HashMap详解
https://blog.csdn.net/weixin_39900608/article/details/111214986
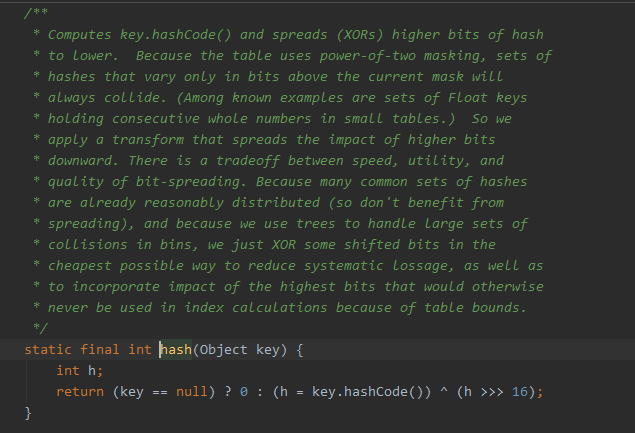
Hash值
先获得key对应的hash值。
将该数据的hash值A 与 将A右无符号移动16位后的数值再做
^得到最终值。这个操作叫
扰动
HashMap的数据结构
JDK1.7:数组+链表
JDK1.8:数组+链表+红黑树
HashMap如何扩容
默认的负载因子(0.75)
初始情况下,当存储的所有节点数 > (16 * 0.75 = 12 )时,就会触发扩容
默认负载因子(0.75)在时间和空间成本上提供了很好的折衷。较高的值会降低空间开销,但提高查找成本(体现在大多数的HashMap类的操作,包括get和put)。设置初始大小时,应该考虑预计的entry数在map及其负载系数,并且尽量减少rehash操作的次数。如果初始容量大于最大条目数除以负载因子,rehash操作将不会发生。
HashMap中链表跟红黑树切换思路,HashMap中链表跟红黑树是怎么个维持方法
这个值表示当某个箱子(数组的某个item)中,链表长度 >= 8 时,有可能会转化成树。设置为8,是系统根据泊松分布的数据分布图来设定的
在哈希表扩容时,如果发现链表长度 <= 6,则会由树重新退化为链表。设置为6猜测是因为时间和空间的权衡
链表转变成树之前,还会有一次判断,只有数组长度大于 64 才会发生转换。这是为了避免在哈希表建立初期,多个键值对恰好被放入了同一个链表中而导致不必要的转化
HashMap的链表数组。无论我们初始化时候是否传参,它在自扩容时总是2的次幂
HashMap线程不安全,如何替换
多线程情况下该类安全,可以考虑用HashTable(加了synchronized ),或者CurrentHashMap(自旋锁cas)
HashMap中的put,get,remove大致过程
put
数据插入的时候大致流程如下:
对数据进行
Hash值计算。将数据插入前先查看下当前
table的状态,如果table是空需要调用resize来进行初始化。通过位运算获得
key的目标位置。并判断当前位置情况。如果当前位置为空则直接进行放置,如果跟当前key一直则进行覆盖。
如果当前有数据则看当前数据类型是否是红黑树,是的话需要调用
putTreeVal。否则就认为是个链表,然后循环的查找进行尾部==插入==。同时还要考虑当前链表转红黑树。
get
获得key的hash然后根据hash和key按照插入时候的思路去查找
get。如果数组位置为NULL则直接返回 NULL。
如果数组位置不为NULL则先直接看数组位置是否符合。
如果数组位置有类型说红黑树类型,则按照红黑树类型查找返回。
如果数组有next,则按照遍历链表的方式查找返回。
remove
查看是否存在,然后是否在首节点上,是否在红黑树上,是否在链表上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号