Python:数据标准化
第一步:导入本地的目标数据集
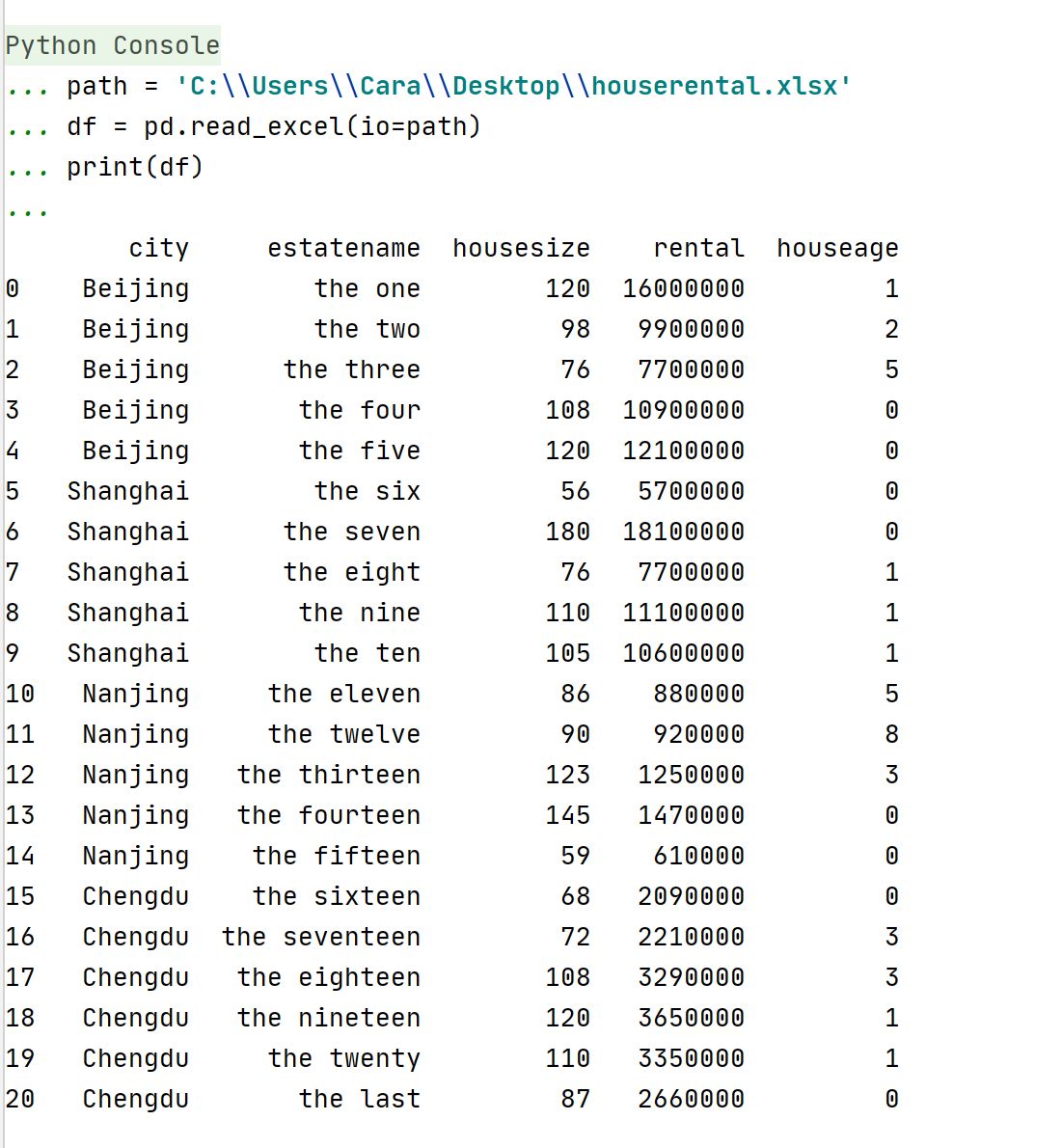
使用pandas库中的read_excel()函数导入的数据格式会默认为dataframe(数据框),可以直接使用数据框支持的所有方法。
观察数据可以发现,数据后三列为数值型,但是各个数值的度量单位是不同的,housesize一般以平方米为单位,rental一般以元为单位,houseage一般以年为单位。
第二步:截取出需要进行标准化处理的列
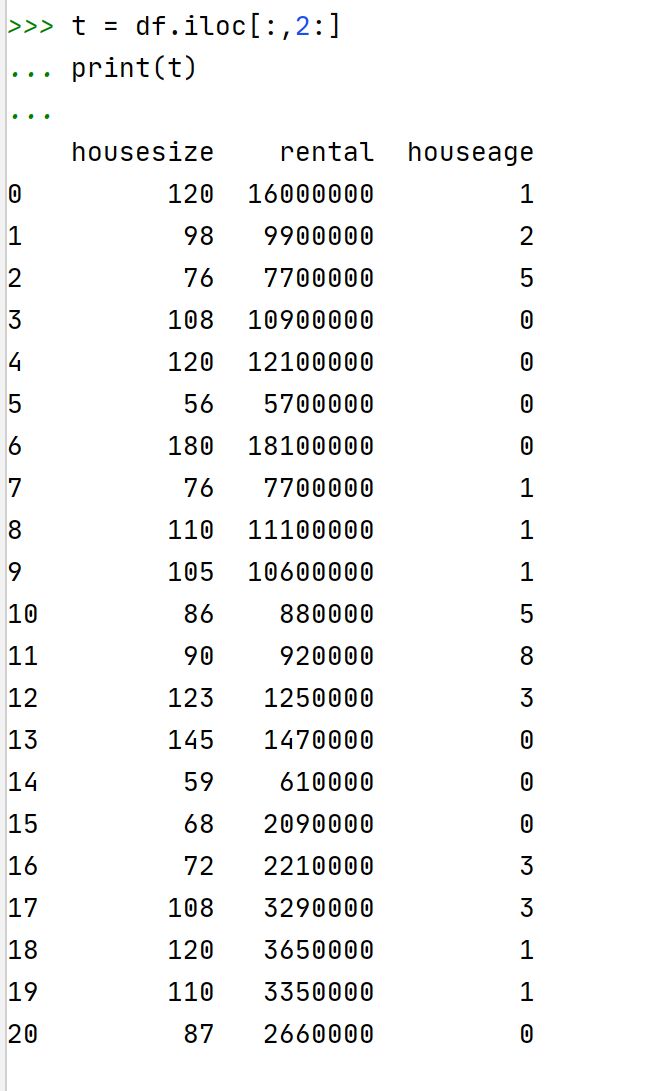
第三步:进行数据标准化
方法一:最小-最大标准化
公式:
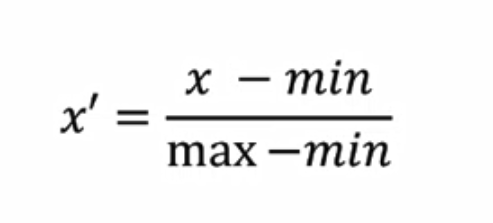
min指x所在列的最小值,max指x所在列的最大值。x'指标准化后的x。
代码如下:
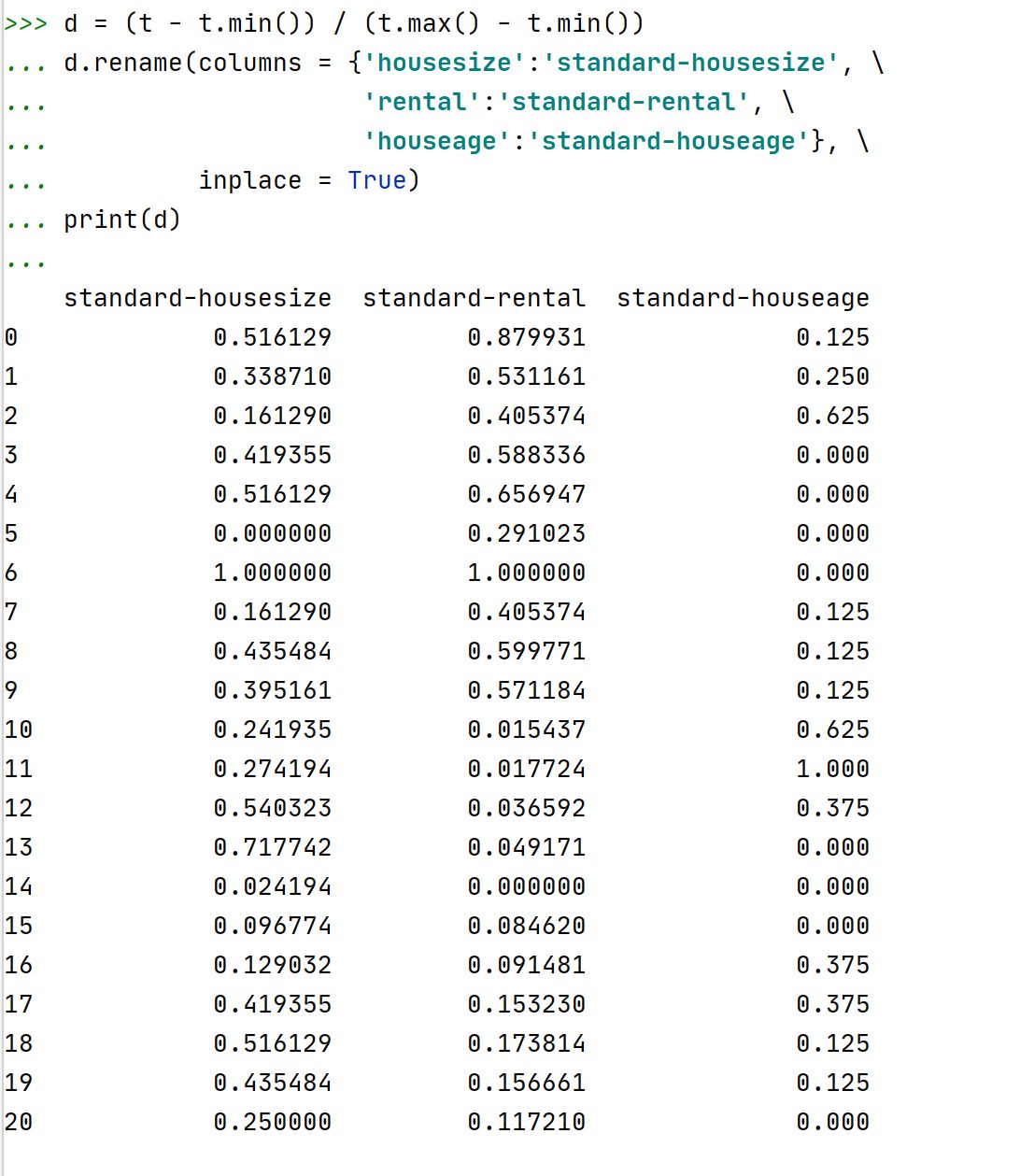
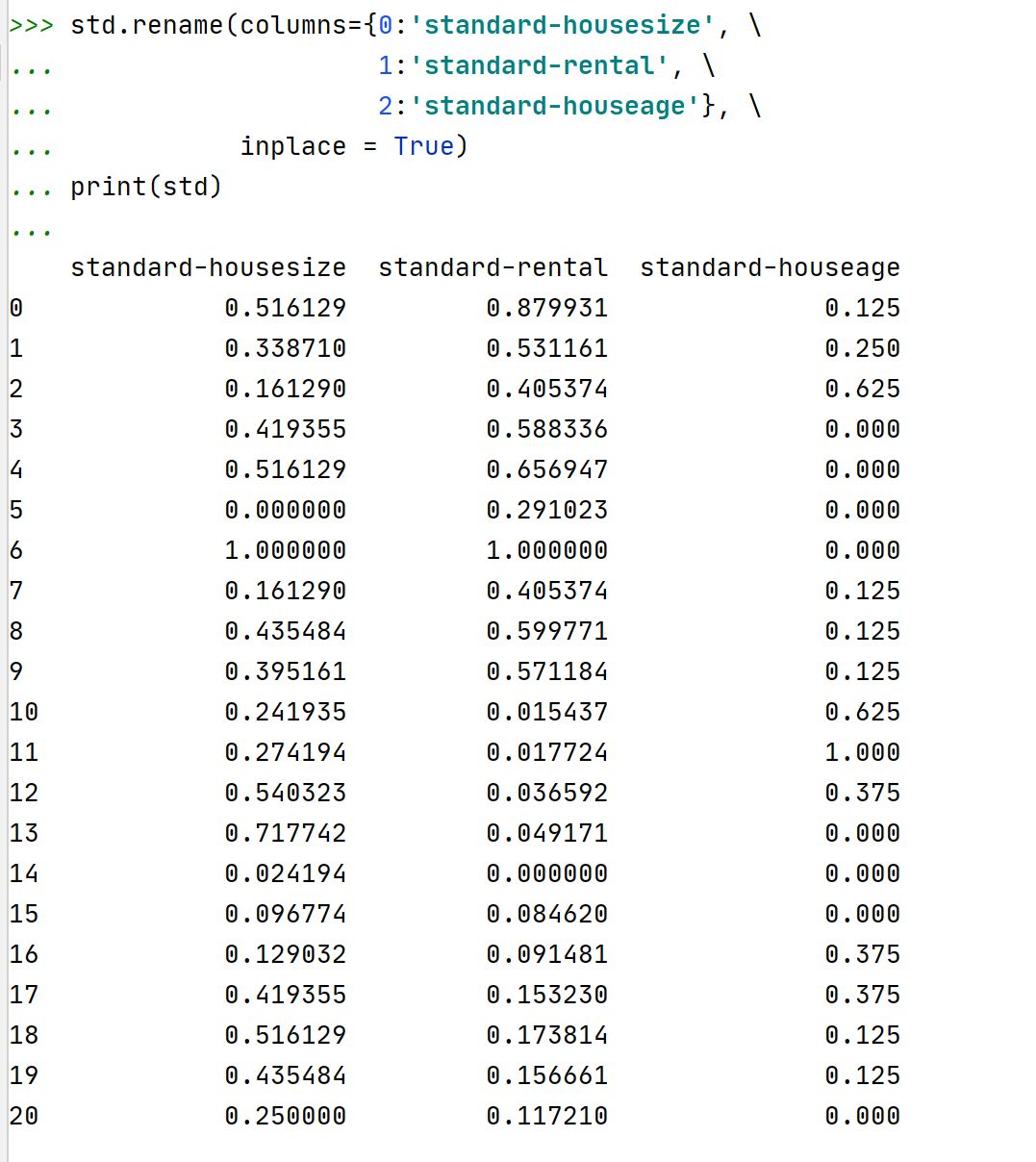
注释:①标准化后的数据框d还是数据框格式~
②数据框下面的rename()方法可以用于对数据框的列名进行随意更改~采用字典格式进行列名修改。
colums = {'originalname1':'newname1','originalname3':'newname3'}无需修改的列名可以直接跳过。
inplace = True表示替换原来的列名,直接显示最新的列名。
最后,需要将标准化后的数据拼接到原数据中去。
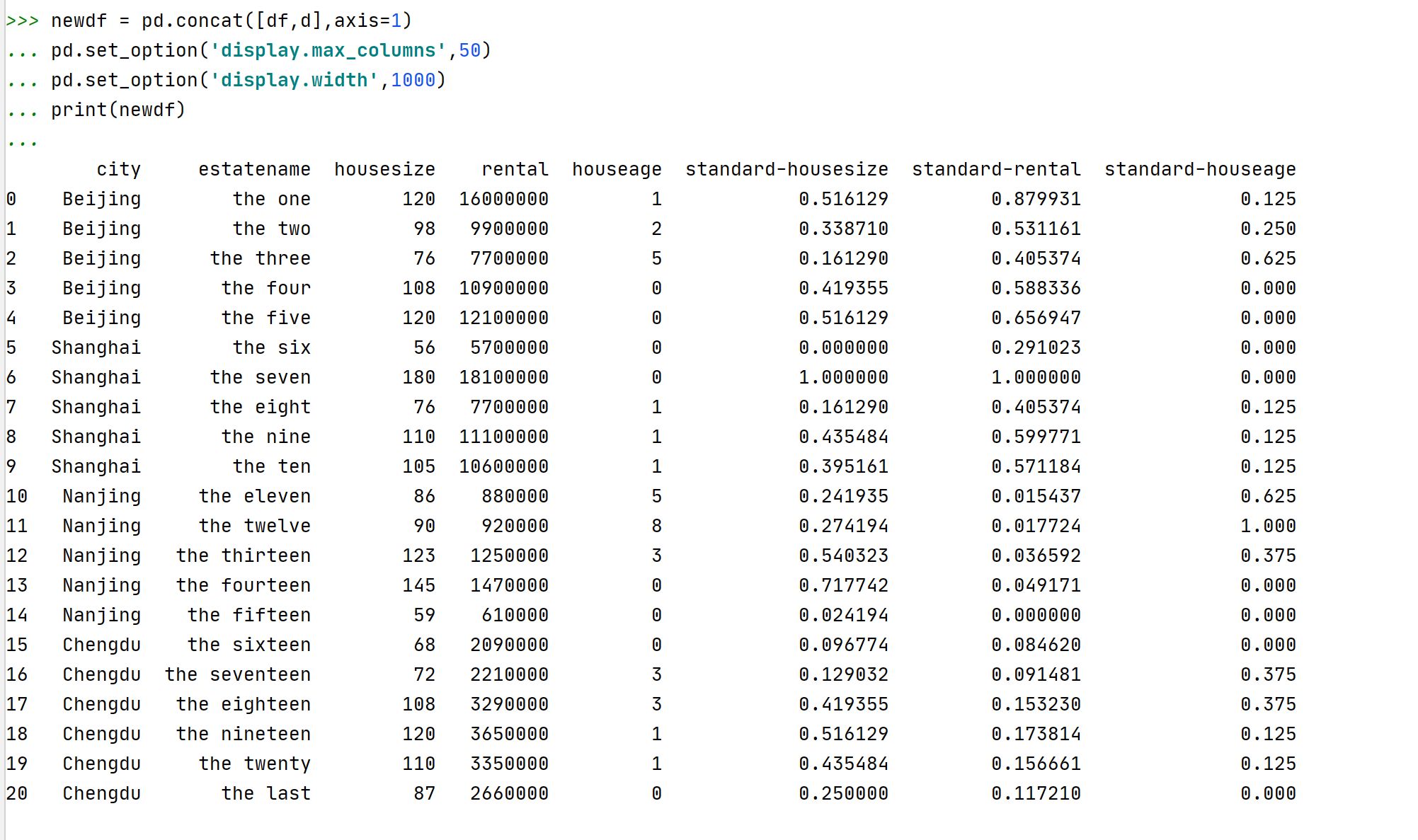
注释:①这里采用的拼接方法concat()为直接拼接,即生硬的将两张表拼凑在一起。并没有根据某一列做匹配,与merge()方法是不一样的~
②pd.set_option('display.max_columns',50),设置显示的最大列数为50列,如果不设置该参数,直接print()会有很多列被省略无法看到完整的拼接结果。
③pd.set_option('display.width',1000),设置显示宽度为1000。如果不设置该参数,则最后几个列会换行显示。
④补充:pd.set_option('display.max_rows', 500) ,设置打印最大行数为500行。
在sklearn库中的preprocessing模块下的minmax_scale()函数可以直接实现最小最大标准化。
第一次尝试:
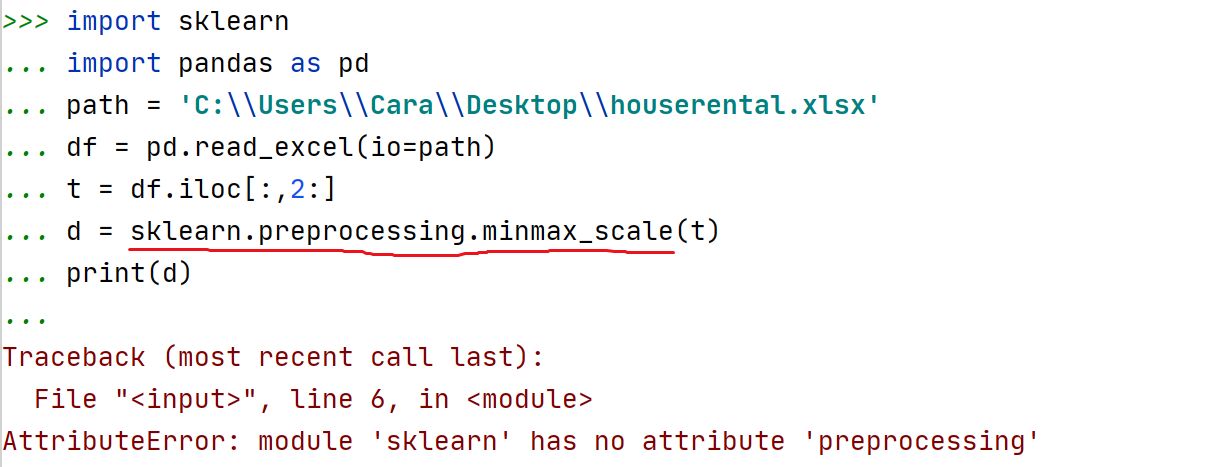
百度一下,发现,导入模块的方法不对,改正如下:
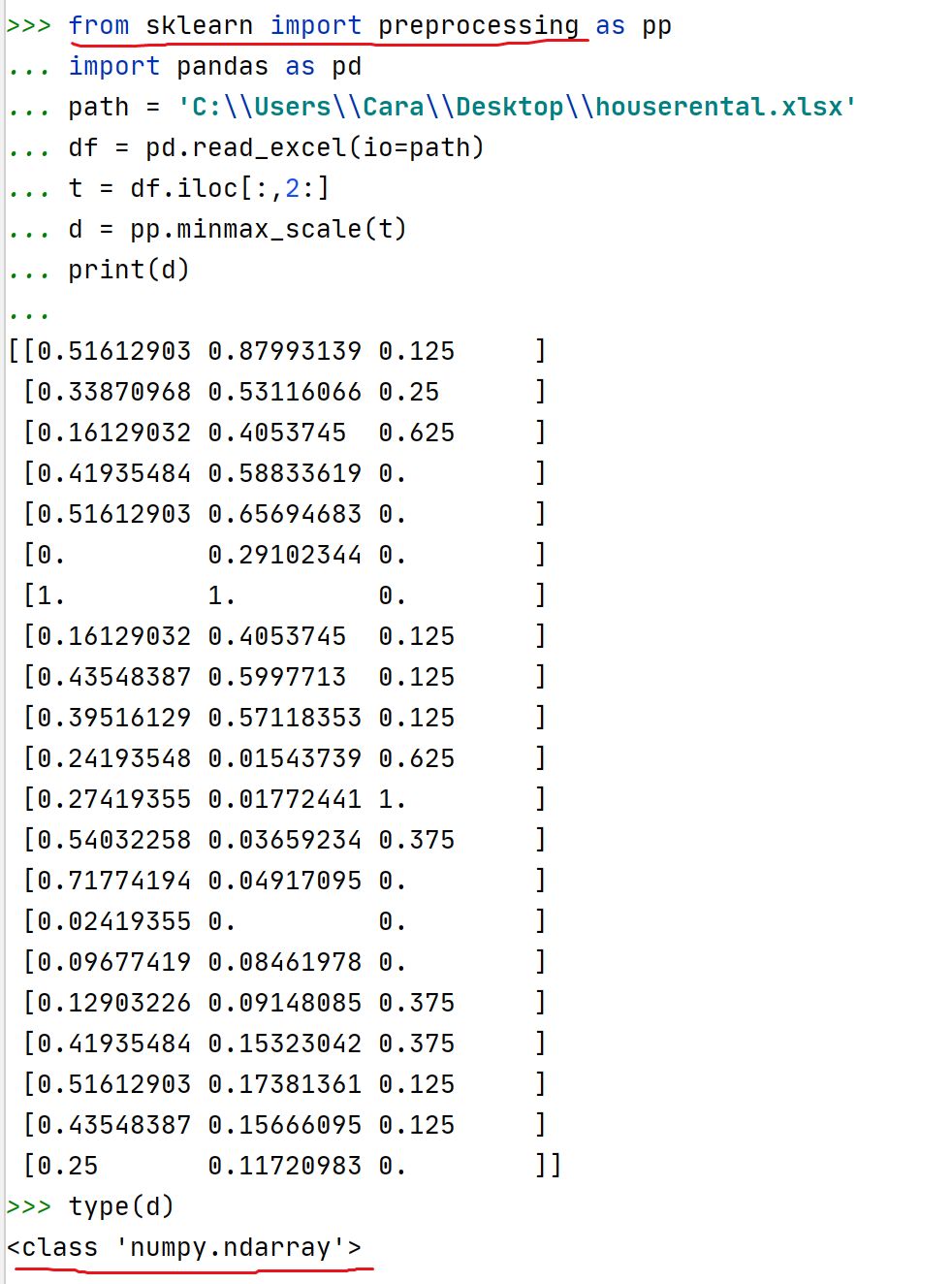
注意:使用该函数后,数据格式发生变化了!不是数据框,而是n维数组了!
那么,如何将n维数组转换为数据框并添加列名呢?
继续百度……
大神说,可以使用pandas库中的DataFrame()函数将数组转为数据框:
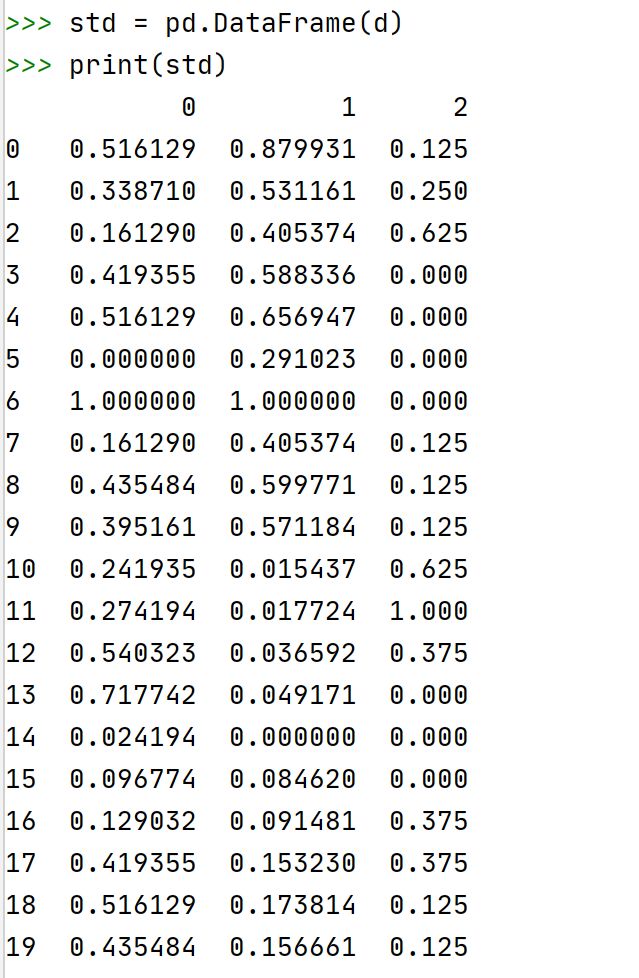
确实成功转换了~
但是,数据框的列名需要修改一下~
最后一步:把原始数据与标准化数据合并起来~本文之前做过,就不重复了~
方法二:Z-score标准化
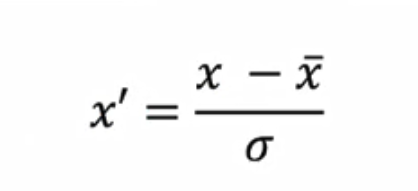
其中,x表示具体数值,xbar表示x所在列的均值,σ 表示x所在列的标准差。
采用这种方法处理后的标准化数据特征为:标准差为1,均值为0。
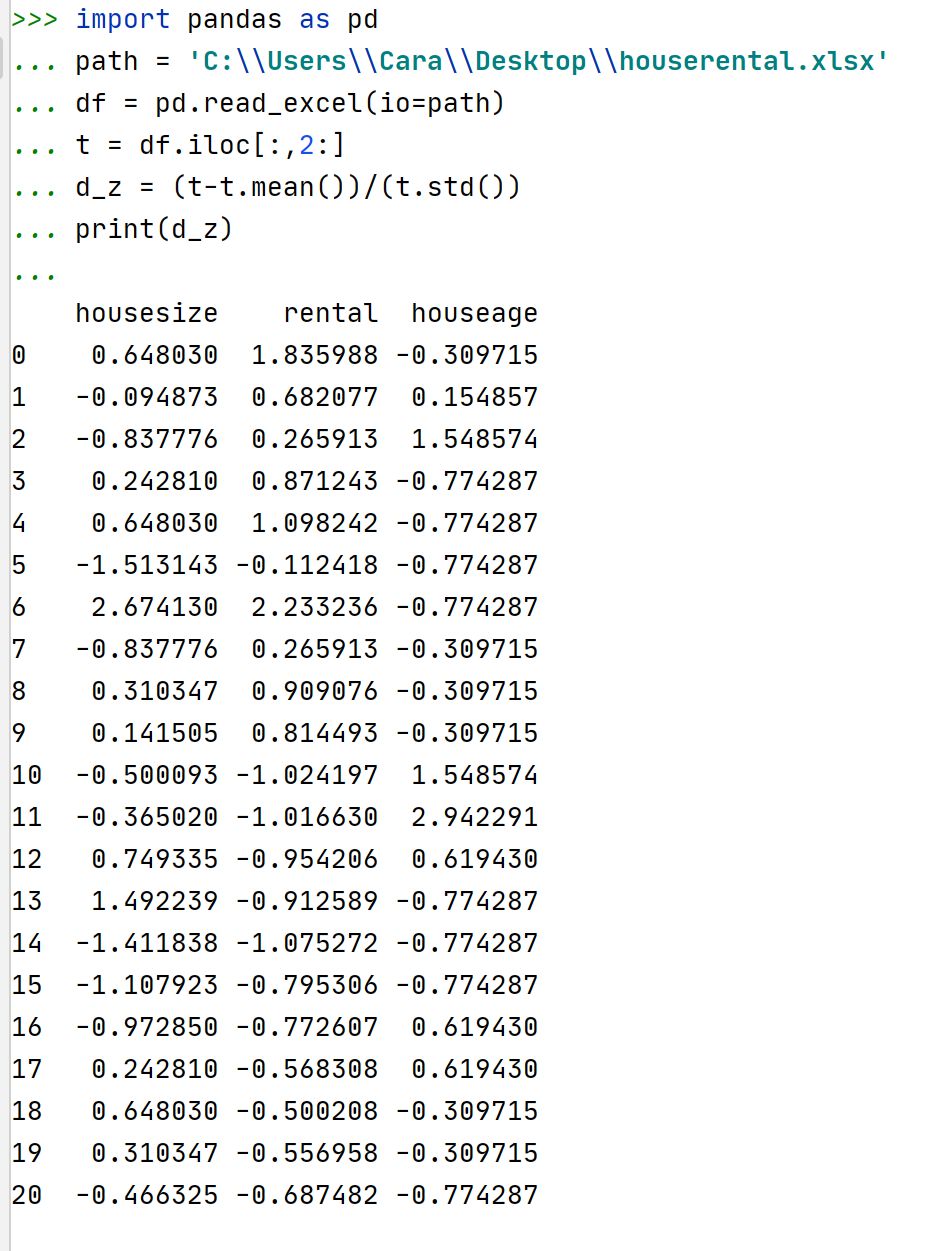
手动Z-score标准化的代码如下:
同样,sklearn库中也有对应的函数可以实现Z-score标准化。
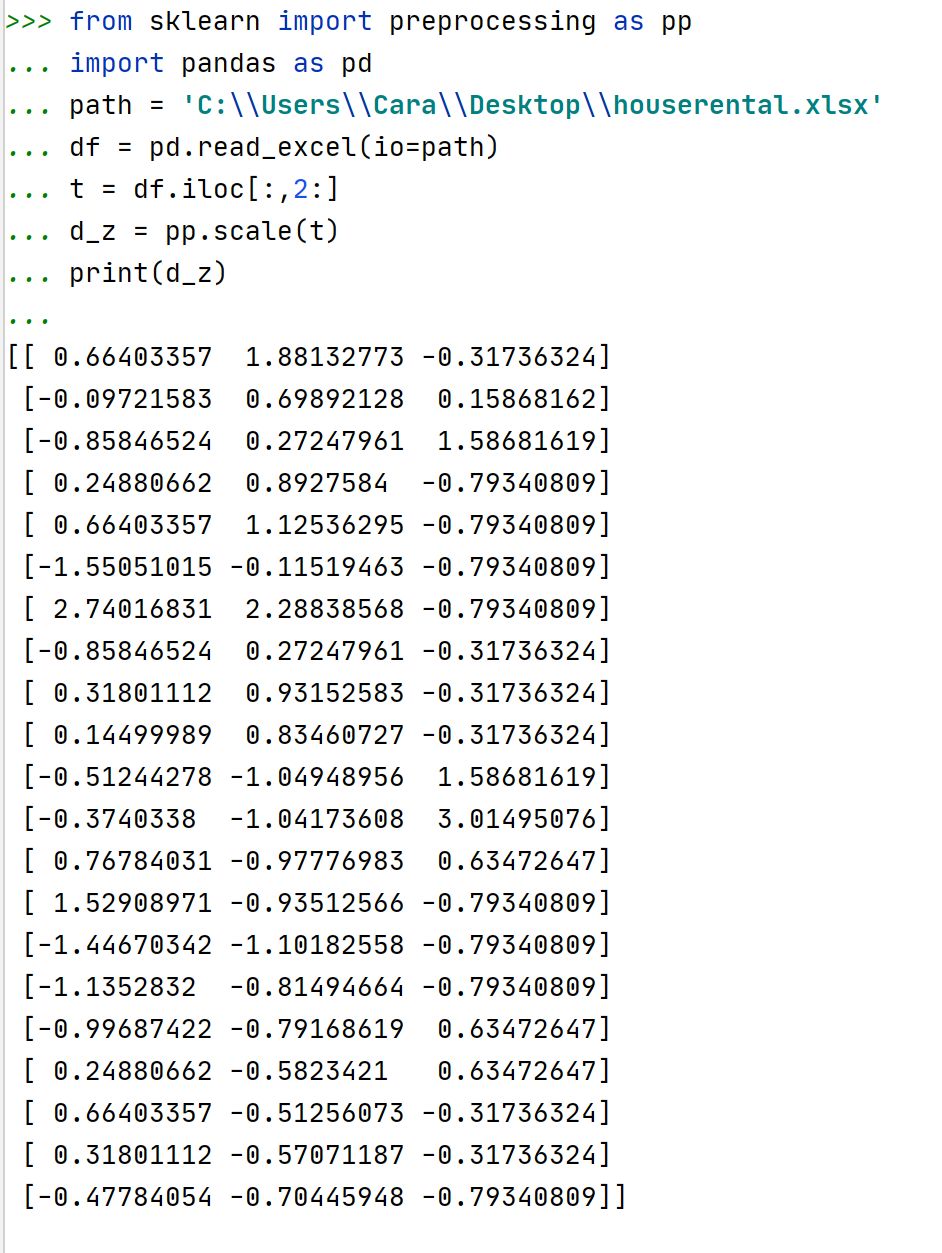
不过,仔细观察会发现,手动的结果和使用scale()函数的结果并完全不一样。
我对使用scale()函数的标准化后的数据进行标准差、均值的检测发现,标准差确实为1,但是均值不等于0,是无限接近0的一个小数。

方法三:小数定标规范化
目的:将任意一个较大的数字,转换为[-1,1]的小数。
如120,将它除以1000,则为0.12。困难在于,任意给定一组数,如何确定应该除以10的多少倍?
基本思路:先将所给的一组数取绝对值,找出这组数中绝对值最大的数,然后,利用对数+向上取整的思想来确定10的次方。
代码如下:

注释:①numpy库中有ceil()函数,表示向上取整。
②numpy库中log10()用于计算一个数以10为底数,对应的值是多少。
参考资料:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!