解析html中的table和表头
原始数据如下:
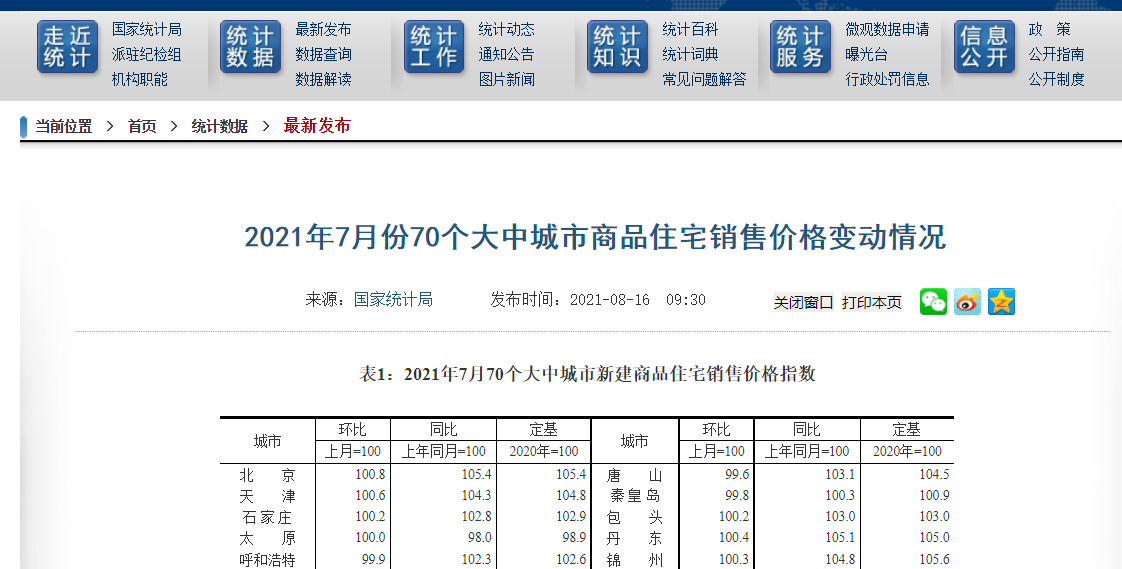
解析后的数据如下:
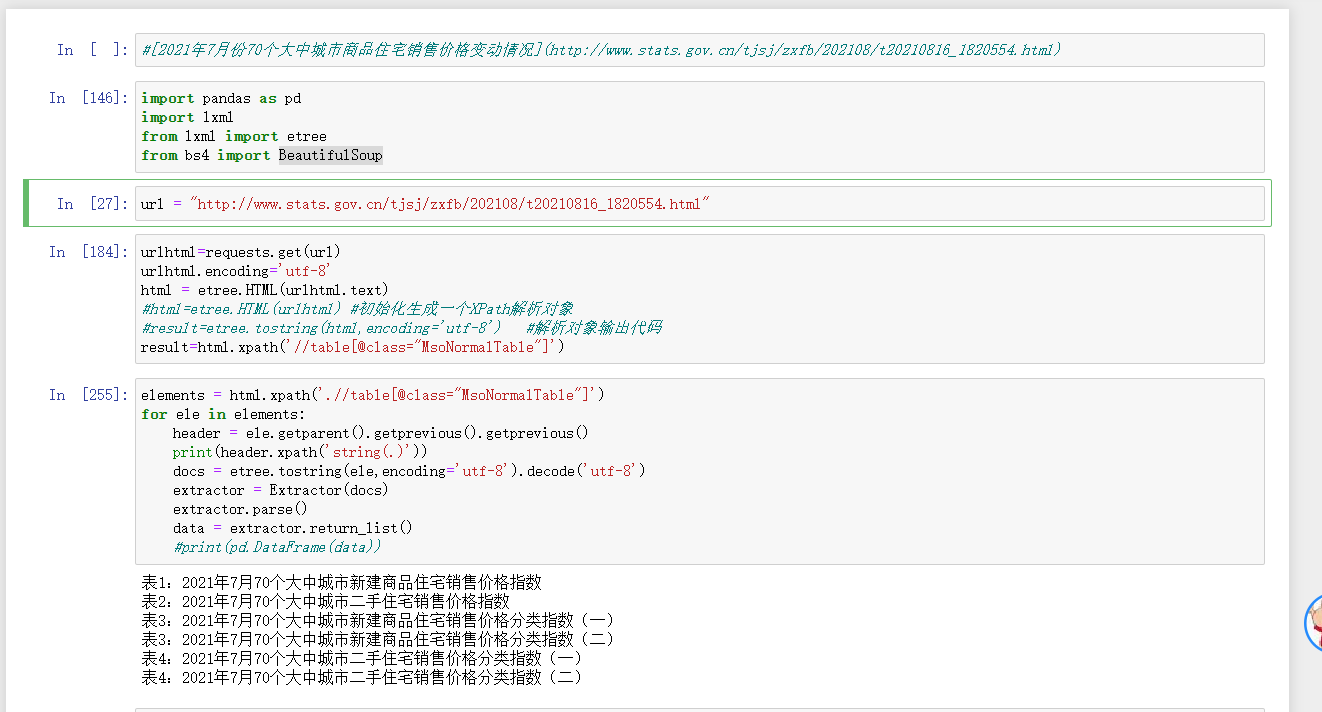
补充代码
import pandas as pd
import lxml
from lxml import etree
from bs4 import BeautifulSoup
url = "http://www.stats.gov.cn/tjsj/zxfb/202108/t20210816_1820554.html"
urlhtml=requests.get(url)
urlhtml.encoding='utf-8'
html = etree.HTML(urlhtml.text)
#html=etree.HTML(urlhtml) #初始化生成一个XPath解析对象
#result=etree.tostring(html,encoding='utf-8') #解析对象输出代码
result=html.xpath('//table[@class="MsoNormalTable"]')
elements = html.xpath('.//table[@class="MsoNormalTable"]')
for ele in elements:
header = ele.getparent().getprevious().getprevious()
print(header.xpath('string(.)'))
docs = etree.tostring(ele,encoding='utf-8').decode('utf-8')
extractor = Extractor(docs)
extractor.parse()
data = extractor.return_list()
#print(pd.DataFrame(data))
#Extractor
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup, Tag
import os
import csv
import pdb
class Extractor(object):
def __init__(self, input, id_=None, **kwargs):
# TODO: should divide this class into two subclasses
# to deal with string and bs4.Tag separately
# validate the input
if not isinstance(input, str) and not isinstance(input, Tag):
raise Exception('Unrecognized type. Valid input: str, bs4.element.Tag')
soup = BeautifulSoup(input, 'html.parser').find() if isinstance(input, str) else input
# locate the target table
if soup.name == 'table':
self._table = soup
else:
self._table = soup.find(id=id_)
if 'transformer' in kwargs:
self._transformer = kwargs['transformer']
else:
self._transformer = str
self._output = []
def parse(self):
self._output = []
row_ind = 0
col_ind = 0
for row in self._table.find_all('tr'):
# record the smallest row_span, so that we know how many rows
# we should skip
smallest_row_span = 1
for cell in row.children:
if cell.name in ('td', 'th'):
# check multiple rows
# pdb.set_trace()
row_span = int(cell.get('rowspan')) if cell.get('rowspan') else 1
# try updating smallest_row_span
smallest_row_span = min(smallest_row_span, row_span)
# check multiple columns
col_span = int(cell.get('colspan')) if cell.get('colspan') else 1
# find the right index
while True:
if self._check_cell_validity(row_ind, col_ind):
break
col_ind += 1
# insert into self._output
try:
self._insert(row_ind, col_ind, row_span, col_span, self._transformer(cell.get_text()))
except UnicodeEncodeError:
raise Exception( 'Failed to decode text; you might want to specify kwargs transformer=unicode' )
# update col_ind
col_ind += col_span
# update row_ind
row_ind += smallest_row_span
col_ind = 0
return self
def return_list(self):
return self._output
def write_to_csv(self, path='.', filename='output.csv'):
with open(os.path.join(path, filename), 'w') as csv_file:
table_writer = csv.writer(csv_file)
for row in self._output:
table_writer.writerow(row)
return
def _check_validity(self, i, j, height, width):
"""
check if a rectangle (i, j, height, width) can be put into self.output
"""
return all(self._check_cell_validity(ii, jj) for ii in range(i, i+height) for jj in range(j, j+width))
def _check_cell_validity(self, i, j):
"""
check if a cell (i, j) can be put into self._output
"""
if i >= len(self._output):
return True
if j >= len(self._output[i]):
return True
if self._output[i][j] is None:
return True
return False
def _insert(self, i, j, height, width, val):
# pdb.set_trace()
for ii in range(i, i+height):
for jj in range(j, j+width):
self._insert_cell(ii, jj, val)
def _insert_cell(self, i, j, val):
while i >= len(self._output):
self._output.append([])
while j >= len(self._output[i]):
self._output[i].append(None)
if self._output[i][j] is None:
self._output[i][j] = val
结果展示
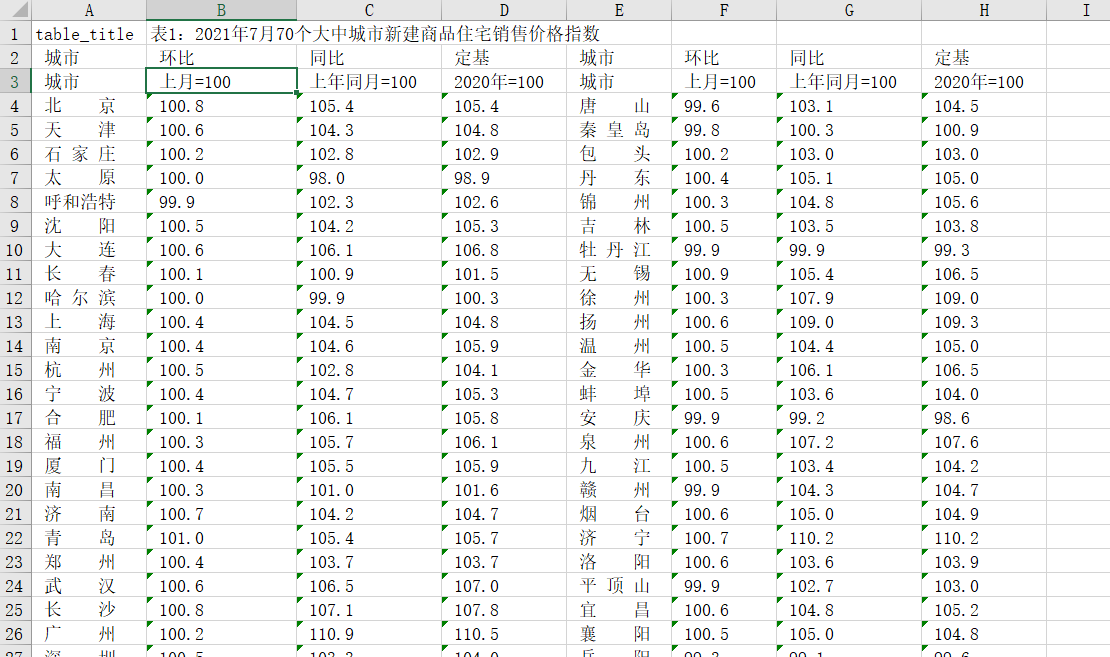
参考
(6条消息) lxml模块常用方法整理总结_彭世瑜的博客-CSDN博客
lxml/Python : get previous-sibling - Stack Overflow
python3解析库lxml - Py.qi - 博客园
yuanxu-li/html-table-extractor: extract data from html table
