第六讲:prometheus初探和配置
- prometheus官网下载
- prometheus开始安装
- prometheus启动运行
- prometheus基本配置文件讲解
- 安装第一个个exporter -》node_exporter
- prometheus连接exporter获取数据
- prometheus命令行入门
时间同步
ntpdate time1.aliyun.com
下载prometheus
本次下载版本为2.10.0
下载地址https://github.com/prometheus/prometheus/releases/tag/v2.10.0
解压安装
mv prometheus-2.10.0.linux-amd64.tar.gz /usr/local/ cd /usr/local/ tar -xf prometheus-2.10.0.linux-amd64.tar.gz mv prometheus-2.10.0.linux-amd64 prometheus
启动
cd prometheus ./prometheus
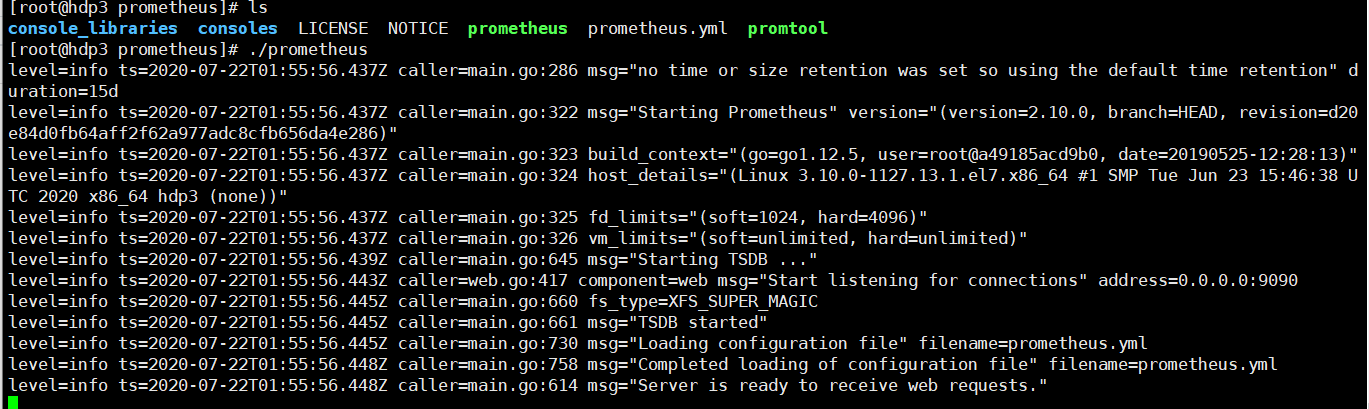
默认启动端口是9090
prometheus解压安装以后,就默认自带了一个基本的配置文件,在解压的文件夹下面的 prometheus.yml
# cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
配置文件解析
#全局变量,抓取数据的时间间隔,默认15秒,不建议定义成1秒 scrape_interval: 15s #全局变量,监控数据规则评估频率 #这个参数是prometheus多长时间会进行一次监控规则评估 #例如我们设置当内存使用量大于70%发出报警 这么一条rule(规则) #那么prometheus会默认每15秒来执行一次这个规则 检查内存情况 evaluation_interval: 15s
Alertmanager是prometheus的一个用于管理和发出报警的插件 这里对Alertmanager暂时先不做介绍,暂时也不需要,我们采用4.0Grafana,本身就已经支持报警发出功能
#抓取数据配置
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
#定义一个任务名称prometheus
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
#定义监控节点targets
static_configs:
- targets: ['localhost:9090']
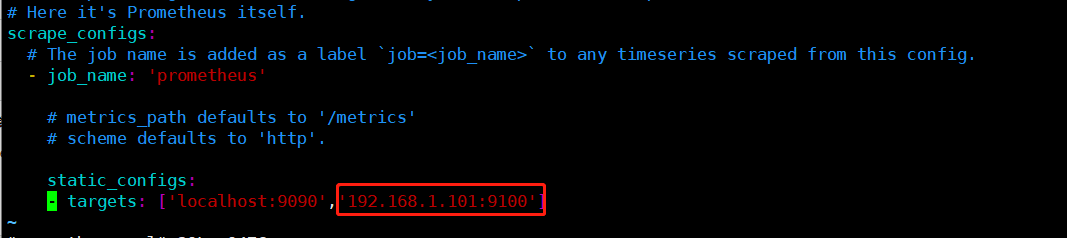
这里可以继续扩展加入其它需要监控的节点
static_configs:
- targets: ['localhost:9090','server01:9100']
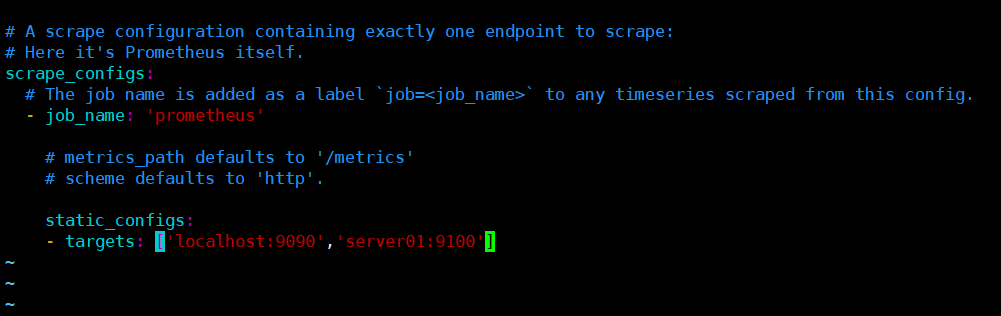
可以targets可以并列写入多个节点,需要设置hosts可以解析,也可以设置IP地址(IP地址不直观)
端口号:通常就是exporter的端口
这里9100其实是node_exporter的默认端口
光搭建好prometheus_server是不够的,我们需要给监控节点搭建第一个exporter用来采集数据
我们就选用企业中最常用的node_exporter这个插件
node_exporter是一个以http_server方式运行在后台,并且持续不断采集Linux系统中各种操作系统本身相关的监控参数的程序
其采集量的很大很全的,往往默认的采集项目就远超实际需求
下载node_exporter
下载地址:https://github.com/prometheus/node_exporter/releases/tag/v0.15.2

解压运行
tar -xf node_exporter-0.15.2.linux-amd64.tar.gz mv node_exporter-0.15.2.linux-amd64 node_exporter cd node_exporter ./node_exporter &
可以使用curl命令查看
curl 192.168.1.101:9100/metrics
执行curl之后可以看到node_exporter返回了大量metrics类型的K/V数据
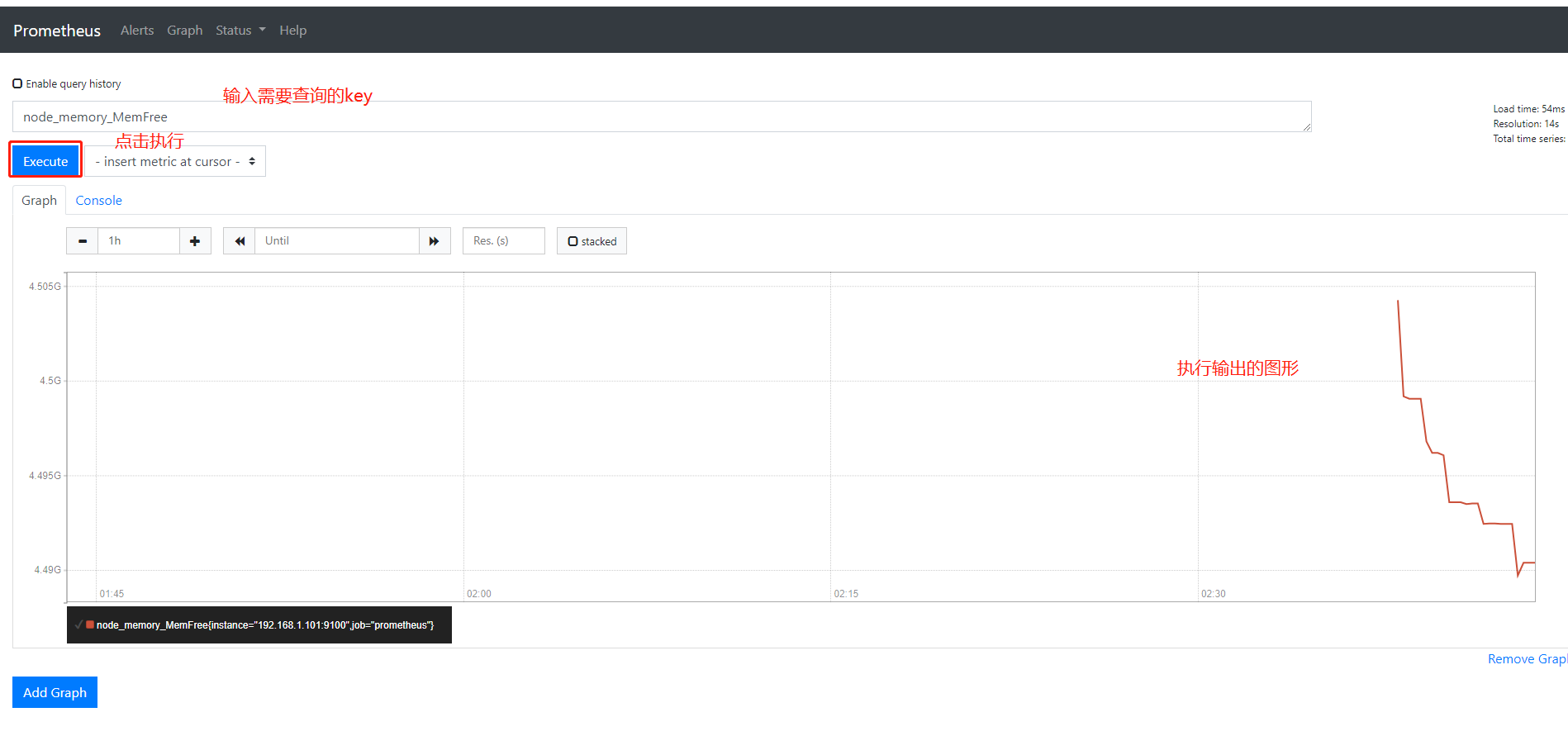
而这些返回的K/V数据,其中的key名称就可以直接复制粘贴在prometheus的查询命令来看结果了
试试node_memory_MemFree 空闲内存
前提是prometheus修改配置把该主机的对应的ip和端口添加进来,添加后需要重启prometheus
难一点的监控CPU使用率
node_cpu这个key也是node_exporter返回的一个用来统计CPU使用率的
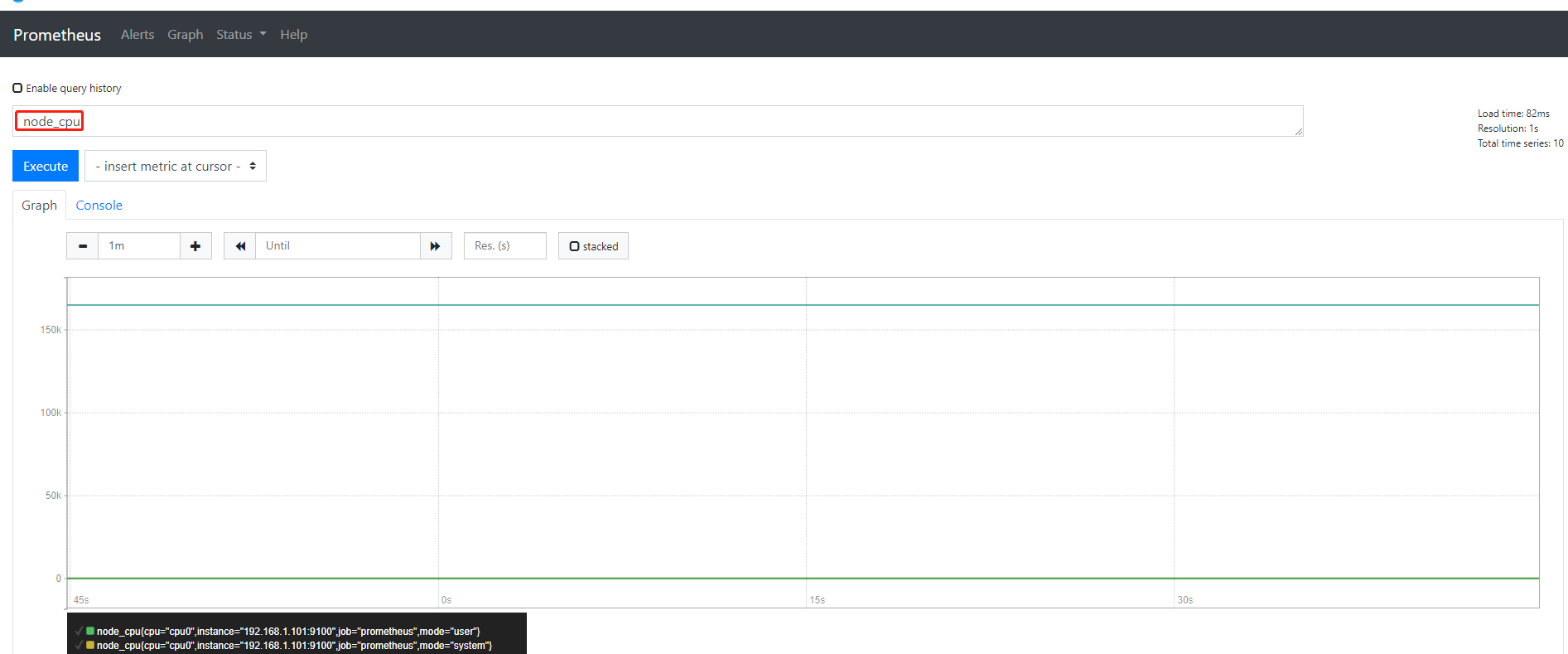
返回的是一个持续不断累加的近似于直线的庞大数值
这个其实关系到prometheus对Linux数据采集的精细特性
其实prometheus对Linux CPU的采集并不是直接返回给我们一个CPU使用率的百分百,而是返回Linux很底层的cpu时间片 累积数值这样一个数据
当我们平时习惯top/uptime这种简单的方式查看CPU使用率,往往浅尝辄止,没有好好深入理解CPU使用率在linux到底是怎么回事
其实如果想要真的弄明白CPU使用率这个概念 在Linux要先从CPU时间这个概念开始建立
Linux CPU时间 实际是指:从操作系统开启算起CPU就开始工作了,并记录在自己的工作中,总共使用的时间的累积量把它保存在系统中
而累积的CPU使用时间还会分成几个重要的状态
比如CPU time分成 CPU user time/sys time/nice time/idle time/irq等
翻译过来就是CPU 用户态使用时间 系统内核态使用时间 nice值分配使用时间 空闲时间 中断时间等
CPU使用率最准确的定义其实是CPU各种状态中除了idle(空闲)外,其他所有CPU状态的和/总CPU时间
得出来的就是CPU使用率
那么会到我们刚才使用node_cpu这个key如果直接输入jinq
返回的其实是CPU刚刚状态下从开机开始一直累积下来CPU使用时间的累积值
CPU时间状态解释
us(user time) 表示CPU执行用户进程的时间,包括ni时间。通常我们只看这项。 sy(system time) 表示CPU在内核运行时间,包括IRQ和softirq时间,系统CPU占用率高,表明系统某部份存在瓶颈,通常值越低越好。 wa(waiting time) CPI在等待I/O操作完成所花费的时间,系统不应该花费大量时间来等待I/O操作,否则说明I/O存在问题。 id(idle time) 系统处于空闲期,等待进程运行。 ni(nice time) 系统调整进程优先级所花费的时间。 hi(hard irq time) 系统处理硬中断所花费的时间。 si(softirq time) 系统处理软件中断所花费的时间。 st(steal time) 被强制等待虚拟CPU的时间,此时hypervisor在为另一个虚拟处理器服务。
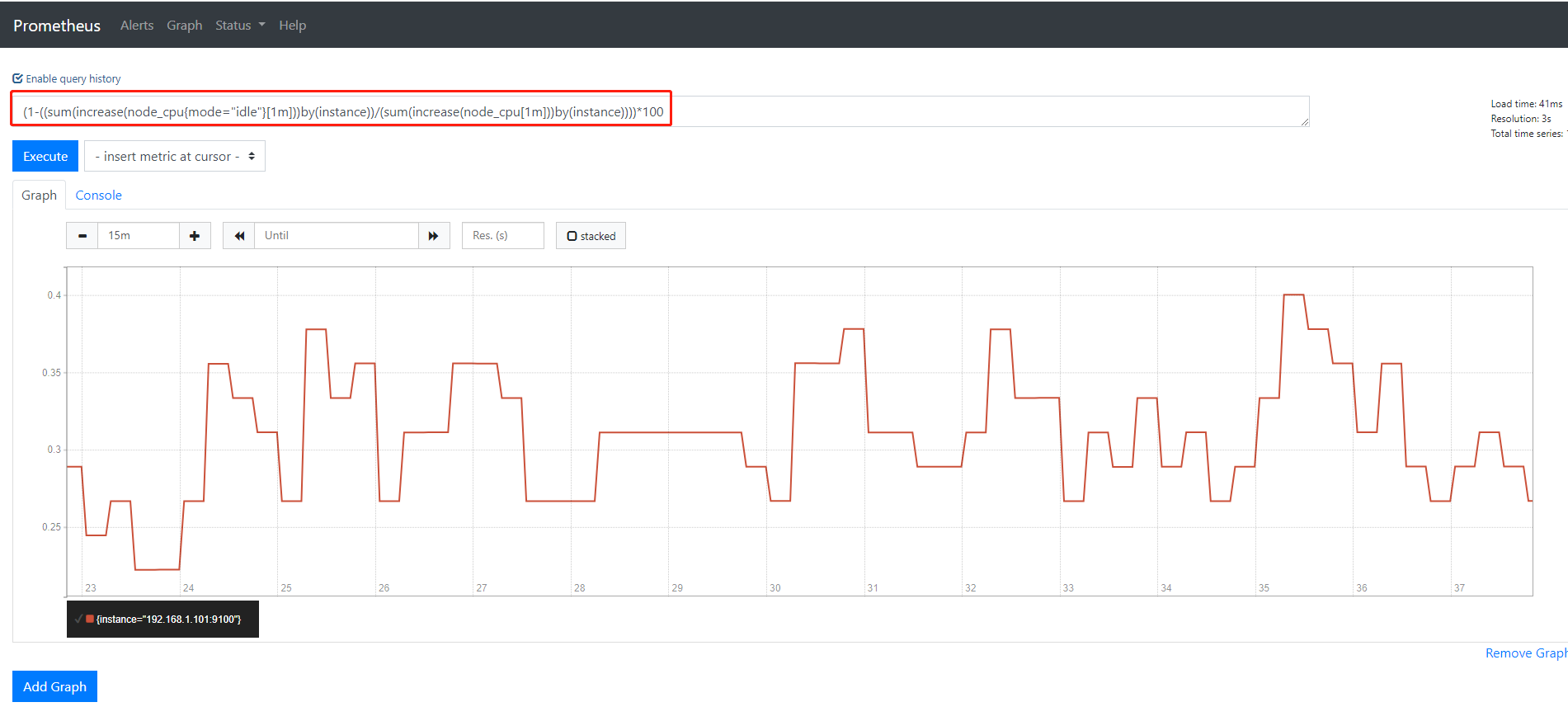
所以:如果在prometheus中,想对CPU的使用率 准确来查询
(1-((sum(increase(node_cpu{mode="idle"}[1m]))by(instance))/(sum(increase(node_cpu[1m]))by(instance))))*100
在web页面输入执行
prometheus这种精细的底层的计算特性虽然学起来难不过带来的好处也是显而易见的
1)prometheus这种底层数据采集所形成的监控是最准确最可信的
2)prometheus本身也逼着使用它的运维同学,你不踏实下来好好真正把Linux技术学习过关的话就没有办法使用好这个超强力的监控工具了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号