Chapter 5 Order Inversion Pattern
5.1 Introdution
The main focus of this chapter is to discuss the order inversion (OI) pattern, which can be used in solving some problems using MapReduce framework. The OI pattern enables us to control the order of values received at a reducer (some computations require ordered data).
这章主要讨论反转排序(OI)模式,可以用于某些使用MapReduce框架解决的问题。OI 模式允许我们控制送到reducer的值的顺序,某些计算需要数据是有序的。在Hadoop中,送到reducer的数据是没限定的(我怎么记得会按键排序来着),OI模式使用更简单的数据结构,占用更少的reducer内存(因为在reducer阶段没有额外的排序)。
看到这里我在想,反转排序的前提不就是有序吗,像是升序反转成降序,不然反转之后不也是无序的。那么,如果后续计算需要数据降序,直接降序送到reducer不就可以,为什么要使用OI模式。书上接下来倒是很贴心地举例来进一步理解OI模式,不过例子也是不明所以(看了几遍选择放弃),并没有回答我的疑问。还说实现关键是定义用户分割器(custom partitioner),用户分割器只关注复合键里的原始键,都是什么鬼。稍微看了一下接下来的内容,大概知道例子在干啥,可是仍然看不出来和“反序”有什么关系。于是去找了一些资料,发现并不是按字面理解的“反序”:
翻译完本文之后,我深深地感觉到,将Order Inversion翻译成反序模式是不恰当的,根据本文的内容,很显然,Inversion并非是将顺序倒排的意思,而是如同Spring的IOC一样,表明的是一种控制权的反转。Spring将对象的实例化责任从业务代码反转给了框架,而在本文的模式中,在mapreduce的sorting过程中,原来由框架负责的数据的排序以及shuffle规则被用户定制化了,控制权从框架反转到了user,实际上这种模式就是由用户控制sorting过程的意思。
----引用自MapReduce 算法 - 反序模式 (Order Inversion) 译者评论。
5.2 Example if Order Inversion Pattern
The simple example to demonstrate the OI pattern is to compute relative frequecies of words for a given set of documents. The goal is to build a N × N matrix (call this matrix M), where N = |V| (the vocabulary size all given documents) and each cell Mij contains the number of times word Wi co-occurs with word Wj within a specific context.
例子是计算N*N共现(co-occurs)矩阵的问题,N是所给输入的词汇数量,元素Mij表示单词Wi和Wj在给定上下文范围内(比如这个单词前后两个单词的范围)共同出现的总次数。不过,这个矩阵有一个缺陷,某个Mij的值很大,可能只是单词Mi或Mj在输入里出现的次数比较高,不能说明这两个单词有一定联系。所以,改进的共现矩阵不是计算绝对频数,而是相对频率,Mij表示的是单词Mj在Mi给定上下文范围内出现的概率。
5.3 MapReduce for Order Inversion Pattern
Following our example of computing relative frequencies for a given set of documents, we do need to generate two sequence of data: the first sequence will be total neighborhood counts (the total number of co-ocurrences of a word) for the word (let‘s denote this by composite Key =(W, ∗)— W denotes the word) and the second sequence will be the counts of that word against other specific words (let‘s denote this by composite Key = (W, W2)).
为了计算相对频率,我们需要两个序列,分别记为(w, *)和(w, wi)。举个例子来说,输入是“w1w2w3”,给定范围是前后两个单词,则对单词w1来说,序列是((w1, *), 2),((w1, w2), 1),((w1, w3), 1),表示w1的共现对数及共现的单词和次数,计算相对频率就很容易了。mapper需要输出上述的序列,为了使同一个单词的序列输到同一个reducer,还要自定义用户分割器,只关注复合键里面的w部分。照旧贴上代码如下。
5.3.1 Custom Partitioner
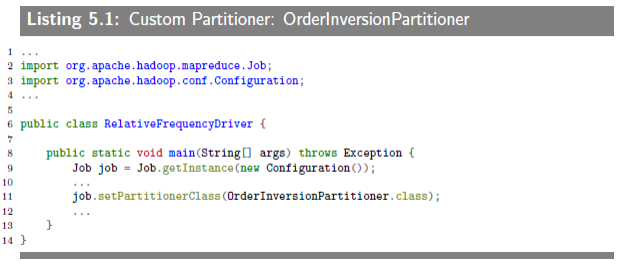
5.3.1.1 Custom Partitioner Implementation in Hadoop
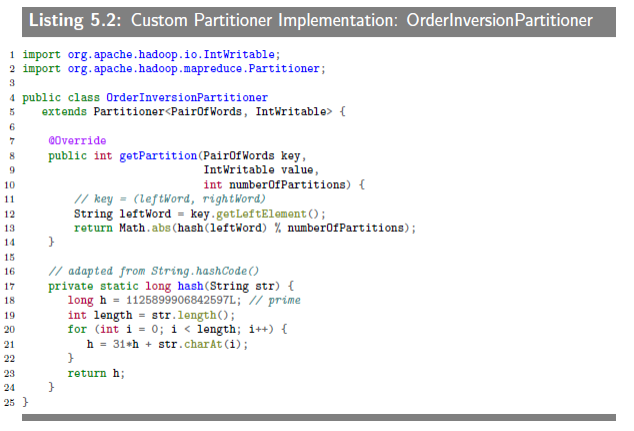
把同一个单词的序列送到同一个reducer。
5.3.2 Relative Frequency Mapper
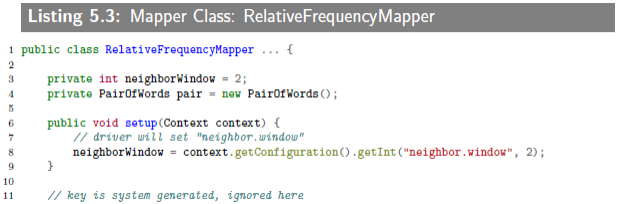
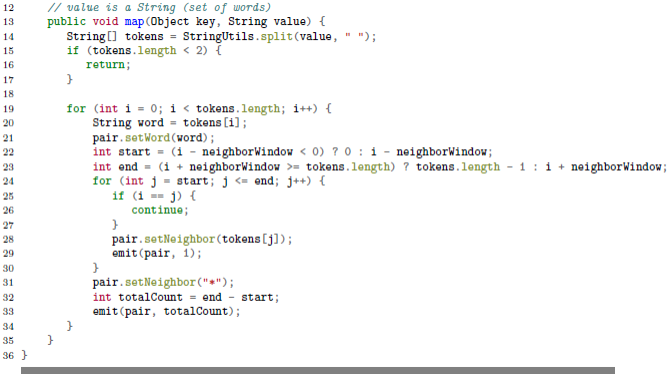
mapper要输出上述序列。
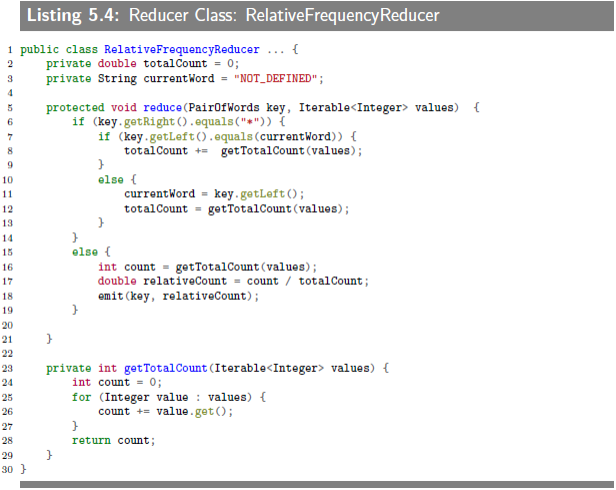
5.3.3 Relative Frequency Reducer
5.3.4 Implementation Classes in Hadoop
跳过“5.4 Sample Run”。
导师布置的看书任务总算是告一段落,最后再来总结一下。第五章内容不多,意外地花了很多时间,最后也是大概知道在说啥的程度。主要就讲了共现矩阵的例子,计算相对频数,具体实现代码不抠。主要是软工实践第二次作业刚发出来了,栋哥说开学第一周会让我们体会到2y2s,以为第二次还有一周(真是2y2s),那还没入门的Python又要先放一边,导师的实验也是,接下来主要争取去学校之前做完第二次作业。稍微看了下作业,感觉下学期软工实践会比想象中更花时间(毕竟渣渣),估计平常晚自习的时间都得给它,其它课程得争取白天没课的碎片时间和睡前的一段时间解决,还有刷书打代码大概得安排在两次作业间隙来做。一直说会见到凌晨三四点的福大,希望只是偶尔和队友们一起体验一下,其他时候合理安排时间也可以完成任务,因为就我个人来说,熬夜时的脑子并不好用。以上。

