
AQL基本语法
目录:
一、数据预览
本次使用的数据共有43条,每条数据包含姓氏、年龄、活动状态和特征等六个字段
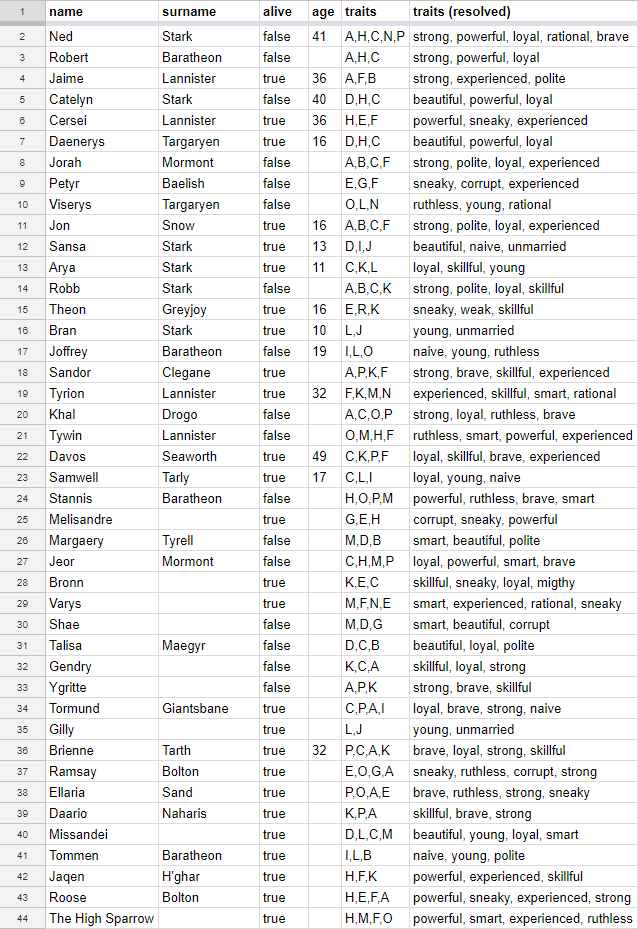
其中每个特征都有一个随机字母作为文档密钥。特质标签有英文和德文。
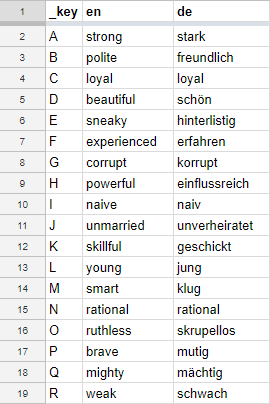
地点由地名和经纬度组成:
二、基本的CRUD
创建集合:
在创建文档之前,需要创造一个放置它的集合,集合可以通过Web界面,arangosh或驱动程序来创建。AQL无法创建集合。
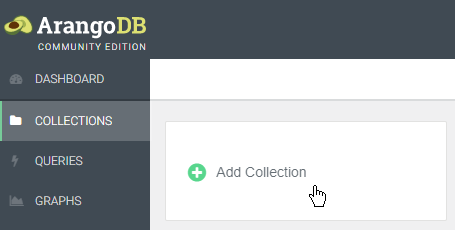
单击Web界面中的COLLECTIONS,然后单击Add Collection并键入 Charactersname。使用保存确认。新集合就出现在了列表中。
插入单个对象:
使用AQL插入文档
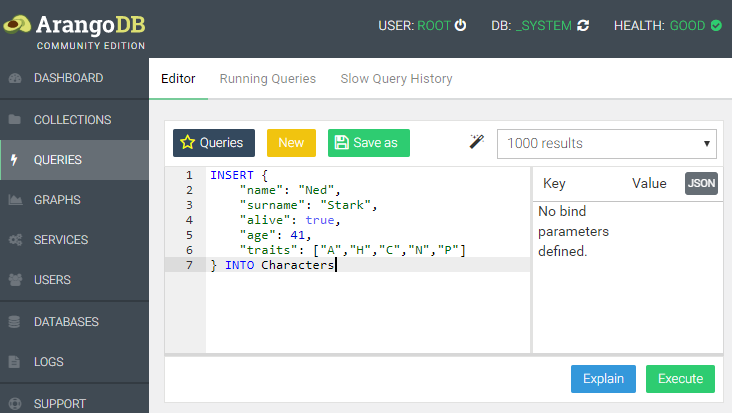
INSERT {
"name": "Ned",
"surname": "Stark",
"alive": true,
"age": 41,
"traits": ["A","H","C","N","P"]
} INTO Characters
语法:
INSERT document INTO collectionName
该文档是一个对象,由属性键和值对组成。属性键的引号在AQL中是可选的。键总是字符串,而属性值可以有不同的类型:
- null
- boolean (true, false)
- number (integer and floating point)
- string
- array
- object
批量插入对象:
AQL不允许INSERT在单个查询中针对同一集合的多个操作。但是可以使用FOR循环体,插入多个文档。
LET data = [
{ "name": "Robert", "surname": "Baratheon", "alive": false, "traits": ["A","H","C"] },
{ "name": "Jaime", "surname": "Lannister", "alive": true, "age": 36, "traits": ["A","F","B"] },
{ "name": "Catelyn", "surname": "Stark", "alive": false, "age": 40, "traits": ["D","H","C"] },
{ "name": "Cersei", "surname": "Lannister", "alive": true, "age": 36, "traits": ["H","E","F"] },
{ "name": "Daenerys", "surname": "Targaryen", "alive": true, "age": 16, "traits": ["D","H","C"] },
{ "name": "Jorah", "surname": "Mormont", "alive": false, "traits": ["A","B","C","F"] },
{ "name": "Petyr", "surname": "Baelish", "alive": false, "traits": ["E","G","F"] },
{ "name": "Viserys", "surname": "Targaryen", "alive": false, "traits": ["O","L","N"] },
{ "name": "Jon", "surname": "Snow", "alive": true, "age": 16, "traits": ["A","B","C","F"] },
{ "name": "Sansa", "surname": "Stark", "alive": true, "age": 13, "traits": ["D","I","J"] },
{ "name": "Arya", "surname": "Stark", "alive": true, "age": 11, "traits": ["C","K","L"] },
{ "name": "Robb", "surname": "Stark", "alive": false, "traits": ["A","B","C","K"] },
{ "name": "Theon", "surname": "Greyjoy", "alive": true, "age": 16, "traits": ["E","R","K"] },
{ "name": "Bran", "surname": "Stark", "alive": true, "age": 10, "traits": ["L","J"] },
{ "name": "Joffrey", "surname": "Baratheon", "alive": false, "age": 19, "traits": ["I","L","O"] },
{ "name": "Sandor", "surname": "Clegane", "alive": true, "traits": ["A","P","K","F"] },
{ "name": "Tyrion", "surname": "Lannister", "alive": true, "age": 32, "traits": ["F","K","M","N"] },
{ "name": "Khal", "surname": "Drogo", "alive": false, "traits": ["A","C","O","P"] },
{ "name": "Tywin", "surname": "Lannister", "alive": false, "traits": ["O","M","H","F"] },
{ "name": "Davos", "surname": "Seaworth", "alive": true, "age": 49, "traits": ["C","K","P","F"] },
{ "name": "Samwell", "surname": "Tarly", "alive": true, "age": 17, "traits": ["C","L","I"] },
{ "name": "Stannis", "surname": "Baratheon", "alive": false, "traits": ["H","O","P","M"] },
{ "name": "Melisandre", "alive": true, "traits": ["G","E","H"] },
{ "name": "Margaery", "surname": "Tyrell", "alive": false, "traits": ["M","D","B"] },
{ "name": "Jeor", "surname": "Mormont", "alive": false, "traits": ["C","H","M","P"] },
{ "name": "Bronn", "alive": true, "traits": ["K","E","C"] },
{ "name": "Varys", "alive": true, "traits": ["M","F","N","E"] },
{ "name": "Shae", "alive": false, "traits": ["M","D","G"] },
{ "name": "Talisa", "surname": "Maegyr", "alive": false, "traits": ["D","C","B"] },
{ "name": "Gendry", "alive": false, "traits": ["K","C","A"] },
{ "name": "Ygritte", "alive": false, "traits": ["A","P","K"] },
{ "name": "Tormund", "surname": "Giantsbane", "alive": true, "traits": ["C","P","A","I"] },
{ "name": "Gilly", "alive": true, "traits": ["L","J"] },
{ "name": "Brienne", "surname": "Tarth", "alive": true, "age": 32, "traits": ["P","C","A","K"] },
{ "name": "Ramsay", "surname": "Bolton", "alive": true, "traits": ["E","O","G","A"] },
{ "name": "Ellaria", "surname": "Sand", "alive": true, "traits": ["P","O","A","E"] },
{ "name": "Daario", "surname": "Naharis", "alive": true, "traits": ["K","P","A"] },
{ "name": "Missandei", "alive": true, "traits": ["D","L","C","M"] },
{ "name": "Tommen", "surname": "Baratheon", "alive": true, "traits": ["I","L","B"] },
{ "name": "Jaqen", "surname": "H'ghar", "alive": true, "traits": ["H","F","K"] },
{ "name": "Roose", "surname": "Bolton", "alive": true, "traits": ["H","E","F","A"] },
{ "name": "The High Sparrow", "alive": true, "traits": ["H","M","F","O"] }
]
FOR d IN data
INSERT d INTO Characters
语法:
LET variableName = valueExpression
LET关键字定义了同名称的变量数据和对象值的数列,格式为[ {...}, {...}, ... ]
FOR variableName IN expression
用于迭代数据数组的每个元素 。在每个循环中,将一个元素分配给变量d。然后在INSERT语句中使用此变量。相当于下面的格式:
INSERT {
"name": "Robert",
"surname": "Baratheon",
"alive": false,
"traits": ["A","H","C"]
} INTO Characters
INSERT {
"name": "Jaime",
"surname": "Lannister",
"alive": true,
"age": 36,
"traits": ["A","F","B"]
} INTO Characters
...
检索
检索集合中的所有文档:
FOR c IN Characters
RETURN c
语法:
FOR variableName IN collectionName
对于集合中的每个文档,依次分配给变量c,然后根据循环体返回该文档。
选取其中一个文档如下:
{
"_key": "2861650",
"_id": "Characters/2861650",
"_rev": "_V1bzsXa---",
"name": "Ned",
"surname": "Stark",
"alive": true,
"age": 41,
"traits": ["A","H","C","N","P"]
},
该文档包含我们存储的四个属性,以及数据库系统添加的另外三个属性:
_key:文档键,用户可以在创建文档时提供文档键,也可以自动分配唯一值,不能改变,只读
_id:集合名/文档键,只读
_rev:系统管理的修订版ID,只读
检索特定文档:
RETURN DOCUMENT("Characters", "2861650")
// --- or ---
RETURN DOCUMENT("Characters/2861650")
返回:
[ { "_key": "2861650", "_id": "Characters/2861650", "_rev": "_V1bzsXa---", "name": "Ned", "surname": "Stark", "alive": true, "age": 41, "traits": ["A","H","C","N","P"] } ]
语法:
DOCUMENT()
使用_key或_id检索特定文档,该函数还允许一次获取多个文档
RETURN DOCUMENT("Characters", ["2861650", "2861653"])
// --- or ---
RETURN DOCUMENT(["Characters/2861650", "Characters/2861653"])
更新文档:
修改现有文件:
UPDATE "2861650" WITH { alive: false } IN Characters
语法:
UPDATE documentKey WITH object IN collectionName
用列出的属性更新指定的文档(如果它们不存在则添加它们),但保持其余不变。要替换整个文档内容,则要使用REPLACE函数:
REPLACE "2861650" WITH { name: "Ned", surname: "Stark", alive: false, age: 41, traits: ["A","H","C","N","P"] } IN Characters
该函数也适用于循环,例如为所有文档添加新属性:
FOR c IN Characters
UPDATE c WITH { season: 1 } IN Characters
删除文件:
语法:
REMOVE _key IN Collectiosname
要从集合中完全删除文档,需要执行REMOVE操作。它的工作方式与其他修改操作类似,但没有WITH子句:
REMOVE "2861650" IN Characters
三、匹配文件
语法:
FILTER
查找满足比_key相等更复杂的条件的文档,能够为要匹配的文档制定任意条件。
等于条件:
FOR c IN Characters
FILTER c.name == "Ned"
RETURN c
过滤条件如下:“ 字符文档的属性name必须等于字符串Ned ”。如果条件适用,则返回字符文档。
范围条件:
FOR c IN Characters
FILTER c.age >= 13
RETURN c.name
多种条件:
FOR c IN Characters FILTER c.age < 13 FILTER c.age != null RETURN { name: c.name, age: c.age } //or FOR c IN Characters FILTER c.age < 13 AND c.age != null RETURN { name: c.name, age: c.age }
替代条件:
FOR c IN Characters FILTER c.name == "Jon" OR c.name == "Joffrey" RETURN { name: c.name, surname: c.surname }
四、排序和限制
限制语法:
LIMIT()
LIMIT后面跟着一个最大显示数的数字,限制结果显示行数。
FOR c IN Characters
LIMIT 5
RETURN c.name
还可以使用LIMIT来跳过一定数量的记录返回下一个n个文档:
FOR c IN Characters
LIMIT 2, 5
RETURN c.name
排序语法:
SORT()
DESC降序来反转排序顺序
FOR c IN Characters
SORT c.name DESC
LIMIT 10
RETURN c.name
多个字段排序
FOR c IN Characters
FILTER c.surname
SORT c.surname, c.name
LIMIT 10
RETURN {
surname: c.surname,
name: c.name
}
此处FILTER的作用是仅保留surname为非空记录
五、组合
语法:
MERGE()
MERGE()的功能是将对象组合在一起。因为使用了原始字符属性{ traits: ... },所以后者被合并覆盖。
FOR c IN Characters
RETURN MERGE(c, { traits: DOCUMENT("Traits", c.traits)[*].en } )
六、图操作
创建图:
语法:
INSERT { _from: _id(A), _to: _id(B) } INTO ChildOf
实例:
首先,创建一个新的集合,并确保将集合类型更改为Edge。

然后,通过查询多个集合的数据,将结果存入边集合中
LET data = [ //关系数据
{
"parent": { "name": "Ned", "surname": "Stark" },
"child": { "name": "Robb", "surname": "Stark" }
}, {
"parent": { "name": "Ned", "surname": "Stark" },
"child": { "name": "Sansa", "surname": "Stark" }
}, {
"parent": { "name": "Ned", "surname": "Stark" },
"child": { "name": "Arya", "surname": "Stark" }
}, {
"parent": { "name": "Ned", "surname": "Stark" },
"child": { "name": "Bran", "surname": "Stark" }
}, {
"parent": { "name": "Catelyn", "surname": "Stark" },
"child": { "name": "Robb", "surname": "Stark" }
}, {
"parent": { "name": "Catelyn", "surname": "Stark" },
"child": { "name": "Sansa", "surname": "Stark" }
}, {
"parent": { "name": "Catelyn", "surname": "Stark" },
"child": { "name": "Arya", "surname": "Stark" }
}, {
"parent": { "name": "Catelyn", "surname": "Stark" },
"child": { "name": "Bran", "surname": "Stark" }
}, {
"parent": { "name": "Ned", "surname": "Stark" },
"child": { "name": "Jon", "surname": "Snow" }
}, {
"parent": { "name": "Tywin", "surname": "Lannister" },
"child": { "name": "Jaime", "surname": "Lannister" }
}, {
"parent": { "name": "Tywin", "surname": "Lannister" },
"child": { "name": "Cersei", "surname": "Lannister" }
}, {
"parent": { "name": "Tywin", "surname": "Lannister" },
"child": { "name": "Tyrion", "surname": "Lannister" }
}, {
"parent": { "name": "Cersei", "surname": "Lannister" },
"child": { "name": "Joffrey", "surname": "Baratheon" }
}, {
"parent": { "name": "Jaime", "surname": "Lannister" },
"child": { "name": "Joffrey", "surname": "Baratheon" }
}
]
FOR rel in data
LET parentId = FIRST( //FIRST()提取第一个元素
FOR c IN Characters
FILTER c.name == rel.parent.name //筛选条件
FILTER c.surname == rel.parent.surname
LIMIT 1
RETURN c._id //返回_id
)
LET childId = FIRST(
FOR c IN Characters
FILTER c.name == rel.child.name
FILTER c.surname == rel.child.surname
LIMIT 1
RETURN c._id
)
FILTER parentId != null AND childId != null //剔除_id都为空的记录
INSERT { _from: childId, _to: parentId } INTO ChildOf //将数据插入边集合
RETURN NEW //返回数据
也可以直接创建边数据:
INSERT { _from: "Characters/robb", _to: "Characters/ned" } INTO ChildOf
遍历图:
语法:
FOR v IN 1..1 OUTBOUND _id ChildOf
RETURN v.name
其中1..1为遍历深度
实例:
FOR c IN Characters
FILTER c.name == "Bran"
FOR v IN 1..1 OUTBOUND c ChildOf
RETURN v.name
返回
[
"Ned",
"Catelyn"
]
遍历的情况如下图:

若是反向遍历,则需要使用到INBOUND关键字:
FOR c IN Characters
FILTER c.name == "Tywin"
FOR v IN 2..2 INBOUND c ChildOf
RETURN DISTINCT v.name
输出:
[
"Joffrey"
]
遍历情况如下:

需要注意的是,“1..1”限制了遍历深度为1,“2..2”限制了遍历深度为2,而"1..2"限制遍历深度既可以为1也可以为2。
七、地理空间查询
地点数据
创建地点集合:
录入地点数据:
LET places = [
{ "name": "Dragonstone", "coordinate": [ 55.167801, -6.815096 ] },
{ "name": "King's Landing", "coordinate": [ 42.639752, 18.110189 ] },
{ "name": "The Red Keep", "coordinate": [ 35.896447, 14.446442 ] },
{ "name": "Yunkai", "coordinate": [ 31.046642, -7.129532 ] },
{ "name": "Astapor", "coordinate": [ 31.50974, -9.774249 ] },
{ "name": "Winterfell", "coordinate": [ 54.368321, -5.581312 ] },
{ "name": "Vaes Dothrak", "coordinate": [ 54.16776, -6.096125 ] },
{ "name": "Beyond the wall", "coordinate": [ 64.265473, -21.094093 ] }
]
FOR place IN places
INSERT place INTO Locations
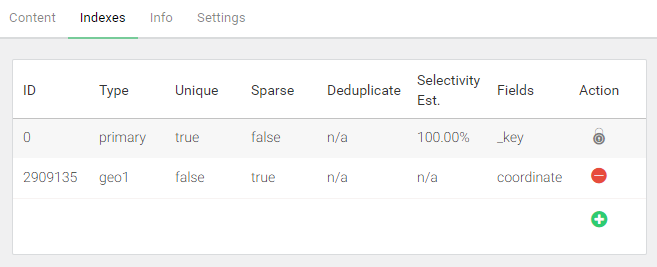
设置地理空间索引:
在COLLECTIONS界面,添加新的Indexes,设置为coordinate字段:

查找附近的位置
语法:
NEAR()
找到最接近的坐标参考点
FOR loc IN NEAR(Locations, 53.35, -6.26, 3)
RETURN {
name: loc.name,
latitude: loc.coordinate[0],
longitude: loc.coordinate[1]
}
输出:
[
{
"name": "Vaes Dothrak",
"latitude": 54.16776,
"longitude": -6.096125
},
{
"name": "Winterfell",
"latitude": 54.368321,
"longitude": -5.581312
},
{
"name": "Dragonstone",
"latitude": 55.167801,
"longitude": -6.815096
}
]
查找半径内的位置
语法:
WITHIN()
从参考点搜索给定半径内的位置
FOR loc IN WITHIN(Locations, 53.35, -6.26, 200 * 1000)
RETURN {
name: loc.name,
latitude: loc.coordinate[0],
longitude: loc.coordinate[1]
}
输出
[
{
"name": "Vaes Dothrak",
"latitude": 54.16776,
"longitude": -6.096125
},
{
"name": "Winterfell",
"latitude": 54.368321,
"longitude": -5.581312
}
]
按距离查找位置:
语法:
NEAR()或WITHIN()
通过添加一个可选的第五个参数返回到参考点的距离。必须是一个字符串:
FOR loc IN NEAR(Locations, 53.35, -6.26, 3, "distance")
RETURN {
name: loc.name,
latitude: loc.coordinate[0],
longitude: loc.coordinate[1],
distance: loc.distance / 1000
}
输出:
[
{
"name": "Vaes Dothrak",
"latitude": 54.16776,
"longitude": -6.096125,
"distance": 91.56658640314431
},
{
"name": "Winterfell",
"latitude": 54.368321,
"longitude": -5.581312,
"distance": 121.66399816395028
},
{
"name": "Dragonstone",
"latitude": 55.167801,
"longitude": -6.815096,
"distance": 205.31879386198324
}
]
使用AQL遇到的问题:
问题1:如何对查询结果进行计数并返回?
解决方法:
RETURN COUNT(FOR v IN visitors FILTER v.ip == "127.0.0.1" RETURN 1)
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号