电商平台商家流量分配机制算法
本文把电商平台搜索场景的流量分配问题定义为在用户 ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729781-1559621070.svg) 提交查询关键词
提交查询关键词 ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729796-1638766462.svg) 后,搜索结果列表的第
后,搜索结果列表的第 ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729657-953261512.svg) 个位置展现哪个商家的哪个商品,以便达到某种商业目标。由此可见,流量跟3个因素有关:用户、查询关键词、搜索结果的展现位置。只要这3个因素其中有一个发生变化,我们就认为产生了一个新的不同的流量。按照这个定义,一般情况下,电商平台的每日流量都在亿或数十亿的数量级。
个位置展现哪个商家的哪个商品,以便达到某种商业目标。由此可见,流量跟3个因素有关:用户、查询关键词、搜索结果的展现位置。只要这3个因素其中有一个发生变化,我们就认为产生了一个新的不同的流量。按照这个定义,一般情况下,电商平台的每日流量都在亿或数十亿的数量级。
电商平台为了达到其商业目标,如最大化平台的总成交额(GMV),需要把每个流量和某个具体的商品联系起来。在搜索场景下,表现为系统决定在用户 提交查询关键词 后搜索列表的各个位置展现哪些商品的过程。这一给流量和商品建立关联的过程就称为流量分配。
在商业目标确定后,流量分配就需要满足一定的约束条件,不能随意而为之。比如,在搜索场景下,考虑到用户体验的问题,流量分配需要能够匹配用户此时此刻的查询意图,即需要满足相关性、个性化、场景化等约束;同时,平台为了更好地服务商家以及追求自身的利益,需要在流量分配时考虑最大化总成交额。
然而,平台的多个商业目标之间,并不是毫无冲突的,比如在最求自身利益最大化的同时并不能很好的服务所有的商家。表现为平台最大化GMV的贪心策略会导致流量分配的马太效应越来越明显,即流量越来越集中到少数的头部商家;中长尾的商家获得的流量少,成交量也少,从而失去参与感。导致这一现象的原因是贪心的流量分配机制严重依赖平台上的历史行为数据。系统倾向于展现过去一段时间转化率高且销量好商品;而对于新上架的商品,或者小众而精美的商品(比如手工艺品等)由于历史成交数据有限,系统未能充分探索并感知其被展现的效用值,因此这类商品得到的展现机会就较少。在机器学习领域,这一问题被称为探索/利用(Exploration and Exploitation)两难问题。
构建平台、用户和商家共赢的生态结构是电商平台的长期目标。采用贪心策略的流量分配机制长期发展下去,不利于平台生态的长远发展。为了缓解马太效应,需要在尽量不影响平台GMV的条件下,有意识的控制头部商家的流量,把更多的流量引导到中长尾商家。这就是本文主要解决的问题。
问题建模
为了使流量分配尽可能趋近平均,我们在目标函数里添加了最大熵正则项(maximum entropy regularizer)。目标是在使得平台整体流量利用率和转化率最大化的基础上,给予中长尾商家一定的流量激励和支持。数学表达如下:
![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729792-249709059.svg)
其中,![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729602-1986882706.svg) 为第 个流量分配给第
为第 个流量分配给第 ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729511-2119685408.svg) 个商家的概率;
个商家的概率; ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729822-670504499.svg) 为流量 分配给商家 时获得的收益,定义为“点击率 * 转化率 * 客单价”;信息熵(
为流量 分配给商家 时获得的收益,定义为“点击率 * 转化率 * 客单价”;信息熵( ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729545-1355627208.svg) )越大,表示流量分配的不确定性越大,即流量需要更加平均的分配;
)越大,表示流量分配的不确定性越大,即流量需要更加平均的分配; ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150730022-1522125284.svg) 是超参数,用来控制正则化的强弱程度;
是超参数,用来控制正则化的强弱程度;![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729749-1530362193.svg) 为第 个商家本时段的目标流量;
为第 个商家本时段的目标流量; ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729715-1686919077.svg) 为指示函数,当参数为真时值为1,否则值为0。
为指示函数,当参数为真时值为1,否则值为0。
由于argmax函数和指示函数都不是连续可微函数,给问题求解带来不便。这里把$K$个不等式约束简化为独立的线性表达形式,如下所示:
![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729821-824338671.svg)
其中, ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729968-1151408364.svg) 为商家 的流量总量软目标,可能的形式如:
为商家 的流量总量软目标,可能的形式如: ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150730021-347042196.svg) ,
, ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729706-120488475.svg) 为一个缩放系数。在流量分配求解过程中,
为一个缩放系数。在流量分配求解过程中, ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729718-1426605726.svg) 作为一个已知的常数,需要预先通过其他手段预估出来。
作为一个已知的常数,需要预先通过其他手段预估出来。
由于流量的数量级非常大,直接求解 是非常困难的;同时流量是实时进入的,系统需要在线快速求解。因此,我们通过把原始问题转化为拉格朗日对偶问题来求解,即把庞大的参数空间{ }转化为较小的参数空间{ ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729775-990587297.svg) },从而简化问题。
},从而简化问题。
该问题的拉格朗日(lagrange)形式如下:
![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729721-430387805.svg)
根据 KKT 条件,最优时 ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729650-729345686.svg) 和
和 ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729794-2083307885.svg) 推得:(推导过程见文章末尾)
推得:(推导过程见文章末尾)
![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729713-1835392474.svg)
再将 ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729746-905502157.svg) ,
, ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729859-1778871378.svg) 带回原式
带回原式 ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729967-328228780.svg) ,得
,得
![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729903-89769905.svg)
则原问题可转化为:![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729793-969556796.svg)
其中, ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729998-1785599186.svg) 是KKT条件的要求。这是个关于
是KKT条件的要求。这是个关于![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150730023-767508609.svg) 的最优化问题,参数空间相对于原始参数 的空间要小很多。用梯度下降(gradient descend)算法可以很好的并行化求解,迭代更新如下,其中
的最优化问题,参数空间相对于原始参数 的空间要小很多。用梯度下降(gradient descend)算法可以很好的并行化求解,迭代更新如下,其中![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150730022-499258887.svg) 为步长:
为步长:
![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729993-1518563866.svg)
我们回过头看的求解式子, 项越大,则 值越小;反之 项越小,则 值越大。当所有都为0时,也就是按 目标值贪心的方法。我们观察参数求解过程,物理上的含义是:如果分配超过约束 ,则增大,下一轮迭代中分配概率 就会减少;反之,当分配没有超过约束 时, 减小导致下一轮获得的分配概率 增加;当 等于0时,表示分配不再受这个约束影响。所以的物理含义是:受约束影响下,对原始收益的折扣系数 。
综上所述,根据概率 来分配流量具有抑制已获得足够流量的商家进一步获取流量的作用,同时有助于未获得足够流量的商家在竞争中获胜,从而达到流量均衡的作用。
商家目标流量预估
那么每个商家应该获取多少流量( )才算合理呢?我们并不希望新的流量分配机制上线之后,对商家的流量分布造成非常大的变化,总体原则是在更多探索中长尾商家的优质商品的同时不能让头部商家明显感知到流量的急剧震荡。同时,我们也需要评估各个商家的流量承接能力。
商家目标流量预估也是一个复杂的问题。有几种做法可以考虑,比如:
- 统计目标场景下过去一段时间(比如一个月)内每个商家获得的流量移动平均值;
- 偏好近期的统计数据,使用权重衰减的方法拟合目标值;
- 为了更好的稳定性,去最近一周的流量移动平均值的中位数(median of means);
- 做成基于时间序列的回归模型(如ARMA);
- 考虑商家/商品的历史点利率和转化率;
在线求解
- 离线为每个商家预估出每个时段的流量目标值(比如每个小时有一个独立的目标,这样线上的流量控制更加平滑),并build到商品索引;
- 在线记录每个商家每个时段到目前为止获得的流量,记为
![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729697-253346806.svg) ,更新
,更新![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729745-275353242.svg) ,其中
,其中 ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729773-1692486411.svg)
- 为每个召回的商品计算未归一化的分配概率:
![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729860-2133933090.svg)
- 在每个相关性档位确定的情况下,按照
![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729966-355436689.svg) 降序排列,取Top N个商品展现
降序排列,取Top N个商品展现
虽然在线求解过程非常简单,但背后的逻辑是有理论支撑的,流程示例图如下。
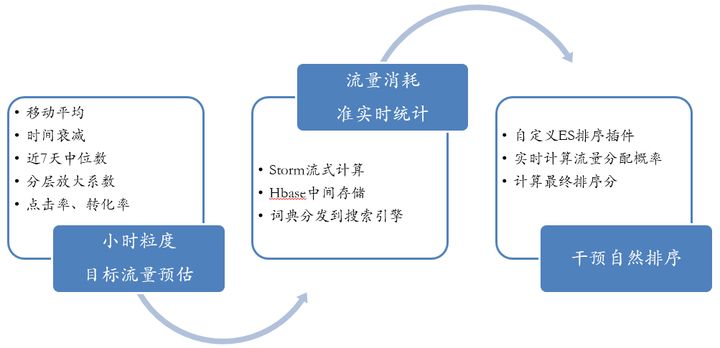
评估指标
- 基尼系数
- 基尼系数原指经济学中用来衡量一个国家或地区贫富差距的指标,数值范围从0到1,数值越大表示收入差距越悬殊,数值越小表示收入越趋向于平均。不了解的同学可以查看这个轻松有趣的1分钟短视频:轻松秒懂基尼系数。
- 借用基尼系数的概念,从商品曝光流量维度统计商家获取流量多少的差距水平,记为曝光基尼系数。具体计算方法:把所有商家按其获取到的曝光流量由低到高的顺序排队,分为人数相等的
![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729831-1603504664.svg) 组,从第1组到第 组商家累计获取曝光流量占全部商家总获取曝光流量的比重为
组,从第1组到第 组商家累计获取曝光流量占全部商家总获取曝光流量的比重为 ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729775-1284581413.svg) ,则
,则 ![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150729773-473901347.svg) 。
。 - 借用基尼系数的概念,从商品点击流量维度统计商家获取点击多少的差距水平,记为点击基尼系数。具体计算方法:把所有商家按其获取到的点击流量由低到高的顺序排队,分为人数相等的 组,从第1组到第 组商家累计获取点击流量占全部商家总获取点击流量的比重为 ,则
![[公式]](https://img2022.cnblogs.com/blog/2304373/202202/2304373-20220216150730057-297337293.svg) 。
。 - 商家动销率:(有销量的商家数)/ (有在售商品的商家总数)
- 商品动销率:(有销量的商品数)/ (在线销售的商品总数)
- 商家曝光比率:(有商品被展现的商家数)/ (有在售商品的商家总数)
- 商家点击比率:(有商品被点击的商家数)/ (有在售商品的商家总数)
业务效果
在我们电商平台上曝光基尼系数和点击基尼系数降低幅度的提升都在16%~20%左右,商家动销率的提升也在10%以上。
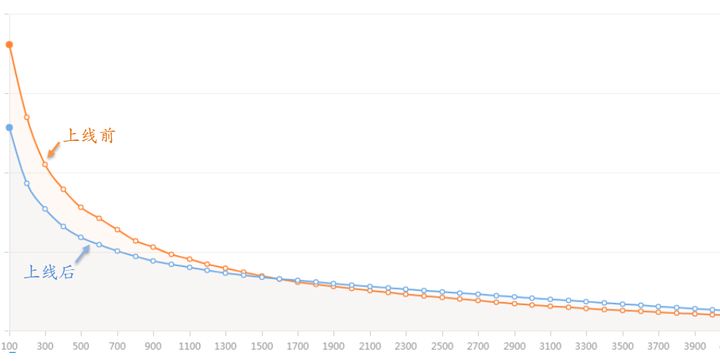
上图是上线前后商家流量的对比图,横坐标的商家的每日流量排名,纵坐标是商家每天获取到的流量总量,具体数值已略去。
有网友对文中的公式推导有疑问,故补充推导的详细过程,如下图:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?