



UDP/TCP
UDP:面向数据报的传输层协议,每个进程的每个输出都正好产生一个UDP数据报,这与面向流字节的协议不同。UDP的长度方面,应用程序必须关注IP数据报的长度,如果超过了网络MTU,就要对IP数据报进行分片。
UDP是面向端口号的,UDP头包含源端口号和目的端口号。那端口号也就表示发送进程和接收进程。TCP和UDP的端口号是独立的。
UDP可以关注的几个方面:关注UDP的长度时需要了解下IP分片。还需要关注下最大的UDP长度。
另外,多播和广播仅用于UDP,多播和广播是一种IP地址形式。
什么叫分组:网络世界中不能发送任意长的数据,网络把数据切成小块packet,这个小块也叫分组。
TCP从“TCP的连接与终止”,“TCP数据流”,TCP超时重传机制”,“TCP定时器”这几部分来简单描述。
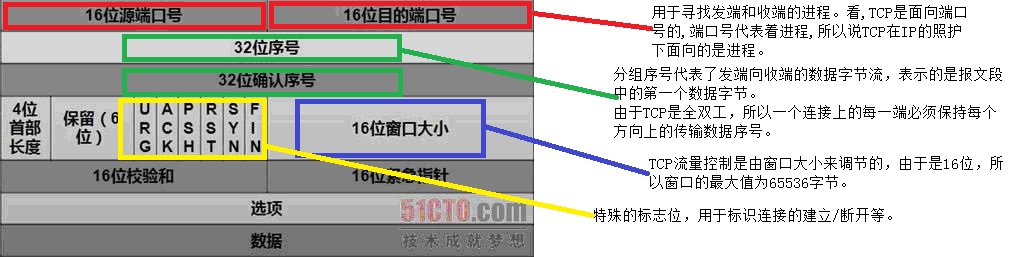
TCP头部(20字节):
(一)TCP连接的建立与终止
从tcpdump看tcp的三次握手:
序号 时间 ip:port
1 0.1 client:6666>server:8888 1415531521:1415531521(0) win(4096) mss<1024>
2 0.2 server:8888>client:6666 1823083521:1823083521(0) ack(1415531522) win(4096) mss<1024>
3 0.3 client:6666>server:8888 ack(1823083522) win(4096)
三次握手的协议中包含几个关键信息:
*) 分组序号:也就是发送端的数据字节流,即包1中的1415531521,接收方的ack回应需要在此分组序号上加一,即包2中的ack(1415531522)。
*) 携带的数据长度:在三次握手中携带的数据长度都是0.
*) 分组ack:表示确认对方的组序号。
*) 窗口大小:是内核协议栈的缓冲处理窗口大小,在连接建立初期一般为默认的大小。
*) mss:最大的报文端长度。表明发端将不接受超过这个长度的tcp报文段。当一个连接建立时,都要互相知会对方各自的MSS,一种默认MSS值为1024,是由于许多版本需要为512的倍数,另一些系统上为1460,是用MTU 1500减去IP数据报头部长度包括IP的20个字节和TCP的20个字节。另一些使用IEEE802.3封装的为1452。
问题:端口在三次握手确认么?
端口是TCP头部的第一个信息,当然需要在TCP建立就明确。
TCP的4次分手:
TCP被定义为一个全双工的连接,就是在两个方向上能同时收发数据,因此每个方向必须能够单独的进行关闭,也叫做TCP的半关闭。简单总结的话半关闭就是双方都有关闭的控制权,一方执行关闭后,不能影响另一方的数据发送,因为另一方还没有确认要关闭此链接。
我们知道FIN的发送是应用程序主动调用的(可能是你的close系统调用),而FIN的ack是由协议栈自动产生的。
当一方主动close发送FIN后,对方协议栈会发送一个FIN的ack表示这一方向的连接关闭处理完成。正常情况下,对方接受到FIN后也会主动close,待对方的FIN ack接收到后,至此双方所控制的“全双工”的连接全部关闭结束。
另一方面说一下TCP的状态图:TCP的状态图就是协议栈处理TCP协议时流程中的一个时间点。
我经常搞不清楚TCP的分手的多种状态,其实,tcp分手时的状态可参考上面的半关闭流程,从协议栈角度理解一下:
1)应用程序主动FIN时候的两个状态是:FIN_WAIT_1,FIN_W AIT_2,TIME_WAIT。
一方发送FIN后连接状态立刻为FIN_WAIT_1,而接收到对方FIN ack后状态立刻为FIN_WAIT_2,这时如果对方没有立刻close,反而继续使用此连接发送数据时,连接就会持续的在FIN_WAIT_2状态上,所以FIN_WAIT_2状态应该是比较常见的连接状态。FIN_WAIT_2状态后协议栈接收到对方的FIN后,就会转到TIME_WAIT状态,经过2MSL后最终为close状态。
2)被动接收FIN的状态为:CLOSE_WAIT,LAST_ACK
被动接受FIN后,协议栈立刻回应了FIN ACK,所以进入了CLOSE_WAIT状态,也就是等待应用进程也关闭掉自己的连接,当本方也发送了FIN后,进入了LAST_ACK状态,等待接收对方协议栈的回应,当收到对方协议栈回应后,连接为close状态了。
(二)TCP数据流
TCP交互数据流---Nagle算法
TCP交互数据流最明显的例子就是一些交互式输入,这些数据特点是一个分组的数据量小,只有几个字节,一个分组的数据字节数都小于IP头部的字节数。
Nagle算法:在广域网上,小分组会引起麻烦,Nagle算法要求一个TCP连接上最多只能有一个未被确认的未完成的小分组,在该分组的确认到达之前不能发送其他小分组。这样,在等待其他阻塞的小分组的时候,TCP就将这些小分组积攒起来,在确认到来时以一个分组分发出去。
而在局域网上,我们不太考虑分组阻塞问题,但是更重视时延问题,所以一般Nagle算法是被禁止的。
TCP成块数据流---滑动窗口
TCP使用滑动窗口协议来加速成块数据的发送。该协议允许发送方在停止或等待确认前可以连续发哦那个多个分组。由于发送方不必每发一个分组就停下来等待确认,因此该协议能够加速数据的传输。使用滑动窗口协议时,接收方不必确认每一个收到的分组,在TCP中,ack是累积的,一个ack可以确认之前的多个报文。
自己总结下,就是当使用滑动窗口处理成块数据流时,发送方可以不必等待每一个分组完成再发数据,而可以在上一个分组没有完成之前发送不大于对方窗口大小的数据量(这是由于TCP协议栈规定在对方窗口为0时,不要继续发送数据)。达到了发送方提前发送的效果。而接收方的协议栈也不惜处理每一个报文的ack,只要在适当的时候返回一个累加ack号的回应即可,这样减少了网络上ack报的流动。
碰到过一个工程问题,就是快的发送方和慢的接收方,在接受方cpu未达到上限时,出现了数据卡顿,接收不完全的现象。抓包看ack回应太多,滑动窗口机制没有生效。结果是发送方没有关闭Nagle算法导致,后来让发送方加上了TCP_NODELAY属性,关闭掉Nagle算法,让滑动窗口生效,从而解决了解码卡顿问题。
(三)TCP的超时与重传
TCP可靠性由TCP的超时重传机制保证,就是要确认从另一端收到的数据。TCP通过设置定时器检查一个分组在规定时间没有收到确认,就重传该数据。TCP协议栈中的一些坚持定时器,就是做这个工作的。
TCP可靠性还有保活机制,TCP的保活功能是当一个连接双方都没有互相的数据发送时,只要两端没有重启,连接依然保持。
TCP对于保活功能是由争议的,协议专家分析是否将保活功能完全放入应用层来实现。以目前了解的状况,TCP层会在每隔两小时发送一个检测分组,已确定对方是否存活。但是在实际的工程应用中,一般使用应用自定义的保活协议来处理完成。

