

动手学Avalonia:基于硅基流动构建一个文生图应用(一)
文生图
文生图,全称“文字生成图像”(Text-to-Image),是一种AI技术,能够根据给定的文本描述生成相应的图像。这种技术利用深度学习模型,如生成对抗网络(GANs)或变换器(Transformers),来理解和解析文本中的语义信息,并将其转化为视觉表现。文生图可以用于创意设计、图像编辑、虚拟现实、游戏开发等多个领域,为用户提供了从文字到图像的创造性转换工具。例如,用户可以输入“一只蓝色的猫坐在月球上”,AI将尝试生成符合描述的图像。

Stable Diffusion
Stable Diffusion 是一种潜在的文本到图像扩散模型。得益于 Stability AI 慷慨的计算资源捐赠以及 LAION 的支持,我们得以使用 LAION-5B 数据库的一个子集中的 512x512 图像来训练一个潜在扩散模型。与 Google 的 Imagen 类似,此模型使用一个冻结的 CLIP ViT-L/14 文本编码器来根据文本提示对模型进行条件设定。该模型拥有 8.6 亿参数的 UNet 和 1.23 亿参数的文本编码器,相对轻量,只需要至少 10GB VRAM 的 GPU 即可运行。详情请参阅以下部分和模型卡片。
简而言之,Stable Diffusion 是一个由 Stability AI 和 LAION 支持的项目,使用 LAION-5B 数据库中的图像训练而成。它借鉴了 Google Imagen 的设计理念,使用 CLIP ViT-L/14 文本编码器处理文本提示,具有相对较小的模型大小,使得它在普通 GPU 上即可运行。
Stable Diffusion 3 Medium 是目前 Stable Diffusion 3 系列中最新、最先进的文本到图像 AI 模型,包含 20 亿个参数。它擅长照片级真实感,处理复杂的提示并生成清晰的文本。
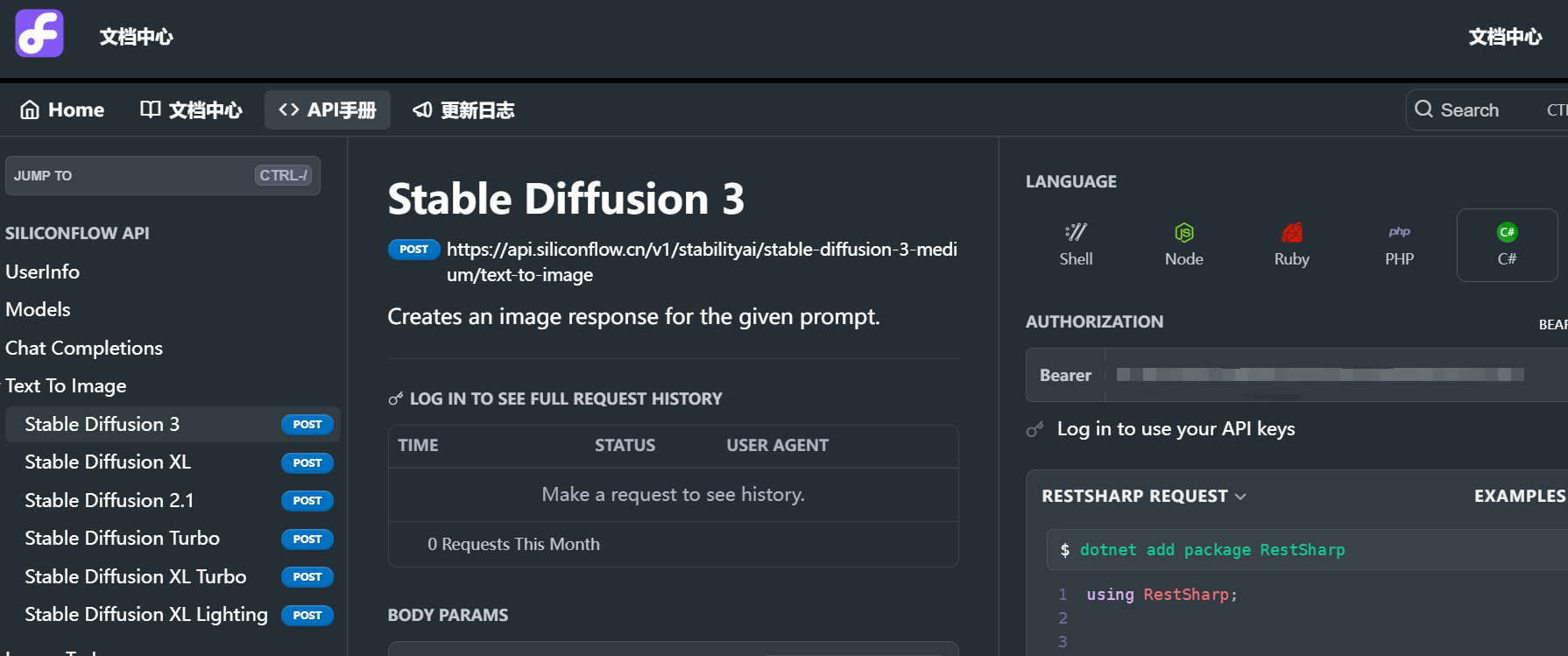
stable-diffusion-3-medium模型开源地址:https://huggingface.co/stabilityai/stable-diffusion-3-medium
硅基流动
由于我目前硬件资源不行无法本地运行stable-diffusion-3-medium,但又想试试文生图模型,因此现阶段可以采用调用api的方式来使用。硅基流动平台目前提供了stable-diffusion-3的调用接口,并且限时免费,因为选择调用硅基流动提供的api。
Avalonia
基于Avalonia可以使用C#+Xaml构建跨平台应用。
本项目或许不具备太大的实用价值,权且当做学习Avalonia的一个练手项目。
项目架构:
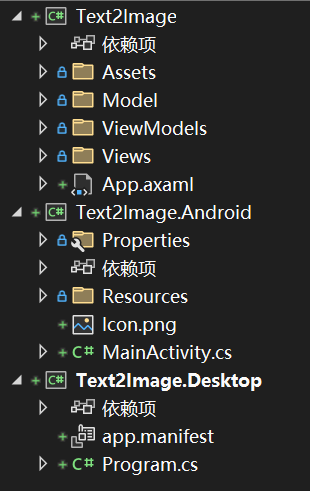
在使用Avalonia的模板创建项目之后,更改项目为.net8,并升级一下包,这样可能会避免一些报错。
由于发现不支持中文提示词,因此还是使用SemanticKerenl基于LLM将中文提示词翻译为英文提示词,然后根据英文提示词绘图。
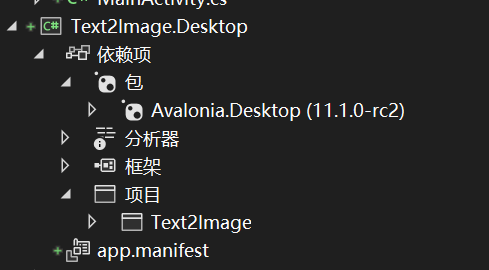
观察一下桌面端的依赖项,桌面端引用了核心项目,使用的包是Avalonia.Desktop。
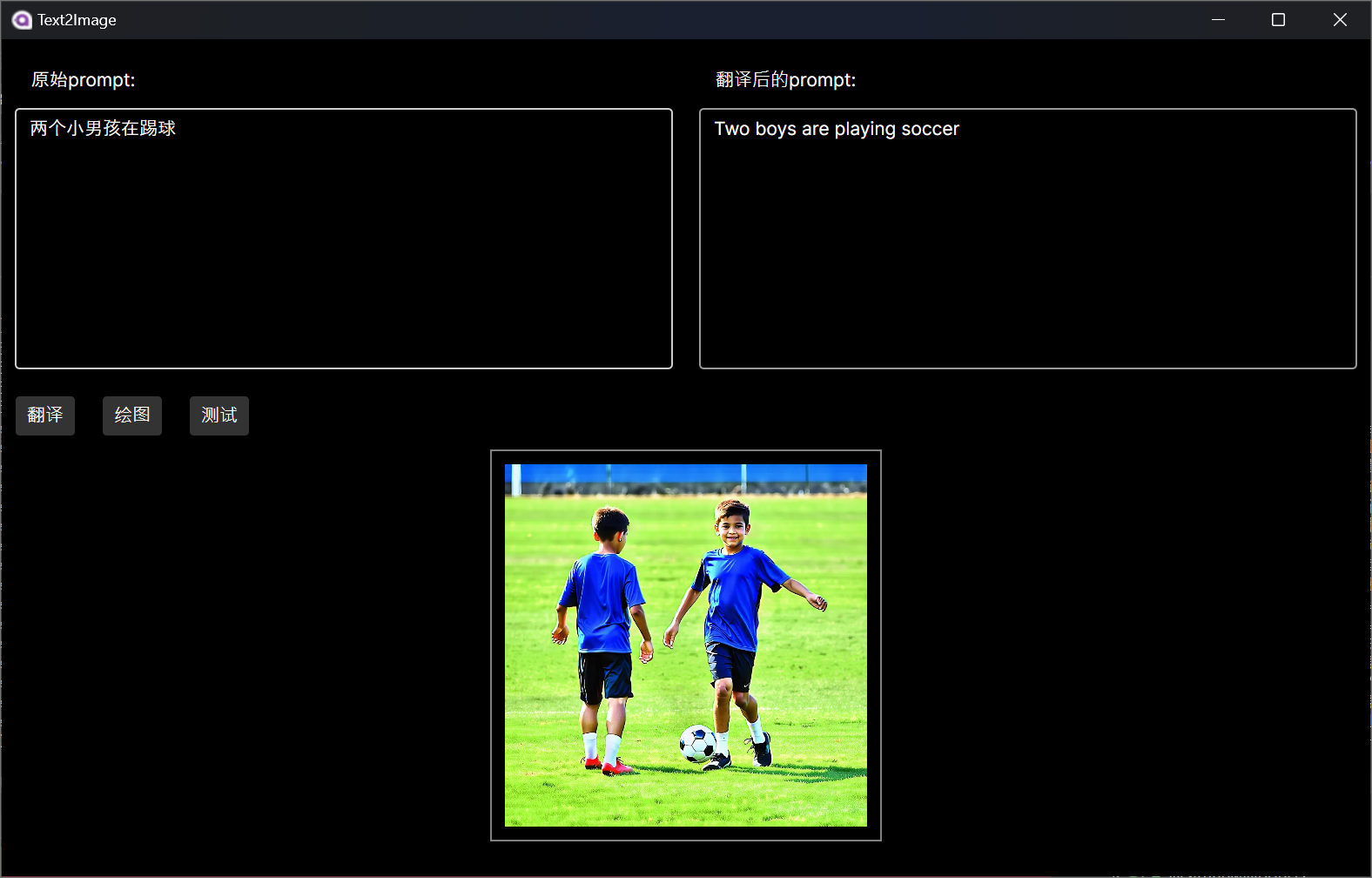
桌面端实现效果如下所示:
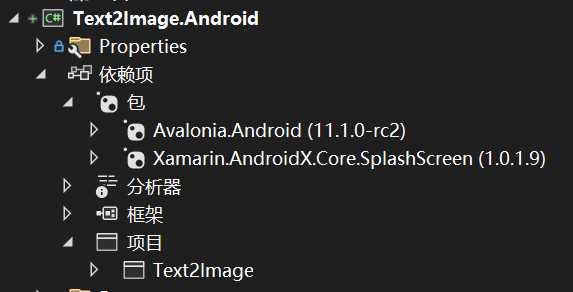
观察一下Android端的依赖项,Android端也引用了核心项目,使用的包是Avalonnia.Android与Xamarin.AndroidX.Core.SplashScreen。
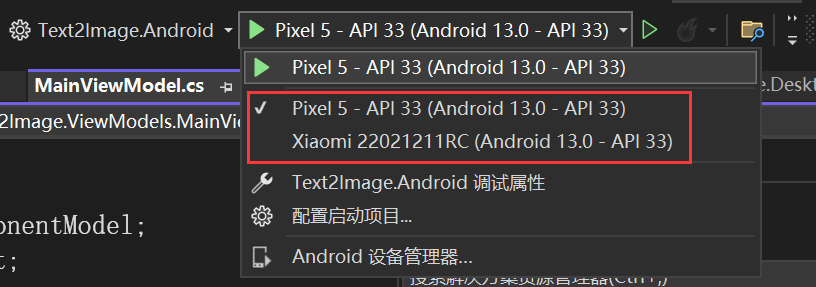
Android端调试可以选择模拟器与物理机。
避坑
选择物理机调试时要打开开发者模式,打开USB调试,最重要的是要允许通过USB安装,我之前没有设置这个,就会遇到一个被用户取消的错误提示。
Android端不知道为什么SenmanticKernel对提示模板不起作用如下所示:

现在只能自己写英文提示词绘图。
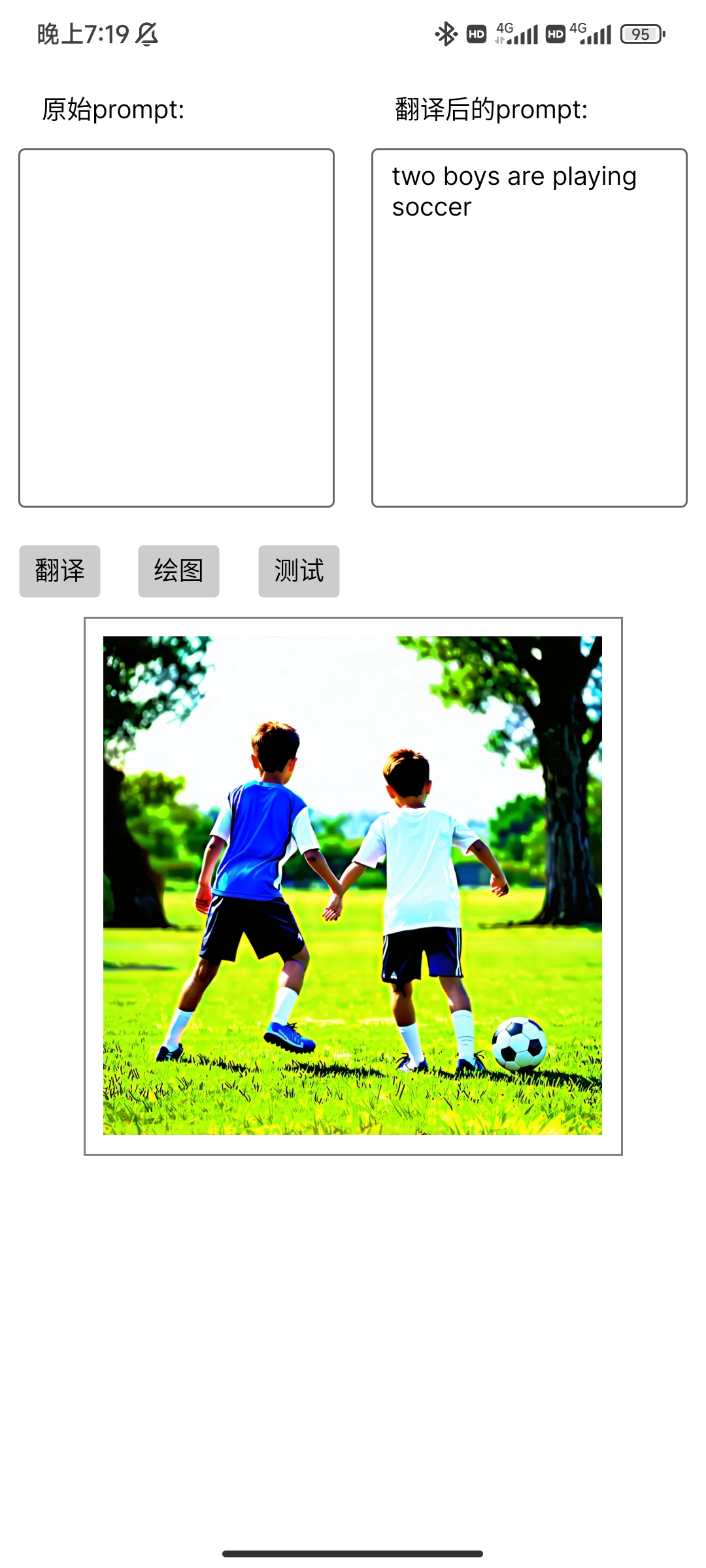
Android端的实现效果如下:
以上就是动手学Avalonia:基于硅基流动构建一个文生图应用(一)的内容,希望对使用C#构建跨平台应用感兴趣的小伙伴有所帮助。
