《数据分析篇》——初探用户画像
〇、当我们在谈用户画像时我们在谈什么?
当谈到用户画像时,有一些人会用到persona这个词,并引用 Alan Cooper的定义:Personas are a concrete representation of target users。
这有两个问题:
1、Cooper的原话是:A persona is a fictitious, specific and concrete representation of target users,出自其1999年出版的 The Inmates are running the Asylum,中译名为《软件创新之路》。既然要引用,就别把关键的fictitous和specific给省掉啊喂。
2、从其定义而言,persona实际是用一个虚构的用户去代表大部分的用户,在中文语境下这更应该被称为典型用户,或者叫用户角色。为表区分,下文统称典型用户。
通常意义下,用户画像更应该用user profile来描述,这与典型用户绝对不是一回事。所以下次看到有人明明要谈用户画像却瞎引用Cooper的persona时,请直接怼回去吧!
那么典型用户(user persona)和用户画像(user profile)要如何区分呢?
典型用户
微信曾经公布过微信典型用户的一天:
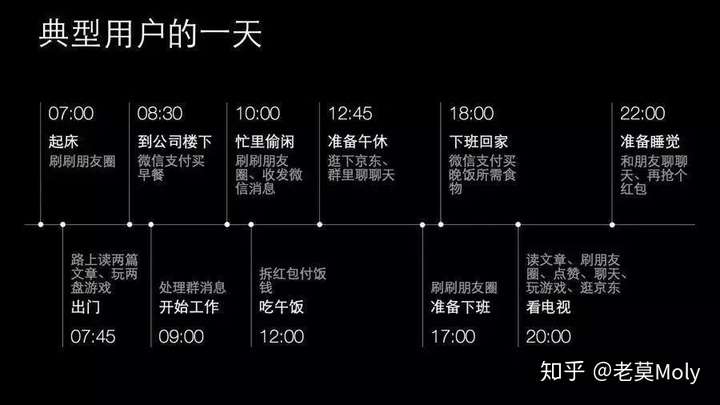
某APP的典型用户
她本科毕业,现26岁,在互联网公司上班,每天早上8点出门挤地铁。在地铁上喜欢边听歌边刷微博和小红书,在微信群里和姐妹聊聊八卦。晚上9点回到家,洗完澡后窝在床上刷刷最新的综艺和电视剧,临睡前逛逛淘宝,把看到喜欢的宝贝放到购物车里但很少下单。周末大部分时间在房间里,出门喜欢吃日料、火锅和街边的小吃。
实际上,并不是所有微信用户都在早上7点起床刷朋友圈,该的APP的用户也不全是女性并在互联网公司上班,但这并不妨碍虚构出这样一个用户,用他的一些行为和特征去代表其他用户。
用户画像
用户画像更像是通过贴标签的方式给每个用户建立档案,并以结构化表格的形式存储:
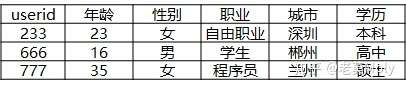
某种程度上可以认为,典型用户是用户画像的应用,用户画像是典型用户的基础。
需要注意的是,用用户画像去虚构出一个典型用户时不要盲目采用平均数,例如一款幼儿教育产品,其用户有10岁的小孩和40岁的父母,但平均后不能说这款产品的典型用户是25岁的年轻人。
一、用户画像的作用
了解用户
我们的用户是谁?我们的用户在哪?我们的用户为什么要我们的产品?这些基础又重要的问题需要通过用户画像来解答。
精准营销
不同的公司可能用的名字不一样,但发展到一定程度或多或少会出现一个用于精准营销的平台,运营人员可以在这个平台上按需圈选出特定的用户,或短信、或邮件、或消推,用不同的方式把营销信息触达到客户,这样的平台就非常依赖用户画像的构建。
个性化推荐
淘宝、当当、京东商品页的“猜你喜欢”,网易云音乐的日推,B站客户端出现在首页的视频,知乎推荐tap页下的问题和回答,抖音和快手的滑动播放的视频,这些功能或许是用算法或许是用标签等方法来实现,但其实质还是通过在底层构建用户画像达到千人千面的效果。
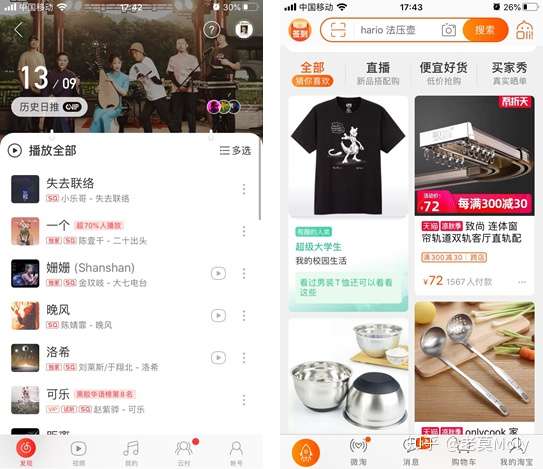 网易云音乐的日推和淘宝的猜你喜欢
网易云音乐的日推和淘宝的猜你喜欢
产品优化
用户画像能为产品同学提供洞察,进而有针对性地改善产品功能,例如:通过监控不同功能的使用情况发现,某功能深受高消费人群的青睐,在后续迭代中可考虑重点优化该功能。
开展运营活动
运营同学能够利用用户画像开展差异化的活动,例如:向价格敏感用户定向发放优惠券以刺激其完成消费。
二、用户画像分类
按其标签计算的方法可分为:统计类、规则类、算法类
统计类
统计类是最常见的标签,如性别、年龄、职业、近7天活跃天数、近7天累计访问时间、近30天累计消费金额等,这些标签往往要么所见即所得,要么通过简单地累加即可得到。
规则类
这类标签需要事先给定规则才能得到,如“轻度用户”的定义是过去7天使用次数小于等于3次,“流失用户”的定义是过去30天没有活跃过,这些规则需要业务方和数据同学共同商议决定。
算法类
算法类标签在规则类更近一步,或通过聚类或通过分类模型,把用户抽象成好几类,如“御宅族”、“社交狂魔”、“氪金大佬”等,这些标签很难用几条明规则来完成分类,而需要借助算法和模型来达到区分用户的目的。
按更新频率可分为动态标签和静态标签:
静态标签
静态标签指用户的一些较为固定、变化缓慢或者不变化的属性,如出生年月日、身份证号码、性别、籍贯、居住地、年收入区间等。
动态标签
动态标签与静态标签想对应,这一类标签变化较快,甚至每天都会发生变化,如最后登录时间、过去7天消费总金额、统计日的购物车内商品数量等。
但当我们需要开始给用户建立标签体系构成用户画像时,如果只是知道统计类、规则类和算法类,或者静态标签和动态标签这些分类方法,是否还是感到无从下手?下面根据我自己构建用户画像时的经验,总结了一种对用户画像标签分类的方法,根据该方法可尽量做到常用标签的不重不漏,需要特殊标签时也能便于开脑洞,下面对该方法做简单的介绍。
首先,我们把用户画像的标签分为人口统计学属性和业务属性。
人口统计学属性
人口统计学属性是自然属性和社会属性相结合的以个体人为单位的属性集合,这些属性可套用到任何产品、任何行业和任何领域里,尽管有时一些属性的侧重点可能会不一样,但大体上都是通用的。
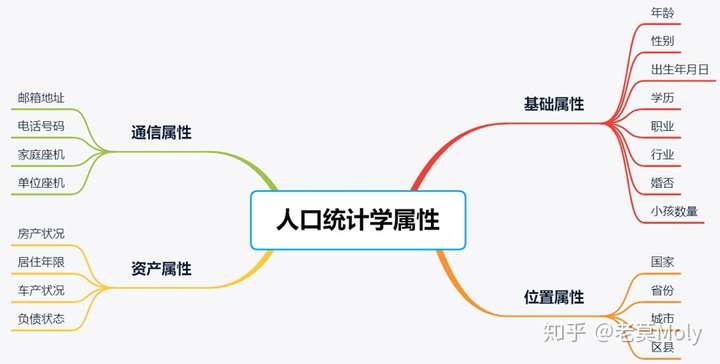
如上是根据人口统计学所拓展出来的不同细分属性,有一些属性是所有领域通用的,如基础属性和位置属性,有一些则是个别领域更为关注的,如金融领域会特别关心用户的资产属性。尽管人口统计学属性可以不断延伸和细分,但也要结合实际可获得的标签属性来构建用户画像,如非金融机构实际上没办法准确获取到用户的资产属性的,而一些隐私属性如小孩数量、婚姻状况等是很难直接获取的,这时如果需要用到属性则要用算法来进行推测。
业务属性
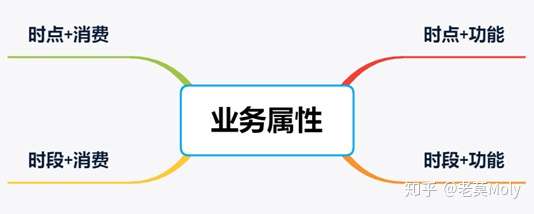
区别于人口统计学属性,业务属性是立足实际业务领域和场景构建出来的。在业务属性下可按照一定的逻辑关系进行分类重组,便于对不断拓展细分属性,也避免遗漏掉一些重要属性。
以互联网产品的用户画像为例:
任何一款互联网产品的商业模型可简化为:以其核心功能去满足用户的特定需求然后获取收入实现盈利。为了有效地构建用户画像,可从用户使用核心功能的情况以及付费情况来拓展用户的相关标签属性。同时,由于我们既会关心用户在某个时点的截面属性,也会关心一段时间内的累计属性,因此上述提到的核心功能和收入与时点和时段交叉结合构建出:时点+功能、时段+功能、时点+消费和时段+消费的用户标签体系。
本篇仅提供一个思路,其详细说明和实际应用将放在用户画像的另一篇里。
一点补充:
有时,所构建的用户的标签是基于业务需要而开展的,如运营需要圈一波沉默用户推送优惠广告来激活,但并非所有用户标签都是为业务而服务的。如这个“沉默用户”标签,可能是基于显式规则则制定出来的,也可能是通过黑箱的模型而划分出来的。当用模型对用户进行分类所需要的维度可能会是几十到这上百个,这些维度并不都是现成的,有一些需要经过特殊地处理才能放到模型里进而提升模型的准确度,这在算法模型领域就是所说的“特征工程”,所以用户画像除了直接为业务服务,有时也是在为算法模型做贡献。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了