

第一讲:企业级运维监控理理论基础
Prometheus构架图

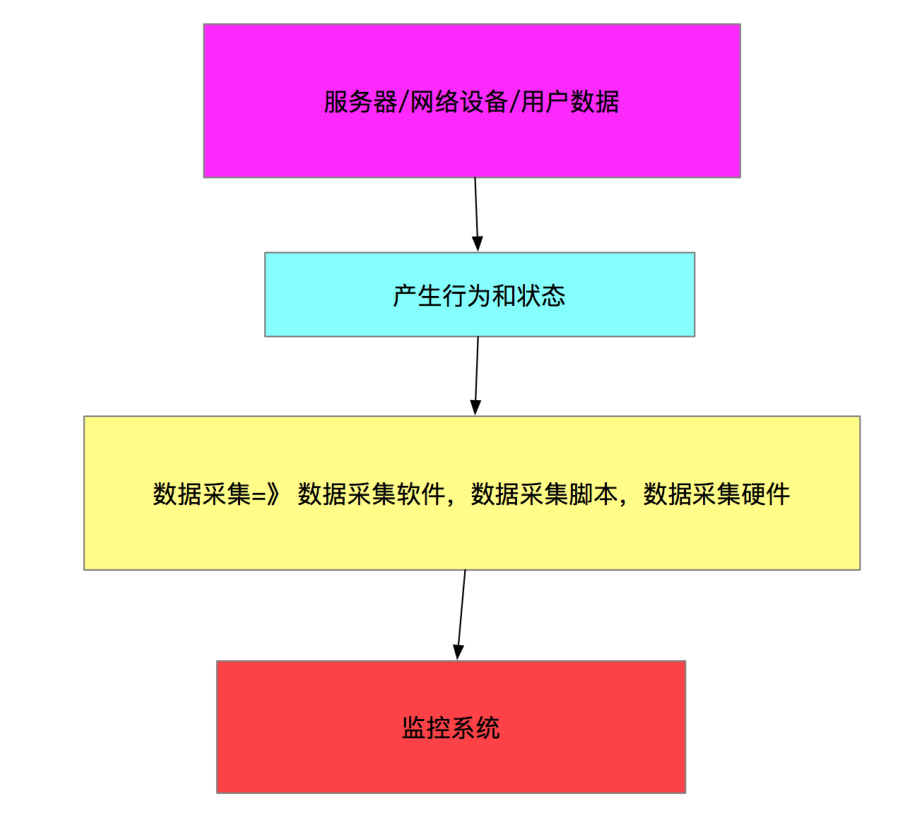
监控和报警
Prometheus优势
•监控数据的精细程度 绝对的第⼀ 可以精确到 1~5秒的采集精度 4 5分钟 理想的状态 我们来算算
采集精度 (存储 性能)
• 集群部署的速度 监控脚本的制作 (指的是熟练之后) ⾮常快速 ⼤⼤缩短监控的搭建时间成本
• 周边插件很丰富 exporter pushgateway ⼤多数都不需要⾃⼰开发了
• 本⾝基于数学计算模型,⼤量的实⽤函数 可以实现很复杂规则的业务逻辑监控(例如QPS的曲线
弯曲 凸起 下跌的 ⽐例等等模糊概念)
• 可以嵌⼊很多开源⼯具的内部 进⾏监控 数据更准时 更可信(其他监控很难做到这⼀点)
• 本⾝是开源的,更新速度快,bug修复快。⽀持N多种语⾔做本⾝和插件的⼆次开发
• 图形很⾼⼤上 很美观 ⽼板特别喜欢看这种业务图 (主要是指跟Grafana的结合)
不足之处
• 因其数据采集的精度 如果集群数量太⼤,那么单点的监控有性能瓶颈 ⽬前尚不⽀持集群 只能
workaround
• 学习成本太⼤,尤其是其独有的数学命令⾏(⾮常强⼤的同时 又极其难学《=⾃学的情况下),
中⽂资料极少,本⾝的各种数学模型的概念很复杂(如果没⼈教 ⾃⼰⼀点点学英⽂官⽹ 得 1-3 个
⽉⼊门)
• 对磁盘资源也是耗费的较⼤,这个具体要看 监控的集群量 和 监控项的多少 和保存时间的长短
• 本⾝的使⽤ 需要使⽤者的数学不能太差 要有⼀定的数学头脑
较完善的监控系统体系
1)监控系统设计
设计部分包括以下内容
评估系统的业务流程,业务方向不同,程序代码不同,系统构架不同
对于各个地方的细节,都需要一定程度的认知,才是监控设计的源头
分类列出所需监控项种类
一般可分为: 业务级别监控/系统级别监控/网络监控/程序代码监控/日志监控/用户行为监控/其他类型监控
大的分类,还有更多细小分类
例如
业务监控:可以包含用户访问OPS,DAU日活,访问状态(http code),业务接口(登录,注册,聊天,上传,留言,短信,搜索)产品转化率,充值额度,用户投诉这些很宏观的概念
系统监控:主要和操作系统相关 CPU/内存/硬盘/IO/TCP链接/流量
网络监控:对网络状态的监控,例如丢包率,延迟等等
日志监控:监控中的重头戏,往往单独设计和搭建,各种种类的日志都需要采集
程序监控:一般需要和开发人员配合,程序中嵌入各种接口,直接获取数据或者特质的日志格式
监控技术方案软件选取
各种监控软件层出不穷,开源的 商业的 自行开发的几百种方案可选
架构师凭借一些因素,开始选材
针对企业的架构特点 大小种类,人员多少等等选取合适的技术方案
监控体系人员安排
运维团队任务划分,责任到人,分块进行
2)监控系统的搭建
- 单点服务端的搭建
- 单点客户端的搭建
- 单点客户端服务器测试
- 采集程序单点部署
- 采集程序批量部署
- 监控服务端HA
- 监控图形化搭建(Grafana)
- 报警系统(Pagererduty)
- 报警规则测试
- 监控+报警联合测试
- 正式上线监控
3)数据采集的编写
例如: shell/python/awk/lua(Nginx安全控制 功能分类)/php/perl/go等等
shell:运维入门脚本,任何和性能,后台,界面无关的逻辑都可以实现最快速的开发
Python:各种扩展功能,扩展库,功能丰富
awk:本身是一个实用命令,也是一门庞大的编程语言。结合shell或者独立都可以使用
lua:多用于nginx模块结合,是比较新的一个语言
php:老牌子的开发语言,在大型互联网开发中,目前有退潮趋势,不过在运维开发中还是很依赖PHP
Perl:传说中对文本处理最快的工具(但是代码可读性不强)
go:新型的语言 目前在开发和运维中很热,在各种后端服务逻辑编写上开发速度快
作为监控数据的采集,首推shell和python
数据采集的形式分类
一次性采集:例如我们使用比较简单的shell + crontab 按定时任务
优点:稳定性比较好,不容易出现错误和性能瓶颈,开发逻辑简单实现快速
缺点:对于有些采集项目实现起来不够智能,也不到位。例如日志的实时采集
后台式采集:采集程序以守护进程运行在Linux后台,持续不断地采集数据
优点:后台采集程序 数据准确性高,采集密度精确,管理方便
缺点:如果开发不够仔细,会出现内存泄漏,僵尸进程 性能瓶颈等问题,且开发时间较长
桥接式采集:本身已后台进程运行,单采集过程不能独立,以桥接方式采集数据
监控的数据和算法其实非常依赖运维架构师对Linux操作系的各种底层知识的掌握
如果我们使用老式傻瓜式的监控nagios,里面的监控脚本很全面,生成报警规则和阈值也很简单,缺点也显而易见;监控太粗糙,实用性不强,另外也不利于希望提高的同学
业务级别监控的算法 运维自身无法做到十分专业
监控图形 曲线QPS上涨,下跌,QPS和历史数据的比较方法,等等这些都属于业务级别的监控阈值类型
需要有专业的数据分析人员的协助 才可以算出优良的算法
例如:如果我现在想针对QPS下跌率进行报警计算,那么用什么样的公式针对我们的业务类型更贴切
计算当前5分钟内的平均值<一个固定数值的时候 报警合适
计算当前10分钟的总量然后和前一个小时同一时间段比较
计算当前1小时的平均值和过去一周内每一天同一时间段的时间比较合适
这些数据算法和Linux无关,只有非常专业的数据计算团队,才可以给出一个合理的算法
监控稳定测试
不管是一次性采集,还是后台采集,只要是部署在Linux都会多多少少产生一定影响
监控自动化
监控客户端的批量部署,监控服务端的HA安装,监控项目的修改,监控项目的监控集群变化
这里给出几个实例
Puppet(配置文件部署)
Jenkins(持续集成)
CMDB(运维自动化的最高资源管理平台和理念)
监控图形化工作
采集好的数据和准备好的监控算法,最终需要一个好的图形展示
grafanna的使用和搭建


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!