
C#效率优化(4)-- 编译器对数组遍历的优化
在平时开发过程中,数组是我们使用频率最高的类型之一,在使用定长列表时,数组可以说是最佳方案,这也是我们最熟悉的数据结构之一。
在C#中使用数组,可以获取在内存上连续的相同类型的一组变量,在连续访问时可以满足CPU访问寄存器的时间局部性和空间局部性,大大提高了对大量数据的访问效率,但是在使用它时我们依然有一些需要注意的地方。
在对编译时类型为数组类型的对象进行foreach循环时,编译器会将该foreach循环优化为for循环,从而减少了迭代器的构造和其带来的额外消耗。但是,如果我们对编译时类型为IEnumerable类型、运行时类型为数组类型的对象进行foreach循环时,编译器并不会进行上面的优化,因为编译器并不知道该对象一定为数组类型,因此没有办法进行优化。
对于下面的代码:
int[] ints = new int[10]; int result = 0; foreach (var item in ints) { result += item; } IEnumerable enumerables = ints; foreach (var item in enumerables) { result += (int)item; }
对编译时类型为数组类型的ints变量进行遍历时,生成的IL代码为:
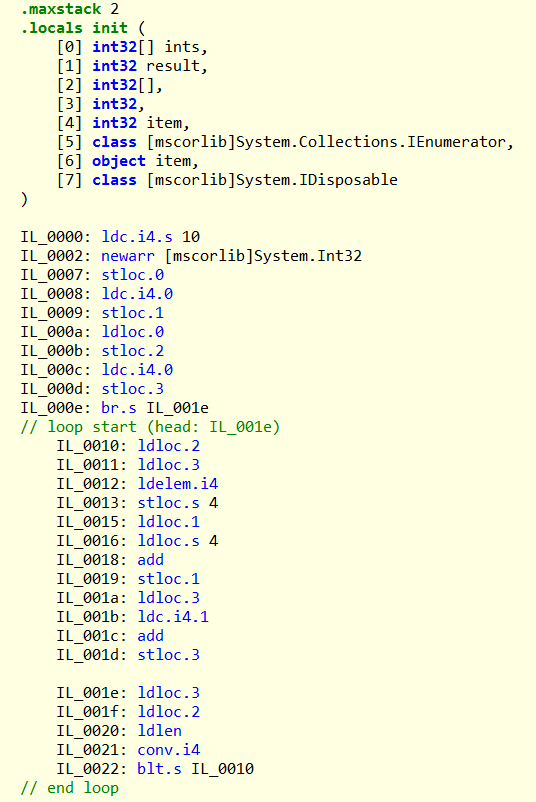
可以看到其对数组的foreach循环进行了for循环优化,而编译时类型为IEnumerable类型的enumerables变量进行遍历时,生成的IL代码为:
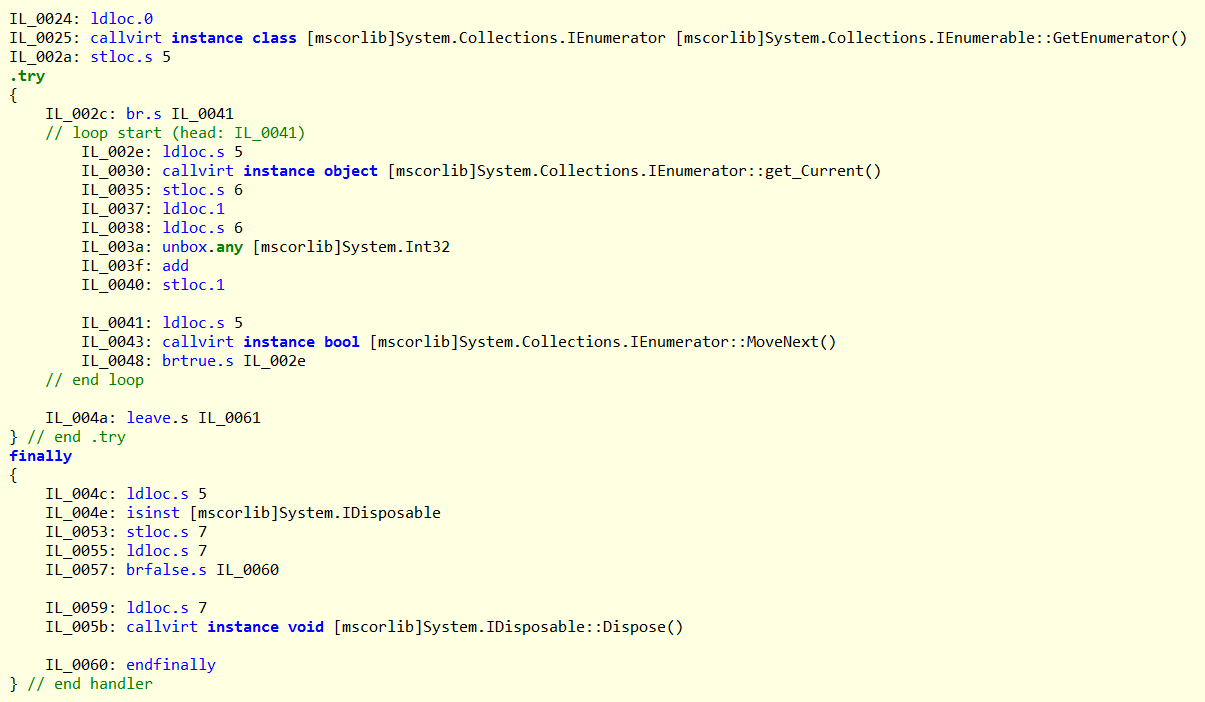
这里并没有对其进行任何的优化,使用构造迭代器的方式进行循环。
因此,在对数组类型的对象进行foreach遍历时,在必要时需要确保其编译时类型即为数组类型,确保其编译器优化被使用。
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的认可是我写作的最大动力!
作者:Minotauros
出处:https://www.cnblogs.com/minotauros/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

