


Kafka核心技术与实战——开篇词 | 为什么要学习Kafka?
- 数据密集型
- 由于大数据业务系统都是为公司业务服务的,所以通常来说它们仅仅是执行一些常规的业务逻辑,因此它们不能算是计算密集型应用,相反更应该是数据密集型的
- 对于数据密集型应用来说,如何应对数据量激增、数据复杂度增加以及数据变化速率变快,是彰显大数据工程师、架构师功力的最有效表征。
- 就拿数据量激增来说,Kafka 能够有效隔离上下游业务,将上游突增的流量缓存起来,以平滑的方式传导到下游子系统中,避免了流量的不规则冲击
- Apache Kafka 被认为是整个消息引擎领域的执牛耳者
- 我们仅需要学习一套框架就能在实际业务系统中实现消息引擎应用、应用程序集成、分布式存储构建,甚至是流处理应用的开发与部署
- Kafka 无论是作为消息引擎还是实时流处理平台,都能在大数据工程领域发挥重要的作用
- 学透 Kafka 有什么路径
- 软件开发工程师
- 寻找对应的 Kafka 客户端, Java 客户端
- 一旦确定了要使用的客户端,马上去官网上学习一下代码示例,如果能够正确编译和运行这些样例,你就能轻松地驾驭客户端
- 下一步你可以尝试修改样例代码尝试去理解并使用其他的 API,之后观测你修改的结果
- 如果这些都没有难倒你,你可以自己编写一个小型项目来验证下学习成果,然后就是改善和提升客户端的可靠性和性能了。到了这一步,你可以熟读一遍 Kafka 官网文档,确保你理解了那些可能影响可靠性和性能的参数
- 最后是学习 Kafka 的高级功能,比如流处理应用开发。流处理 API 不仅能够生产和消费消息,还能执行高级的流式处理操作,比如时间窗口聚合、流处理连接等
- 系统管理员或运维工程师
- 那么相应的学习目标应该是学习搭建及管理 Kafka 线上环境。
- 如何根据实际业务需求评估、搭建生产线上环境将是你主要的学习目标。
- 另外对生产环境的监控也是重中之重的工作,Kafka 提供了超多的 JMX 监控指标,你可以选择任意你熟知的框架进行监控。
- 有了监控数据,作为系统运维管理员的你,势必要观测真实业务负载下的 Kafka 集群表现。
- 之后如何利用已有的监控指标来找出系统瓶颈,然后提升整个系统的吞吐量,这也是最能体现你工作价值的地方
- 软件开发工程师
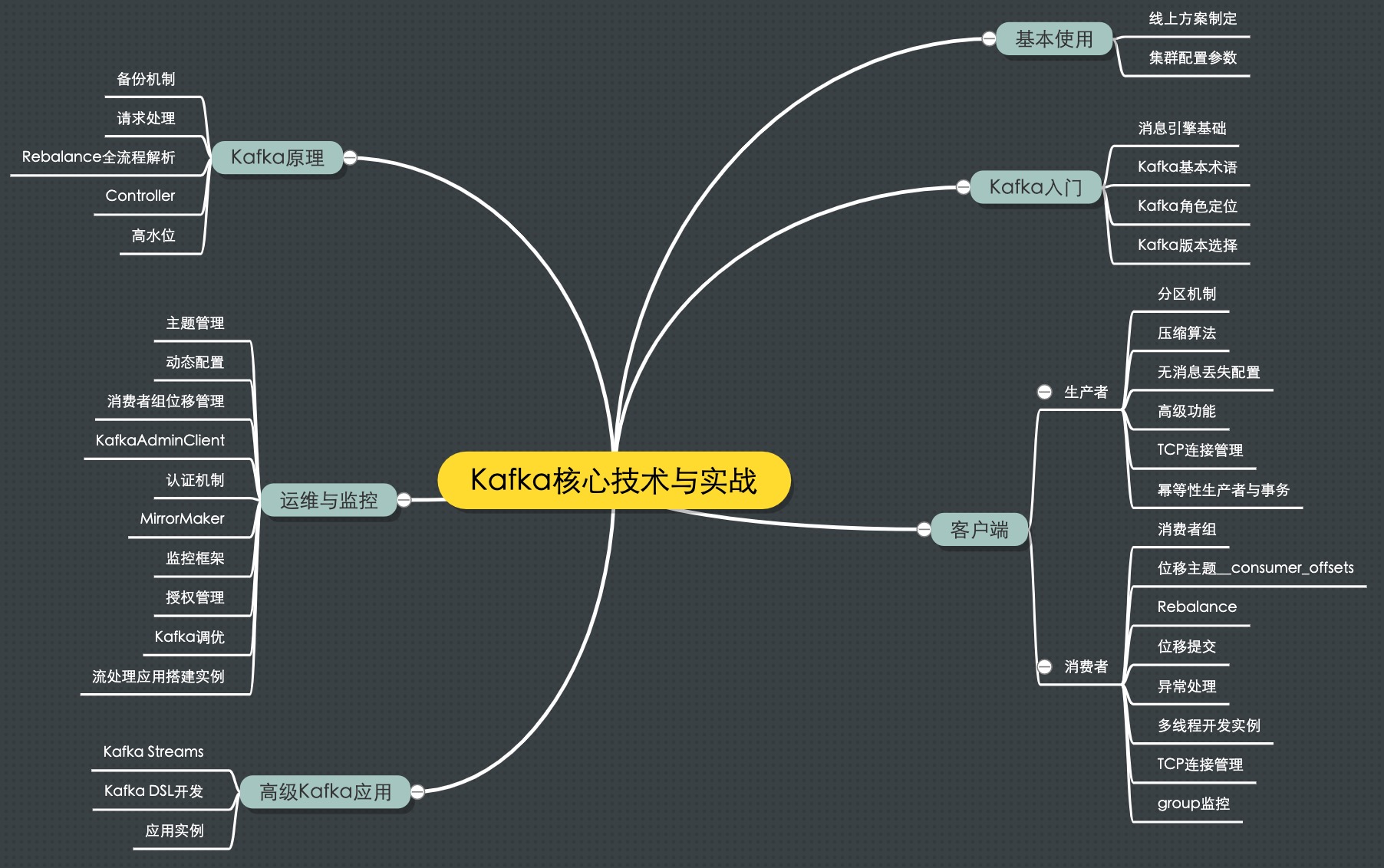
- 专栏知识结构体系
- 专栏的第一部分我会介绍消息引擎这类系统大致的原理和用途,以及作为优秀消息引擎代表的 Kafka 在这方面的表现。
- 第二部分则重点探讨 Kafka 如何用于生产环境,特别是线上环境方案的制定。
- 在第三部分中我会陪你一起学习 Kafka 客户端的方方面面,既有生产者的实操讲解也有消费者的原理剖析,你一定不要错过。
- 第四部分会着重介绍 Kafka 最核心的设计原理,包括 Controller 的设计机制、请求处理全流程解析等。
- 第五部分则涵盖 Kafka 运维与监控的内容,想获得高效运维 Kafka 集群以及有效监控 Kafka 的实战经验?
- 最后一个部分我会简单介绍一下 Kafka 流处理组件 Kafka Streams 的实战应用,希望能让你认识一个不太一样的 Kafka。
-
行者无疆,始于足下
行走,思考,在路上

