个人项目(论文查重)
| 这个作业属于哪个课程 | 网工1934-软件工程 |
|---|---|
| 这个作业要求在哪里 | 论文查重 |
| 这个作业的目标 | 了解并实现论文查重算法 使用PSP表格 使用单元测试 使用代码质量检测工具 使用性能分析工具 |
项目代码已上传至GitHub
PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 60 |
| Development | 开发 | 360 | 460 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 180 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| · Design | · 具体设计 | 10 | 15 |
| · Coding | · 具体编码 | 120 | 150 |
| · Code Review | · 代码复审 | 20 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 20 |
| Reporting | 报告 | 35 | 30 |
| · Test Repor | · 测试报告 | 20 | 10 |
| · Size Measurement | · 计算工作量 | 5 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 15 |
| Total | 总计 | 425 | 550 |
计算模块接口的设计与实现过程
使用的接口
jieba.cut
用于对中文句子进行分词,功能非常强大,详细功能见GitHub-jieba
演示效果如下:
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
运行结果:
他, 来到, 了, 网易, 杭研, 大厦
re.match
由于对比对象为小说段落,因此应该对读取到的文件数据中存在的标点符号过滤掉。
gensim.dictionary.doc2bow
Doc2Bow是gensim中封装的一个方法,主要用于实现Bow模型。
Bag-of-words model (BoW model) 最早出现在自然语言处理(Natural Language Processing)和信息检索(Information Retrieval)领域.。该模型忽略掉文本的语法和语序等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的。
例如:
text1='John likes to watch movies. Mary likes too.'
text2='John also likes to watch football games.'
基于上述两个文档中出现的单词,构建如下一个词典 (dictionary):
{"John": 1, "likes": 2,"to": 3, "watch": 4, "movies": 5,"also": 6, "football": 7, "games": 8,"Mary": 9, "too": 10}
上面的词典中包含10个单词, 每个单词有唯一的索引, 那么每个文本我们可以使用一个10维的向量来表示。如下:
[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
[1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
该向量与原来文本中单词出现的顺序没有关系,而是词典中每个单词在文本中出现的频率。
gensim.similarities.Similarity
该方法可以用于计算余弦相似度
实现方式:
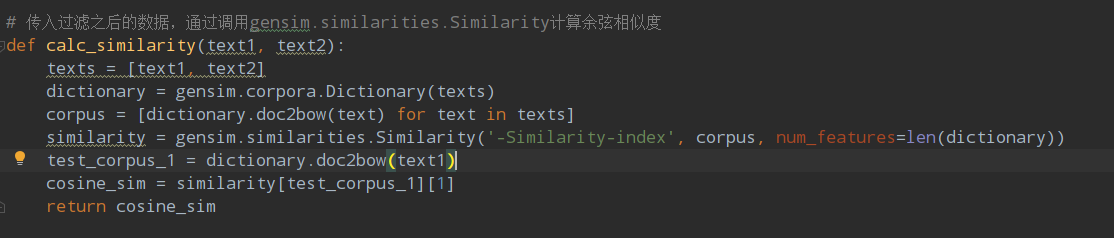
过程实现思路与结果展示
实现思路
结果展示
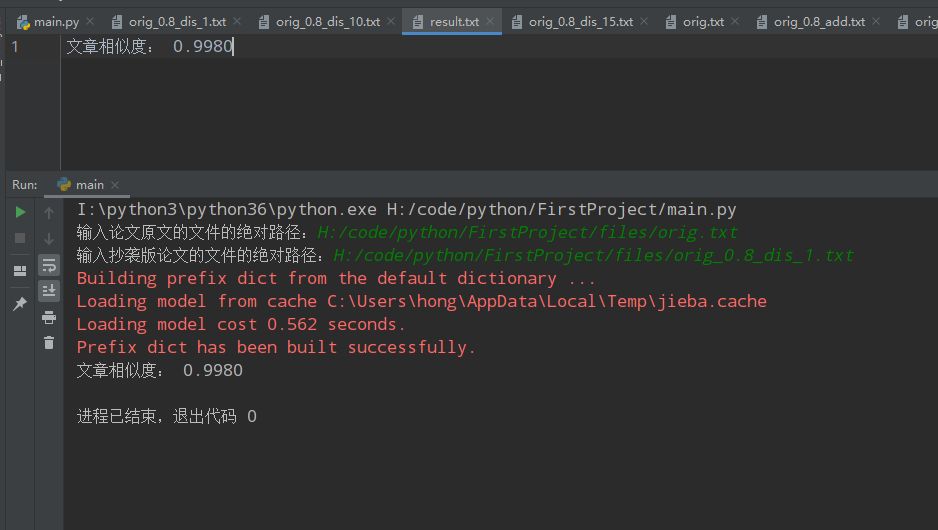
结果存放至同目录下的result.txt中
计算模块接口部分的性能改进
性能分析
代码优化前
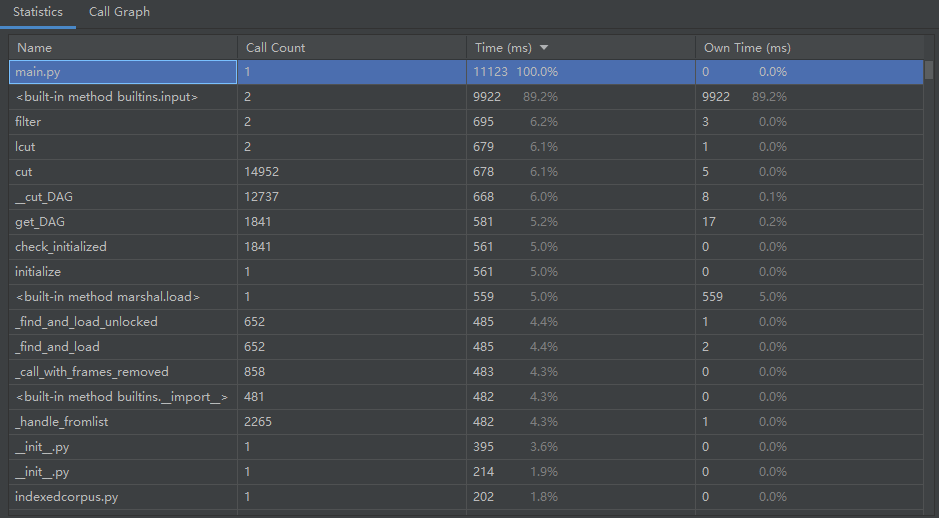
故对文件读取方式、代码等进行了些许修改
代码优化后
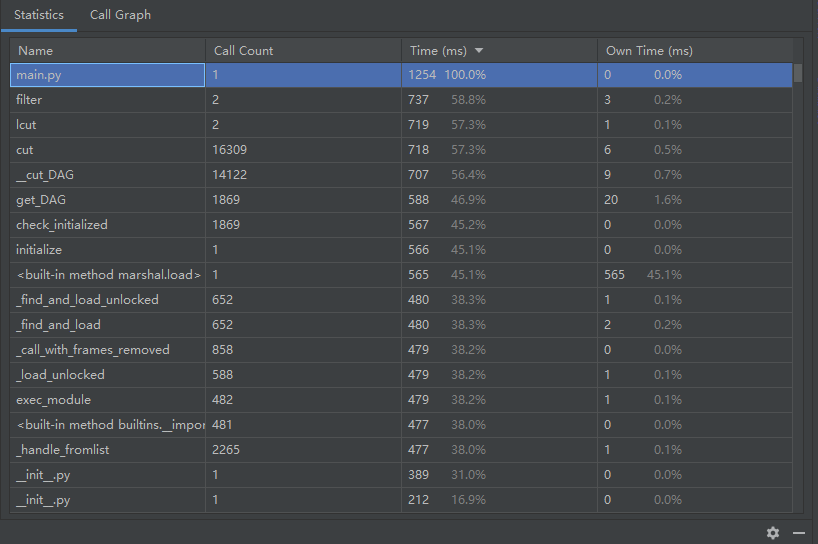
可见效率得到提升
代码覆盖率
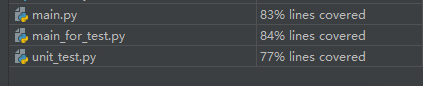
比较低的原因可能是:判断异常情况的语句中的另外一部分在运行时未被使用
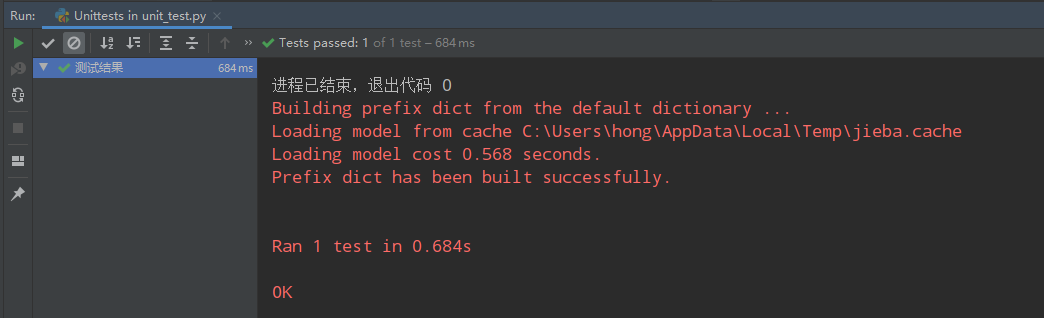
单元测试
将通过的情况的相似度设为0.99
成功的情况
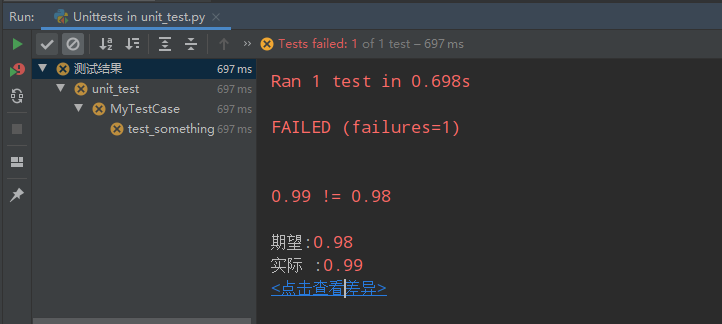
失败的情况
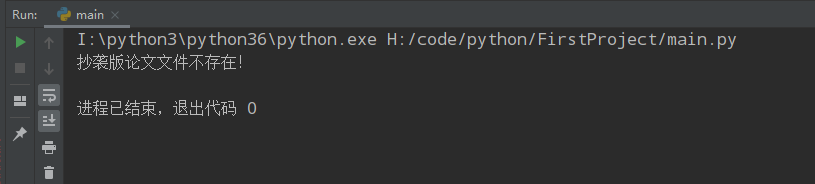
计算模块部分异常处理说明
若原文件或抄袭文件不存在,则报出错误信息

测试结果
参考链接
https://www.jb51.net/article/137755.html
https://www.jianshu.com/p/edf666d3995f

 浙公网安备 33010602011771号
浙公网安备 33010602011771号