode="idle"}[1m]))by(instance))/(sum(increase(node_cpu[1m]))by(instance))))*100 |
拆分并解释这个公式
举一反三计算CPU其他状态
Linux系统开启后,CPU进入工作状态,每一个状态的CPU使用时间都是从零开始累计
而我们在客户端安装node_exporter会抓取并返回给我们常用的八种CPU状态的累积时间数值
我们先用用户态CPU举例
用户态CPU通常是占用CPU状态最多的类型,当然也有个别例外内核态 IO等待占用的更多
Linux使用top命令第二行输出就是用户态使用率
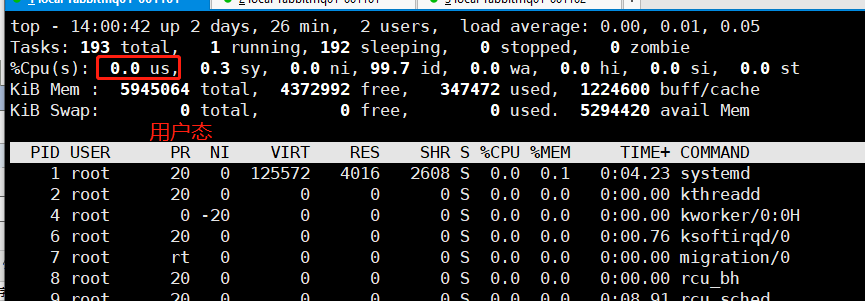
假设有台机器从12:00开机至12:30
在这30分钟的过程中(假设机器CPU为1核)
CPU用户态的时间8分钟
CPU在内核态的时间一共1.5分钟
CPU在IO等待状态的时间是0.5分钟
CPU在Idle等待的时间是20分钟(其实就是CPU没有工作的时间)
上面这些数据为了我们计算CPU在这30min是时间使用率提供的单位数据基础
CPU使用率=(所有非空闲状态的CPU使用时间的总和)/(所有状态CPU时间总和)
有了这个公式以后计算
1 2 3 | (user(8mins)+sys(1.5mins)+iowa(0.5mins)+0+0+0)/(30mins)=10分钟/30分钟=33.33% |
· 还可以使用更简单的计算方式先计算空闲时间然后再用1减
1 | 1-idle(20)/30 |
上面的计算方法最终只能计算出CPU在30分钟内的总平均时间
如果要知道中间的某一分钟CPU的总平均时间是多少
那么使用当前这个算法我们就没办法精确知道某一分钟的平均值了
对于CPU这种实时变化的监控数据,我们往往需要更精确的单位去判断当前时刻或者过去某一时刻的即时状况,知道30分钟的平均值其实没多大意义
如何解决这个问题
还记得我们学过Counter的数据类型吗
node_cpu给我们返回的是Counter数据
Counter是一个持续增长的数值
现在面临的问题是30分钟内CPU使用时间持续增长,我们需要截取其中一段增长的增量值
如果我们能获取1分钟的增量值 然后拿这个数值再去使用刚才同样的计算公式
那么我们就得到了1分钟的平均值
prometheus的数学查询命令行,其实给我们提供了非常丰富的计算函数
先介绍一个很实用的函数
increase()
1 2 | increase函数在prometheus中,用来针对Counter这种持续增长的数值,截取其中一段时间的增量increase(node_cpu[1m])这样就获取了CPU总使用时间在一分钟内的增量 |
实际工作中CPU大多是多核的CPU
如下图
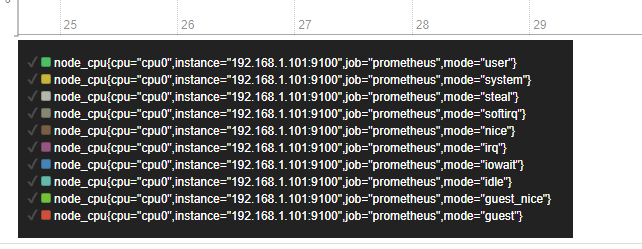
采集的数据精细到每个CPU的
不过我们在运维实际监控中,往往并不太关注每一个核心CPU的表现如何
如果每一个核心都需要一个单独的监控图形意义不大,而且看起来混乱
有什么办法可以解决这个问题
使用另一个函数sum()
如字面意思一样起到加和的作用
外套一个sum即可把所有核数值相加
1 | sum(increase(node_cpu[1m])) |
拆分并解释运算CPU的计算公式
1 | (1-((sum(increase(node_cpu{mode="idle"}[1m]))by(instance))/(sum(increase(node_cpu[1m]))by(instance))))*100 |
第一步
key:node_cpu是我们需要使用的key name
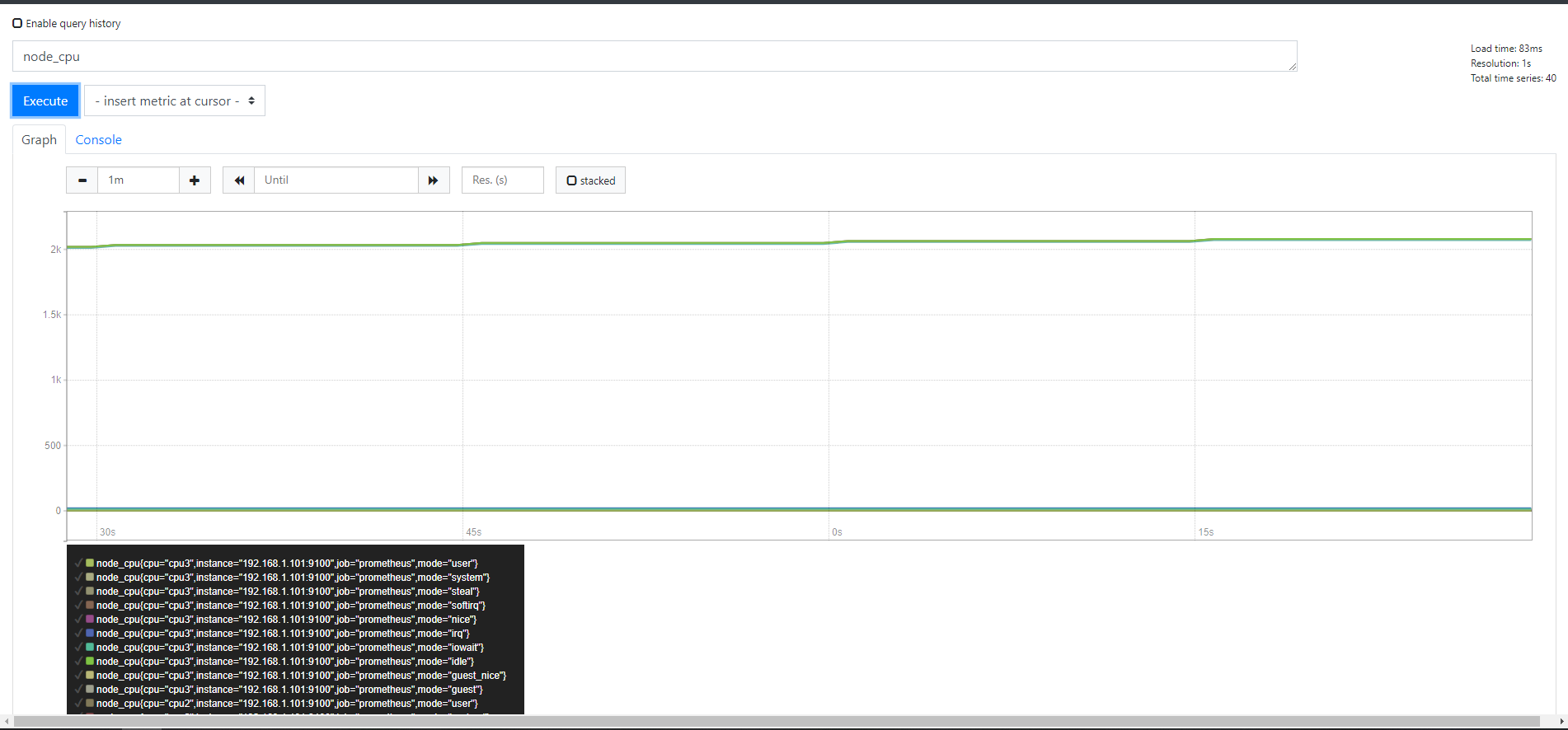
直接输入如上图所示,几乎是直线的图
这种图没有意义,我们继续完善命令行
第二步
把idle空闲的CPU时间和全部CPU时间都给过滤出来
key使用{}做过滤
1 2 | node_cpu{mode="idle"} #空闲CPU时间node_cpu #全部CPU时间 |
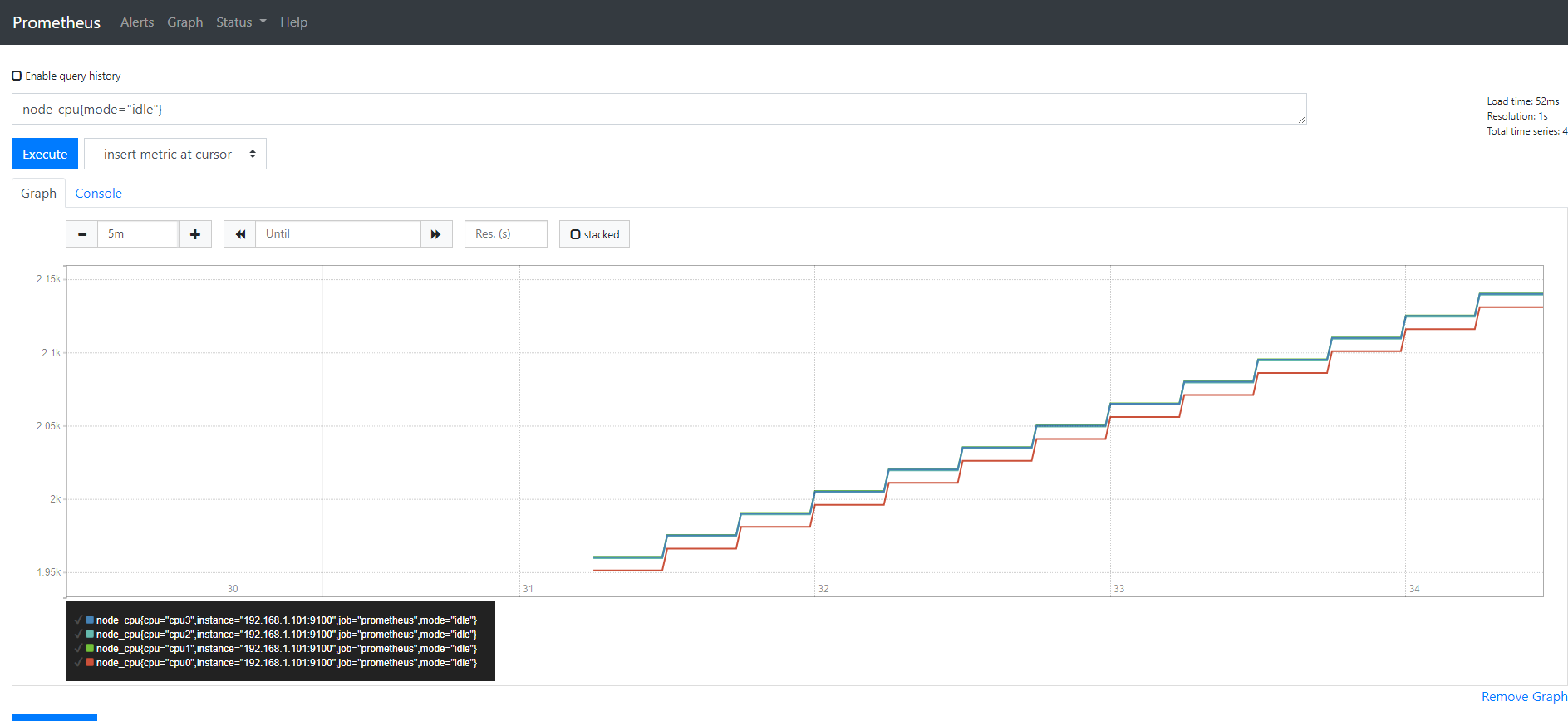
第三步
我们使用increase( [1m])把node_cpu{mode="idle"}包起来
1 | increase(node_cpu{mode="idle"} [1m]) |
这样就把一分钟的增量的CPU时间给取出来了
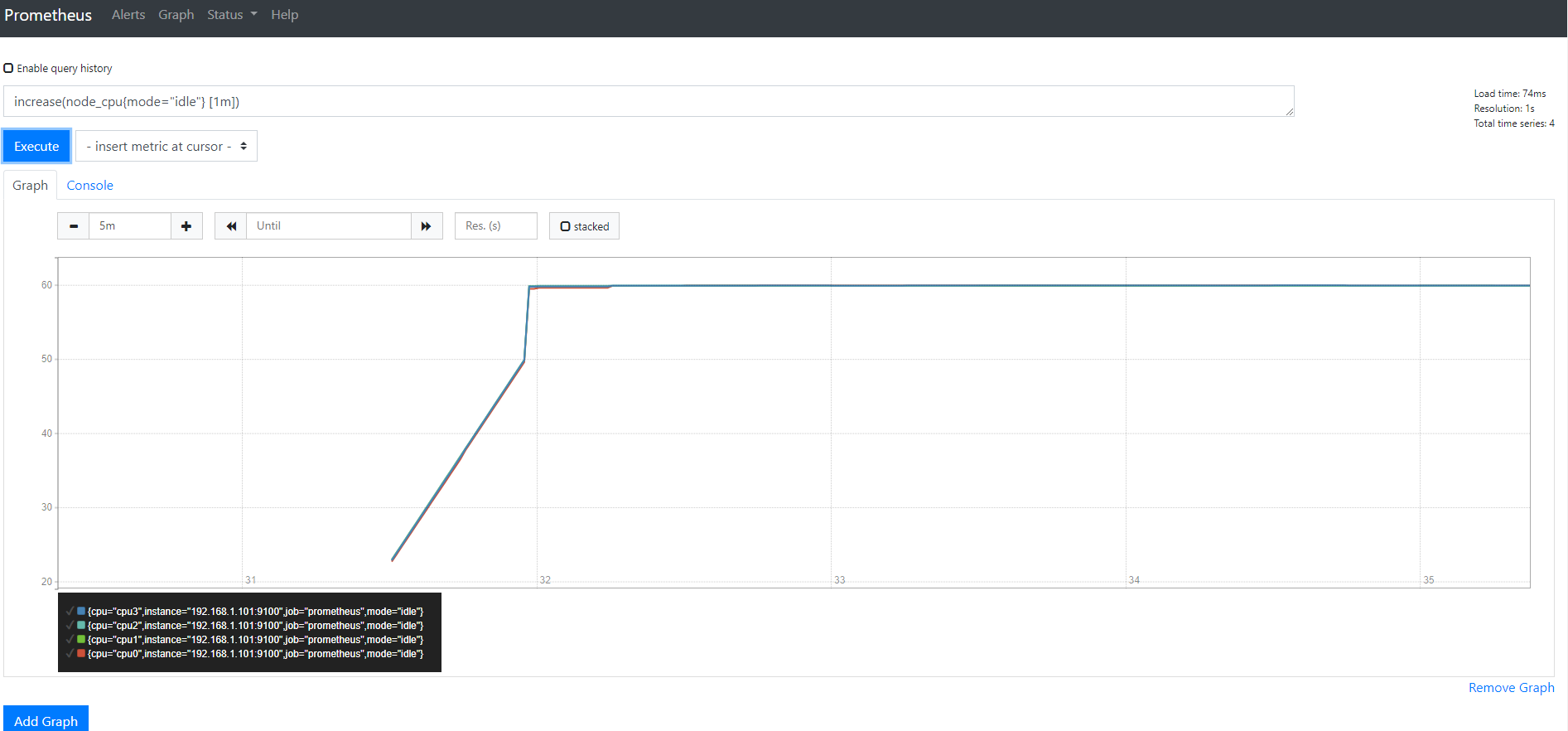
第四步
默认会把所有CPU生成一个图形
使用sum()再包一层
1 | sum(increase(node_cpu{mode="idle"} [1m])) |
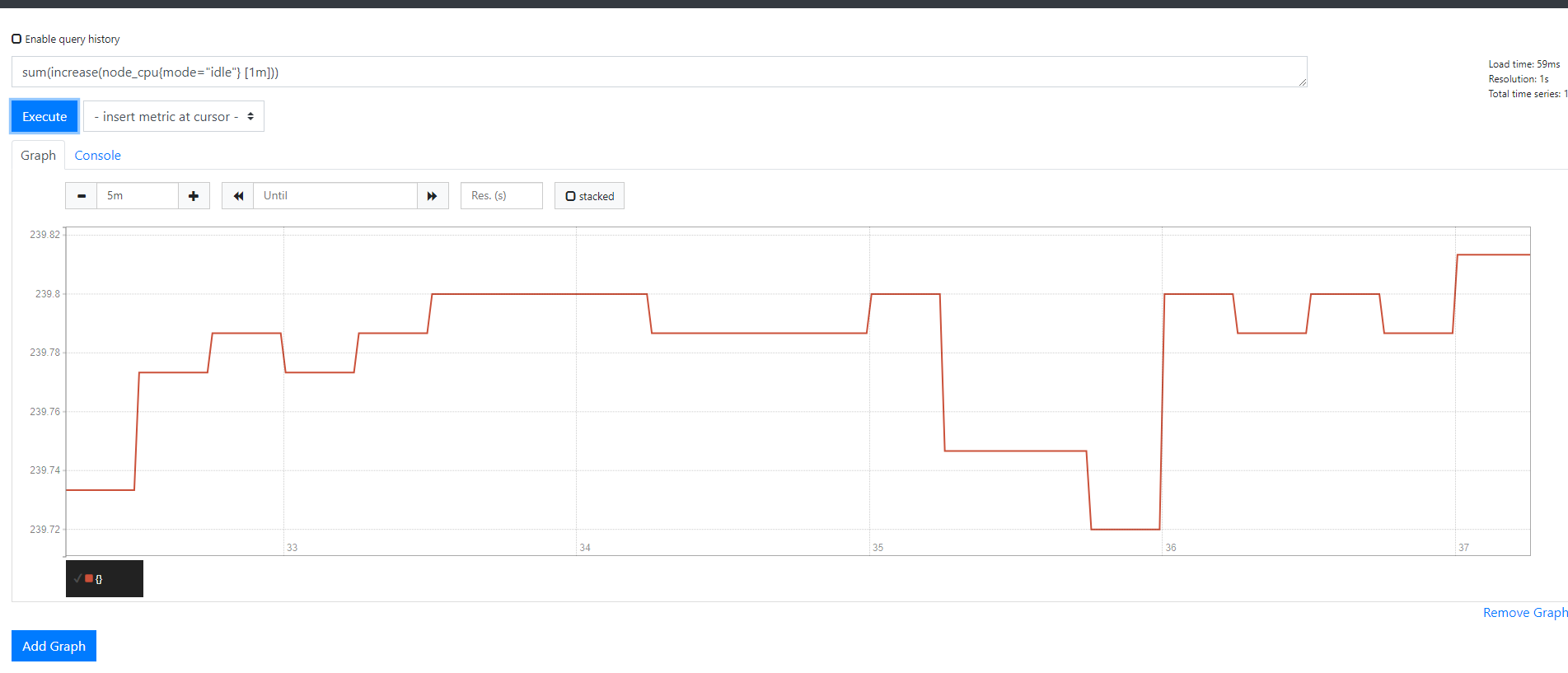
我们这个CPU的监控其实采集的是多台服务器的监控数据
怎么变成一条线了
其实是由于这个sum()函数的原因
sum()函数 其实默认情况下是把所有数据不管是什么内容全部进行加合了
不光把每一台机器多个核加载一起了(这是我们需要的)
这里是把所有机器的CPU也全部加到一起了
第五步
再引出一个新的函数
1 | by(instance) |
这个函数可以把sum全部加合到一起的数值,按照指定的一个方式进行一层的拆分
instance代表的是机器名
1 | sum(increase(node_cpu{mode="idle"} [1m])) by (instance) |
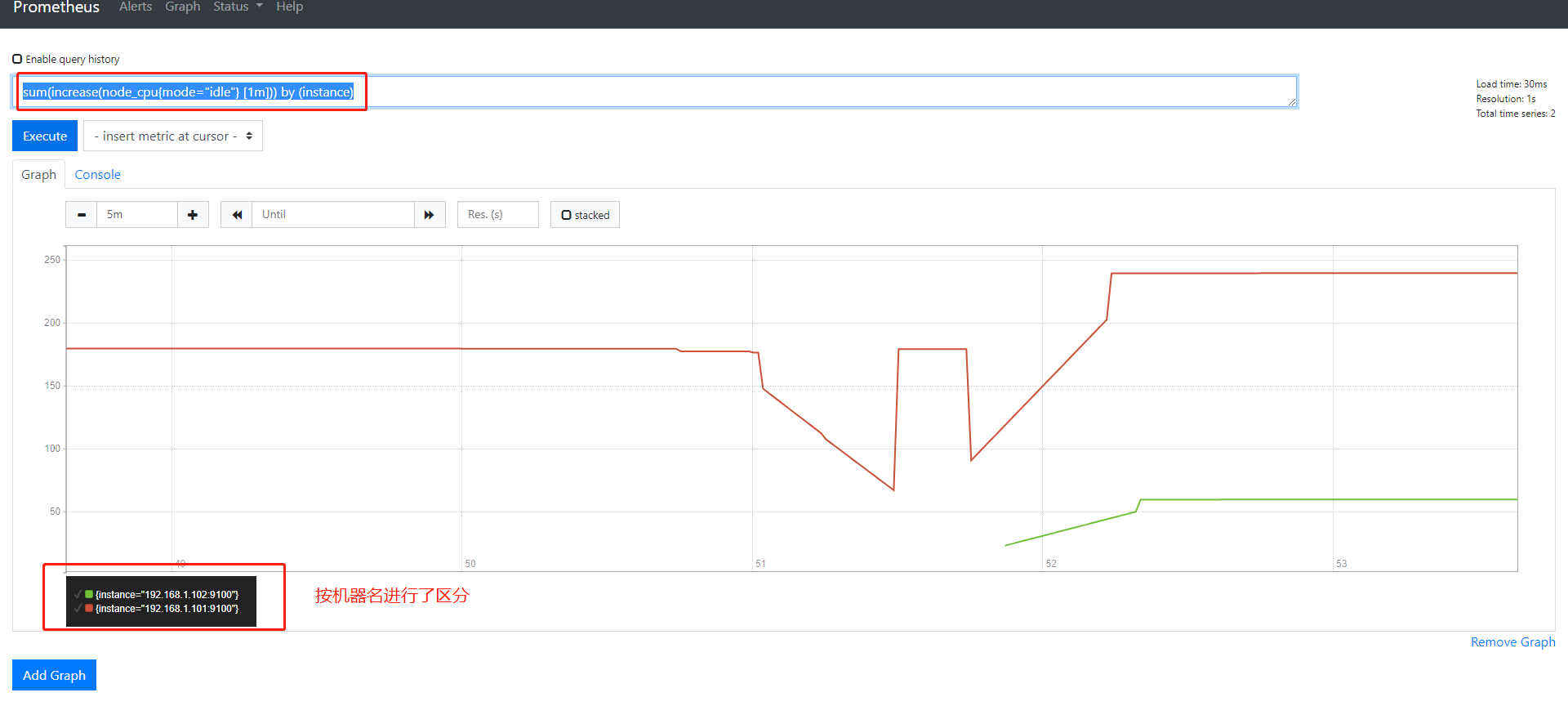
第六步
把公式写完整
1 2 3 | sum(increase(node_cpu{mode="idle"} [1m])) by (instance)#空闲时间sum(increase(node_cpu [1m])) by (instance)#总时间sum(increase(node_cpu{mode="idle"} [1m])) by (instance) / sum(increase(node_cpu [1m])) by (instance) #空闲时间除以总时间 |
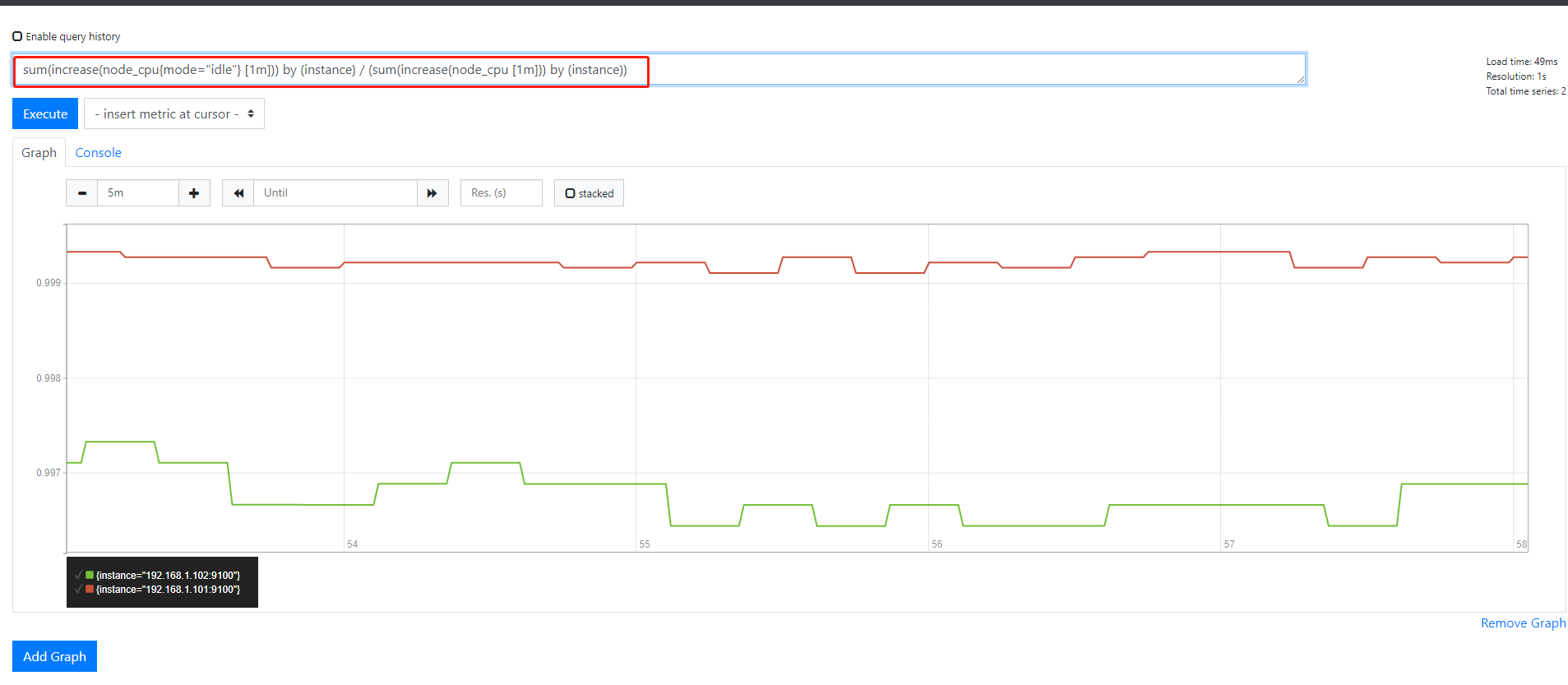
每一条取消是空闲CPU百分百,需要计算出非空闲CPU百分百 把整个公司加()再用1去减再乘以100就是CPU的使用率
1 2 3 4 | 1-(sum(increase(node_cpu{mode="idle"} [1m])) by (instance) / sum(increase(node_cpu [1m])) by (instance)) #用1减去空闲CPU占比就是使用CPU的占比#再乘以100就是百分比(1-(sum(increase(node_cpu{mode="idle"} [1m])) by (instance) / sum(increase(node_cpu [1m])) by (instance))) * 100 |
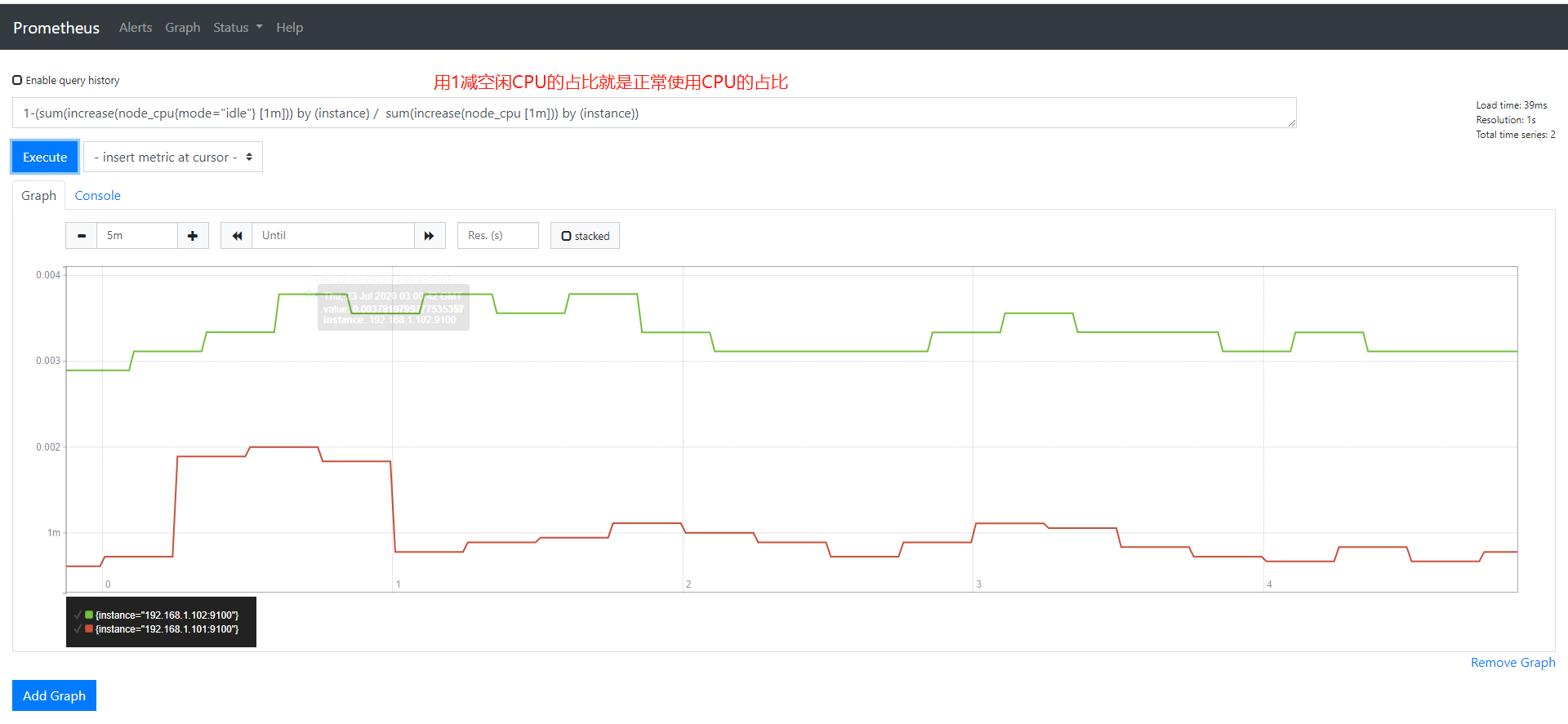
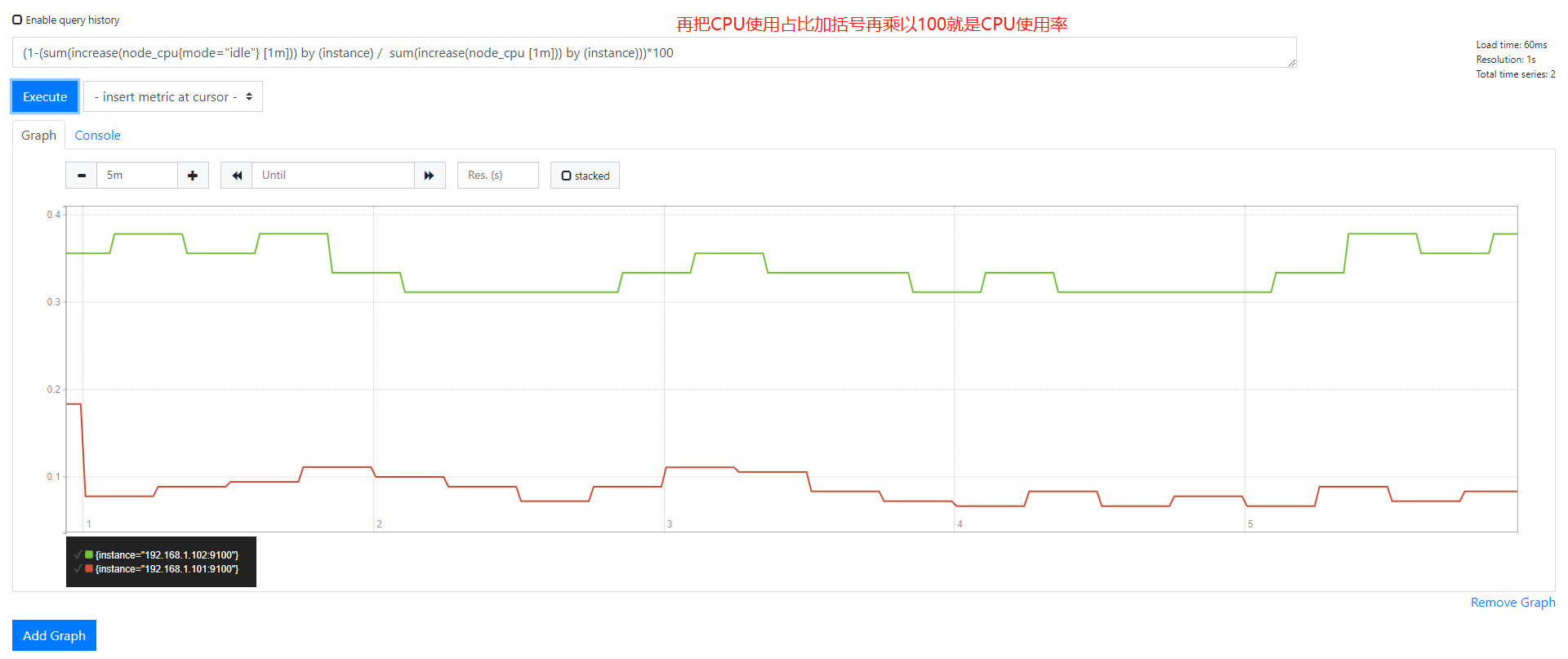
举一反三查看其它CPU类型的使用率
例如查看用户态 系统态 io等待状态CPU使用率
1 2 3 | sum(increase(node_cpu{mode="user"} [1m])) by (instance) / sum(increase(node_cpu [1m])) by (instance)sum(increase(node_cpu{mode="system"} [1m])) by (instance) / sum(increase(node_cpu [1m])) by (instance)sum(increase(node_cpu{mode="iowait"} [1m])) by (instance) / sum(increase(node_cpu [1m])) by (instance) |
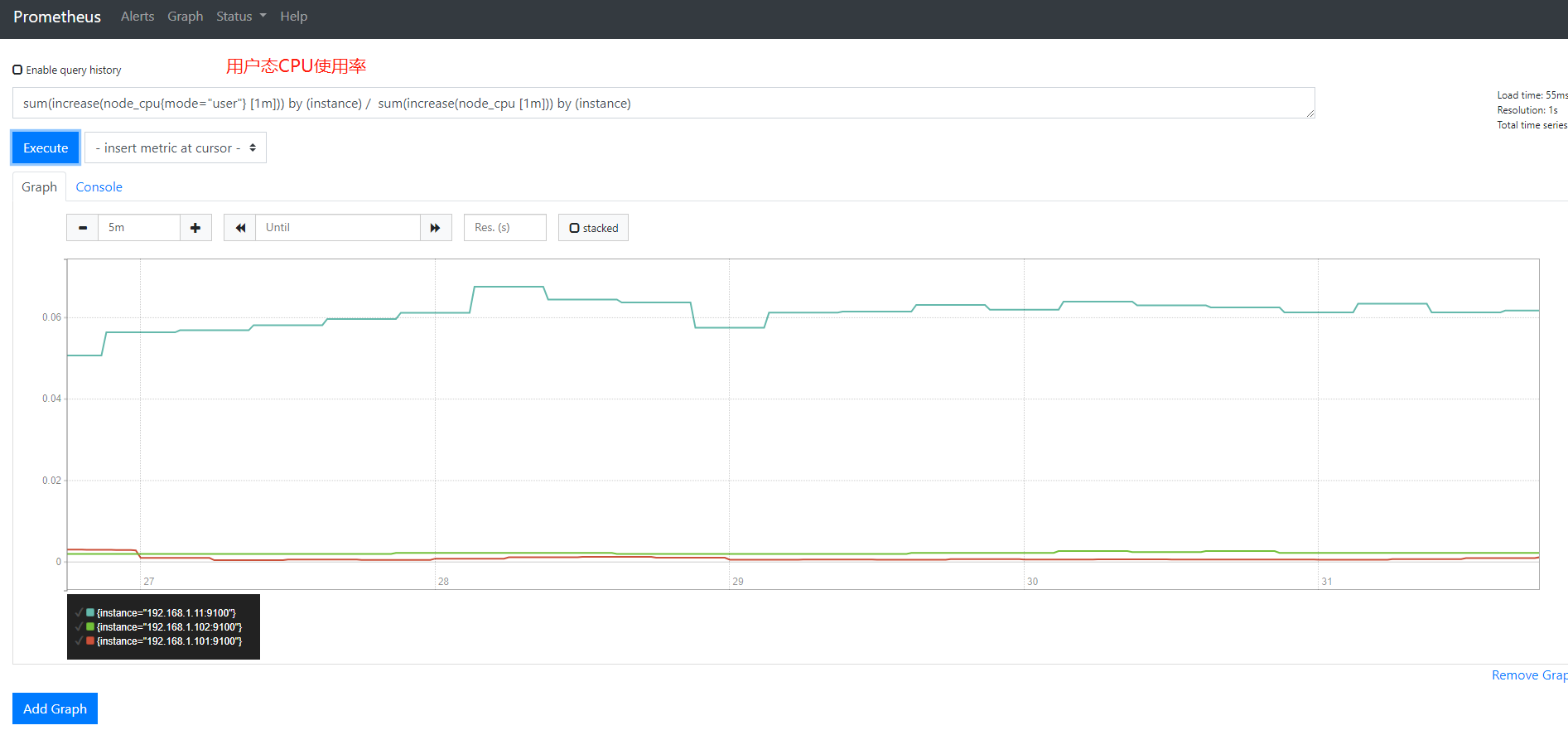
系统态等图形不展示了
说到这里为什么是不是发现top命令中这一行是什么意思了

prometheus要求运维人员必须对Linux系统的深层次的知识要有一定掌握


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!