《波动解读—指标拆解的加减乘除双因素》
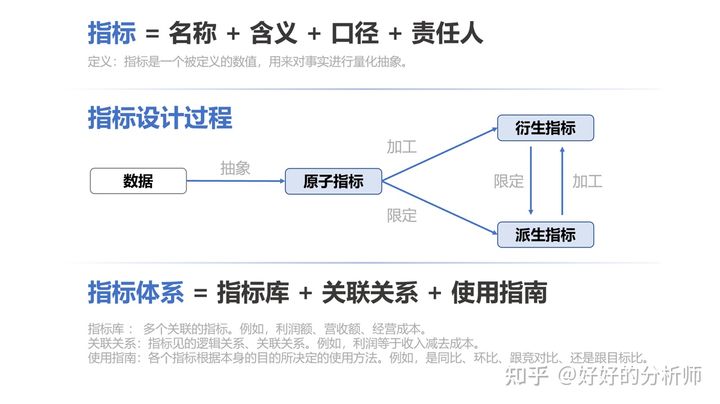 图1:指标与指标体系相关概念(详见上述超链接推文)
图1:指标与指标体系相关概念(详见上述超链接推文)
当我们有了指标体系,开始用指标量化的方式,来描述、追踪、推动业务时,很自然地就产生了一项工作——对指标进行解读,尤其是对波动进行解读。
一、指标解读的类型
对指标的解读,按照顺序,可以分为2步:判断与归因。首先,当我们要解读指标变动时,要给出一个判断,这个变动是不是个问题。如果是个问题,第二步我们要做的就是判断问题出在哪里。
- 判断:对指标进行判断类解读,是指当一个指标在某个水平,或变化时,给出一些判断,例如:指标的现状是好还是坏?是不是个问题?需不需要解决?
- 归因:对指标进行归因类解读,是指当一个指标在某个水平,或变化时,给出一些解释,例如:这个现状是由哪些因素构成的?这个变化是由哪些因素导致的?主因是什么?
判断类的解读,可以用“一量三比”[1]的方法进行初步地处理。现在假设,我们已经判断某个指标存在问题了,应该如何对这个问题进行归因呢?
Boss:
这阵子我们的业务出了一些问题;
可是我也不太清楚问题出在哪里?
那冷冷冰冰的指标,不剩多少意义。
就当我求求你,给我一些说明!
二、因果推断的层次与对应的方法
对问题的归因,按照顺序,可以分为2步:明确目标与选定方法。
- 明确目标:首先,我们要明确希望得到什么程度的结论,以及对这个结论的确定性有怎么样的期待。根据期望得到的结论与期望的可靠程度,我们可以将“归因”分为3个层次。分别为:猜测性因果推断、可能性因果推断、确定性因果推断。
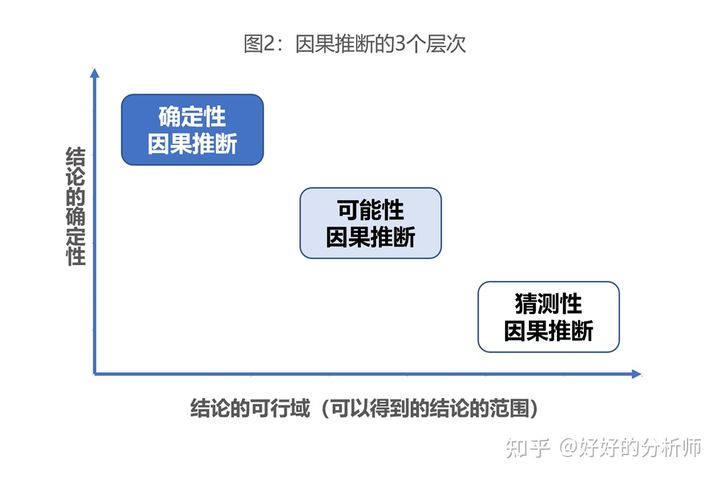
这里举个例子,说明一下这3类推断的含义:
确定性:
例如,现在公司本季度的销售业绩不达标,我们想要找到最拖后腿的10%的小组,这就是一个希望得到“确定性因果推断”的例子。
可能性:
如果,我们现在想要知道的是,是哪些因素导致了团队业绩不达标(例如是出勤情况不佳导致,还是面访执行不佳导致),这就是一个“可能性因果推断”的例子。因为,通常而言,这种多个因素之间的因果关系判断,不是确定性的。
猜测性:
假设,我们通过数据探查发现,所有小组的出勤情况都不错,面访执行率也不差,其他能数据验证的因素都没有得出有价值的结论。在实际的工作场景中,我们可能会猜测:是不是由于最近疫情影响了消费者的消费能力?是不是竞对最近有了力度更大的促销活动?这就是“猜测性因果推断”。
使用“猜测性因果论断”时,要注意两点:不要不敢猜测;不要只会猜测。第一,不要拘泥于数据岗位的职责,只敢给数据判断,不敢给业务判断;“猜测性因果推断”也是信息增量。第二,“猜测性因果推断”不是纯粹的通过数据证明的结论,因此给出“猜测”并不是分析的终点,而是起点。当我们有了猜测之后,要尽可能地通过数据的手段去还原与验证结论。
- 选定方法:不同层次的因果推断,对应的是不同的数据分析方法。
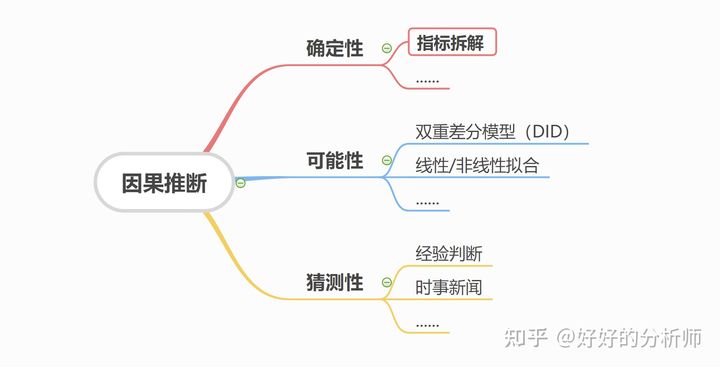 【图3:3类因果推断对应的方法示例】
【图3:3类因果推断对应的方法示例】
本文要介绍的是“确定性因果推断”中的“指标拆解”。其他各类方法的介绍,参见《4类数据分析问题对应的解决方案》。
三、指标拆解的5种方式
“贫僧唐三藏,自东土大唐而来,欲往西天拜佛求经。今日路过宝刹,见天色已晚,想在贵地借宿一晚,化些斋饭,明早便行。” —— 唐僧
真挚的友谊来自不断的自我介绍,唐三藏每次出场的自我介绍,都回答了人生的四大问题:
- 我是谁?(唐三藏)
- 自何处来?(东土大唐)
- 往何处去?(西天取经)
- 怎么去?(借宿一宿,明早便行。)
对于指标而言,同样存在着4个问题:
- 我是谁:现状是怎么构成的?
- 自何处来:变化是怎么构成的?
- 往何处去:未来会怎么变化?
- 怎么去向美好未来:要实现指标向好,该怎么做?
要回答这4个问题,我们必须要从静态和动态两个方面,对指标进行解读。简单而言,就是我们不仅要解释 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237563-96892997.svg) ,还要解释
,还要解释 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237465-1842155257.svg) 。
。
并且,根据不同的指标设计,我们需要采用不同的拆解方式。
以下归纳了6种常用的指标拆解方式,可以基本覆盖问题定位、贡献计算等工作场景的需要。也欢迎大家补充没有覆盖的工作场景与拆分方法。
1. 加法拆解 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237575-1149935727.svg)
对于绝对量指标的维度拆解,我们可以用加法拆解。
假设,要解读的绝对量指标为 ,例如新增保费收入。通过维度拆解,例如按城市拆解,可以分为n个城市的新增保费收入 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237580-1230583492.svg) 、
、![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237726-1996355375.svg) 、
、![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237738-11338757.svg) 到
到 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237710-401430256.svg) 。
。
那么当我们要分析目前的业绩达成构成的时候,可以用静态的加法拆解。
(1)静态加法拆解 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237487-1266103457.svg) 当我们需要分析同比量的变化时,可以用动态的加法拆解。
当我们需要分析同比量的变化时,可以用动态的加法拆解。
(2)动态加法拆解 (单因素拆解)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237597-686476614.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237476-1468450221.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237776-1551605826.svg)
那么如果要分析同比变化,各个城市的贡献是多少的时候应该怎么计算呢?
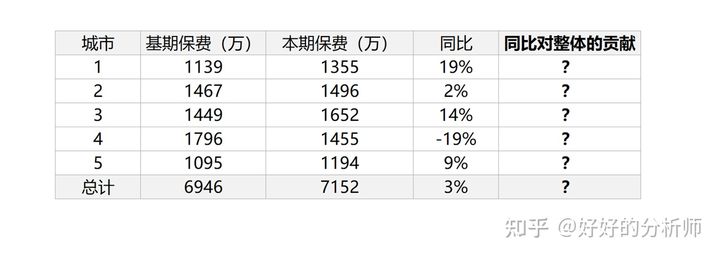 表1:分城市保费达成情况示例
表1:分城市保费达成情况示例
- 大家可以先双击屏幕,暂停思考一下,再继续查看参考的解决方案。
因为绝对量指标的同比变化,就是各个分项指标变化的求和,所以各个分项对整体同比变化的贡献 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237968-519695105.svg) 可以依据下式计算:
可以依据下式计算: ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237732-2105597650.svg)
实测如下:
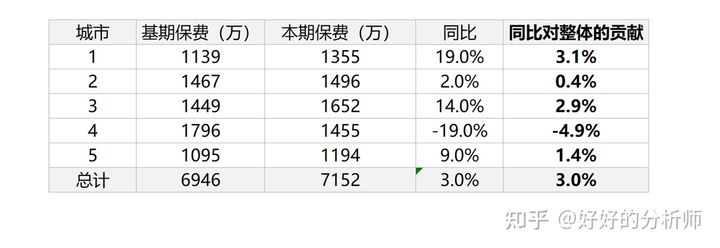 图2:分城市保费达成贡献测算
图2:分城市保费达成贡献测算
2. 减法拆解 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237572-547964580.svg)
对于通过(加)减法设计出的衍生指标,我们可以用减法拆解。
假设,要解读的绝对量指标为 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237571-328547938.svg) ,例如利润。通过指标拆解,可以将其分为收入
,例如利润。通过指标拆解,可以将其分为收入 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237562-1444204132.svg) 、成本
、成本 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237564-496798231.svg) 与费用
与费用 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237387-46163431.svg) 。
。
那么当我们要分析利润过低,是由于哪个因素导致的时候,可以使用静态减法拆解。
(1)静态减法法拆解![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237636-1362724247.svg) 当我们要分析利润降低的原因时,可以使用动态减法拆解。
当我们要分析利润降低的原因时,可以使用动态减法拆解。
(2)动态减法拆解
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237745-989508359.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237614-633641899.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237624-1109755718.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237605-1171919819.svg)
3. 乘法拆解 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237753-1158583465.svg)
对于通过涉及到流程链路的指标,我们可以用乘法拆解。
(1)静态乘法拆解
假设,要解读的衍生指标为 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237627-627176427.svg) ,例如新增成交用户数。依据流程分析的思路,将其分为了4个漏斗节点:获取用户、用户激活、用户留存、用户购买。我们用四个指标来衡量这四个节点的表现:新增用户量
,例如新增成交用户数。依据流程分析的思路,将其分为了4个漏斗节点:获取用户、用户激活、用户留存、用户购买。我们用四个指标来衡量这四个节点的表现:新增用户量 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237757-1453346864.svg) 、新用户激活率
、新用户激活率 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237755-1682516365.svg) 、激活用户3日留存率
、激活用户3日留存率 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237765-884368660.svg) 、留存用户购买率 。现在我们就有了
、留存用户购买率 。现在我们就有了
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237785-1166127550.svg)
通过这样的拆解,我们就能知道每个节点的业务表现如何。那么如何衡量哪个节点更加重要呢?
(2)动态乘法拆解(敏感性分析 与 LMDI乘积因子拆解)
这里介绍2种方法:敏感性分析法与LMDI乘积因子拆解法
- 敏感性分析
这个方法的核心思想是,通过推算每个因子某种程度上的波动,会对目标函数(指标)产生的影响的大小,来衡量它的重要性 。
以留存购买率 为例,当 变动 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237806-901091853.svg) 时,对 的影响大小为:
时,对 的影响大小为:
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237828-874155939.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237865-1290078456.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237864-375852074.svg)
因此在乘积拆解的公式当中,每个因素的重要性,即其对目标函数 的影响,与其自身的变化率是等价的。以上是,只有2期数据的简单情况。
当我们的历史数据有n个数据点时,我们可以用每个因子的变异系数 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237872-1471609646.svg) ,来衡量它的变化程度,进而衡量这个因子的重要性。
,来衡量它的变化程度,进而衡量这个因子的重要性。
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237912-1605905162.svg)
其中, ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237927-1966118882.svg) 是变量
是变量 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237966-893591149.svg) 的标准差,
的标准差, ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201237967-244237667.svg) 是 的平均值。
是 的平均值。
证明:略。
以上就通过控制变量的方式,对每个因子对于整体指标 的影响作出了一个刻画。
但是有经验的同学,会很自然的想到一个问题:以上的推演,是单变量变化的情况;但事实上, 的变化由4个因子影响,而且通常而言它们是同时变化,共同影响结果的。如果采用敏感性分析的方法,能把这种情况解释清楚吗?
- 很遗憾,不能。
通过敏感性分析的方式,测算每个因子对于目标函数 的影响后求和,不等于4个因素对于目标函数 的整体影响。
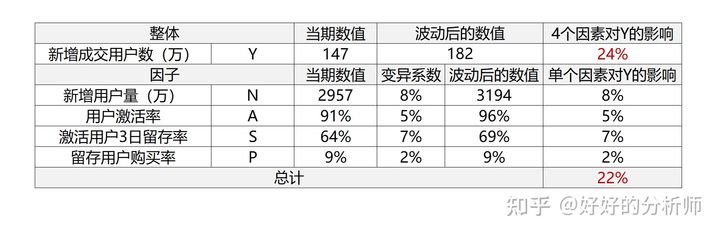 表3:敏感性分析测算实例
表3:敏感性分析测算实例
那么如何才能解决这个问题呢?
- LMDI(Logarithmic Mean Index Method)乘积因子拆解
回顾一下我们的问题:我们有一个结果指标新增成交用户数 。它由4个结果指标构成,分别为:新增用户量 、新用户激活率 、激活用户3日留存率 、留存用户购买率 。
我们希望,通过计算因子波动对结果指标 的影响,来衡量这4个指标的重要性如何。
或是另外一个非常常见的工作场景,Y发生了较大的波动。我们希望通过指标拆解,清楚地说明,各个因素的变动对整体的波动产生了什么样的影响。
首先我们通过LMDI算法计算 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238075-1261399606.svg) 中,新增用户量 贡献了多少(
中,新增用户量 贡献了多少( ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238075-388442994.svg) )、新用户激活率 贡献了多少 (
)、新用户激活率 贡献了多少 (![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238084-1621188030.svg) )、激活用户3日留存率 贡献了多少(
)、激活用户3日留存率 贡献了多少( ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238095-554025724.svg) )、留存用户购买率 贡献了多少(
)、留存用户购买率 贡献了多少( ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238122-1929807501.svg) )。
)。
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238144-138833729.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238158-1157260567.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238177-539714891.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238193-609717580.svg)
其中 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238200-1755281567.svg) 为平均对数权重(Logarithmic Weight Average)
为平均对数权重(Logarithmic Weight Average)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238226-1834201396.svg)
然后我们计算这4个因子对整体变化率的贡献,即重要性。
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238234-1846793601.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238232-173961757.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238243-1575305001.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238254-398660070.svg)
实测如下:
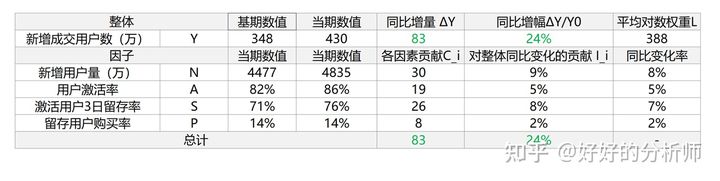 表4:LMDI乘积因子拆解测算实例
表4:LMDI乘积因子拆解测算实例
证明参见:
[1] Ang, Beng W., F. Q. Zhang, and Ki-Hong Choi. "Factorizing changes in energy and environmental indicators through decomposition." Energy 23.6 (1998): 489-495.
[2] Ang B W . The LMDI approach to decomposition analysis: a practical guide[J]. Energy Policy, 2005, 33(7):867-871.
该算法有2个显著的优点:
i. MECE(不重不漏):
通过LMDI对各个因子变动的影响进行测算后,对各个因子的贡献求和,会等于整体指标的变化率,不会存在解释不清楚的部分。
证明:
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238296-250287746.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238331-267036825.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238352-272799764.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238366-1494009110.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238393-1734410229.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238434-459482540.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238446-1866662843.svg)
ii. 计算独立:
有些聪明的同学,在工作中会对敏感度分析法进行改良,采用逐步替代因子变化率的方式计算贡献度。例如先假设新增用户量 变动,计算 的贡献率;再在 变动的基础上,假设新用户激活率 变动,计算 的贡献率。以此类推,计算4个因子的贡献率。这样也可以达成MECE的目的。
但这会导致一个新的问题,贡献率的多寡,依赖于替代的次序。同一个因子,因计算的替代顺序不同,会计算出不同的贡献率。这是逐步替代法很难解释的部分。而采用LMDI,每个因子的贡献率计算过程是相互独立的。无论先算哪个结果都一样。
4. 除法拆解 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238565-1485396107.svg)
对于涉及到多个因素、包含关系等的比例指标,我们可以使用除法拆解。
(1)静态除法拆解(乘一法)
假设,要解读的衍生指标为 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238593-518992151.svg) ,例如呼叫中心的单位人员效率。依据目前的定义:单位人员效率等于员工的实际服务量
,例如呼叫中心的单位人员效率。依据目前的定义:单位人员效率等于员工的实际服务量 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238592-461430724.svg) ,除以员工的上班时长
,除以员工的上班时长 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238594-1367243079.svg) 。
。
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238635-258492294.svg)
单位人员效率,是不少客服中心的核心KPI;但运营起这个核心指标却不是件容易的事,原因有二。
- 第一,影响这个指标的达成的因素较多,如服务的需求量、员工的能力、排班的优劣等等。
- 第二,这些因素通常有可控因素,也有不可控因素;即使是内部可控的因素,也可能因为组织架构、生产关系等原因,归属与不同的团队职能,非常容易扯皮。
那么这个问题该如何解?我们可以通过除法拆解的方式,对影响因素进行拆解。进而帮助团队,做到管理学上的“权责对等”与“责任到人”。为了利于业务的同学理解,好好称这个方法为“乘一法”。
- 首先,我们将客服上班时间中的直服排班时间(直接服务客户)与综合工作时间(如数据标注、培训等等)区分清楚。
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238657-1746893299.svg)
拆分除法,交换分母。
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238682-778071354.svg)
- 然后,我们将排班时间中的在线时长与非在线时长区分清楚。
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238689-1939740154.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238716-752312282.svg)
拆分除法,交换分母。
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238750-757056508.svg)
- 接着,我们将在线时长中的在线服务时长与候线时长区分清楚。
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238766-2014856046.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238789-293292694.svg)
拆分除法,交换分母。
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238816-1569868568.svg)
- 最后我们将拆分出来各类因素,设计成新的指标,并找到与之对应的责任人。
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238840-1795068766.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238855-101184531.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238877-1417959322.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238874-2040881704.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238889-408173622.svg)
客服服务能力与客服遵时率,责任归属与服务运营团队;有效排班率,责任归属与资源运营团队;直服工作调控比例,责任归属于管理团队。
通过除法拆解的方式,将一个结果指标拆分为多个运营指标,做到“权责对等”与“责任到人”。
每次当业务的同学或管理层感叹“这个指标的问题非常复杂。”、“涉及的因素比较多”,而各个因素的影响又没有量化清楚的时候,就是数据同学大显身手的时候了。
不妨尝试一下用“乘一法”拆解这个问题。
(2)动态除法拆解
当我们对指标完成静态的除法拆解之后,动态的拆解方法同“乘法”:敏感性分析法、LMDI乘积拆解法。
5. 双因素拆解
在加法拆解的部分中,我们有介绍对于绝对数指标的“单因素拆解法”。但是很多时候,我们要解读的并不是绝对数指标,而是相对数指标,例如转化率、好评率等等。那么当我们需要对相对数指标进行维度拆解,变动归因的时候,应该怎么做呢?
双因素分析[2]是一个能够解决此类问题的非常好的算法。为什么称之为“双因素分析法”,因为相对数指标的分项对整体的贡献,受两个因素影响:
- 分项的相对数指标达成情况
- 分项在整体中所占的比重
假设,要解读的相对数指标为客户满意度(CSAT),在此满意度的定义为:
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238906-107684067.svg)
目前的业务现状是,全球客户的服务由由英、日、韩、粤、普通话五条语言线承接。
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238908-1203528429.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238972-652705449.svg)
这里的E(English)表示英文线;J(Japanese)表示日文线;K(Korean)表示韩文线;C(Cantonese)表示粤语线;M(Mandarin)表示普通话线。各语言线参评量的占比用 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238941-2130443066.svg) 表示,各语言线好评量的占比用
表示,各语言线好评量的占比用 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238940-1334550523.svg) 表示。
表示。
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238989-983715096.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238955-1711902733.svg)
这里 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238963-1842730421.svg) 为所有的参评量;
为所有的参评量; ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238969-916365129.svg) 为所有的好评量。
为所有的好评量。
本期的满意度较上期有所下跌,我们想定位一下是哪条语言线出现了问题;各个语言线的达成,对整体达成的贡献 是怎么样的。(即,按语言线维度进行维度拆解。)
这里的贡献 又两部分构成:
- 分项的相对数指标变化的贡献
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238999-1072777868.svg)
- 分项在整体中的占比变化的贡献
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238998-1970409156.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201238990-452410759.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201239023-112725114.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201239029-2065201118.svg)
简而言之:
- 分项的指标波动贡献 = 满意度同比变化值 * 上期参评占比
- 分项的结构变化 = 占比同比变化值 * (分项本期满意度 - 整体上期满意度 )
实例如下:
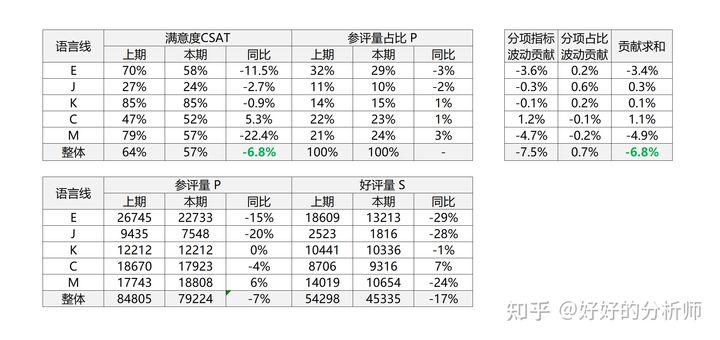 表5:双因素拆解测算实例
表5:双因素拆解测算实例
该算法对于贡献率的计算同样是MECE且相互独立的。
i. MECE:
证明:
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201239054-1800272964.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201239073-2058190579.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201239088-460589422.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201239093-1831109714.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201239102-186821679.svg)
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201239104-1995251846.svg)
ii. 相互独立:
证明:参见 与 的计算公式,不涉及到除 以外项本期的达成情况。
该方法可以适用任何单一分子分母的相对数指标解读,包括但不限于:转化率、退款率、故障率、好评率、差评率等等,不一而足。
PS:
资深一些的同学,可能又会想到一个问题,以上的双因素测算方法,只覆盖了维度标签保持一致的情况。换言之,在我们今天所用的案例当中,就是指上期有5条语言线,本期依旧是5条语言线的情况。如果说我们本期新增了一条语言线,能否使用这个方法,去测算呢?
- 很遗憾,不能。
原因是,如果本期存在上期没有的语言线(维度标签),就无法计算这条语言线的满意度同比变化 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201239126-1727378670.svg) 、占比同比变化
、占比同比变化 ![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201239127-977980227.svg) 。
。
“不听不听,王八念经。”“我就要!我也要!我还要!”
但是在实际的工作中,变化是很快的;新增语言线并不是件罕见的事,是我们必须要处理的业务场景。(或者是对于转化率而言,新增入口;对于退款而言,新增渠道;等等)
那么应该如何处理类似的情况呢?
有个小技巧可以很简单的解决这个问题,大家可以双击屏幕,稍微思考一下。
即,将新增语言线(新增维度标签)上期的参评量与好评量设置为1。这样同样可以保证计算的贡献结果是MECE,且相互独立的。感兴趣的同学,可以尝试证明一下~
实例如下:
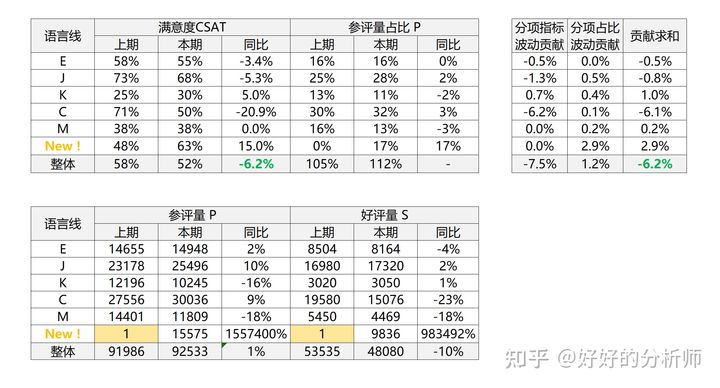 表5:双因素拆解推广测算实例
表5:双因素拆解推广测算实例
○ 变式训练
以上介绍了5种指标拆解的方式,现在思考一下:形如下式X的指标,应该如何解释其现状构成与波动贡献呢?
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201239162-1441260175.svg)
好好:
Okay~ 这不是暂时的数据波动问题
必须要找原因 多给业务一点关心
打电话给你发 最新的会议邀请
你说工作很忙 要加班到夜里
Okay~你忙先 我写套方法论给你
四、小结一下~
- 指标解读的类型:2类,判断与归因。
- 因果推断的步骤:2步,明确目标与选定方法。
- 因果推断的层次:3层,确定性、可能性、猜测性。
- 指标拆解是一种常用的确定性因果推断。
- 5类指标拆解方法:加、减、乘、除、双因素拆解。
“知己知彼,百战不殆;不知彼而知己,一胜一负;不知彼不知己,每战必败。”——《孙子兵法 · 谋攻篇》
![[公式]](https://img2020.cnblogs.com/blog/2304373/202109/2304373-20210922201239178-1828013021.svg)
参考
- ^绝对量级看影响,和自己比看趋势。和目标比看完成,和别人比看差距。
- ^在此由衷感谢《新电商时代》的作者高云惠老师~ https://item.m.jd.com/product/26653530446.html?gx=RnE2lzENYGKKn9R28Nc1DNdCftA&ad_od=share&utm_source=androidapp&utm_medium=appshare&utm_campaign=t_335139774&utm_term=CopyURL
