聚集索引的叶子页存储的就是表的数据。因此,表行物理上按照聚集索引列排序,因为表数据只能有一种物理顺序,所以一个表只能有一个聚集索引。
当我们创建主键约束时,如果不存在聚集索引并且该索引没有被明确指定为非聚集索引,SQL Server会自动将其创建为唯一的聚集索引,这并不是说主键列就一定是聚集索引,这只是默认行为而已。
示例,建表时通过指定主键为非聚集索引使主键列不为聚集列:
CREATE TABLE MyTableKeyExample
{
Column1 int IDENTITY PRIMARY KEY NONCLUSTERED,
Column2 int
}
一、堆表与聚集表
没有聚集索引的表称为堆表。堆表的数据列没有任何特别的顺序,连接到表的相邻页面。与访问大的聚集表相比,对标这种无组织的结构通常增大了访问大的堆表的开销。
有聚集索引的表称为聚集表,聚集表是B树结构,数据量大时,能够大幅减少读次数。
二、与非聚集索引的关系
SQL Server中聚集索引和非聚集索引之间有一个有趣的关系,非聚集索引的一个索引列包含指向表的对应数据行的指针。这个指针被称为行定位器。行定位器的值取决于数据表是堆表还是聚集表。当时堆表时,行定位器是指向堆中数据行的RID指针。对于具有聚集索引的表,行定位器是聚集索引键值。
下面用一个表格来说明这种关系
假设有一个2列的表:
| RID(这不是实际列) | 列1 | 列2 |
| 1 | A1 | A2 |
| 2 | B1 | B2 |
堆表:
| 索引列(列1) | 行定位器 |
| A1 | RID = 1 指向表中第一行数据 |
| B1 | RID = 2 指向表中第二行数据 |
聚集表,假设我们将列2设为聚集索引列:
| 索引列(列1) | 行定位器 |
| A1 | A2 指向聚集键 |
| B1 | B2 指向聚集键 |
由此可见,通过非聚集索引列查找一行数据,还需要多一步-通过RID获得实际数据。这个RID在堆表是行指针,在聚集表是聚集键值。
三、聚集索引的建议
1、首先创建聚集索引
对于聚集表而言,因为所有非聚集索引在其索引行上都保存一个聚集索引键值,所以非聚集索引和聚集索引创建的顺序非常重要。如果非聚集索引先于聚集索引创建,那么非聚集索引的行定位器将包含指向堆表的RID的指针。然后再创建聚集索引时,会将所有非聚集索引的RID指针改为聚集键,这实际上相当于重新建立了非聚集索引。
为了最好的性能,最好在创建任何非聚集索引之前创建聚集索引。这将使得非聚集索引在创建的时候将他们的行定位器直接设置为聚集索引值。这对最终的性能没有太大影响,但是SQL Server工作量少很多,速度快很多。如果你是在线上运行着的系统进行维护操作,这尤其有用。
2、保持窄索引
因为所有的非聚集索引将聚集索引键作为行定位器,为了最佳的性能,应使聚集索引的总体长度尽可能小。
试想,假如创建了个宽的聚集索引,如CHAR(500),这将在每个非聚集索引中添加一个500字节的值。就算非聚集索引什么都不放,光聚集索引键值占用的空间,它一页的数据页仅仅能存放16个数据行左右。
保持窄聚集索引能有效减少逻辑读操作与磁盘I/O。
3、一步重建聚集索引
因为聚集索引上有非聚集索引的依赖性,用单独的DROP INDEX 和 CREATE INDEX语句重建聚集索引将导致所有非聚集索引被重建两次(DROP,行定位器指向堆表数据行指针,CREATE行定位器指向新的聚集键值)。为了避免这种情况,使用CREATE INDEX语句的DROP_EXISTING子句来在一个单独的原子步骤中重建聚集索引。相似地,也可以在非聚集索引上使用DROP_EXISTING子句。
CREATE CLUSTERED INDEX index1 ON PersonTenThousand(Id) WITH (DROP_EXISTING = ON)
4、何时使用聚集索引
在某些情况下,使用聚集索引是非常有帮助的。
1、检索一定范围的数据
因为聚集索引的叶子页面就是表的实际数据,聚集索引列的顺序就是表中数据行的物理顺序。如果数据行的物理顺序与查询请求的数据顺序相同,磁盘刺头可以顺序地读取所有行,而不需要太多的磁头移动。
假设我聚集索引建立在ID列,我需要读取ID BETWEEN 1 AND 100或ID > 100的数据,那么所有数据行在磁盘上排列在一起。这使磁头可以移动到磁盘上第一行的位置,然后用最少的磁头移动顺序读出所有数据。另一方面,如果行在磁盘上没有以正确的物理顺序排列,磁头必须随机地从一个位置移动到另一个位置来读取所有相关的行。磁头的物理移动是磁盘操作开销的最主要部分,将行以合适的物理顺序在磁盘上排序(使用聚集索引)优化了I/O开销。
2、读取预先排序的数据
聚集索引在数据读取需要排序时特别有效,如果在可能需要排序的一列或多列上创建一个聚集索引,那么行将被按该顺序物理排序,这消除了数据读取之后排序的开销。
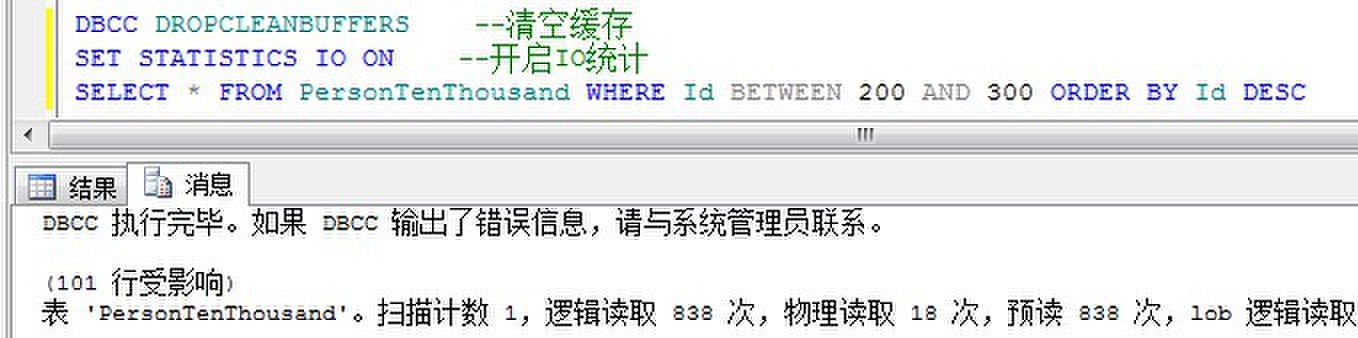
在没有聚集索引的情况下,检索范围排序的数据:
在有聚集索引的情况下,检索范围排序的数据:
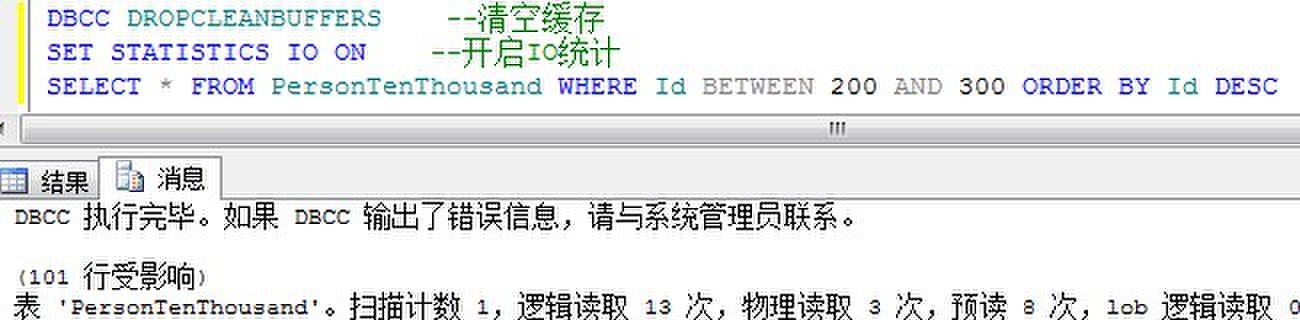
从中看到,有聚集索引的范围排序返回数据非常快速,因为对于聚集列,本身就是已经排好顺序存放于数据库中的。
5、何时不使用聚集索引
在某些情况下,最好不使用聚集索引。
1、频繁更新的列
如果聚集索引列频繁更新,将导致所有非聚集索引行的行定位器相应更新,从而显著地增加相关操作查询的开销。还将阻塞这段时间引用相同部分和非聚集索引的其他查询,从而影响数据库的并行性。因此,应该避免在大量更新的列上创建聚集索引。
2、宽的关键字
因为所有非聚集索引将聚集键作为其行定位器,所以为了性能,应该避免在非常宽或太多列上创建聚集索引。上面红色加粗字体特别说明了原因。
3、太多并行的顺序插入
如果希望并发地添加许多新行,那么对于性能来讲,将他们分布到表的各个数据页面更好一些。但是,如果将所有行按照与聚集索引相同的顺序添加,那么所有的插入操作都在表的最后一个页面上进行。这可能在磁盘的对应山区造成一个巨大的“热点”,为了避免磁盘热点,不应该将数据行按照物理位置相同的顺序排列。可以通过创建另一列上的索引(该索引不会将行按照新航相同的顺序来排列)来插入操作随机地分布到整个表。这个问题只在大量同时插入时发生。
允许在表的尾部插入,能够避免需要容纳新行时发生的页拆分。如果并行插入数据降低,那么按照新行的顺序来排列数据行(使用聚集索引)将避免页拆分。但是,如果磁盘热点成为性能瓶颈,那么新行可以通过降低表的填充因子来容纳到中间页面。另外,“热”的页面将在内存中,这也有利于性能。
最后附上一个设置非主键为聚集索引列的方法:
1. 查看所有的索引,默认情况下主键上都会建立聚集索引
查看索引:
sp_helpindex person
查看约束:
sp_helpconstraint person
2. --删除主键约束,把【1】中查询出的主键上的索引约束【如:PK__person__117F9D94】去除掉。去掉主键字段上面的主键约束,此时该字段不是主键了。
alter table person drop constraint PK_Person
3.--创建聚集索引到其它列
create clustered index test_index on person(Name)
4.—修改原来的主键字段还是为主键,此时会自动建立非聚集索引【因为已经有了聚集索引】
sp_helpindex person sp_helpconstraint person alter table person drop constraint PK_Person create clustered index test_index on person(Name) alter table person add primary key (id)
alter table person add primary key (id)