JAVA基础知识
最近逐渐向JAVA方向转了 ,有时间学习一下JAVA的基础知识,记录下一些笔记,以便以后参考查询,以后有时间会经常更新一些
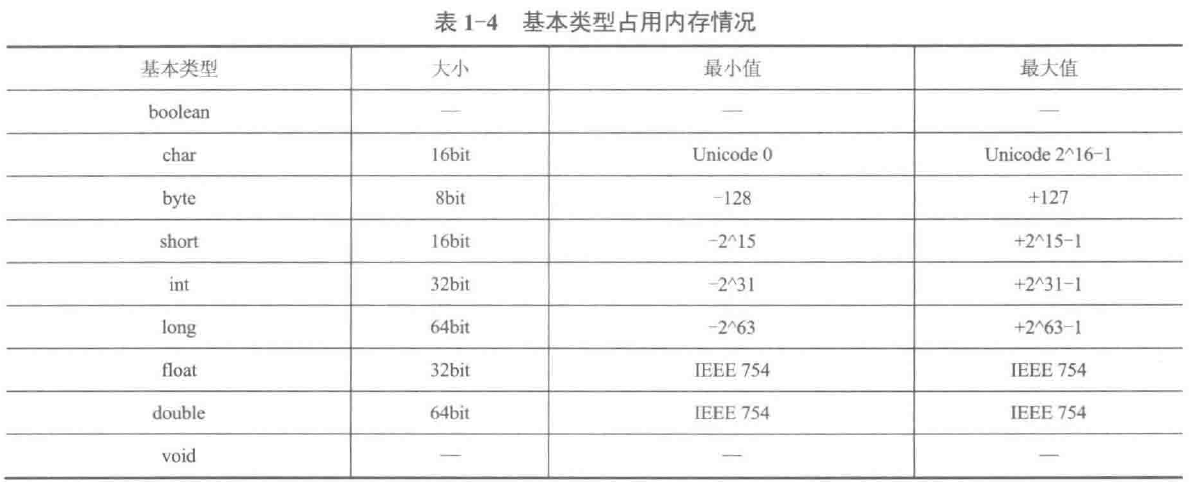
1、java中,基本的数据类型:浮点型float、字符型char ,布尔类型boolen,数值类型 byte、short、int、long

2、二进制转换成十进制 11101------29
采用Unicode编码,一个Unicode用16位(2个字节)来表示
3、int 和Integer的区别
1)int是java语言提供的八种基本的原始数据类型之一,当作为对象的属性是,他的默认值是0,
而Integer是java 为int提供的封装类,默认值为null,由此可见,int无法区分未赋值与赋值为0 的情况,而Integer确可以区分这两种情况
2)int是基本数据类型,在使用的时候是值传递;而Integer是引用传递
3)int只能用来运算,而Integer可以做更对的事情,因为Integer提供了很多有用的方法,
4)当需要往容器(例如list)里存放整数时,无法直接存放int,因为List里面存放的都是对象,所以在这种情况下只能用Integer。
4、流
在java语言中,输入和输出都被称作抽象的流,流可以看做是一组有序的字节集合,即数据在两个设备之间的传输
流的本质是数据传输,根据处理数据的类型不同,流可以分为两大类:字节流和字符流。其中前者以字节为单位(8bit),包含两个抽象类:InputStream(输入流)和OutputStream(输出流)。字符流以字符(16bit)为单位,根据码表映射字符,一次可以读多个字节,包含两个抽象类:Reader(输入流)和Writer(输出流)。其中字节流和字符流的主要区别为:字节流在处理输入输出的时候不会用到缓存,而字符流用到了缓存。
InputStream和Reader都可以用来读取数据(从文件中读取数据或从Socket中读取数据),最主要的区别如下:InputStream 用来读取二进制数(字节流),而Reader用来读取文本数据,即Unicode字符,那么二进制数与文本数据有什么区别呢?从本质上来讲所有读取的内容都是字节,想要把字节转换为文本需要制定一个编码方法,而Reader就可以把字节流进行编码从而转换为文本。当然,这个转换过程就涉及编码方式。他采用系统默认的编码方式对字节流进行编码,也可以显式的制定一个编码方式,例如“UTF-8”。尽管这个概念非常简单,但是java程序员经常会犯一些编码的错误,最常见的错误就是不指定编码方式。在读取文件或者从Socked读取数据的时候,如果没有指定正确的编码方式,读取的数据就可能会有乱码
FileInputStream和FileReader有着类似的区别,他们都是从文件中读取数据,前者读取二进制数据,后者读取字符数据
5、序列化
在分布式环境下,当进行远程通信时,无论是何种类型的数据,都会以二进制序列的形式在网络上传送。序列化是一种将对象转换为字节序列的过程。用于解决在对对象六进行读写操作时引发的问题。序列化可以将对象的状态写在流里进行网络传输,或者保存到文件。数据库等系统里,并在需要的时候把该流读取出来重新构造一个相同的对象。所有要实现序列化的类都必须实现Serializable接口,Serializable接口位于java.lang包中,它里面没有包含任何方法,使用该对象的writeObject(Object obj) 方法就可以将obj对象写出(即保存其状态),要恢复的时候就可以使用对应的输入流,具体而言,序列化的主要特点有:
1)如果一个类能被序列化,那么他的子类也能够被序列化
2)由于static(静态)代表类的成员,transient(java关键字,如果用transient声明一个实例变量,当变量存储式,他的值不需要维持)代表的是临时数据,因此,被声明为这种类型的数据成员是不够被实例化的
3)子类实现了Serializable接口,父类没有,父类中的属性不能被实例化,但是自列中的属性仍然能够被实例化。
6、网络通讯
在JAVA语言中,Socket的链接和建立的原理是什么?
https://www.jianshu.com/p/066d99da7cbd
网络上的两个程序通过一个双向的通讯链接实现数据的交换,这两个双向链路的一端成为一个Socket。Socket也称套接字,可以用来实现不同虚拟机或不同计算机之间的通信。在Java语言中,Socket分为两种类型:面向连接的Socket(TCP传输控制协议)通信协议和面向无连接的Socket(UDP用户数据报协议)通信协议,任何一个Socket都是由IP地址和端口号唯一确定的
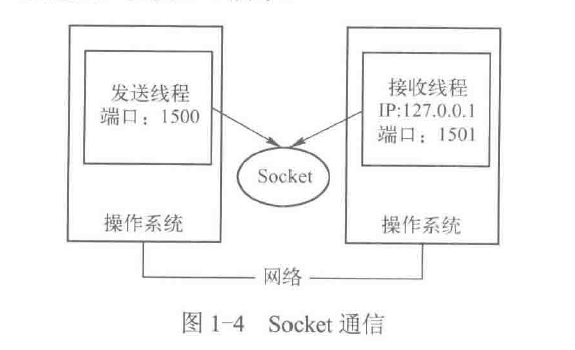
基于TCP协议的通信过程如下:首先,server端Listen(监听)指定的某个端口(建议使用大于1024的端口)是否有连接请求,然后Client端向server端发出Connect请求,紧接着,server端向Client端发回Accept(接受)消息一个连接就建立起来了,会话随即产生,server端和Client端都可以通过Send、Write等方法进行通信,
Stocket的声明周期可以分为三个阶段:打开Socket,使用Socket收发数据和关闭Socket,在java中可以使用ServerSocket作为服务端,Socket作为客户端来实现网络通信
7、描述Java类加载器的原理及其组织结构
Java语言是一种具有动态性的解释型语言,类只有被加载到JVM中够才能运行,当运行程序时,JVM会讲编译生成的.class文件按照需求和一定的规则加载到内存中,并组成一个完整的java应用程序。这个加载过程时由加载器来完成的,具体而言,就是有ClassLoader和他的子类来实现的,类的加载器本身也是一个类,其实质是把类的文件从硬盘读取到内存中。
类的加载方式分为隐式装载和显式装载两种,隐式装载指的是程序在使用new等方式创建对象的时候,会隐式的调用类的加载器把对应的类加载到JVM中,显式装载指的是通过直接调用class.forName()方法将所需要的类加载到JVM中
任何的一个工程项目都是由许多个类组成的,当程序启动时,只把需要的类加载到JVM中,其他的类只有在被使用的时候才会被加载,采用这种方法,一方面可以加快加载速度,另一方面可以节约程序运行过程中对内存的开销,此外,在Java语言中,每个类或者接口都对应一个.class文件,这些文件可以被看成是一个个可以被动态加载的单元,因此当只有不分类被修改的时候,只要重新编译变化的类即可,而不需要重新编译所有的文件,因此加快了编译速度
在java云烟中,类的加载是动态的,他并不会一次性的将所有的类全部加载后再运行,而是保证程序运行的基础类完全加载到jvm中,至于其他类,则在需要的时候才加载,在Java语言中可以把类分为三类 系统类、扩展类和自定义类。Java语言针对这三种不同的类提供了三种类型的加载器,这三种加载器的关系如下:
BootstrapLoader ---复制加载系统类(jre/lib/rt.jar的类)
--ExtClassLoader --负责加载扩展类(jre/lib/ext/*.jar的类)
AppClassLoader ---负责夹杂应用类(classpath指定的目录或jar中的类)
他们通过委托的方式实现,具体而言,就是当有类需要被加载时,类装载器会请求父类来完成这个载入工作,父类会使用其自己的搜索路径来索索需要被载入的类,如果搜索不到,才会有子类按照其搜索路径来搜索
类加载的主要步骤:
1)装载:根据查找路径找到对应的.class文件,然后导入
2)链接: ①检查:检查待加载的class文件的正确性
②准备: 给类中的静态变量分配存储空间
③解析: 将符号引用转换成直接引用(这一步是可选的)
3)解析:对静态变量和静态代码块执行初始化工作。
8、JVM工作原理
为了便于管理,JVM在执行Java程序的时候,会把他管理的内存划分为不同的区域,如下图所示
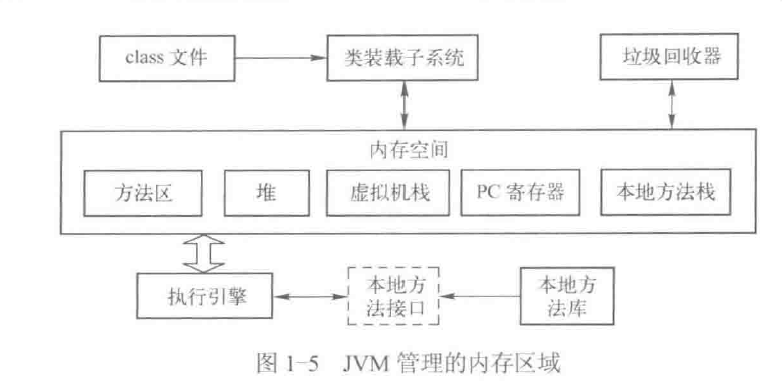
以下将分别对这些去进行介绍
1)class文件
class文件是java程序编译后生成的中间代码,这些代码将会被jvm解释执行
2)类装载器子系统 负责把class文件装载到内存中,供虚拟机执行
JVM有两种装载器,分别是启动类装载器和用户自定义装载器,其中,前者是JVM实现的一部分,后者则是JAVA程序的一部分,必须是ClassLoader类的子类,常见的类加载器主要有以下几种:
①BootstrapLoader 这是JVM的跟ClassLoader,他是用c++语言实现的 ,当JVM启动时,初始化此ClassLoader,并由此ClassLoader完成$JAVA_HOME中的jre/lib/rt.jar(Sun JDK的实现)中的所有class文件的加载,这个jar中包含了JAVA规范定义的所有的接口及实现
②Extension ClassLoader JVM用此ClassLoader来加载扩展功能的jar包
③System ClassLoader。JVM用此ClassLoader来加载启动参数中指定的Classpath中的jar包以及目录,在Sun JDK 中,ClassLoader对应的类名是APPClassLoader
④ User-Define ClassLoader。是Java开发人员继承ClassLoader抽象类自行实现的ClassLoader。基于自定义的ClassLoader可用于加载非Classpath中的jar以及目录
3)方法区
方法区用来存储被虚拟机加载的类信息、常量、静态变量和编译器编译后的代码等数据,在类加载器加载class 文件时,这些信息会被提取出来,并存储到方法中。由于这个区域是所有县城共享的区域,因此他被设计成为新城安全的。
方法区中还存放了运行时的常量池,最典型的应用就是字符串常量 例如定义了如下语句:String s="Hello";String s1=“Hello”;,其中。“Hello”是字符串常量,存储在常量池中。两个字符串引用s1和s都指向常量池中的“Hello”
4)堆
堆是虚拟机启动时候创建的被所有县城共享的区域,这块区域主要用来存放对象的实例,通过new操作创建出来的对象实例都存储在堆空间中,因此,堆就成为垃圾回收管理器管理的重点区域
5)虚拟机栈
栈是线程私有的区域,每当有新的线程创建时,就会给他分配一个栈控件,当线程结束后栈控件被回收,因此栈与线程拥有相同的生命周期,栈主要用来实现java语言中的方法的调用与执行,每个方法在被执行的时候,就会创建一个栈帧用来存储这个方法的局部变量、操作栈、动态链接和方法出口等信息,当进行方法调用时,通过压栈与弹栈等操作进行栈控件的分配与释放。当一个方法被调用的时候,就会压入一个新的栈帧到这个线程的栈中,当方法调用结束后,就会弹出这个栈帧,从而回收调用这个方法使用的栈空间
6)程序计数器
程序计数器也是线程私有的资源,JVM会给每个线程创建单独的程序计数器,他可以被看做是当前线程执行的字节码的行号指示器,解释器的工作原理就是通过改变这个计数器的值来确定下一条需要被执行的字节码指令,程序控制的流程(循环、分支、异常处理。线程恢复)都是通过这个计数器来完成的
7)本地方法栈
本地方法栈与虚拟机栈的作用是相似的,唯一不同的是虚拟机栈为虚拟机执行java方法(也就是字节码)服务。而本地方法栈则是为虚拟机使用到的Native(本地)方法服务,本地方法接口都会用到某种本地方法栈,当线程调用java方法时,jvm会创建一个新的栈帧并压入虚拟机栈,然而当他调用的是本地方法时,虚拟机栈保持不变么不会在线程的虚拟机中压入新的帧,而是简单的动态链接并直接调用指定的本地方法,如果某个虚拟机实现的本地方法接口使用的是c++链接模型,那么他的本地方法栈就是c++栈
8)执行引擎
执行引擎主要负责执行字节码,方法的字节码是由java虚拟机的指令序列构成的,每一条指令包含一个单字节的操作码,后面跟随0个或者多个操作数,然后执行这个操作,执行完成后会继续取得下一个操作码去执行
在执行方法时,JVM提供了四种指令来执行
①invokestatic“调用类的static方法
②invokevirtual:调用对象实例的方法
③invokeinterface:将属性定义为接口来进行调用
④invokespecial:调用一个初始化方法,私有方法或者父类的方法
9)垃圾回收
垃圾回收主要是回收程序中不再使用的内存
9、垃圾回收
在java 语言中 GC是一个非常重要的概念,他的主要作用是回收程序中不再使用的内存,在c和c++语言进行程序开发的时候,开发人员必须仔细的管理好内存的分配与释放,如果忘记或者错误的释放内存往往会导致程序运行不正确甚至是程序的崩溃,为了减轻开发人员的工作,同时增加系统的安全性和稳定性,java语言提供了垃圾回收器来自动检测对象的租用与,自动地、把不再被使用的存储空间释放掉,具体而言,垃圾回收主要负责完成三项任务:分配内存、确保被引用对象的内存不被错误地回收以及回收不再被引用的对象的内存空间
垃圾回收器的存在,一方面把开发人员从释放内存的复杂的工作中解脱出来,提高了开发人员的生产效率;另一方面对开发人员屏蔽了释放内存的方法,可以避免因为开发人员错误地操作内存从而导致应用程序的崩溃,保证了程序的稳定性,但是垃圾回收也带来问题,为了实现垃圾回收,垃圾回收器必须跟踪内存的使用情况,释放没有用的对象,在完成内存的释放后,还要处理堆中的碎片,这些操作必定会增加JVM的负担,从而降低程序的执行效率
在java语言中,释放掉占据的内存空间是由GC完成的,程序员无法直接强制释放存储空间,当一个对象不被使用的时候,GC会将该对象标记为垃圾,并在后面一个不确定的时间内回收垃圾(程序员无法控制这个时间),给对象引用赋值为null,并且该对象无其他引用,GC会标记该对象为垃圾,并且在后面一个不确定的时间内回收垃圾,所谓不确定什么时间回收,程序员无法控制
java 中 查看程序使用内存的情况:
每个Java程序都有一个Runtime类实例。

使JVM的堆、栈和持久代发生内存的方法:
1)堆:通过new实例化的对象都存储在堆空间中,因此只要不断的new实例化对象,切一致保持对这些对象的引用(垃圾回收器无法回收),实例化足够多的实例出来就会导致堆溢出
List<Object> a =new ArrayList<Object>();
while(true)
{ a.Add(new Object())}
2) 在方法的调用时,栈从来保存上下文的一些内容,由于栈的大小是有上限的,当出现非常深层次的方法调用的时候就会把栈的空间用完,最简单的栈溢出的代码就是无限递归
3)持久代 在Java语言中,当一个类第一次被访问的时候,JVM需要把来加载出来,而类加载器就会占用持久代空间来存储classes信息,持久代中只要包含以下信息:类方法、类名、常量池和JVM使用的内部对象等,当JVM需要加载一个新类时候,如果持久带中没有足够的空间,吃就会跑出JAVA.Lang.OutOfMemoryErry:PermGen Space异常,所以,当代码加载足够多类的时候就会导致持久代溢出,当然并不是所有的Java虚拟机都有持久代的概念
Java中老年代、年轻代的区别
根据对象的声明周期的长短把对象分为不同的种类(年轻代。年老代和持久代),并分别进行内存回收,也就是分带垃圾回收。其主要思路如下:把堆分成两个或者多个子堆,没一个子堆被视为一代,在运行的过程中,优先收集那些年幼的对象,如果一个对象经过多次收集仍然存货,name就可以把这个对象转移到高一级的堆里面,减少对其的扫描次数
目前最长用的jvm是SUN公司(现被Oracle公司收购)的HotSport,他采用的算法为分代回收。
(1)年轻代 :被分为三个部分,一个Eden区和两个相同的Survivor区,前者用来存储新建的对象,后者也被叫做From和To区,Survivor区是大小相等的两块区域,在使用“复制”回收算法时,作为双缓存,起内存整理的作用,因此,Survivor区始终保持一个是空的
(2)老年代 主要存储声明周期较长的对象、超大的对象(无法在新生代分配的对象)
(3)永久代 存放代码、字符串常量池和静态变量等可以持久化的数据。SunJDK把方法区实现在了永久代
由于永久代基本不参与垃圾回收,随意这里主要介绍年轻代和老年代的垃圾回收方法
新建对象优先在Eden区分配内存,如果Eden区已满在创建对象的时候,会因为无法申请到空间而触发minoreGC操作,minoreGC主要用来对年轻代垃圾进行回收:把Eden中不能被回收的对象放入到空的Survivor区,另一个Survivor区里不能被回收的对象也会被放入到这个Survivor区,这样保证一个Survivor区是空的。如果这个Survivor区也满了,就会把这些对象复制到老年代,如果老年代也满了,就会触发FullGC
fullGC是用来清理整个空间的,包括年轻代和永久代,所以fullGC会造成很大的系统开销,因此通常需要尽量避免fullGC操作。
下面介绍几种常见的避免fullGC的方法
1)调用System.gc()方法会触发fullGC,因此在编码的时候尽量避免调用这个方法
2)老年代空间不足。由于老年代主要用来存储从年轻代转入的对象、大对象和大数组,因此,为了避免触发fullGC,应尽量做到让对象在MinorGC阶段被回收,不要创建过大的数组及对象,由于在MinorGC时,只有Survivor区放不下的对象才会被放入老年代,而此时只有老年代放不下才会触发fullGC,因此,另一种避免fullGC的方法是 根据实际情况增大Survivor区,老年代空间或调低触发GC的概率
3)永久代满,永久代主要存放class相关的信息,当永久代满的时候也会触发fullGC,未来避免这种情况,可以增大永久代的空间(例如-XX:MaxPermSize=16m:设置永久代的大小为16M)为了避免永久代满引起的fullGC 也可以开启CMS回收永久代选项(开启的选项为+CMSPermGenSweepingEnabled-XX:+CMSClassUnloadingEnabled。)CMS利用和应用程序线程并发的垃圾回收线程来进行垃圾回收操作
需要注意的是 JAVA8中已经移除了永久代,新加了一个称为元数据区的native内的存储区,所以大部分类的元数据都在本地内存中分配
10 、容器
1、HashMap和Hashtable的区别
1)都实现了Map接口,HashMap允许空(null)键值(最多只允许一条记录),而HashTable不允许
2)HashMap把Hashtable的contains 方法,改成containsvalue 和containskey。以内contains方法会让人引起误解,Hashtable 继承自Dictionary类,而hashMap继承自AbstractMap类
3)HashTable的方法是县城安全的,而HashMap不是线程安全的,当多个线程访问Hashtable时,不需要开发人员对他进行同步,而对弈HashMap,开发人员必须提供额外的同步机制,所以效率上HashMap可能要高于Hashtable、
4)“快速失败”,也就是fail-fast,他是Java集合的一种错误检测机制,当多个线程对几个进行结构上的改变操作时,就会有可能产生fail-fast事件。例如 假设存在两个线程,他们分别是线程1与线程2,当线程1通过Iterator(迭代器)在遍历A中的元素时,如果线程2修改了集合A的结构(删除或者新增了元素),那么,此时就会抛出ConcurrentModificationException异常,从而产生fail-fast 事件
由于Hashtable是线程安全的,因此没有快速失败的机制,而HashMap是非线性安全的,迭代HashMap采用了快速失效的机制
5)Hashtable使用Enumeration进行遍历,HashMap使用Iterator进行遍历
6)两者采用的hash/rehash算法几乎一样,所以性能不会有很大的差异
7)Hashtable中hash数组默认大小是11,增加的方式是old*2+1,HashMap中hash数组的默认大小是16,而且一定是2的指数
8)hash值的使用不同 Hashtable直接使用对象的hashCode
2、List<?extends T> 和List<?super T>的区别
List<?extends T>表示类型的上界,也就是说参数化的类型可能是T或者是T的子类,例如下面的写法都是合法的赋值语句:
List<?extends Number> list =new ArrayList<.Number>();
List<?extends Number> list =new ArrayList<.Integer>();//Integer是Number的子类
List<?extends Number> list =new ArrayList<.Float>();//Float是Number的子类
<?extends T> 被设计为用来读数据的泛型(只能读取类型为T的元素)原因如下:
1)在上面赋值的示例中,对读数据进行分析
①不管给list如何赋值,可以保证list里面存放的一定是Number类型或者其子类,因此,可以从list列表里读取number类型的值
②不能从list中读取Integer,因为list里面可能丛芳的是Float值,同理也不能从list 中读取Float
2)对写数据进行分析
①不能向list中写Number,因为list中可能会存放的是Float
②不能向list中写Integer,因为list中可能会存放的是Float
③不能向list中写Float,因为list中可能会存放的是Integer
从上面分析可以发现,只能从List<?extends T>读取T,因为无法确定他实际指向列表的类型
所以违法确定列表里面存放的实际的类型,也无法向列表中添加元素
<?super T>标识类型下界,也就是说,参数化的类型时此类的超类型(父类型)
List<?super Foat> list =new ArrayList<.Number>();
List<?super Foat> list =new ArrayList<.Object>();//Integer是Number的子类
List<?super Foat> list =new ArrayList<.Float>();//Float是Number的子类
<?super T>被设计为用来写数据的泛型(只能写入T或者T的子类类型),不能用来读
分析如下
1)读数据,无法保证list里面一定存放的是Float或者Number类型,因为有可能存放的是Object类型,唯一能确定的是list里面存放的是OBject或其子类,但是无法确定具体自尅的类型没正事由于无法确定list里面存放数据的类型,因此无法从list里面读取数据
2)写数据
①可以向list里面写入Float类型的数据(不管list 里面实际存放的是Float、Number或OBject,写入Float都是允许的),同理,也可以向list里面添加Float子类类型的元素
②不可以向list里面添加Number或者Object类型的数据,因为list中可能存放的是Float数据
3、ArryList、Vector和LinkedList的特点
三个类均在Java.util包中,都是可伸缩的数组,即可以动态改变长度的数组
ArrayList和Vector都是基于存储元素Object[] array来实现的,他们会在内存中开辟一块连续的空间来存储。由于数据存储式连续的,因此他们支持用序号(下标、索引)来访问元素,同时索引数据的速度比较快,但是在插入元素的时候需要移动容器中的元素,所以,对数据的插图操作执行速度比较慢。ArrayList和Vector都有一个初始化的容量大小,当里面的存储的元素超过这个大小的时候,就需要动态的扩充他们的存储空间。为了提高程序的效率,每次扩充容量的时候,不是简单的扩充一个存储单元,而是一次就会增加多个存储单元,Vector默认扩充为原来的2倍(每次扩充空间的大小也是可以设置的),而ArrayList默认扩充为原来的1.5倍(没有提供方法来实质空间扩充的方法),两者醉倒的区别就是Synchronization(同步)的使用,没有一个ArrayList的方法是同步的,而Vector的绝大多数方法(例如Add,insert、remove、set、equals、hashCode等)都是直接或间接同步的,所以,Vector是线程安全的,ArrayList不是线程安全的,正是由于Vector提供了线程安全的机制,使其性能上也略逊于Arraylist
LinkedList是采用双向列表来实现的,对数据的索引需要从列表头开始遍历、因此随机访问的效率比较低,但是 插入元素的时候不需要对数据进行移动,插入数据的效率比较高。同时LinkedList不是线性安全的
那么在实际使用中,当对数据的主要操作为索引或只在集合的末端增加。删除元素使用ArrayList或者Vector 效率比较高。当数据的操作主要为指定位置的插入或者删除操作,使用LInkedList效率比较高,当在多线程中使用容器(即多个线程会同时方位该容器)时,选用Vector较为安全
4、Collection和Collections的区别
Collection 是一个集合接口,他提供了对集合对象进行基本操作的通用接口方法,实现该接口的类主要有List和Set,该接口的设计目标是为各种具体的集合提供最大化的同意操作方式
Collections是针对集合类一个包装类,他提供了一系列静态方法实现对各种集合的搜索、排序和线程安全话等操作,其中的大多数方法都是用于处理线性表。Collections类不能被实例化,如同一个工具类,服务于Collection框架,如果在使用Collections类的方法时,对用的Collection对象为null时,则这些方法都会抛出NUllPointerException
5、fail-fast 和fail-safe迭代器的区别是什么?
主要区别 是fail-safe允许在遍历的过程中对容器中的数据进行修改,而fail-fast则不允许,下面分别介绍两种迭代器的工作原理
fail-fast 直接在容器上进行遍历,在遍历的过程中,一旦发现容器中的数据被修改了 (添加、删除、修改元素)会立即抛出ConcurrentModificationException 异常从而导致遍历失败。常见的使用fail-fast方式的容器有HashMap和ArrayList等
fail-safe:这种遍历基于容器的一个克隆,因此对容器中内容的修改不影响遍历,常见的遍历的容器有ConcurrentHashMap和CopyOnWriteArrayList。
6、HashSet中,equals 与hashCode的区别
HashSet是基于Java.util包中的类,存储的元素时不能重复的,由于其中存放的是对象,主要通过hashCode和equals两个方法来判断,所以 对于在HashSet中存储的对象,对应的类最好根据实际情况实现自己的equals个hashCode方法、
每当想HashSet中添加一个元素的时候,可以采用以下方法来判断两个对象是否相同:
1)如果两个对象的hashCode值不同,那么说明两个对象不相同
2)如果两个对象的hashCode 值相同,接着会调用对象的equals方法,如果equals方法返回的结果为true,那说明两个对象相同吗否则两个对象不相同
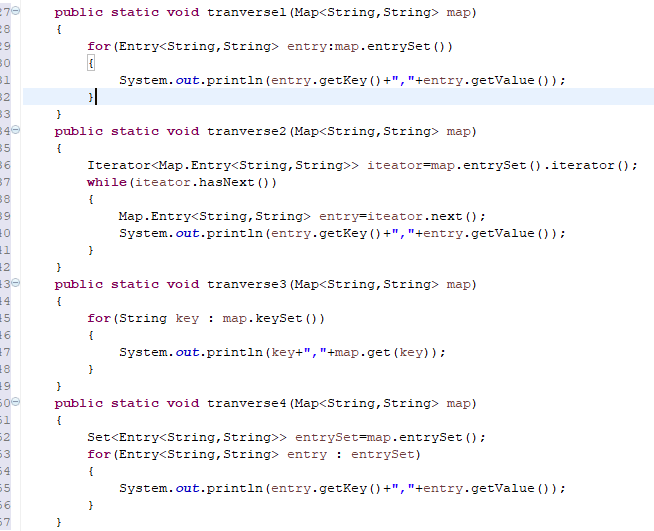
10.遍历HashMap的四中方法
1)foreach map.entrySet().
2)显式调用map.entrySet()的集合迭代器
3)foreach map.keySet(),再调用get方法取
4)foreach map.entrySet() 用临时变量保存map.entrySet()