
第二章 Kubernetes进阶之使用二进制包部署集群
1.官方提供的三种部署方式
minikube
Minikube是一个工具,可以在本地快速运行一个单点Kubernetes,仅用于尝试Kubernetes或日常开发以后使用
kubeadm
Kubeadm也是一个工具,提供kubeadm init和kubeadm join,用于快速部署Kubernetes集群
init初始化master
join使node加入集群
目前属于测试阶段不适用于生产环境
二进制包
推荐部署方式,从官方下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群
2.Kubernetes平台环境规划
| 软件 | 版本 |
| Linux操作系统 | CentOS7.5_X64 |
| Kubbernetes | 1.12 |
| Docker | 18.xx.ce |
| Etcd | 3.x |
| Flannel | 0.10 |
| 角色 | IP | 组件 | 推荐配置 |
| master01 | 192.168.1.63 |
kube-apiserver kube-controller-manager kube-scheduler etcd |
CPU:2C+ 内存:4G+
|
| master02 | 192.168.1.64 |
kube-apiserver kube-controller-manager kube-scheduler |
|
| node01 | 192.168.1.65 |
kubelet kube-proxy docker flannel etcd |
|
| node02 | 192.168.1.66 |
kubelet kube-proxy docker flannel etcd |
|
|
Load Balancer (Master) |
192.168.1.61 192.168.1.60(VIP) |
Nginx L4 | |
|
Load Balancer (Backup) |
192.168.1.62 | Nginx L4 | |
| Registry | 192.168.1.66 | Harbor |
单节点master构架图

3.自签SSL证书
部署之前关闭防火墙和selinux

修改主机名
| IP | 主机名 |
| 192.168.1.61 | |
| 192.168.1.62 | |
| 192.168.1.63 | k8s-master01 |
| 192.168.1.64 | k8s-master02 |
| 192.168.1.65 | k8s-node01 |
| 192.168.1.66 | k8s-node02 |
自签SSL证书
| 组件 | 适用的证书 |
| etcd | ca.pem server.pem server-key.pem |
| flannel | ca.pem server.pem server-key.pem |
| kube-apiserver | ca.pem server.pem server-key.pem |
| kubelet | ca.pem ca-key.pem |
| kube-proxy | ca.pem kube-proxy.pem kube-proxy.pem |
| kubeclt | ca.pem admin.pem admin-key.pem |
4.Etcd数据库集群部署
下载cfssl工具
1 2 3 4 5 6 7 | wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64chmod +x cfssl_linux-amd64 cfssljson_linux-amd64 cfssl-certinfo_linux-amd64mv cfssl_linux-amd64 /usr/local/bin/cfsslmv cfssljson_linux-amd64 /usr/local/bin/cfssljsonmv cfssl-certinfo_linux-amd64 /usr/bin/cfssl-certinfo |
生产json文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | cat > ca-config.json <<EOF{ "signing": { "default": { "expiry": "87600h" }, "profiles": { "www": { "expiry": "87600h", "usages": [ "signing", "key encipherment", "server auth", "client auth" ] } } }}EOF |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | cat > ca-csr.json <<EOF{ "CN": "etcd CA", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "Beijing", "ST": "Beijing" } ]}EOF |
生产ca证书
1 | cfssl gencert -initca ca-csr.json | cfssljson -bare ca - |
会在当前目录生成一下两个证书

生成etcd域名证书,没有域名使用IP代替这里部署etcd的三台服务器的IP分别为192.168.1.63 192.168.1.65 192.168.1.66
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | cat > server-csr.json <<EOF{ "CN": "etcd", "hosts": [ "192.168.1.63", "192.168.1.65", "192.168.1.66" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing" } ]}EOF |
生成证书
1 | cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server |
生成以下两个证书

两次生成证书的命令生成以下证书

部署etcd
以下操作在etcd的三个节点63 65 66均执行一遍,三个节点不同的地方是配置文件的ip不同
下载二进制包,下载地址是https://github.com/etcd-io/etcd/releases/tag/
本次部署下载包为etcd-v3.3.10-linux-amd64.tar.gz
创建etcd执行文件配置文件及ssl证书目录
1 | mkdir /opt/etcd/{bin,cfg,ssl} -p |
解压压缩包
1 | tar -xf etcd-v3.3.10-linux-amd64.tar.gz |
复制可执行文件
1 | cp etcd-v3.3.10-linux-amd64/etcd etcd-v3.3.10-linux-amd64/etcdctl /opt/etcd/bin/ |
创建etcd配置文件
1 | /opt/etcd/cfg/etcd |
内容如下
1 2 3 4 5 6 7 8 9 10 11 12 13 | # cat /opt/etcd/cfg/etcd #[Member]ETCD_NAME="etcd01"ETCD_DATA_DIR="/var/lib/etcd/default.etcd"ETCD_LISTEN_PEER_URLS="https://192.168.1.63:2380"ETCD_LISTEN_CLIENT_URLS="https://192.168.1.63:2379"#[Clustering]ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.1.63:2380"ETCD_ADVERTISE_CLIENT_URLS="https://192.168.1.63:2379"ETCD_INITIAL_CLUSTER="etcd01=https://192.168.1.63:2380,etcd02=https://192.168.1.65:2380,etcd03=https://192.168.1.66:2380"ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"ETCD_INITIAL_CLUSTER_STATE="new" |
变量说明
1 2 3 4 5 6 7 8 9 | ETCD_NAME 节点名称ETCD_DATA_DIR 数据目录ETCD_LISTEN_PEER_URLS 集群通信监听地址ETCD_LISTEN_CLIENT_URLS 客户端访问监听地址ETCD_INITIAL_ADVERTISE_PEER_URLS 集群通告地址ETCD_ADVERTISE_CLIENT_URLS 客户端通告地址ETCD_INITIAL_CLUSTER 集群节点地址ETCD_INITIAL_CLUSTER_TOKEN 集群TokenETCD_INITIAL_CLUSTER_STATE 加入集群的当前状态,new是新集群,existing表示加入已有集群 |
创建systemd管理etcd文件
1 | /usr/lib/systemd/system/etcd.service |
内容如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | [Unit]Description=Etcd ServerAfter=network.targetAfter=network-online.targetWants=network-online.target[Service]Type=notifyEnvironmentFile=/opt/etcd/cfg/etcdExecStart=/opt/etcd/bin/etcd \--name=${ETCD_NAME} \--data-dir=${ETCD_DATA_DIR} \--listen-peer-urls=${ETCD_LISTEN_PEER_URLS} \--listen-client-urls=${ETCD_LISTEN_CLIENT_URLS},http://127.0.0.1:2379 \--advertise-client-urls=${ETCD_ADVERTISE_CLIENT_URLS} \--initial-advertise-peer-urls=${ETCD_INITIAL_ADVERTISE_PEER_URLS} \--initial-cluster=${ETCD_INITIAL_CLUSTER} \--initial-cluster-token=${ETCD_INITIAL_CLUSTER_TOKEN} \--initial-cluster-state=new \--cert-file=/opt/etcd/ssl/server.pem \--key-file=/opt/etcd/ssl/server-key.pem \--peer-cert-file=/opt/etcd/ssl/server.pem \--peer-key-file=/opt/etcd/ssl/server-key.pem \--trusted-ca-file=/opt/etcd/ssl/ca.pem \--peer-trusted-ca-file=/opt/etcd/ssl/ca.pemRestart=on-failureLimitNOFILE=65536 |
2024-05-13补充
使用Rocky系统安装后enable etcd出现以下错误
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # systemctl daemon-reloadsystemctl start etcdsystemctl enable etcdThe unit files have no installation config (WantedBy=, RequiredBy=, Also=,Alias= settings in the [Install] section, and DefaultInstance= for templateunits). This means they are not meant to be enabled or disabled using systemctl. Possible reasons for having this kind of units are:• A unit may be statically enabled by being symlinked from another unit's .wants/ or .requires/ directory.• A unit's purpose may be to act as a helper for some other unit which has a requirement dependency on it.• A unit may be started when needed via activation (socket, path, timer, D-Bus, udev, scripted systemctl call, ...).• In case of template units, the unit is meant to be enabled with some instance name specified. |
解决方法
修改文件添加以下内容
1 | /usr/lib/systemd/system/etcd.service |
添加内容如下
1 2 | [Install]WantedBy=multi-user.target |
补充结束
把证书拷贝至配置文件中的证书位置
1 | cp *.pem /opt/etcd/ssl/ |
可以在第一个节点192.168.1.63配置好后使用scp命令把文件夹及文件拷贝至另外两台etcd服务器192.168.1.65 192.168.1.66
1 2 3 4 5 | scp -r /opt/etcd/ root@192.168.1.65:/opt/scp -r /opt/etcd/ root@192.168.1.66:/opt/scp /usr/lib/systemd/system/etcd.service root@192.168.1.65:/usr/lib/systemd/systemscp /usr/lib/systemd/system/etcd.service root@192.168.1.66:/usr/lib/systemd/system |
192.168.1.65 192.168.1.66其他文件不变,只修改配置文件
1 | /opt/etcd/cfg/etcd |
192.168.1.65
1 2 3 4 5 6 7 8 9 10 11 12 13 | # cat /opt/etcd/cfg/etcd #[Member]ETCD_NAME="etcd02"ETCD_DATA_DIR="/var/lib/etcd/default.etcd"ETCD_LISTEN_PEER_URLS="https://192.168.1.65:2380"ETCD_LISTEN_CLIENT_URLS="https://192.168.1.65:2379"#[Clustering]ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.1.65:2380"ETCD_ADVERTISE_CLIENT_URLS="https://192.168.1.65:2379"ETCD_INITIAL_CLUSTER="etcd01=https://192.168.1.63:2380,etcd02=https://192.168.1.65:2380,etcd03=https://192.168.1.66:2380"ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"ETCD_INITIAL_CLUSTER_STATE="new" |
192.168.1.66
1 2 3 4 5 6 7 8 9 10 11 12 13 | # cat /opt/etcd/cfg/etcd #[Member]ETCD_NAME="etcd03"ETCD_DATA_DIR="/var/lib/etcd/default.etcd"ETCD_LISTEN_PEER_URLS="https://192.168.1.66:2380"ETCD_LISTEN_CLIENT_URLS="https://192.168.1.66:2379"#[Clustering]ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.1.66:2380"ETCD_ADVERTISE_CLIENT_URLS="https://192.168.1.66:2379"ETCD_INITIAL_CLUSTER="etcd01=https://192.168.1.63:2380,etcd02=https://192.168.1.65:2380,etcd03=https://192.168.1.66:2380"ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"ETCD_INITIAL_CLUSTER_STATE="new" |
部署完etcd启动并设置开机自启动,三台etcd主机都操作
1 2 3 | systemctl daemon-reloadsystemctl start etcdsystemctl enable etcd |
启动完以后检查etcd集群状态,因为是自建证书需要指定证书路径进行检查
1 2 | cd /opt/etcd/ssl//opt/etcd/bin/etcdctl --ca-file=ca.pem --cert-file=server.pem --key-file=server-key.pem --endpoints="https://192.168.1.63:2379,https://192.168.1.65:2379,https://192.168.1.66:2379" cluster-health |
出现以下提示代表etcd正常
1 2 3 | member 472edcb0986774fe is healthy: got healthy result from https://192.168.1.65:2379member 89e49aedde68fee4 is healthy: got healthy result from https://192.168.1.66:2379member ddaf91a76208ea00 is healthy: got healthy result from https://192.168.1.63:2379 |

如果启动失败查看日志/var/log/message
拍错
如果日出现提示
1 | has already been bootstrapped |
删除etcd数据目录文件夹并新建再重启etcd
1 2 | rm -rf /var/lib/etcd/ mkdir /var/lib/etcd |
5.Node安装Docker
在node安装docker,使用国内阿里源安装,安装参考https://developer.aliyun.com/mirror/docker-ce?spm=a2c6h.13651102.0.0.3e221b117i6d6B
1 2 3 4 5 6 7 8 9 10 11 | # step 1: 安装必要的一些系统工具sudo yum install -y yum-utils device-mapper-persistent-data lvm2# Step 2: 添加软件源信息sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo# Step 3: 更新并安装Docker-CEsudo yum makecache fastsudo yum -y install docker-ce# Step 4: 开启Docker服务sudo service docker start# Step 5:设置开机启动systemctl enable docker |
6.Flannel容器集群网络部署
Kubernetes网络模型设计基本要求
- 一个pod一个IP
- 每个Pod独立IP
- 所有容器都可以与其他容器通信
- 所有节点都可以与所有容器通信
flannel工作原理图

Overlay Network
覆盖网络,在基础网络上叠加一种虚拟网络技术模式,该网络中的主机通过虚拟链路连接起来。
Flannel是Overlay网络的一种,也是将源数据包封装在另一种网络包里进行路由转发和通信,目前支持UDP,VXLAN,Host-GW,AWS VPC和GCE路由等数据转发方式。
Falnnel要用etcd存储一个子网信息,所以要保证能成功连接etcd,写入预定义子网段
在master01 192.168.1.63上操作
1 2 3 4 | #进入证书目录cd /opt/etcd/ssl#设置/opt/etcd/bin/etcdctl --ca-file=ca.pem --cert-file=server.pem --key-file=server-key.pem --endpoints="https://192.168.1.63:2379,https://192.168.1.65:2379,https://192.168.1.66:2379" set /coreos.com/network/config '{ "Network": "172.17.0.0/16", "Backend": {"Type": "vxlan"}}' |
出现以下提示代表设置正常 设置以后创建docker容器的网段即为172.17.0.0/16

把以上命名的set改成get就能获取到设置信息
1 | /opt/etcd/bin/etcdctl --ca-file=ca.pem --cert-file=server.pem --key-file=server-key.pem --endpoints="https://192.168.1.63:2379,https://192.168.1.65:2379,https://192.168.1.66:2379" get /coreos.com/network/config '{ "Network": "172.17.0.0/16", "Backend": {"Type": "vxlan"}}' |
注意:设置的网段信息不要和宿主机网段信息一致,否则可能出现启动docker后无法获取到docker网段的信息
以下配置在node节点192.168.1.65 192.168.1.66配置
下载二进制包
1 2 3 4 5 6 7 | wget https://github.com/coreos/flannel/releases/download/v0.10.0/flannel-v0.10.0-linux-amd64.tar.gz#解压tar -xf flannel-v0.11.0-linux-amd64.tar.gz#创建Kubernetes目录mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}#把解压后的flanneld文件复制到对应目录 cp flanneld mk-docker-opts.sh /opt/kubernetes/bin |
配置flannel配置文件
1 | /opt/kubernetes/cfg/flanneld |
内容如下
1 | FLANNEL_OPTIONS="--etcd-endpoints=https://192.168.1.63:2379,https://192.168.1.65:2379,https://192.168.1.66:2379 -etcd-cafile=/opt/etcd/ssl/ca.pem -etcd-certfile=/opt/etcd/ssl/server.pem -etcd-keyfile=/opt/etcd/ssl/server-key.pem" |
需要把etcd对应的证书拷贝到这个配置文件指定的目录opt/etcd/ssl下
配置system管理flanneld
1 | /usr/lib/systemd/system/flanneld.service |
内容如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # cat /usr/lib/systemd/system/flanneld.service[Unit]Description=Flanneld overlay address etcd agentAfter=network-online.target network.targetBefore=docker.service[Service]Type=notifyEnvironmentFile=/opt/kubernetes/cfg/flanneldExecStart=/opt/kubernetes/bin/flanneld --ip-masq $FLANNEL_OPTIONSExecStartPost=/opt/kubernetes/bin/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/subnet.envRestart=on-failure[Install]WantedBy=multi-user.target |
启动flanneld以后可以查看文件/run/flannel/subnet.env查看子网信息

配置docker使用子网信息
1 | /usr/lib/systemd/system/docker.service |
内容如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | # cat /usr/lib/systemd/system/docker.service [Unit]Description=Docker Application Container EngineDocumentation=https://docs.docker.comAfter=network-online.target firewalld.serviceWants=network-online.target[Service]Type=notifyEnvironmentFile=/run/flannel/subnet.envExecStart=/usr/bin/dockerd $DOCKER_NETWORK_OPTIONSExecReload=/bin/kill -s HUP $MAINPIDLimitNOFILE=infinityLimitNPROC=infinityLimitCORE=infinityTimeoutStartSec=0Delegate=yesKillMode=processRestart=on-failureStartLimitBurst=3StartLimitInterval=60s[Install]WantedBy=multi-user.target |

重启docker和flanneld
1 2 3 | systemctl daemon-reloadsystemctl restart flanneldsystemctl restart docker |
注意:因为docker需要使用到flanneld子网信息所以以上启动顺序为先启动flanneld再启动docker
检查是否生效
1 2 3 | # ps -ef|grep dockerroot 15817 1 2 09:52 ? 00:00:00 /usr/bin/dockerd --bip=172.17.82.1/24 --ip-masq=false --mtu=1450root 15824 15817 0 09:52 ? 00:00:00 containerd --config /var/run/docker/containerd/containerd.toml --log-level info |
确保flannel和docker0在同一网段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # ip addr1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 00:50:56:b7:26:a4 brd ff:ff:ff:ff:ff:ff inet 192.168.1.65/24 brd 192.168.1.255 scope global noprefixroute eth0 valid_lft forever preferred_lft forever3: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default link/ether 1e:87:55:50:7f:31 brd ff:ff:ff:ff:ff:ff inet 172.17.82.0/32 scope global flannel.1 valid_lft forever preferred_lft forever4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default link/ether 02:42:c0:26:ad:3d brd ff:ff:ff:ff:ff:ff inet 172.17.82.1/24 brd 172.17.82.255 scope global docker0 valid_lft forever preferred_lft forever |
同样的操作在node02 192.168.1.66操作一遍
在node2上查看ip
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # ip addr1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 00:50:56:b7:bf:2f brd ff:ff:ff:ff:ff:ff inet 192.168.1.66/24 brd 192.168.1.255 scope global noprefixroute eth0 valid_lft forever preferred_lft forever3: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default link/ether de:df:37:b7:be:5c brd ff:ff:ff:ff:ff:ff inet 172.17.30.0/32 scope global flannel.1 valid_lft forever preferred_lft forever4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default link/ether 02:42:38:91:f2:c4 brd ff:ff:ff:ff:ff:ff inet 172.17.30.1/24 brd 172.17.30.255 scope global docker0 valid_lft forever preferred_lft forever |
测试不同node节点互通

如果能通说明Flannel部署成功。如果不通检查下日志:journalctl -u flannel
两个node启动一个容器ping测试
1 | docker run -it busybox |
7.部署Master组件
在部署Kubernetes之前一定要确保etcd、flannel、docker是正常工作的,否则先解决问题再继续。
在master01 192.168.1.63上操作
创建CA证书
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | cd /root/k8s/k8s-cert# cat ca-config.json { "signing": { "default": { "expiry": "87600h" }, "profiles": { "kubernetes": { "expiry": "87600h", "usages": [ "signing", "key encipherment", "server auth", "client auth" ] } } }}# cat ca-csr.json { "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "Beijing", "ST": "Beijing", "O": "k8s", "OU": "System" } ]}cfssl gencert -initca ca-csr.json | cfssljson -bare ca - |
生成以下两个证书

创建apiserver证书
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | # cat server-csr.json { "CN": "kubernetes", "hosts": [ "10.0.0.1", "127.0.0.1", "192.168.1.60", "192.168.1.61", "192.168.1.62", "192.168.1.63", "192.168.1.64", "192.168.1.65", "192.168.1.66", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing", "O": "k8s", "OU": "System" } ]} |
为了不遗漏这里把所有ip都填上
1 | cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes server-csr.json | cfssljson -bare server |
生成以下两个证书

创建kube-proxy证书
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | # cat kube-proxy-csr.json { "CN": "system:kube-proxy", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing", "O": "k8s", "OU": "System" } ]} |
1 | cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy |
生成以下证书

最终生成6个证书
1 2 | # ls *.pemca-key.pem ca.pem kube-proxy-key.pem kube-proxy.pem server-key.pem server.pem |
部署apiserver组件
下载二进制包下载地址https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.13.md#server-binaries-8
本次下载v1.13.4包

创建Kubernetes目录
1 | mkdir /opt/kubernetes/{bin,cfg,ssl,logs} -p |
解压并且把可执行文件放置在对应目录
1 2 3 | tar -xf kubernetes-server-linux-amd64.tar.gzcd kubernetes/server/bin/usr/bin/cp kube-apiserver kube-scheduler kube-controller-manager kubectl /opt/kubernetes/bin/ |
创建token文件
1 2 3 4 5 | export BOOTSTRAP_TOKEN=$(head -c 16 /dev/urandom | od -An -t x | tr -d ' ')cat > token.csv <<EOF${BOOTSTRAP_TOKEN},kubelet-bootstrap,10001,"system:kubelet-bootstrap"EOFcp token.csv /opt/kubernetes/cfg/ |
token文件内容如下
1 2 | # cat /opt/kubernetes/cfg/token.csv 9015cf068f594553a06fc70e4367c3a4,kubelet-bootstrap,10001,"system:kubelet-bootstrap" |
第一列:随机字符串,自己可生成
第二列:用户名
第三列:UID
第四列:用户组
创建apiserver配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | # cat /opt/kubernetes/cfg/kube-apiserver KUBE_APISERVER_OPTS="--logtostderr=false \--log-dir=/opt/kubernetes/logs \--v=4 \--etcd-servers=https://192.168.1.63:2379,https://192.168.1.65:2379,https://192.168.1.66:2379 \--insecure-bind-address=127.0.0.1 \--bind-address=192.168.1.63 \--insecure-port=8080 \--secure-port=6443 \--advertise-address=192.168.1.63 \--allow-privileged=true \--service-cluster-ip-range=10.0.0.0/24 \#--admission-control=NamespaceLifecycle,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota,NodeRestriction --authorization-mode=RBAC,Node \--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \--kubelet-https=true \--enable-bootstrap-token-auth \--token-auth-file=/opt/kubernetes/cfg/token.csv \--service-node-port-range=30000-50000 \--tls-cert-file=/opt/kubernetes/ssl/server.pem \--tls-private-key-file=/opt/kubernetes/ssl/server-key.pem \--client-ca-file=/opt/kubernetes/ssl/ca.pem \--service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \--etcd-cafile=/opt/etcd/ssl/ca.pem \--etcd-certfile=/opt/etcd/ssl/server.pem \--etcd-keyfile=/opt/etcd/ssl/server-key.pem" |
配置好前面生成的证书,确保能连接etcd
参数说明
1 2 3 4 5 6 7 8 9 10 11 12 13 | --logtostderr 启用日志---v 日志等级--etcd-servers etcd集群地址--bind-address 监听地址--secure-port https安全端口--advertise-address 集群通告地址--allow-privileged 启用授权--service-cluster-ip-range Service虚拟IP地址段--enable-admission-plugins 准入控制模块--authorization-mode 认证授权,启用RBAC授权和节点自管理--enable-bootstrap-token-auth 启用TLS bootstrap功能,后面会讲到--token-auth-file token文件--service-node-port-range Service Node类型默认分配端口范围 |
配置system管理apiserver
1 2 3 4 5 6 7 8 9 10 11 12 | # cat /usr/lib/systemd/system/kube-apiserver.service [Unit]Description=Kubernetes API ServerDocumentation=https://github.com/kubernetes/kubernetes[Service]EnvironmentFile=-/opt/kubernetes/cfg/kube-apiserverExecStart=/opt/kubernetes/bin/kube-apiserver $KUBE_APISERVER_OPTSRestart=on-failure[Install]WantedBy=multi-user.target |
启动
1 2 3 | systemctl daemon-reloadsystemctl enable kube-apiserversystemctl restart kube-apiserver |

部署scheduler组件
创建schduler配置文件
1 2 3 4 5 6 | # cat /opt/kubernetes/cfg/kube-scheduler KUBE_SCHEDULER_OPTS="--logtostderr=true \--v=4 \--master=127.0.0.1:8080 \--leader-elect" |
参数说明
1 2 | --master 连接本地apiserver--leader-elect 当该组件启动多个时,自动选举(HA) |
创建system管理schduler组件
1 2 3 4 5 6 7 8 9 10 11 12 | # cat /usr/lib/systemd/system/kube-scheduler.service [Unit]Description=Kubernetes SchedulerDocumentation=https://github.com/kubernetes/kubernetes [Service]EnvironmentFile=-/opt/kubernetes/cfg/kube-schedulerExecStart=/opt/kubernetes/bin/kube-scheduler $KUBE_SCHEDULER_OPTSRestart=on-failure [Install]WantedBy=multi-user.target |
启动
1 2 3 | # systemctl daemon-reload# systemctl enable kube-scheduler# systemctl restart kube-scheduler |

部署controllers-manager组件
创建controllers-manager配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # cat /opt/kubernetes/cfg/kube-controller-manager KUBE_CONTROLLER_MANAGER_OPTS="--logtostderr=true \--v=4 \--master=127.0.0.1:8080 \--leader-elect=true \--address=127.0.0.1 \--service-cluster-ip-range=10.0.0.0/24 \#--service-cluster-ip-range=172.17.0.0/16 \--cluster-name=kubernetes \--cluster-signing-cert-file=/opt/kubernetes/ssl/ca.pem \--cluster-signing-key-file=/opt/kubernetes/ssl/ca-key.pem \--root-ca-file=/opt/kubernetes/ssl/ca.pem \--service-account-private-key-file=/opt/kubernetes/ssl/ca-key.pem \--experimental-cluster-signing-duration=87600h0m0s" |
PS:这里master配置必须是127.0.0.1而不能是192.168.1.63否则会出现连接拒绝的报错信息

system管理controllers-manager
1 2 3 4 5 6 7 8 9 10 11 12 | # cat /usr/lib/systemd/system/kube-controller-manager.service [Unit]Description=Kubernetes Controller ManagerDocumentation=https://github.com/kubernetes/kubernetes [Service]EnvironmentFile=-/opt/kubernetes/cfg/kube-controller-managerExecStart=/opt/kubernetes/bin/kube-controller-manager $KUBE_CONTROLLER_MANAGER_OPTSRestart=on-failure [Install]WantedBy=multi-user.target |
启动
1 2 3 | # systemctl daemon-reload# systemctl enable kube-controller-manager# systemctl restart kube-controller-manager |
所有组件都已经启动成功,通过kubectl工具查看当前集群组件状态:
1 2 3 4 5 6 7 | /opt/kubernetes/bin/kubectl get csNAME STATUS MESSAGE ERRORcontroller-manager Healthy ok scheduler Healthy ok etcd-1 Healthy {"health":"true"} etcd-2 Healthy {"health":"true"} etcd-0 Healthy {"health":"true"} |
8.部署Node组件
Master apiserver启用TLS认证后,Node节点kubelet组件想要加入集群,必须使用CA签发的有效证书才能与apiserver通信,当Node节点很多时,签署证书是一件很繁琐的事情,因此有了TLS Bootstrapping机制,kubelet会以一个低权限用户自动向apiserver申请证书,kubelet的证书由apiserver动态签署。
认证大致工作流程如图所示:

在master01上操作,将kubelet-bootstrap用户绑定到系统集群角色
1 | kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap |
查看
1 | kubectl get clusterrolebinding |
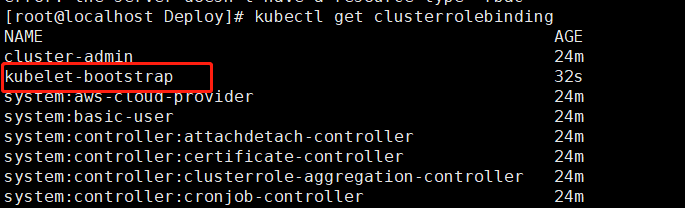
创建kubeconfig文件
在kubernetes证书目录/opt/kubernetes/ssl下执行以下命令生成kubeconfig文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | #创建kubelet bootstrapping kubeconfig#该token需要与配置文件中/opt/kubernetes/cfg/token.csv一致BOOTSTRAP_TOKEN=9015cf068f594553a06fc70e4367c3a4KUBE_APISERVER="https://192.168.1.63:6443"# 设置集群参数kubectl config set-cluster kubernetes \ --certificate-authority=./ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=bootstrap.kubeconfig# 设置客户端认证参数kubectl config set-credentials kubelet-bootstrap \ --token=${BOOTSTRAP_TOKEN} \ --kubeconfig=bootstrap.kubeconfig# 设置上下文参数kubectl config set-context default \ --cluster=kubernetes \ --user=kubelet-bootstrap \ --kubeconfig=bootstrap.kubeconfig# 设置默认上下文kubectl config use-context default --kubeconfig=bootstrap.kubeconfig#----------------------# 创建kube-proxy kubeconfig文件kubectl config set-cluster kubernetes \ --certificate-authority=./ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=kube-proxy.kubeconfigkubectl config set-credentials kube-proxy \ --client-certificate=./kube-proxy.pem \ --client-key=./kube-proxy-key.pem \ --embed-certs=true \ --kubeconfig=kube-proxy.kubeconfigkubectl config set-context default \ --cluster=kubernetes \ --user=kube-proxy \ --kubeconfig=kube-proxy.kubeconfigkubectl config use-context default --kubeconfig=kube-proxy.kubeconfig |
生成以下两个配置文件

将这两个文件拷贝至node的目录/opt/kubernetes/cfg下
在两个node192.168.1.65 192.168.1.66部署kubelet组件
将前面下载的二进制包中的kubelet和kube-proxy拷贝到/opt/kubernetes/bin目录下
创建kubelet配置文件
1 2 3 4 5 6 7 8 9 | # cat /opt/kubernetes/cfg/kubeletKUBELET_OPTS="--logtostderr=true \--v=4 \--hostname-override=192.168.1.65 \--kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \--bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \--config=/opt/kubernetes/cfg/kubelet.config \--cert-dir=/opt/kubernetes/ssl \--pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0" |
参数说明
1 2 3 4 5 | --hostname-override 在集群中显示的主机名--kubeconfig 指定kubeconfig文件位置,会自动生成--bootstrap-kubeconfig 指定刚才生成的bootstrap.kubeconfig文件--cert-dir 颁发证书存放位置--pod-infra-container-image 管理Pod网络的镜像 |
其中/opt/kubernetes/cfg/kubelet.config配置文件如下:
1 2 3 4 5 6 7 8 9 10 11 12 | kind: KubeletConfigurationapiVersion: kubelet.config.k8s.io/v1beta1address: 192.168.1.65port: 10250readOnlyPort: 10255cgroupDriver: cgroupfsclusterDNS: ["10.0.0.2"]clusterDomain: cluster.local.failSwapOn: falseauthentication: anonymous: enabled: true |
system管理kubelet
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # cat /usr/lib/systemd/system/kubelet.service [Unit]Description=Kubernetes KubeletAfter=docker.serviceRequires=docker.service[Service]EnvironmentFile=/opt/kubernetes/cfg/kubeletExecStart=/opt/kubernetes/bin/kubelet $KUBELET_OPTSRestart=on-failureKillMode=process[Install]WantedBy=multi-user.target |
启动
1 2 3 | # systemctl daemon-reload# systemctl enable kubelet# systemctl restart kubelet |
启动后会在目录下自动生成证书
1 2 3 4 | # pwd/opt/kubernetes/ssl[root@k8s-node01 ssl]# lskubelet-client.key.tmp kubelet.crt kubelet.key |
注意:如果启动kubelet失败则检查docker和网络服务flanneld是否启动
如果虚拟机是从其他node克隆而来在修改配置以后启动需要先删除ssl下所有证书,否则启动会报以下错误
1 | node "192.168.1.67" not found |
启动后没有加入到集群,需要在master手动添加
处于Pending状态
1 2 3 | # kubectl get csrNAME AGE REQUESTOR CONDITIONnode-csr-LvL9p0VJzJOAiLbjLMPNoMKYVcpU0aQ2OTG-tTJD5Ho 7m20s kubelet-bootstrap Pending |
使用命令添加即可kubectl certificate approve
1 2 3 4 5 | # kubectl get csrNAME AGE REQUESTOR CONDITIONnode-csr-hL-XazsjjMvWzkrdg7ePgmu9IRd5SBIFtqLkvqwxEc4 41m kubelet-bootstrap Approved,Issuednode-csr-uM16cNRQFg5S6UHeiMFprfO3dNBQp5udk74CvbSqv5E 48m kubelet-bootstrap Approved,Issued#kubectl certificate approve node-csr-hL-XazsjjMvWzkrdg7ePgmu9IRd5SBIFtqLkvqwxEc4 |
添加完查看node是否加入集群
1 2 3 4 | # kubectl get nodeNAME STATUS ROLES AGE VERSION192.168.1.65 Ready <none> 22m v1.12.10192.168.1.66 Ready <none> 22m v1.12.10 |
部署kube-proxy组件
创建kube-proxy配置文件
1 2 3 4 5 6 | # cat /opt/kubernetes/cfg/kube-proxyKUBE_PROXY_OPTS="--logtostderr=true \--v=4 \--hostname-override=192.168.1.65 \--cluster-cidr=10.0.0.0/24 \--kubeconfig=/opt/kubernetes/cfg/kube-proxy.kubeconfig" |
system管理kube-proxy
1 2 3 4 5 6 7 8 9 10 11 12 | # cat /usr/lib/systemd/system/kube-proxy.service [Unit]Description=Kubernetes ProxyAfter=network.target[Service]EnvironmentFile=-/opt/kubernetes/cfg/kube-proxyExecStart=/opt/kubernetes/bin/kube-proxy $KUBE_PROXY_OPTSRestart=on-failure[Install]WantedBy=multi-user.target |
启动
1 2 3 | # systemctl daemon-reload# systemctl enable kube-proxy# systemctl restart kube-proxy |

node2 192.168.1.66上面部署方式一样
集群部署完成,在master 192.168.1.63查看集群状态
1 2 3 4 5 6 7 8 9 10 11 | # kubectl get nodeNAME STATUS ROLES AGE VERSION192.168.1.65 Ready <none> 122m v1.13.4192.168.1.66 Ready <none> 118m v1.13.4[root@localhost ~]# kubectl get csNAME STATUS MESSAGE ERRORscheduler Healthy ok controller-manager Healthy ok etcd-0 Healthy {"health":"true"} etcd-2 Healthy {"health":"true"} etcd-1 Healthy {"health":"true"} |
9.部署一个测试示例
Kubernetes集群部署完毕,在master上面部署一个nginx测试
1 2 3 4 5 6 | #创建一个deployment名称为nginx使用镜像为nginxkubectl create deployment nginx --image=nginx#创建一个service对应的deloyment为nginx 集群内部端口为80对外使用NodePort暴露端口kubectl expose deployment nginx --port=80 --type=NodePort#查看pod和svckubectl get pod,svc |
删除deployment和svc
1 2 | kubectl delete deployment nginxkubectl delete svc nginx |
注意:创建deployment之前确保node节点的kube-proxy服务已经部署正常,否则创建了svc后不对外映射对应的随机端口,并且没有报错信息

通过web访问访问方式为node ip加对应端口192.168.1.65:47679

10.部署Web UI(Dashboard)
部署UI的配置文件可以在以下地址下载https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/dashboard

下载部署配置文件
1 2 3 4 5 6 7 8 9 10 | # cat dashboard-configmap.yaml apiVersion: v1kind: ConfigMapmetadata: labels: k8s-app: kubernetes-dashboard # Allows editing resource and makes sure it is created first. addonmanager.kubernetes.io/mode: EnsureExists name: kubernetes-dashboard-settings namespace: kube-system |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | # cat dashboard-rbac.yaml kind: RoleapiVersion: rbac.authorization.k8s.io/v1metadata: labels: k8s-app: kubernetes-dashboard addonmanager.kubernetes.io/mode: Reconcile name: kubernetes-dashboard-minimal namespace: kube-systemrules: # Allow Dashboard to get, update and delete Dashboard exclusive secrets.- apiGroups: [""] resources: ["secrets"] resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs"] verbs: ["get", "update", "delete"] # Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map.- apiGroups: [""] resources: ["configmaps"] resourceNames: ["kubernetes-dashboard-settings"] verbs: ["get", "update"] # Allow Dashboard to get metrics from heapster.- apiGroups: [""] resources: ["services"] resourceNames: ["heapster"] verbs: ["proxy"]- apiGroups: [""] resources: ["services/proxy"] resourceNames: ["heapster", "http:heapster:", "https:heapster:"] verbs: ["get"]---apiVersion: rbac.authorization.k8s.io/v1kind: RoleBindingmetadata: name: kubernetes-dashboard-minimal namespace: kube-system labels: k8s-app: kubernetes-dashboard addonmanager.kubernetes.io/mode: ReconcileroleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: kubernetes-dashboard-minimalsubjects:- kind: ServiceAccount name: kubernetes-dashboard namespace: kube-system |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | # cat dashboard-secret.yaml apiVersion: v1kind: Secretmetadata: labels: k8s-app: kubernetes-dashboard # Allows editing resource and makes sure it is created first. addonmanager.kubernetes.io/mode: EnsureExists name: kubernetes-dashboard-certs namespace: kube-systemtype: Opaque---apiVersion: v1kind: Secretmetadata: labels: k8s-app: kubernetes-dashboard # Allows editing resource and makes sure it is created first. addonmanager.kubernetes.io/mode: EnsureExists name: kubernetes-dashboard-key-holder namespace: kube-systemtype: Opaque |
修改镜像地址为国内地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 | # cat dashboard-deployment.yaml apiVersion: v1kind: ServiceAccountmetadata: labels: k8s-app: kubernetes-dashboard addonmanager.kubernetes.io/mode: Reconcile name: kubernetes-dashboard namespace: kube-system---apiVersion: apps/v1kind: Deploymentmetadata: name: kubernetes-dashboard namespace: kube-system labels: k8s-app: kubernetes-dashboard addonmanager.kubernetes.io/mode: Reconcilespec: selector: matchLabels: k8s-app: kubernetes-dashboard template: metadata: labels: k8s-app: kubernetes-dashboard annotations: seccomp.security.alpha.kubernetes.io/pod: 'docker/default' spec: priorityClassName: system-cluster-critical containers: - name: kubernetes-dashboard image: lizhenliang/kubernetes-dashboard-amd64:v1.10.1 #image: huanwei/kubernetes-dashboard-amd64 resources: limits: cpu: 100m memory: 300Mi requests: cpu: 50m memory: 100Mi ports: - containerPort: 8443 protocol: TCP args: # PLATFORM-SPECIFIC ARGS HERE - --auto-generate-certificates volumeMounts: - name: kubernetes-dashboard-certs mountPath: /certs - name: tmp-volume mountPath: /tmp livenessProbe: httpGet: scheme: HTTPS path: / port: 8443 initialDelaySeconds: 30 timeoutSeconds: 30 volumes: - name: kubernetes-dashboard-certs secret: secretName: kubernetes-dashboard-certs - name: tmp-volume emptyDir: {} serviceAccountName: kubernetes-dashboard #nodeSelector: # "kubernetes.io/os": linux tolerations: - key: "CriticalAddonsOnly" operator: "Exists" |
设置NodePort端口为3001
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | # cat dashboard-service.yaml apiVersion: v1kind: Servicemetadata: name: kubernetes-dashboard namespace: kube-system labels: k8s-app: kubernetes-dashboard kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcilespec: selector: k8s-app: kubernetes-dashboard type: NodePort ports: - port: 443 targetPort: 8443 nodePort: 30001 |
应用 本次一次性应用目录下所有配置文件
1 2 3 4 5 6 7 8 9 | # kubectl apply -f .configmap/kubernetes-dashboard-settings createdserviceaccount/kubernetes-dashboard createddeployment.apps/kubernetes-dashboard createdrole.rbac.authorization.k8s.io/kubernetes-dashboard-minimal createdrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard-minimal createdsecret/kubernetes-dashboard-certs createdsecret/kubernetes-dashboard-key-holder createdservice/kubernetes-dashboard created |
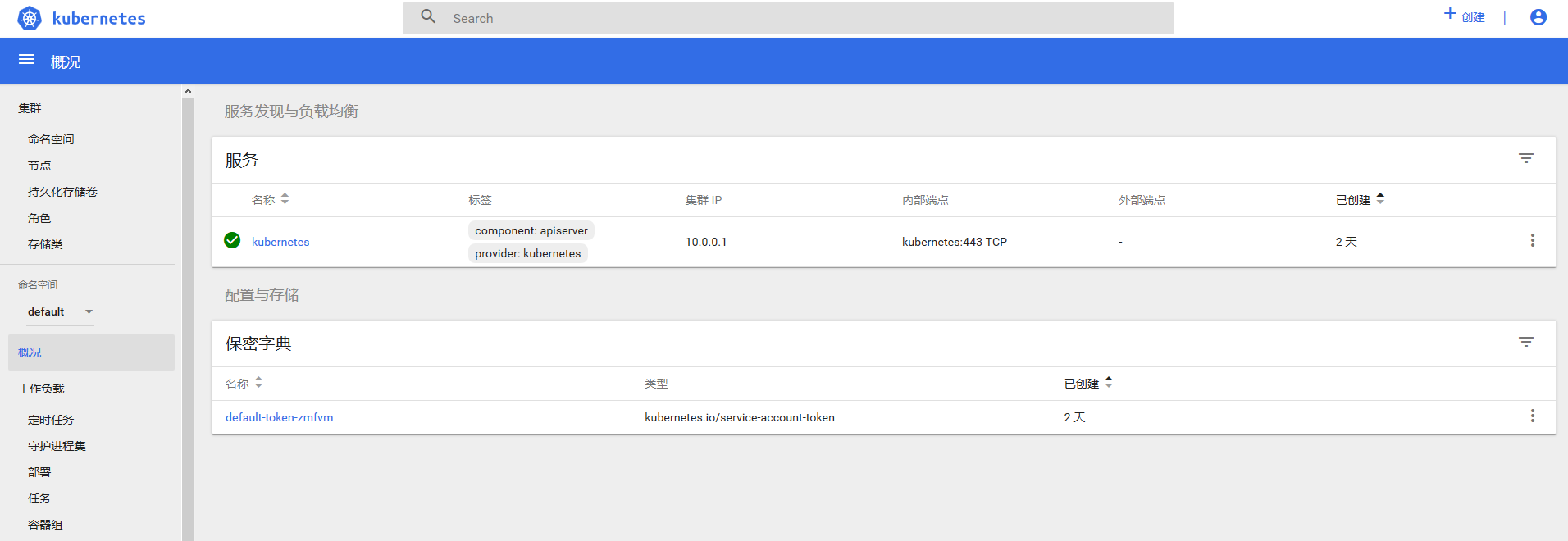
查看
1 2 3 4 5 6 | # kubectl get pod,svc -n kube-systemNAME READY STATUS RESTARTS AGEpod/kubernetes-dashboard-88ffb5bfc-7sjw4 1/1 Running 0 2m9sNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEservice/kubernetes-dashboard NodePort 10.0.0.114 <none> 443:30001/TCP 6m50s |
创建面向应用的用户
1 | kubectl create serviceaccount dashboard-admin -n kube-system |
集群角色绑定,设置最高的管理员权限
1 | kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin |
获取登录的token令牌
1 | kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}') |
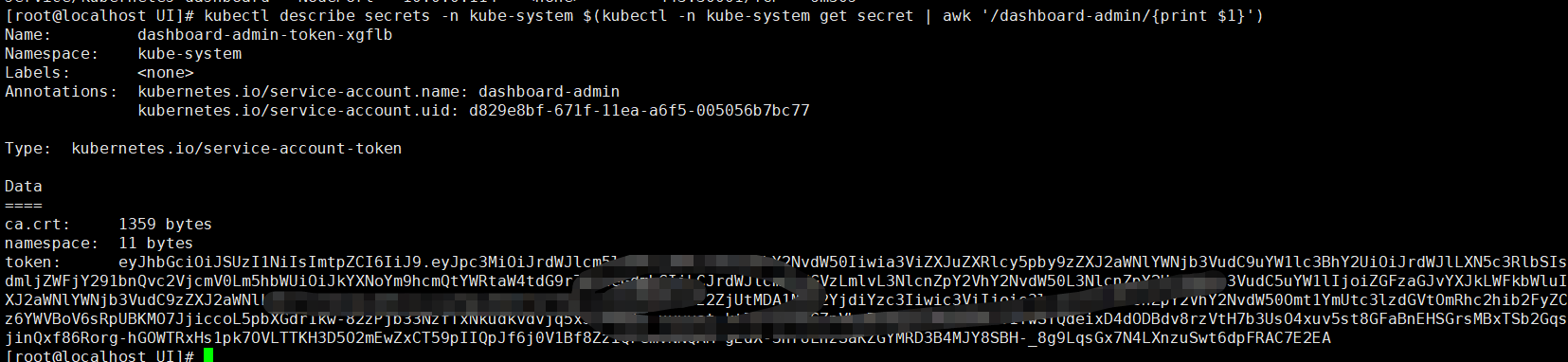
web页面登录https://nodeip:30001需要使用https登录 输入刚刚获取的token
11.部署多master
学习及测试部署单master即可满足需要,生产需要部署多master
从master01 192.168.1.63拷贝配置文件至master02
1 2 3 4 5 6 | scp -r /opt/kubernetes/ root@192.168.1.64:/opt/scp /usr/lib/systemd/system/kube-apiserver.service root@192.168.1.64:/usr/lib/systemd/systemscp /usr/lib/systemd/system/kube-controller-manager.service root@192.168.1.64:/usr/lib/systemd/systemscp /usr/lib/systemd/system/kube-scheduler.service root@192.168.1.64:/usr/lib/systemd/system#etcd文件也需要拷贝,需要etcd的ssl证书scp -r /opt/etcd/ root@192.168.1.64:/opt/ |
修改配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | # cat kube-apiserver KUBE_APISERVER_OPTS="--logtostderr=false \--log-dir=/opt/kubernetes/logs \--v=4 \--etcd-servers=https://192.168.1.63:2379,https://192.168.1.65:2379,https://192.168.1.66:2379 \--insecure-bind-address=127.0.0.1 \--bind-address=192.168.1.64 \--insecure-port=8080 \--secure-port=6443 \--advertise-address=192.168.1.64 \--allow-privileged=true \--service-cluster-ip-range=10.10.10.0/24 \--admission-control=NamespaceLifecycle,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota,NodeRestriction --authorization-mode=RBAC,Node \--kubelet-https=true \--enable-bootstrap-token-auth \--token-auth-file=/opt/kubernetes/cfg/token.csv \--service-node-port-range=30000-50000 \--tls-cert-file=/opt/kubernetes/ssl/server.pem \--tls-private-key-file=/opt/kubernetes/ssl/server-key.pem \--client-ca-file=/opt/kubernetes/ssl/ca.pem \--service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \--etcd-cafile=/opt/etcd/ssl/ca.pem \--etcd-certfile=/opt/etcd/ssl/server.pem \--etcd-keyfile=/opt/etcd/ssl/server-key.pem" |
需要修改--bind-address 和--advertise-address对应ip地址,其他配置文件使用本机ip 127.0.0.1无需修改
启动
1 2 3 4 5 6 | systemctl status kube-apiserver systemctl restart kube-controller-manager systemctl restart kube-scheduler systemctl enable kube-apiserver systemctl enable kube-controller-manager systemctl enable kube-scheduler |
部署load balaner本次使用nginx
在192.168.1.61操作
yum安装nginx
1 | yum -y install nginx |
查看编译信息,默认包负载均衡参数--with-stream
四层负载均衡参考https://www.cnblogs.com/minseo/p/10288379.html
1 | nginx -V |
修改配置文件,增加四层负载均衡配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 | # cat /etc/nginx/nginx.conf# For more information on configuration, see:# * Official English Documentation: http://nginx.org/en/docs/# * Official Russian Documentation: http://nginx.org/ru/docs/user nginx;worker_processes auto;error_log /var/log/nginx/error.log;pid /run/nginx.pid;# Load dynamic modules. See /usr/share/doc/nginx/README.dynamic.include /usr/share/nginx/modules/*.conf;events { worker_connections 1024;}stream { upstream k8s-apiserver{ server 192.168.1.63:6443; server 192.168.1.64:6443; } server { listen 192.168.1.61:6443; proxy_pass k8s-apiserver; }}http { log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65; types_hash_max_size 2048; include /etc/nginx/mime.types; default_type application/octet-stream; # Load modular configuration files from the /etc/nginx/conf.d directory. # See http://nginx.org/en/docs/ngx_core_module.html#include # for more information. include /etc/nginx/conf.d/*.conf; server { listen 80 default_server; listen [::]:80 default_server; server_name _; root /usr/share/nginx/html; # Load configuration files for the default server block. include /etc/nginx/default.d/*.conf; location / { } error_page 404 /404.html; location = /40x.html { } error_page 500 502 503 504 /50x.html; location = /50x.html { } }# Settings for a TLS enabled server.## server {# listen 443 ssl http2 default_server;# listen [::]:443 ssl http2 default_server;# server_name _;# root /usr/share/nginx/html;## ssl_certificate "/etc/pki/nginx/server.crt";# ssl_certificate_key "/etc/pki/nginx/private/server.key";# ssl_session_cache shared:SSL:1m;# ssl_session_timeout 10m;# ssl_ciphers HIGH:!aNULL:!MD5;# ssl_prefer_server_ciphers on;## # Load configuration files for the default server block.# include /etc/nginx/default.d/*.conf;## location / {# }## error_page 404 /404.html;# location = /40x.html {# }## error_page 500 502 503 504 /50x.html;# location = /50x.html {# }# }} |

重启使配置生效
1 | systemctl restart nginx |
查看
1 2 | # netstat -antp|grep 6443tcp 0 0 192.168.1.61:6443 0.0.0.0:* LISTEN 29759/nginx: master |
已经在nginx代理了两个后端服务器的6443端口,然后在node01 node02上面修改配置文件
1 | /opt/kubernetes/cfg/bootstrap.kubeconfig |

1 | /opt/kubernetes/cfg/kubelet.kubeconfig |

1 | /opt/kubernetes/cfg/kube-proxy.kubeconfig |

重启
1 | systemctl restart kubelet<br>systemctl restart kube-proxy |
node02 192.168.1.66进行同样修改操作后重启
为了查看负载均衡日志,修改nginx配置文件在stream增加两行记录日志
1 2 | log_format main "$remote_addr $upstream_addr - $time_local $status"; access_log /var/log/nginx/k8s-access.log main; |

重启nginx
1 | systemctl restart nginx |
重启node的kubelet查看日志
1 | systemctl restart kubelet |
192.168.1.61 查看日志
1 2 3 | # tail -f /var/log/nginx/k8s-access.log 192.168.1.65 192.168.1.63:6443 - 02/Mar/2020:11:36:46 +0800 200192.168.1.65 192.168.1.64:6443 - 02/Mar/2020:11:36:46 +0800 200 |
在master上面查看node状态是正常的及代表负载均衡通信正常
1 | kubectl get node |
在负载均衡backup 192.168.1.62同样安装nginx修改配置文件,启动nginx
使用keepalived创建一个虚拟ip实现高可用 keepalived+nginx高可用参考https://www.cnblogs.com/minseo/p/9216499.html
在nginx master 192.168.1.61 和 nginx backup 192.168.1.62安装keepalived
1 | yum -y install keepalived |
nginx master修改配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 192.168.200.1 smtp_connect_timeout 30 router_id LVS_DEVEL vrrp_skip_check_adv_addr #vrrp_strict #需要注释否则VIP不通 vrrp_garp_interval 0 vrrp_gna_interval 0}vrrp_instance VI_1 { state MASTER #master节点 interface eth0 #绑定的网口是eth0 virtual_router_id 51#ip 需要唯一主备一致 priority 150 #优先级,优先级越高越优秀占用VIP advert_int 1 authentication { auth_type PASS #认证 auth_pass 1111 #认证密码需要相同 } virtual_ipaddress { 192.168.1.60/24 dev eth0 label eth0:1 #设置VIP }} |
backup配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 192.168.200.1 smtp_connect_timeout 30 router_id LVS_DEVEL vrrp_skip_check_adv_addr #vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0}vrrp_instance VI_1 { state BACKEND interface eth0 virtual_router_id 52 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.1.60/24 dev eth0 label eth0:1 }} |
有如下不同 state为BACKEND
优先级低于master
启动keepalived
1 2 | systemctl start keepalivedsystemctl enable keepalived |
在master上面查看是否生成了VIP 192.168.1.60
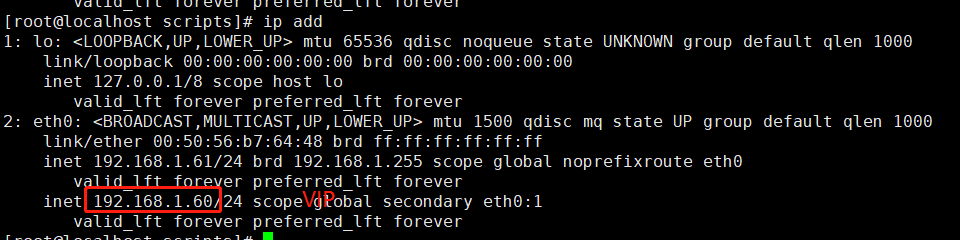
backup
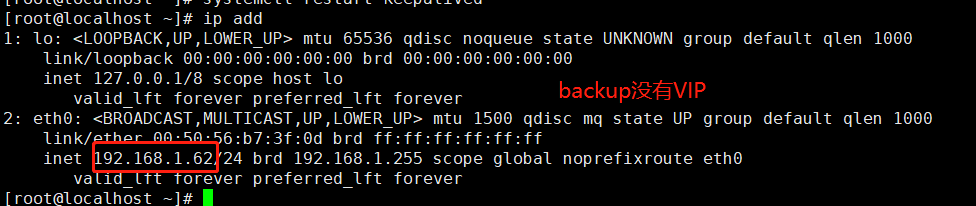
停止master的keepalived VIP会跳至backup
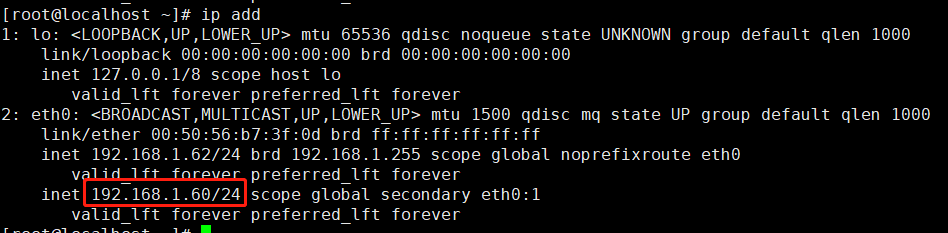
重启maste的keepalived则VIP会漂移至master,实现了故障迁移
如果是主的nginx出现故障,但是keepalived并不会把vip漂移,需要写脚本检测nginx宕则主动停止keepalived实现VIP漂移
1 | check_nginx.sh |
1 2 3 4 5 6 7 8 | #!/bin/bashwhile true do if [ `nmap 127.0.0.1 -p 80|sed -n "6p"|grep open|wc -l` -lt 1 ];then systemctl stop keepalived fi sleep 5 done |
后台运行并设置成开机启动即可实现如果是nginx出现故障也能实现VIP漂移
1 | sh check_nginx.sh & |
修改两个node192.168.1.65 192.168.1.66的配置文件
1 2 3 | bootstrap.kubeconfigkubelet.kubeconfigkube-proxy.kubeconfig |
把对应的IP修改成192.168.1.60重启kubelet kube-proxy即可
配置完毕在k8s-master01 192.168.1.63查看k8s集群状态
1 2 3 4 | # kubectl get nodeNAME STATUS ROLES AGE VERSION192.168.1.65 Ready <none> 3d3h v1.13.4192.168.1.66 Ready <none> 3d3h v1.13.4 |
k8s多master配置完毕


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 在鹅厂做java开发是什么体验
· 百万级群聊的设计实践
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战
· 永远不要相信用户的输入:从 SQL 注入攻防看输入验证的重要性
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析