爬虫数据存储
爬取的数据,需要保存,可以存储在文件中或者数据库中。
- 存储在文件中,包括txt、csv、json;
- 存储在数据库中,包括MySQL关系数据库和MongoDB数据库。
python 字典操作参考:
http://jianwl.com/2017/08/22/高效实用Python字典的清单/
python 读写参考:
https://www.cnblogs.com/liutongqing/p/6892099.html
1、基本存储:存储至txt、csv、json
(1)存入txt文件(saving_data.py)
all_house数据结构:all_house[{'house_area':dd,'price':dd,'build_year':dd},{},{}...]
f=open('net_saving_data.txt','w');
for item in all_house:
# house_area=item['house_area'];
# price=item['price'];
output='\t'.join([str(item['house_area']),str(item['price']),str(item['build_year'])]);
f.write(output);
f.write('\n');
f.close();
效果如图:
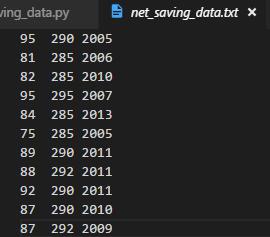
- 若需要将几个变量写入txt中,可以用
'\t'.join(["house_area","price","build_year"]),注意join()内是个列表。
(2)存入CSV文件(saving_data.py)
CSV(Comma-Separated_values),以逗号分隔值的文件格式,文件以纯文本格式存储表格数据(数字和文本),每一行以换行符分隔,列与列之间用逗号分隔。与txt比较,能够存储的数据大小差不多,但是数据以逗号分隔较整齐,所有python网络爬虫经常用此来存储数据。
- 从字典中写入csv文件
import csv;
f=open('net_saving_data.csv','w');
csv_write=csv.writer(f);
for item in all_house:
csv_write.writerow([item.get('house_area',None),item.get('price',None),item.get('build_year',None)]);
#f.write('\n');
f.close();
效果如图:
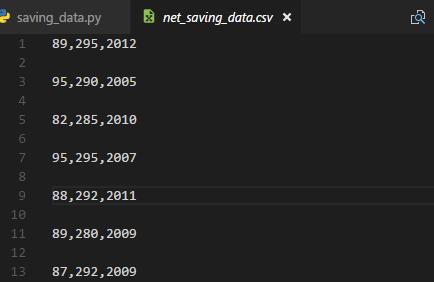
若是想在csv中加入key值,操作如下:
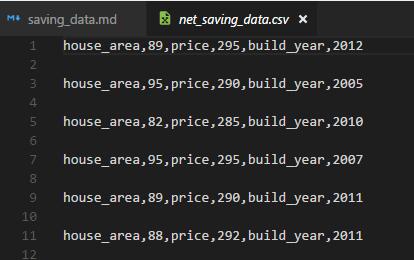
csv_write.writerow(['house_area',item.get('house_area',None),'price',item.get('price',None),'build_year',item.get('build_year',None)]);
效果如图:
- 从列表中写入csv文件
houses=[['2edr','ser','sge'],['as','hi','hioh','aaajio']];
f=open('saving_data.csv','w');
csv_write=csv.writer(f);
for house in houses:
csv_write.writerow([item for item in house]);
f.close();
效果如图:

(3)写入json文件
##写入
with open("anjuke_salehouse.json","w",encoding='utf-8') as f:
json.dump(all_house,f,ensure_ascii=False);
print(u'加载入文件完成...');
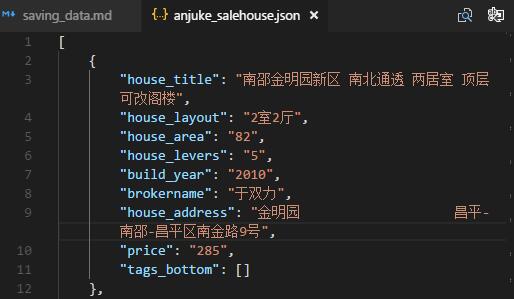
2、csv、json、txt读取:
(1)csv读取
-参考:https://www.cnblogs.com/liutongqing/p/6892099.html
import csv;
houses=[];
with open('net_saving_data.csv','r') as openscv:
csv_reader=csv.reader(openscv);
for row in csv_reader:
houses.append(row);
openscv.close();
print houses;
原数据界面:
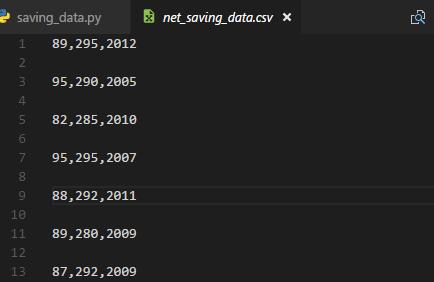
读取数据界面如下:
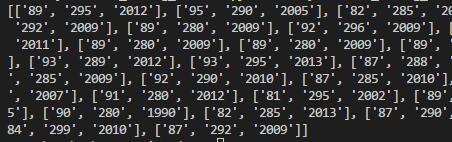
(2)json读取
##读入
with open("anjuke_salehouse.json",'r',encoding='utf-8') as f:
load_dict=json.load(f);
print (load_dict);
什么的不要想,直接load出来的就是json文件格式一模一样的一个对象。 主要是防止乱码的等参数设置。
(3)txt读取
参考文章:https://blog.csdn.net/shandong_chu/article/details/70173952
with open('net_saving_data.txt','r') as opentxt:
txt_reader=opentxt.readlines();
for lin in txt_reader:
print (lin);
3、MySQL数据库操作
建库、更删改查,因为下面涉及一些对数据库的操作,现在这里复习一下基本的更删改查
(1)建数据库、建表
create table urls(id int NOT NULL auto_increment,url varchar(1000) NOT NULL,content varchar(4000) NOT NULL,created_time timestamp default current_timestamp,primary key(id));
*/
(2)查表结构或查database
describe urls;
show databases;

(3)表中插入数据
insert into urls(url,content)values("www.baidu.com","这是内容。")
select * from urls where id=1;
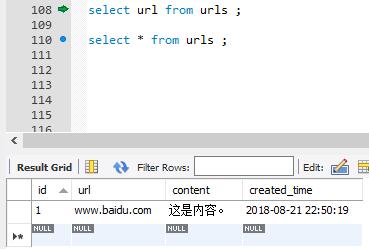
(4)从数据表中提取数据
insert into urls(url,content)values("www.blog.com","博客网址。");
select * from urls ;
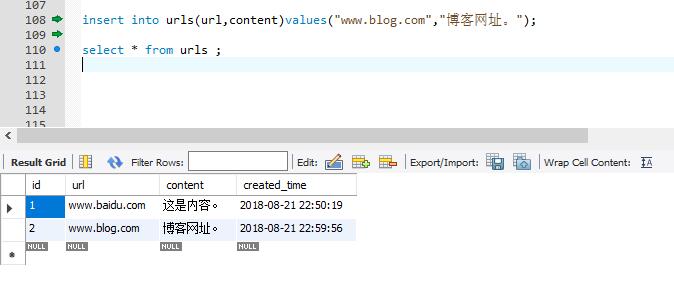
(5)删除数据
delete from urls where url='www.baidu.com';
select * from urls ;

(6)修改数据
将id=2的content改成博客园
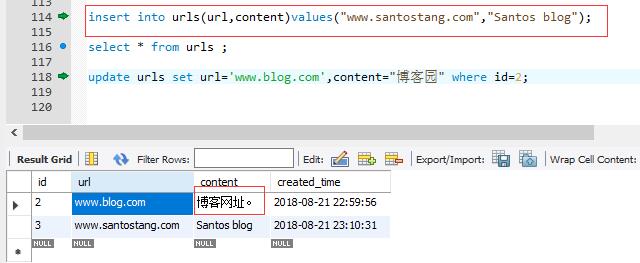
insert into urls(url,content)values("www.santostang.com","Santos blog");
update urls set url='www.blog.com',content="博客园" where id=2;
select * from urls ;

(7)语句参考地址:https://blog.csdn.net/ljxfblog/article/details/52066006
UNION
select * from a order by id) union (select * from b order by id);
- 如果不同的语句中取出的行,有完全相同(这里表示的是每个列的值都相同),那么union会将相同的行合并,最终只保留一行。也可以这样理解,union会去掉重复的行。如果不想去掉重复的行,可以使用union all。如果子句中有order by,limit,需用括号()包起来。推荐放到所有子句之后,即对最终合并的结果来排序或筛选。两次查询的列数必须一致
JOIN
//使用连表查询
SELECT Persons.LastName, Persons.FirstName,Orders.OrderNo
FROM Persons, Orders
WHERE Persons.Id_P = Orders.Id_P
//使用join查询(inner join)
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
INNER JOIN Orders
ON Persons.Id_P = Orders.Id_P
ORDER BY Persons.LastName


- 有时为了得到完整的结果,我们需要从两个或更多的表中获取结果。我们就需要执行 join。 数据库中的表可通过键将彼此联系起来。主键(Primary Key)是一个列,在这个列中的每一行的值都是唯一的。在表中,每个主键的值都是唯一的。这样做的目的是在不重复每个表中的所有数据的情况下,把表间的数据交叉捆绑在一起。上面的例子中使用的 INNER JOIN(内连接),JOIN默认使用内连接,可以省略INNER。 我们还可以使用其他几种连接。
LEFT JOIN
//使用left join查询,只要左表有匹配的条件,就会生成一行,右表的列值为空。
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
LEFT JOIN Orders
ON Persons.Id_P=Orders.Id_P
ORDER BY Persons.LastName



RIGHT JOIN
//使用right join查询,只要右表有匹配的条件,就会生成一行,左表的列值为空。
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
RIGHT JOIN Orders
ON Persons.Id_P=Orders.Id_P
ORDER BY Persons.LastName

FULL JOIN
//使用full join查询,只要其中一个表中存在匹配,就会生成一行,另一个表的列值为空。
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
FULL JOIN Orders
ON Persons.Id_P=Orders.Id_P
ORDER BY Persons.LastName
- JOIN: 如果表中有至少一个匹配,则返回行(INNER JOIN 与 JOIN)
- LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN: 只要其中一个表中存在匹配,就返回行
ALTER
alter table urls add created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP;
#增加一列
alter table test modify content char(10)
#修改表列类型

4、python操作MySQL数据库
参考文献:https://www.cnblogs.com/whatisfantasy/p/6134660.html
在操作数据库的时候,python2中一般使用mysqldb,但在python3中已经不在支持mysqldb了,我们可以用pymysql和mysql.connector。本文的所有操作都是在python3的pymysql下完成的。python -m pip install pymysql
mysql -u root -p
using mysql;
select host,user from mysql.user;
mysql的host、user、password等信息。

查询
conn=pymysql.connect(host='localhost',user='root',passwd='123456',db='scraping');
cur=conn.cursor();#获取方法,创建游标
sql='select * from urls';
recount=cur.execute(sql);#操作execute()方法写入sql语句
data=cur.fetchall(); # 返回数据,返回的是tuple类型
print data;
conn=pymysql.connect(host='localhost',user='root',passwd='123456',db='scraping')用于创建数据库的连接,里面指定参数(用户名,密码,主机信息)。cur=conn.cursor()通过获取的数据库连接conn下的cursor()方法来创建游标,之后通过游标操作execute()方法写入纯SQL语句。完成MySQL数据库操作后,需要关闭游标cur和连接conn。
插入数据
conn=pymysql.connect(host='localhost',user='root',passwd='123456',db='scraping');
cur=conn.cursor();
sql1='insert into urls(url,content)values(%s,%s)';
params=('www.sinlang.com','新浪微博');
recount=cur.execute(sql1,params);
##executemany 批量插入
li=[('www.blogs.com','批量插入的第一个'),('www.sou.com','批量插入的第二个')];
sql2='insert into urls(url,content)values(%s,%s)';
recount=cur.executemany(sql2,li);
sql3=sql='select * from urls';
recount=cur.execute(sql3);
data=cur.fetchall();
conn.commit;
cur.close;
conn.close;
print data;
#返回的都是元组((1,'','',time),(2,'','',time)...(6,'','',time));
- 其中commit只要执行一次,以上都是返回元组。
插入数据,返回dict类型的数据
conn=pymysql.connect(host='localhost',user='root',passwd='123456',db='scraping');
cur=conn.cursor(cursor=pymysql.cursors.DictCursor);# 参数设置
sql='select * from urls';
recount=cur.execute(sql);
data=cur.fetchall();
cur.close();
conn.close();
print recount;
print data;
#返回的是列表含字典[{u'url': 'www.baidu.com', u'content': 'xxx', u'id': 1, u'created_time': datetime.datetime(2018, 8, 22, 22, 2, 23)}, {xxx}, {xxx}];
fechone来逐条获取数据或者for循环
- for 循环获取数据
conn=pymysql.connect(host='localhost',user='root',passwd='123456',db='scraping');
cur=conn.cursor(cursor=pymysql.cursors.DictCursor);
sql='select * from urls';
recount=cur.execute(sql);
data=cur.fetchall();
for i in range(len(data)):
print data[i]
cur.close();
conn.close();
print recount;
- fechone来逐条获取数据
conn=pymysql.connect(host='localhost',user='root',passwd='123456',db='scraping');
cur=conn.cursor(cursor=pymysql.cursors.DictCursor);
sql='select * from urls';
recount=cur.execute(sql);
cur.close();
conn.close();
print recount;
for i in range(recount):
data=cur.fetchone();
print data;
两种方法获取结果都如下:

5、爬取网页数据存入MySQL数据库
(1) 在cmd 数据库中先创建database 和相应表;
create database anjuke;
use anjuke;
create table anjuke (id int not null Auto_increment,house_title varchar(1000) not null,house_layout varchar(1000) not null,house_area int not null,house_levers int not null,brokername varchar (1000),address varchar(2000),price int not null,primary key(id));

(2)将数据插入数据库中,爬取的数据格式如下[{},{},{},{}]。for循环列表,提取每一个字典中的信息,建立sql语义传参至execute中。
conn=pymysql.connect(host='localhost',user='root',passwd='123456',db='anjuke');
cur=conn.cursor();
for item in all_house:
house_title=item['house_title'];
house_layout=item['house_layout'];
house_area=item['house_area'];
house_levers=item['house_levers'];
brokername=item['brokername'];
house_address=item['house_address'];
price=item['price'];
sql='insert into anjuke(house_title,house_layout,house_area,house_levers,address,brokername,price) values (%s,%s,%s,%s,%s,%s,%s)';
#parme=(house_title,house_layout,house_area,house_levers,house_address,brokername,price);
#cur.execute(sql,parme);
cur.execute(sql,(house_title,house_layout,house_area,house_levers,house_address,brokername,price));
conn.commit();
cur.close();
conn.close();

(3) 读取存入MySQL数据库de网页爬取数据,可以[{},{},{}...{}]或者{}/n{}/n{}/n.../n{}形式输出。
conn=pymysql.connect(host='localhost',user='root',passwd='123456',db='anjuke');
cur=conn.cursor(cursor=pymysql.cursors.DictCursor);
sql='select * from anjuke';
cur.execute(sql);
conn.close();
cur.close();
data=cur.fetchall();#[{},{},{}...{}]
print data;
conn=pymysql.connect(host='localhost',user='root',passwd='123456',db='anjuke');
cur=conn.cursor(cursor=pymysql.cursors.DictCursor);
sql='select * from anjuke';
recount=cur.execute(sql);
conn.close();
cur.close();
for i in range(recount):
data=cur.fetchone();
print data;
- 可close()后,再对cur进行data的输出。

总结 NOTE
- 数据存至txt csv有固定格式,记住就好
- 存到mysql,主要是连接数据库:
conn=mysql.connect()、获取游标:cur=conn.cursor、对数据库操作:cur.execute(sql)、获取数据库:cur.fetchall()四个操作进行数据库操作。一般获取后,可以不用commit,存入数据等需要conn.commit(),但都要conn.close(),cur.close()。 - 另外深入可参考:http://www.runoob.com/python/python-mysql.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号