hashtable-structure
哈希表(Hash Table,也叫散列表),是存储键值对(key-value)的数据结构,主要利用hash算法将key映射到表中,以便加快查找速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。对于数组而言,查找数据容易,但添加删除数据比较慢;对于链表来说,添加删除数据容易,但查找数据比较慢,所以哈希表结合数据和链表来实现数据快速的存取。
哈希表的实现主要需要解决两个问题,哈希函数和冲突解决。
哈希函数
在哈希表内部,使用桶(bucket)来保存键值对,数组索引即为桶号,哈希函数决定了给定的键存于散列表的哪个桶中,例如下面的函数:
index = f(key, array_size)
其中需要先通过key计算hash值,然后再利用算法计算出index,在维基百科中,有如下介绍:
hash = hashfunc(key)
index = hash % array_size
哈希函数和计算index的算法可以有很多种实现,但最终目的是能够均匀并独立地将所有的键散布在数组范围内。
冲突解决
即使采用的哈希算法能够使键值均匀分布,但避免不了“碰撞”的出现,当两个不同的键值产生了相同值,这时就需要解决冲突。
解决冲突有很多种方法,比如拉链法和开地址法,这里主要分析拉链法的具体实现。
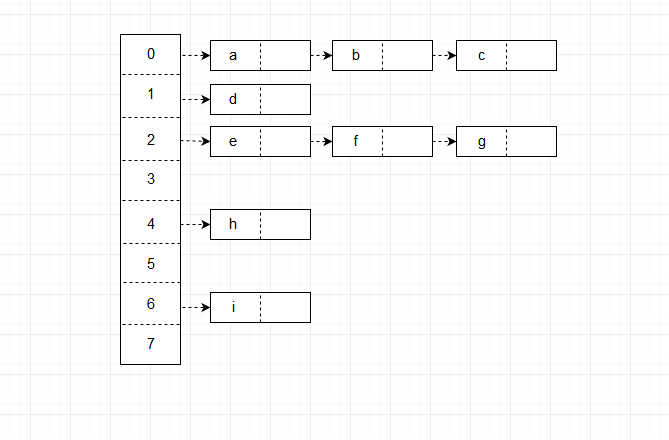
采用拉链法的哈希表,每个桶里都存放了一个链表。初始时所有链表均为空,当一个键被散列到一个桶时,这个键就成为相应桶中链表的首结点,之后若再有一个键被散列到这个桶(即发生碰撞),第二个键就会成为链表的第二个结点,以此类推。采用拉链法解决冲突的哈希表如下图所示:
具体实现
对于哈希表而言,主要有增,删,获取操作,我们先来定义一个接口:
public interface Map<K,V> {
public V put(K k,V v);
public V get(K k);
public V remove(K k);
interface Entry<K,V>{
public K getKey();
public V getValue();
}
}
在Map接口中,定义了三个方法put,get,remove三个方法,同时定义了一个内部接口Entry,用来表示key-value结构。
接下来我们就采用拉链法来实现上面的接口。首先定义一下常量,成员变量以及在类的构造函数初始化一些数据代码如下:
// 默认大小
static final int DEFAULT_INITIAL_CAPACITY = 16;
// 默认负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 定义数组大小
private int length;
// 扩容标准 所使用的数组数量/数组长度 > 0.75
private float loadFactor;
// 使用数组位置的总量
private int useSize;
// 定义Map 骨架 只要数组
private Entry<K, V>[] table = null;
public HashMapDemo() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
@SuppressWarnings("unchecked")
public HashMapDemo(int length, float loadFactor) {
if (length < 0) {
throw new IllegalArgumentException("参数不能为负数" + length);
}
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new IllegalArgumentException("扩容标准必须为大于0的数字" + length);
}
this.length = length;
this.loadFactor = loadFactor;
this.table = (Entry<K, V>[])new Entry[length];
}
接下来下类的内存实现静态内存类Entry,由于采用了拉链法,所以需要用链表来存储具有相同的index的节点。代码如下:
static class Entry<K, V> implements Map.Entry<K, V> {
K k;
V v;
Entry<K, V> next;
public Entry(K k,V v,Entry<K, V> next){
this.k = k;
this.v = v;
this.next = next;
}
public K getKey() {
return k;
}
public V getValue() {
return v;
}
}
hash算法
那么如何实现hash算法呢?这个问题有点复杂,还是先看看jdk8中HashMap是如何实现的,下面是部分代码:
/**
* 用来通过自身数组的长度和key来确定存储位置
* @param k
* @param length
* @return
*/
private int getIndex(K k, int length) {
// hashCode 与运算
int m = length - 1;
int index = hash(k.hashCode()) & m;
// 三元运算符处理
return index >= 0 ? index : -index;
}
/**
* jdk1.8中hashmap的hash算法
* @param hashCode
* @return
*/
private int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
从代码中可以看出,要获取索引位置需要以下步骤:
取 key 的 hashCode 值、高位运算、取模运算。
其中,key.hashCode()是Key自带的hashCode()方法,返回一个int类型的散列值。我们知道,32位带符号的int表值范围从-2147483648到2147483648。这样只要hash函数松散的话,一般是很难发生碰撞的,因为HashMap的初始容量只有16。但是这样的散列值我们是不能直接拿来用的。用之前需要对数组的长度取模运算。得到余数才是索引值。具体参看浅谈HashMap中的hash算法
快存
将key-value数据存入到哈希表表中,首先需要判断是否需要扩容,这里需要利用负载因子(loadFactor)来判断,默认扩容两倍。然后利用哈希算法来获取索引位置index,判断当前位置是否有结点,如果没有结点,就将当前结点作为这个桶中链表的头结点;如果有节点,那么就将其放在链表的末尾。代码如下:
/**
* 快存
*/
@Override
public V put(K k, V v) {
if (useSize > this.length * this.loadFactor) {
// 需要扩容
up2Size();
}
// 通过key来存储位置
int index = getIndex(k, table.length);
Entry<K,V> entry = table[index];
if (entry == null) {
table[index] = new Entry<K, V>(k, v, null);
} else if (entry != null) {
table[index] = new Entry<K, V>(k, v, entry);
}
useSize++;
return table[index].getValue();
}
扩容代码如下:
/**
* 增大容量,这里扩容两倍
*/
@SuppressWarnings("unchecked")
private void up2Size() {
Entry<K, V>[] newTable = (Entry<K,V>[])new Entry[2 * this.length];
// 原来数组有非常多的Entry对象,由于Entry对象散列,需要再次散列
againHash(newTable);
}
/**
* 存储的对象存储到新数组中(再次散列)
* @param newTable
*/
private void againHash(Entry<K, V>[] newTable) {
// 将数组里面的对象封装到List
List<Entry<K, V>> entryList = new ArrayList<Entry<K, V>>();
for (int i = 0; i < table.length; i++) {
if (table[i] == null) {
continue;
}
foundEntryByNext(table[i], entryList);
}
if (entryList.size() > 0) {
useSize = 0;
this.length = 2 * this.length;
table = newTable;
for (Entry<K, V> entry : entryList) {
if (entry.next != null) {
//形成链表关系取消掉
entry.next = null;
}
put(entry.getKey(), entry.getValue());
}
}
}
/**
* 寻找entry对象
* @param entry
* @param entryList
*/
private void foundEntryByNext(Entry<K, V> entry, List<Entry<K, V>> entryList) {
if (entry != null && entry.next != null) {
// 说明entry对象已经形成链表结构
entryList.add(entry);
// 需要递归
foundEntryByNext(entry.next, entryList);
} else {
entryList.add(entry);
}
}
快取
从哈希表中根据key来取出元素比较简单,利用哈希算法计算出索引位置index,然后遍历链表即可。
/**
* 快取
*/
@Override
public V get(K k) {
int index = getIndex(k, table.length);
if (table[index] == null) {
throw new NullPointerException();
}
return findValueByEntryKey(k, table[index]);
}
private V findValueByEntryKey(K k, Entry<K, V> entry) {
Entry<K, V> e = entry;
while (e != null) {
if (k == e.getKey() || k.equals(e.getKey()))
return e.getValue();
e = e.next;
}
return null;
}
移除
根据key将元素从哈希表中移除需要考虑以下几种情况:
- 该节点为链表头结点
- 该节点为链表中间节点
- 该节点为链表尾节点
然后按照上面的情况分别处理即可。
/**
* 移除
* @param k
*/
@Override
public V remove(K k) {
int index = getIndex(k, table.length);
Entry<K, V> e = table[index];
Entry<K, V> prev = null;
while (e != null && (!(k == e.getKey() ||
(k != null && k.equals(e.getKey()))))) {
prev = e;
e = e.next;
}
if (e == null) {
return null;
}
Entry<K, V> next = e.next;
if (prev != null && next != null) {
prev.next = next;
} else if (prev != null && next == null) {
prev.next = null;
} else if (prev == null && next != null) {
// Node is the head
table[index] = next;
} else {
// prev==null && next==null
table[index] = null;
}
useSize--;
return e.v;
}
参考
Hash table维基百科
散列表的基本原理与实现
浅谈HashMap中的hash算法
title: Hashtable结构分析
tags: [数据结构, 哈希表]
author: Mingshan
categories: [数据结构, 哈希表]
date: 2018-7-16
本文来自博客园,作者:mingshan,转载请注明原文链接:https://www.cnblogs.com/mingshan/p/17793539.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号