主成分分析(PCA)和独立成分分析(ICA)相关资料
首先回答题主的问题:不管是PCA还是ICA,都不需要你对源信号的分布做具体的假设;如果观察到的信号为高斯,那么源信号也为高斯,此时PCA和ICA等价。下面稍作展开。
====答案的分割线====
假设你观察到的信号是n维随机变量主成分分析(PCA)和独立成分分析(ICA)的目的都是找到一个方向,即一个n维向量
使得线性组合
的某种特征最大化。
主成分分析(PCA)
PCA认为一个随机信号最有用的信息体包含在方差里。为此我们需要找到一个方向

【图片来自wikipedia】
如果用矩阵的形式,记
- y的各分量不相关;
的方差递减。
特别地,当原随机信号x为高斯随机向量的时候,得到的y仍为高斯随机向量,此时它的各个分量不仅仅是线性无关的,它们还是独立的。
通过PCA,我们可以得到一列不相关的随机变量至于这些随机变量是不是真的有意义,那必须根据具体情况具体分析。最常见的例子是,如果x的各分量的单位(量纲)不同,那么一般不能直接套用PCA。比如,若x的几个分量分别代表某国GDP, 人口,失业率,政府清廉指数,这些分量的单位全都不同,而且可以自行随意选取:GDP的单位可以是美元或者日元;人口单位可以是人或者千人或者百万人;失业率可以是百分比或者千分比,等等。对同一个对象(如GDP)选用不同的单位将会改变其数值,从而改变PCA的结果;而依赖“单位选择”的结果显然是没有意义的。
独立成分分析(ICA)
ICA又称盲源分离(Blind source separation, BSS),它假设观察到的随机信号x服从模型,其中s为未知源信号,其分量相互独立,A为一未知混合矩阵。ICA的目的是通过且仅通过观察x来估计混合矩阵A以及源信号s。
- z的各个分量不相关;
- z的各个分量的方差都为1。
有许多不同的ICA算法可以通过z把A和s估计出来。以著名的FastICA算法为例,该算法寻找方向使得随机变量
的某种“非高斯性”(non-Gaussianity)的度量最大化。一种常用的非高斯性的度量是四阶矩
。类似PCA的流程,我们首先找
使得
最大;然后在与
正交的空间里找
,使得
最大,以此类推直到找到所有的
. 可以证明,用这种方法得到的
是相互独立的。
ICA认为一个信号可以被分解成若干个统计独立的分量的线性组合,而后者携带更多的信息。我们可以证明,只要源信号非高斯,那么这种分解是唯一的。若源信号为高斯的话,那么显然可能有无穷多这样的分解。
====一些技术细节====
实际上PCA等价于求随机信号x的协方差矩阵的特征值分解(eigenvalue decomposition, EVD)或者奇异值分解(singular value decomposition, SVD)。比如,求的过程可以写成
注意其中上式中包含欧氏范数为1的约束条件,这是因为如果没有这个约束条件那么右边方差可以无限大,这个问题因而也就变得没有意义了。现假设x的协方差矩阵C为已知,那么上式可以化为
不难看出这个问题的解为对应于矩阵C的最大的特征值
的那一个特征向量。
类似的,求第n个方向需要解
这个问题的解为对应于矩阵C的第k大的特征值
的那一个特征向量。
另外关于ICA,我们有下面的“ICA基本定理”:
定理(Pierre Comon, 1994)假设随机信号z服从模型,其中s的分量相互独立,且其中至多可以有一个为高斯;B为满秩方阵。那么若z的分量相互独立当且仅当B=PD,其中P为排列矩阵(permutation matrix),D为对角矩阵。
这个定理告诉我们,对于原信号x做线性变换得到的新随机向量,若z的分量相互独立,那么z的各个分量
一定对应于某个源信号分量
乘以一个系数。到这里,我们可以看到ICA的解具有内在的不确定性(inherent indeterminacy)。实际上,因为
,即具备相同统计特征的x可能来自两个不同的系统,这意味着单从观察x我们不可能知道它来自于哪一个,从而我们就不可能推断出源信号s的强度(方差)。为了在技术上消除这种不确定性,人们干脆约定源信号s的方差为1。有了这个约定,再通过数据预处理的方法,我们可以把原混合矩阵A化为一个自由度更低的正交矩阵:
对于一组3个模拟信号,如正弦、余弦、随机信号
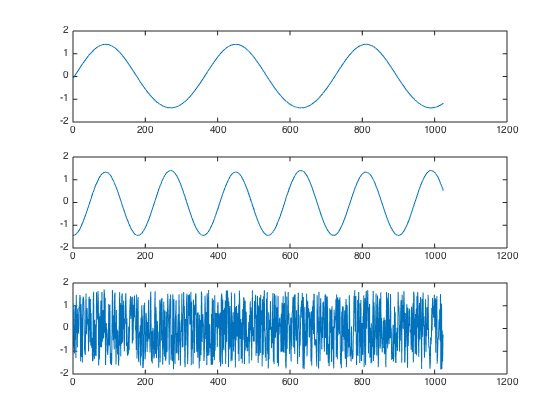

白化在这里先不提,PCA本质上来说就是一个降维过程,大大降低ICA的计算量。
PCA,白化后的结果如下图所示。可以看到,原先的6路信号减少为3路,ICA仅需要这3路混合信号即可还原源信号。
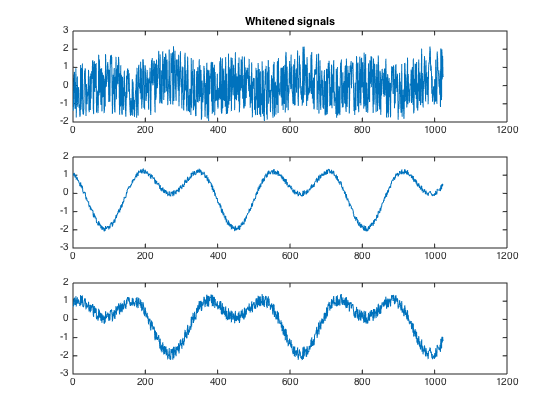
总的来说,ICA认为观测信号是若干个统计独立的分量的线性组合,ICA要做的是一个解混过程。
而PCA是一个信息提取的过程,将原始数据降维,现已成为ICA将数据标准化的预处理步骤。
[1] A. Hyva ̈rinen, J. Karhunen, and E. Oja, Independent Component Analysis, Wiley-Interscience, New York, 2001
[2] J.-F. Cardoso, “Blind signal separation: statistical principles”, Pro- ceedings of the IEEE, vol. 90, n. 8, pp. 2009-2026, October 1998.
[3] A. Hyva ̈rinen and E. Oja, ”A Fast Fixed-Point Algorithm for Inde- pendent Component Analysis”. Neural Computation, 9(7):1483-1492, 1997.
[4] A. Hyva ̈rinen, “Fast and Robust Fixed-Point Algorithms for Inde- pendent Component Analysis”. IEEE Trans. on Neural Networks, 10(3):626-634, 1999.
一、PCA和ICA的用途完全不同。如果只在意数据的能量或方差、假设噪声或不感兴趣的信号都比较微弱,那么用PCA就能把主要信号留下来。在某种意义上,ICA更智能——它不在意信号的能量或方差,只看独立性。所以给定的待分析的混合信号经任意的线性变换都不会影响ICA的输出结果,但会严重影响PCA的结果。
二、若多于一个原始独立信号是正态的,那么ICA的结果不唯一;下面给个直觉。若数据在两个正交方向方差相同(比如协方差是isotropic的),PCA结果不唯一。大部分算法都用两步来实现ICA:第一步做白化预处理(whitening),让输出信号不相关而且同方差。第二步找一个旋转(就是正交变换)让输出信号不只不相关(uncorrelated),进而在统计意义上独立(statistically independent)。为简单起见,考虑两维的情况。
如果原始独立信号都是正态的,第一步后输出信号的联合分布如下图:
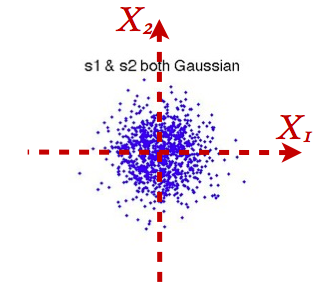
那么你可以看到,不管怎样旋转,输出的两个信号(在横坐标以及纵坐标上的投影)都是独立的。
非高斯分布下情况就不同了。在下图中,原始独立的信号都是超高斯的,可以看到白化预处理后的输出虽然不相关,但并不独立:

类似的,如果原始独立信号是均匀分布的,第二步就需要从
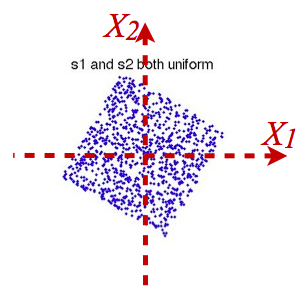
旋转到
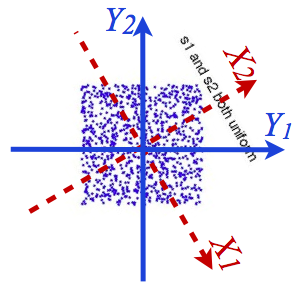
这样就直觉上了解了为什么ICA需要假设原始独立信号的非高斯分布之后才有意义。
三、ICA只是让输出信号尽量独立,实际应用中因种种因素,比如噪声影响、非线性因素、太多源信号的影响等等,输出往往不是完全独立。这时很多情况下ICA的输出还是包含了主要的独立的成分,是有意义的。
四、总的来说,不相关是非常一种弱的独立性(线性独立性),一般必须配合别的性质使用才能得出唯一的结果:在PCA里就配合了能量或方差最大这个性质。而一般情况下独立性比不相关强了很多,在一定条件下,强到了足以把数据的产生过程恢复出来的地步。
更进一步,每当我们做回归(regression),不管是线性回归还是非线性回归,噪声和predictor都是不相关的。但很多情况下,它们却不是独立的(!)。这个性质最近十年内在因果关系分析中得到很重要的应用。ICA是找出构成信号的相互独立部分(不需要正交),对应高阶统计量分析。ICA理论认为用来观测的混合数据阵X是由独立元S经过A线性加权获得。ICA理论的目标就是通过X求得一个分离矩阵W,使得W作用在X上所获得的信号Y是独立源S的最优逼近,该关系可以通过该式表示:Y = WX = WAS , A = inv(W).
ICA相比与PCA更能刻画变量的随机统计特性,且能抑制高斯噪声。从线性代数的角度去理解,PCA和ICA都是要找到一组基,这组基张成一个特征空间,数据的处理就都需要映射到新空间中去。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号