
MapReduce原理和WordCount数据详细过程
1.MapReduce原理
1.1 MapReduce简介
MapReduce是一种分布式计算模型,是Google提出的,主要用于搜索领域,解决海量数据的计算问题。
MR有两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算
1.2 MapReduce工作原理
MapReduce分为2个过程,分别为Map过程和Reduce过程,如下图所示:
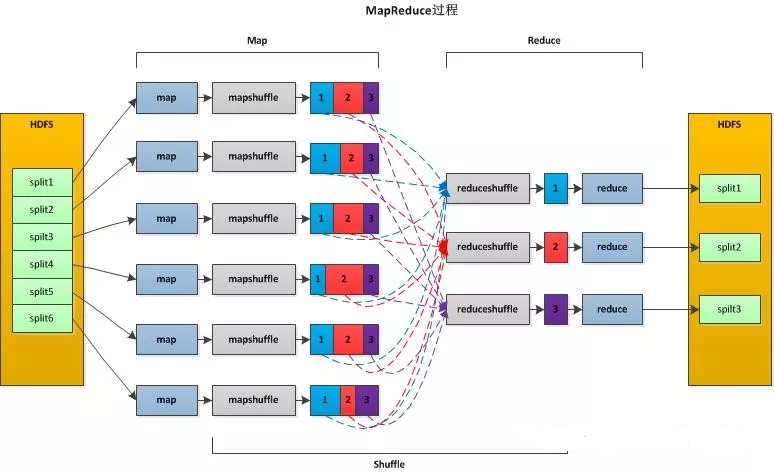
Map端
1)每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
2)在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combine操作,这样做的目的是让尽可能少的数据写入到磁盘。
3)当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combine操作,目的有两个:1.尽量减少每次写入磁盘的数据量;2.尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了。
4)将分区中的数据拷贝给相对应的reduce任务。分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳,所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置即可
Reduce端
1)Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),当数据量超过该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
2)随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作。排序是hadoop的灵魂。
3)合并的过程中会产生许多的中间文件(写入磁盘),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。
2.WordCount数据流程
在WordCount中,Map首先处理的数据经过分片获取输入,以键值对的形式,然后通过Map的切割,切割成一个个单词,然后把每个单词的计数标记为1,并且写到环形内存缓冲区中,排序、合并,写到分区中。
在Reduce段,每个Reduce把每个Map处理的数据中同一个patition的数据拷贝过来,并且经过排序、合并,数据格式类似<Hello,list(1,3,2)>,形成Reudce数据输入。最后才写道HDFS或其他渠道中。
其完整流程如下图:
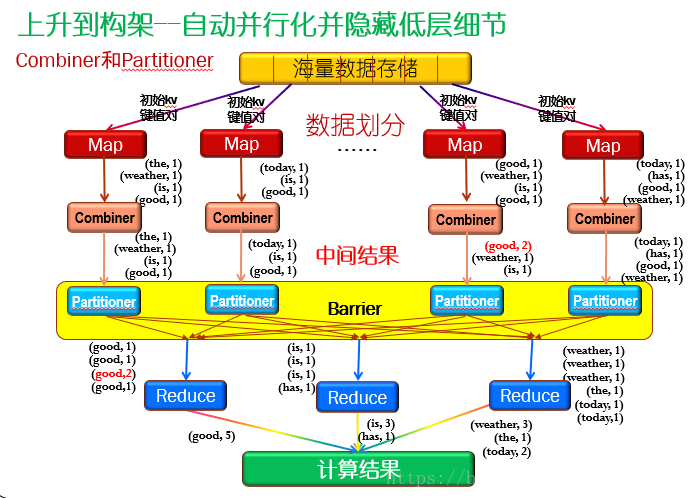
为了更加方便地描述,我自己画了一张图,来形容这个过程
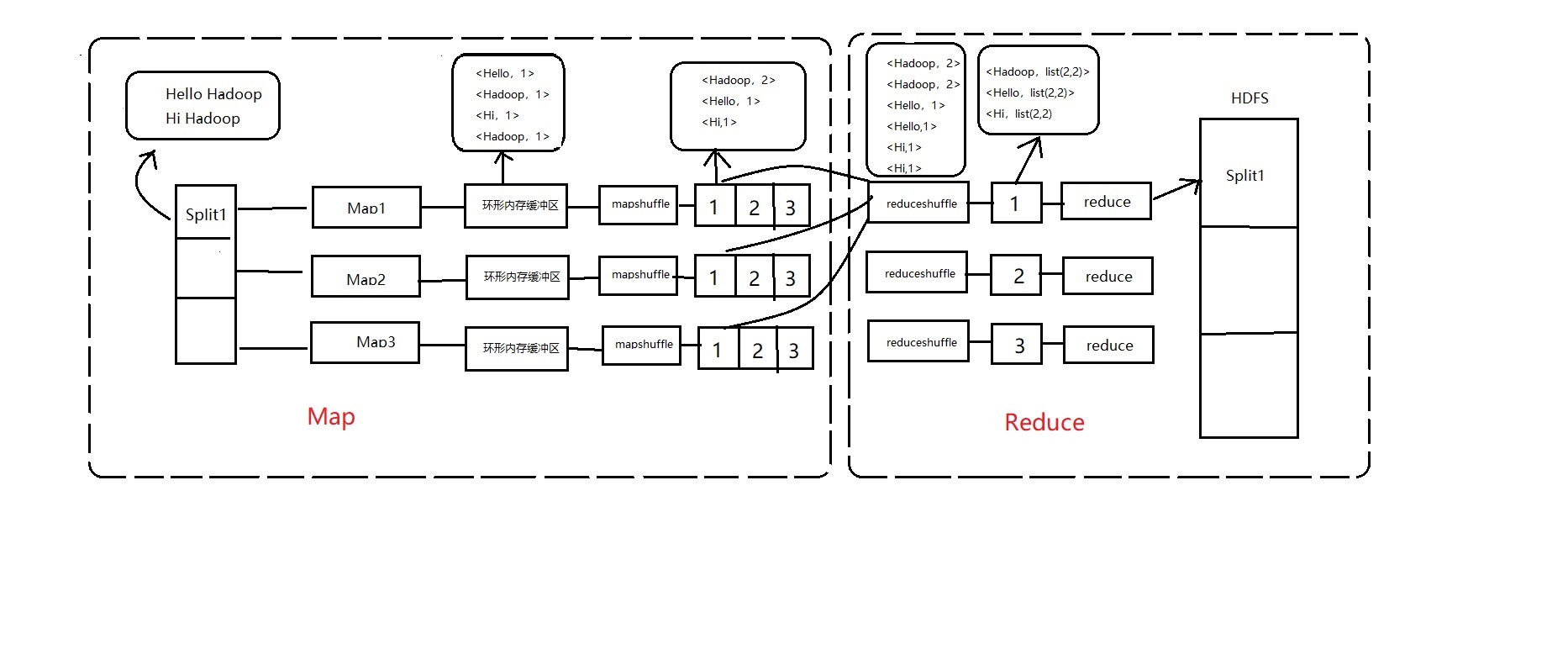
这是我对整个流程一些浅薄地见解,有什么不明白地欢迎留言
参考网站:
https://blog.csdn.net/fanxin_i/article/details/80388221
https://www.cnblogs.com/laowangc/p/8961946.html
https://www.cnblogs.com/riordon/p/4605022.html

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步