爬虫 处理登陆表单
在客户端向服务器提交http请求的时候,两种最常用的方法是GET和POST。按照规定,get请求只应用于获取数据,因此一般都是用requests.get()。相对于GET请求,POST请求则用于提交数据。对登陆表单的处理,每次登陆可以直接处理登陆表单或者选择在第一次登陆后,保存cookies等信息,下次可直接登陆。以下内容主要介绍直接处理表单的,获取目标页面的url的方法。
1、直接处理登陆表单(即处理需要登录名、登陆密码的网页)
参考书籍:Python网络爬虫从入门到实践中http://www.santostang.com./wp-login.php;
用户名:test;密码:a12345;
参考网页:https://www.cnblogs.com/ddddfpxx/p/8624715.html
登陆表单分为两步:
-
研究网站登陆表单,构建POST请求的参数字典;
-
提交POST请求;
(1)参数字典
构建参数字典主要是4个部分,都是 键值对的形式,通过查询网页,拣选对应的键和值;
- 用户名 name 的属性值 作为键值对中的key(用户需输入的用户名则为value)
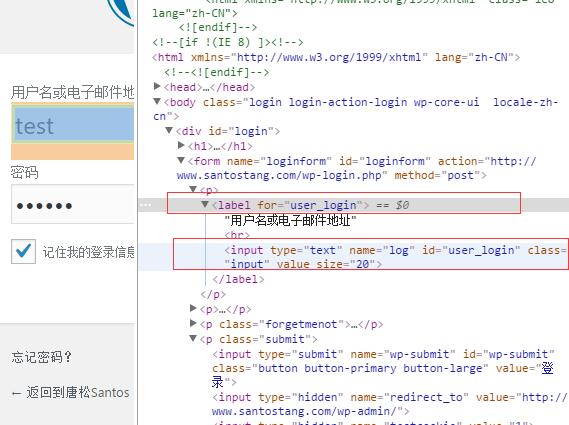
如上图,F12 点选用户名框,name的属性值为"log",以此作为key;value 为用户实际名。so 'log'='a12345';
- 用户密码 name的属性值 作为键值对中的key(用户需输入的用户名则为value)
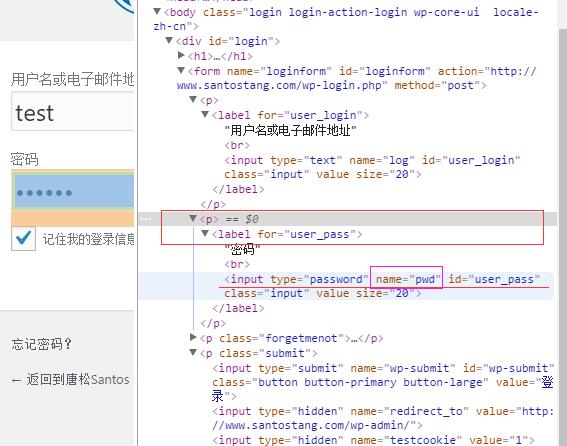
如上图,F12 点选密码框,name的属性值为"pwd",以此作为key;value 为用户实际名。so 'pwd'='test';
- 记住登陆密码 name的属性值 作为键值对中的key,value的属性值作为 键值对中的value
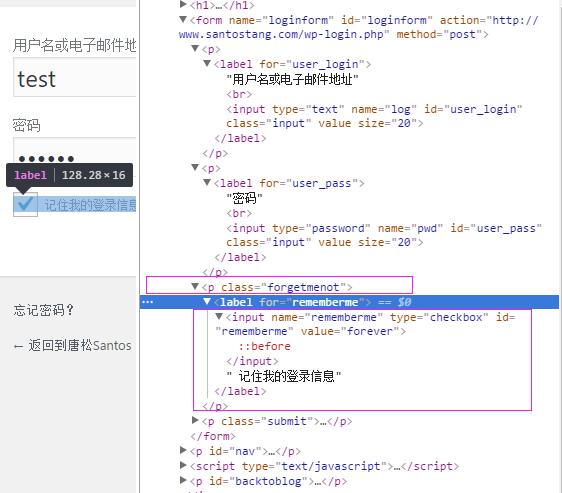
如上图,F12 点选 记住密码框,name的属性值为"rememberme",value的属性值为"forever"。so 'rememberme'='forever';
- 在登陆表单中,有些key值在浏览器中设置了hidden值,所以只提交用户名、密码和记住密码不能直接登陆,还需要审查出来。

如上图,F12 点选 记住登陆框,input type的属性值为"hidden"的有两条。第一条,name属性值为"redirect_to",value的属性值为"http://www.santostang.com/wp-admin/",so 'redirect_to'='http://www.santostang.com/wp-admin/';第二条,name属性值为"testcookie",value的属性值为"1" so 'testcookie'='1';
综上所述:建立参数字典,如下:
post_data={
'log':'a12345',
'pwd':'test',
'rememberme':'forever',
'redirect_to':'http://www.santostang.com/wp-admin/',
'testcookie':'1'
};
(2)提交参数字典
提交POST请求,就可以登陆网站了。首先需要导入requests库,并创建一个session对象。用户浏览某个网站时,从进入网站到关闭浏览器所经过的这个过程,session对象会存储特定用户会话所需要的属性和配置信息。 session 对保存和操作cookies非常重要。
#encoding:utf-8;
import requests;
post_link='http://www.santostang.com./wp-login.php';#登陆页面 url
agent='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36';
host='www.santostang.com';
oringin='http://www.santostang.com';
cookied='wordpress_test_cookie=WP+Cookie+check';
headers={'User-Agent':agent,'Host':host,'Origin':oringin,'Referer':post_link,'Cookie':cookied};#提交者
post_data={
'log':'test',
'pwd':'a12345',
'wp-submit':'登录',
'redirect_to':'http://www.santostang.com/wp-admin/',
'testcookie':'1'
};
login_page=requests.post(post_link,data=post_data,headers=headers,allow_redirects=False);
profile_page=login_page.headers['location'];
print (login_page.status_code);## 回复302
print (login_page.headers['location']);## 回复http://www.santostang.com/wp-admin/profile.php
提交post的过程很简单,即先建立各个参数,然后使用post方法,参数是post_url,data是postdata,headers是headers,allow_redirects。headers中,User-Agent、Host、Origin(比host多了个http?)、Referer(就是登陆页面的url)、cookies。
- 查看登陆表单是否请求成功,可查看响应状态
login_page.status_code。返回值200,表请求成功;303,表重定向;400,表请求错误;401,表未授权;403,表禁止访问;404,表文件未找到,500,表服务器错误。
表单登陆页面:http://www.santostang.com/wp-login.php
表单中的重定向网址:http://www.santostang.com/wp-admin/
登陆成功目标网址:http://www.santostang.com/wp-admin/profile.php
NOTE1
-
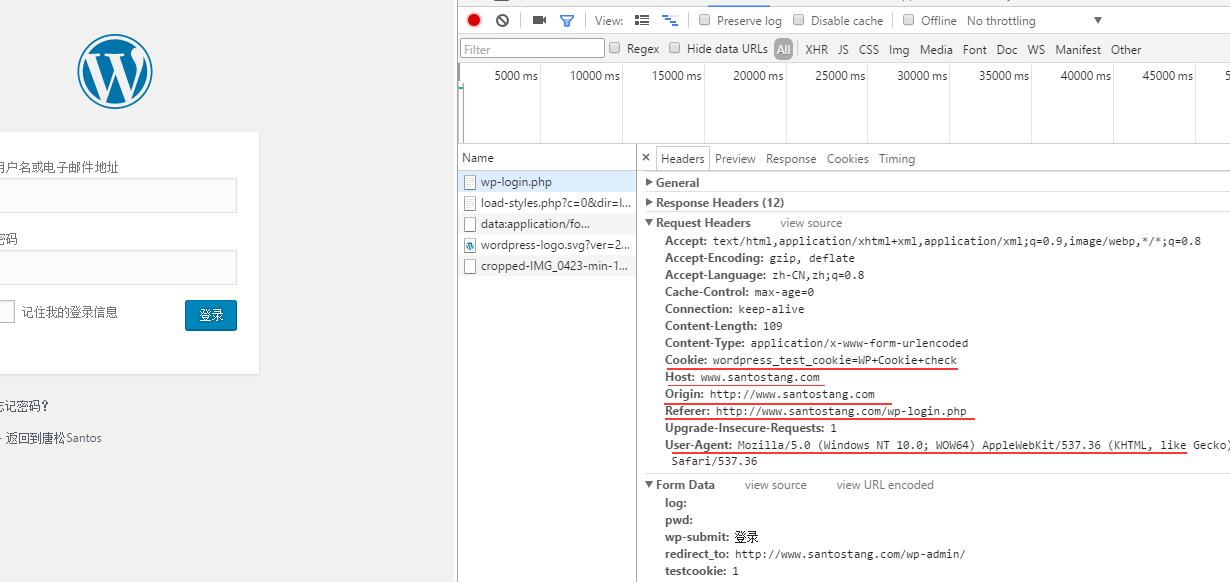
获得Headers的参数的捷径, 在登录页,不输入用户及用户名,点击登录框,查看F12 中 request headers,post_data的参数,如上,headers中的cookied也必须有。
login_page=requests.post(post_link,data=post_data,headers=headers,allow_redirects=False)中的allow_redirects=False,必须有,不然
login_page.status_code的返回值为200,其实去了post_data中的redirect_to 重定向网页中,而不是跳转到目标网页;添加该属性,返回的是302,完成了post的第一次请求,其respons header中location属性值即为profile的url,可以此url向服务器发送第二次请求。即可以此url采集数据。
-
但是我不懂,资料中对headers的参数及post参数的设定不明确,漏掉了cookie及allow_redirects 导致刚开始一直进入重定向网址,而获取不到目标网页的网址。还是官方文档比较靠谱。http://www.python-requests.org/en/master/user/quickstart/#redirection-and-history
2、处理cookies(记住cookies,登陆)
参考网址:https://blog.csdn.net/zhu_free/article/details/50563756
通过session,可记录网页cookies中用户信息,以避免每次登陆的时候都要输用户名及密码。只要将第一次接触的网页cookies 用session 存储,或者将多次网页的cookies从session中提取,即可。
3、疑难杂症
(1)一直搞不懂,网页network headers中response headers和requests headers 是干蛤的。
http://www.santostang.com/wp-login.php
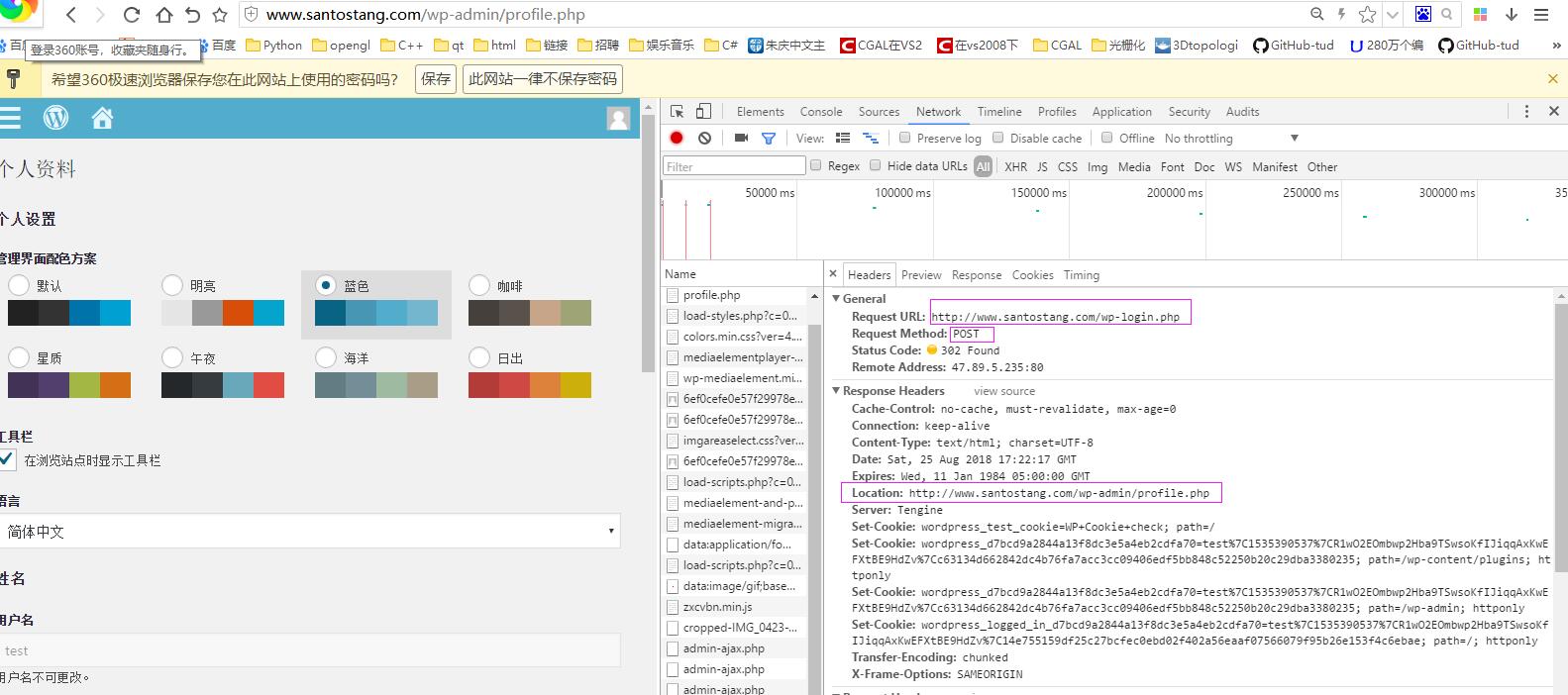
post第一次请求 http://www.santostang.com/wp-admin/profile.php
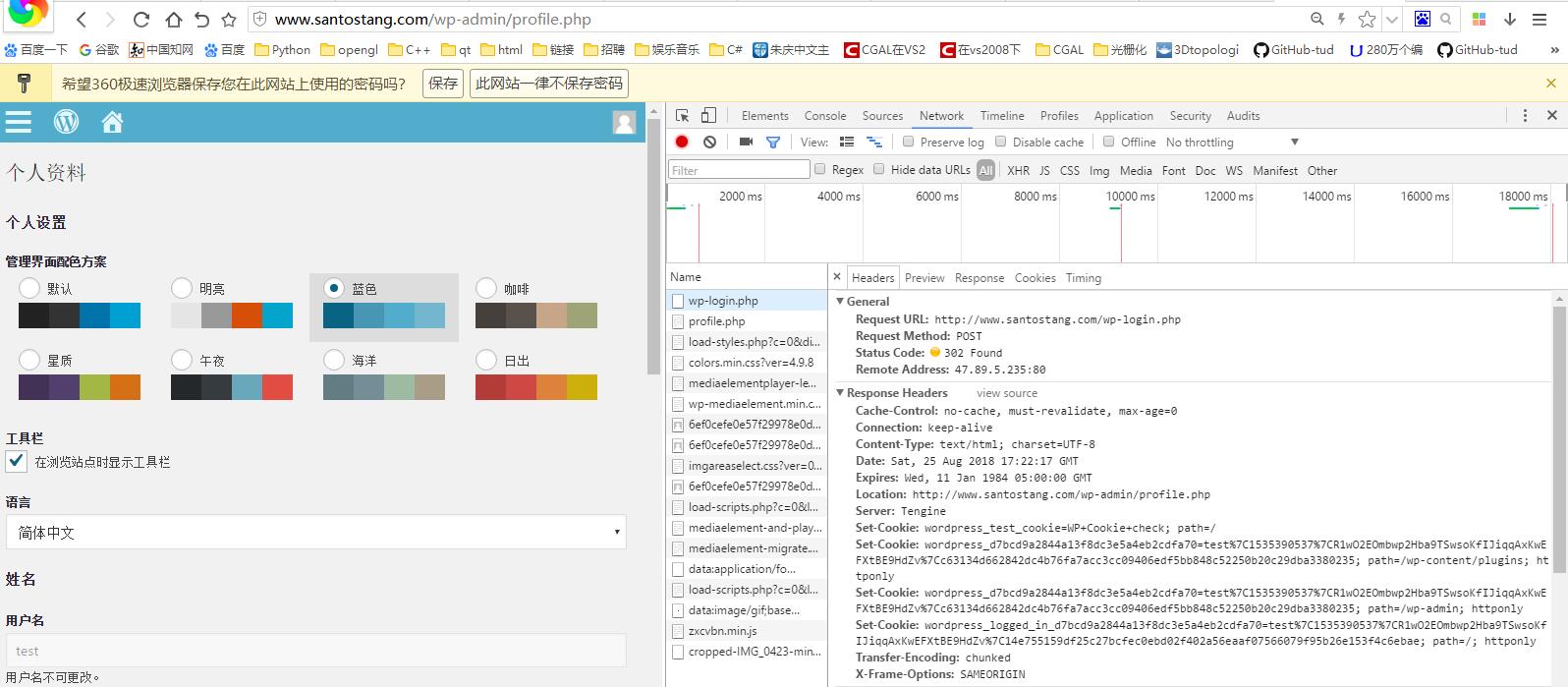
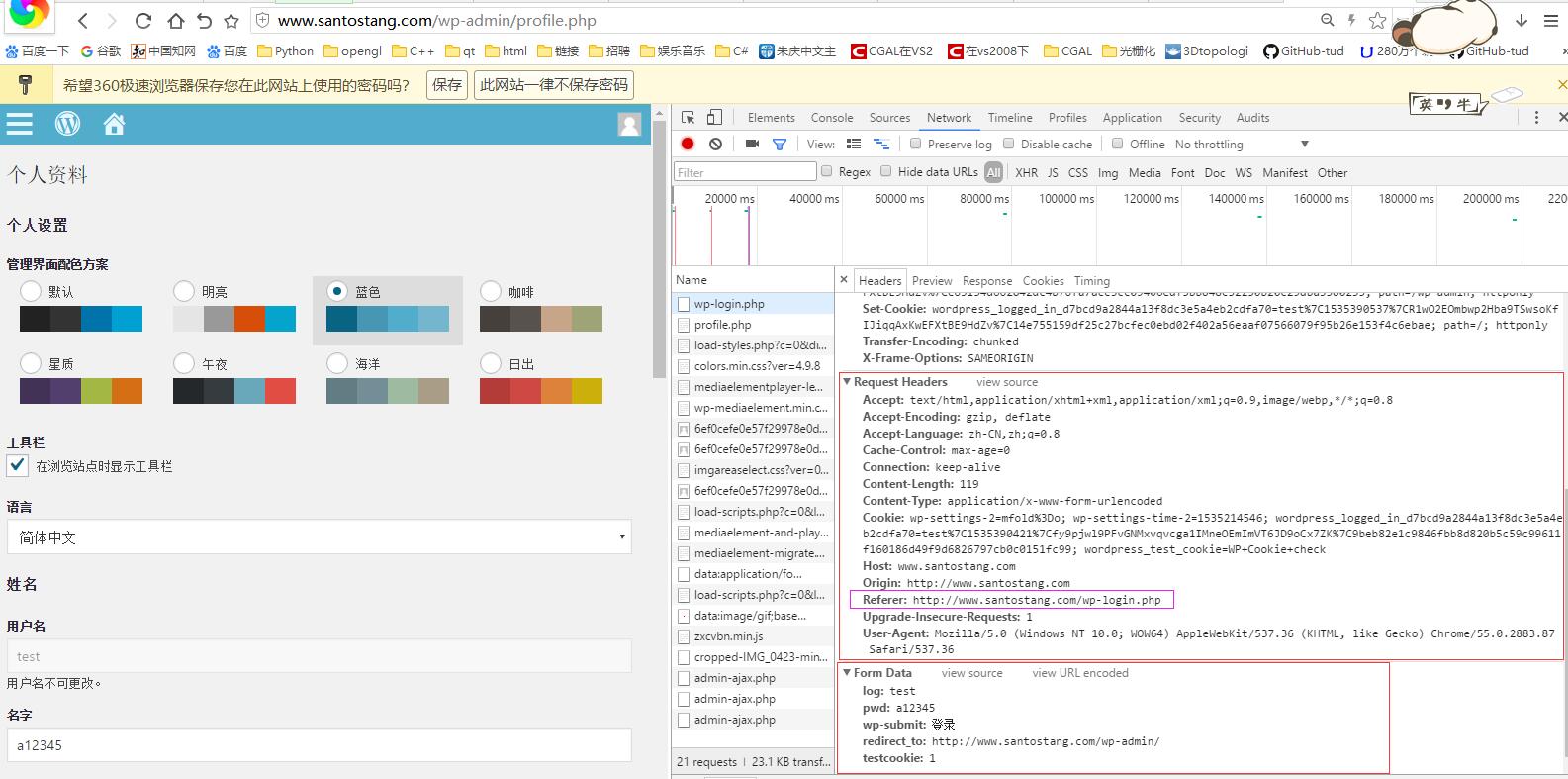
登陆后http://www.santostang.com/wp-admin/profile.php
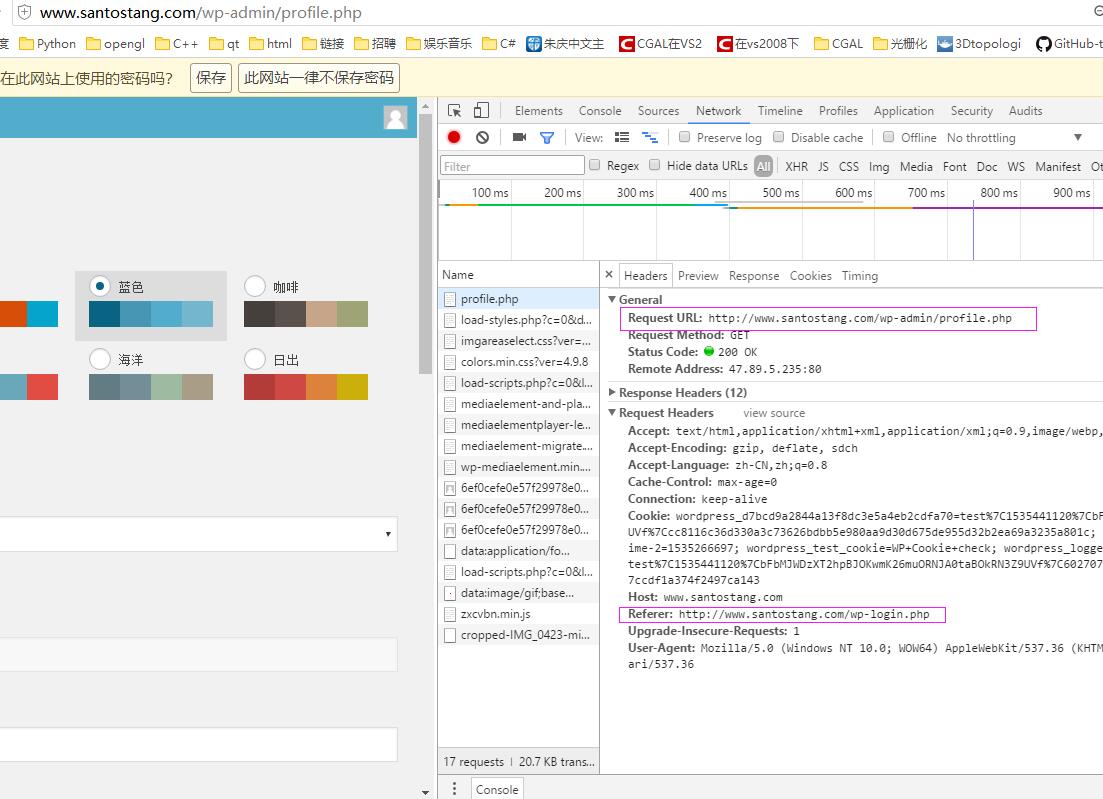
-
每个url,都会有requests和respons,其实每次请求都会用到这两个。requests 可以理解是向服务器发送请求需要的,而respon是服务器接收到请求后,反馈回来的。
-
在表单登陆的过程中,由login网页到进入profile的过程。由图二可知,所以我们第一次从login进入到profile的request method 是post,status code 是302 Found;所以我们在login到profile需要用post,而不是get。
-
post请求进入profile的过程我们可以用两次请求理解。第一次以login 这个url想服务器发送请求返回login 的response有一个状态码 302 foubd、location和cookies(其实就是图二的respons 内容);第二次用login response headers 的这个location url再向服务器发送请求,返回的就是想进入的location url界面。
-
由上可知,进入到profile url 前,想象增加一个中间页面,如图三,虽然浏览器中已经是pofile的地址,但其general 的request url 还是login ,其respons可以理解为post login url第一次请求后服务器返回的内容(location、cookies 已找到),request可以理解以location、cookies第二次向服务器发送请求的要求(所以Referer是login,并且在我们post请求的headers 参数值中),且增加一块From data,就是post的参数字典。但是进入location url ,如图四,其general url 变成 profile 、request method 为get、status code 为200 。
-
一个重定向网址,就是为了记住登录前的网页,这样,不会每次登陆后都回到 首页。
(2)cookies
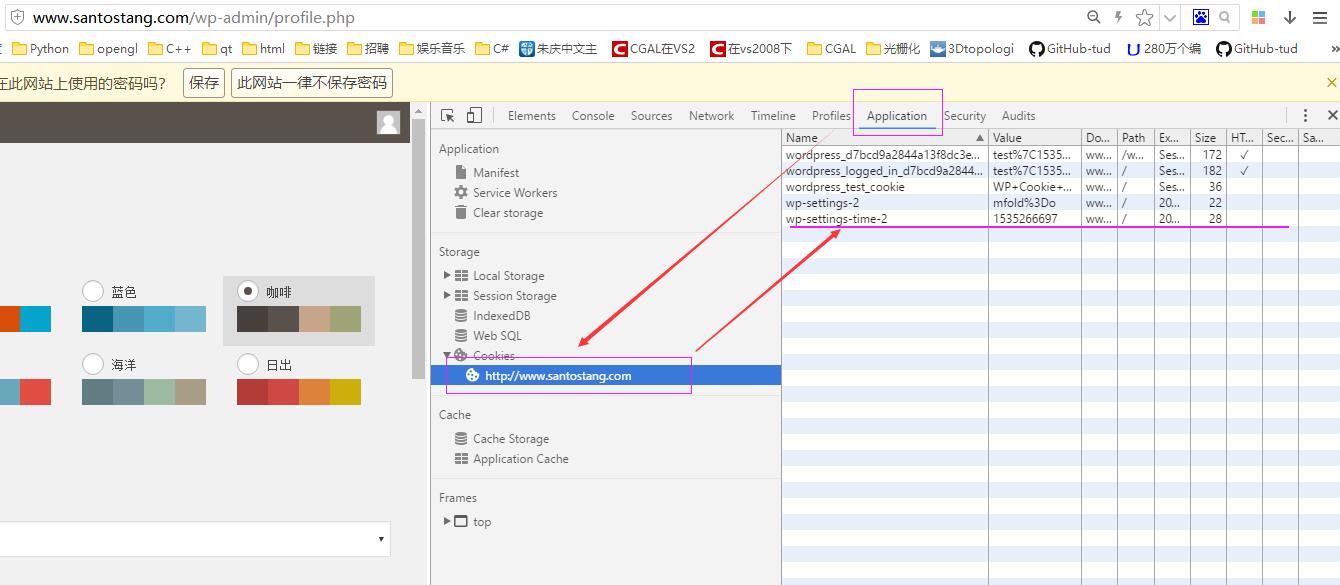
其实cookies就是每个登陆的钥匙。
(3)其实还是不是很懂这种网页的东西,记得很绕,不是理论,就是自己的催眠自己的理解。希望不要误导到人。慎入,哈哈。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号