C#+HtmlAgilityPack—糗事百科桌面版V2.0
最近在浏览以前自己上传的源码,发现在糗事百科桌面端源码评论区中,有人说现在程序不能用了。查看了一下源码运行情况,发现是正则表达式解析问题。由于糗百的网页版链接和网页格式稍有变化,导致解释失败。虽然可以通过更改正则表达,重新获网页的信息,但比较复杂,出错率较高(技术有限)。因此第二个版本采用HtmlAgilityPack类库解析Html。
1. HtmlAgilityPack类库
HtmlAgilityPack是一个解析Html文档的一个类库,当然也能够支持XML文件,该类库比.NET自带的XML解析库要方便灵活多,主要是HtmlAgilityPack支持XPath路径表达式,通过XPath表达式能够快速定位到文档中的某个节点。有了它,解析网页不成问题,接下来简述一下HtmlAgilityPack的使用方法。
HtmlAgilityPack 有3个比较重要的类型。
- HtmlDocument : 加载Html文档(string),并解析成有层次的对象结构。
- HtmlNode : 元素节点类型,该类型提供许多非常有用的方法,下面会将重点的方法都介绍一遍。
- HtmlNodeCollection : html节点集合类型。
通过例子来讲解这三个类型的使用,可能会更加的清晰,html源码,如下:
<div>
<div id="content" class="c1">
<p id="p1" class="pStyle" title="HtmlAgility">段落1</p>
<p id="p2" class= "pStyle">段落2</p>
</div>
<div id="content2" class="c1">
<p class="pStyle">段落3</p>
<span>
<h1>hello</h1>
<span>
<div>
</div>
使用HtmlDocument类型解析上面的html源码。
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(htmlStr);
HtmlNode rootNode = htmlDoc.DocumentNode;//获取文档的根节点
通过该类型的 LoadHtml 方法解析html字符串,然后获取html文档的根节点,当然该类型还有一个 Load方法,支持从文件中,url 或者流中加载html文档。获取了HtmlNode 类型的根节点之后,利用根节点与XPath路径表达可以获取文档中任意的节点。
获取所有class=pStyle的p节点
string xpath = "//p[@class='pStyle']";
HtmlNodeCollection pNodes = rootNode.SelectNodes(xpath);
利用HtmlNode类型的SelectNodes(xpath)方法可以获取所有class为pStyle的p标签。但是这次会把文档中所有的样式类为pStyle的p标签都获取到。如果只想获取“div id="content"”容器下面的。只需要更改xpath路径表达式即可做到。
string xpath = "//div[@id='content']/p[@class='pStyle']";
HtmlNodeCollection pNodes = rootNode.SelectNodes(xpath);
通过在之前的路径上加上div[@id='content']进行限定即可。如果只想找"div id="content"”容器下面的class=pStyle 且 title=HtmlAgility的p标签代码如下。
string xpath = @"//div[@id='content']/p[@class='pStyle' and @title='HtmlAgility']";
HtmlNodeCollection pNodes = rootNode.SelectNodes(xpath);
通过XPath可以很方便的定位到文档中的节点,并通过节点类型的属性或者方法来获取节点的属性值和文本值以及内部html。
获取节点的文本和class属性值,代码如下:
string xpath = @"//div[@id='content']/p[@class='pStyle' and @title='HtmlAgility']";
HtmlNodeCollection pNodes = rootNode.SelectNodes(xpath);
string nodeText=pNodes[0].InnerText;
string classValue = pNodes[0].GetAttributeValue("class", "");
HtmlNode类型的属性和方法如下:
InnerText : 节点的文本值
InnerHtml: 节点内部的html字符串
GetAttributeValue :通过节点的属性名字获取属性值,该方法有三个重载的版本,可以获取分别返回bool,string、int 三种类型的属性值。
上面都在简介HtmlAgilityPack类库的使用,下面简单介绍一下XPath。
- // 所有后代节点,从根部开始,跟SelectNodes方法前面的节点没关系 例子://div: 所有名为div的节点
- . 表示当前节点,与SelectNodes方法前面的节点相关 例子:./div :当前节点下的所有名为div节点
- .. 表示父节点,与SelectNodes方法前面的节点相关 例子: ../div :当前节点的父节点下的div节点
- @ 选取属性 例子://div/@id:所有包含id属性的div
XPath不仅仅可以通过路径定位,还可以对定位后的节点集做一些限制,使得选择更加精准。
- /root/book[1] 节点集中的第一个节点
- /root/book[last()] 节点集中最后一个节点
- /root/book[position() - 2] 节点集中倒数第三个节点集
- /root/book[position() < 5] 节点集中前五个节点集
- /root/book[@id] 节点集中含有属性id的节点集
- /root/book[@id='chinese'] 节点集中id属性值为chinese的节点集
- /root/book[price > 35]/title 节点集中book的price元素值大于35的title节点集
XPath对于路径匹配,谓语限制都可以使用通配符。
- /div/* div节点下面的所有节点类型
- //div[@*] div下面的所有属性
此外XPath还能进行逻辑运算
- | ——例:/root/book[1] | /root/book[3]:两个节点集的合并—— (
+,*) - //div[@id='test1' and @class='divStyle']—— 找寻所有 id=test1 和class=divStyle 的div节点
- //div[not(@class)]——找寻不包括class属性div节点
(or, and, not, =, !=, >, <, >=)
最后在提供一个小技巧,在网页中打开开发者工具,可以直接定位到相应的html节点,然后右键可以直接获取该节点在文档中的XPath路径,如下图:
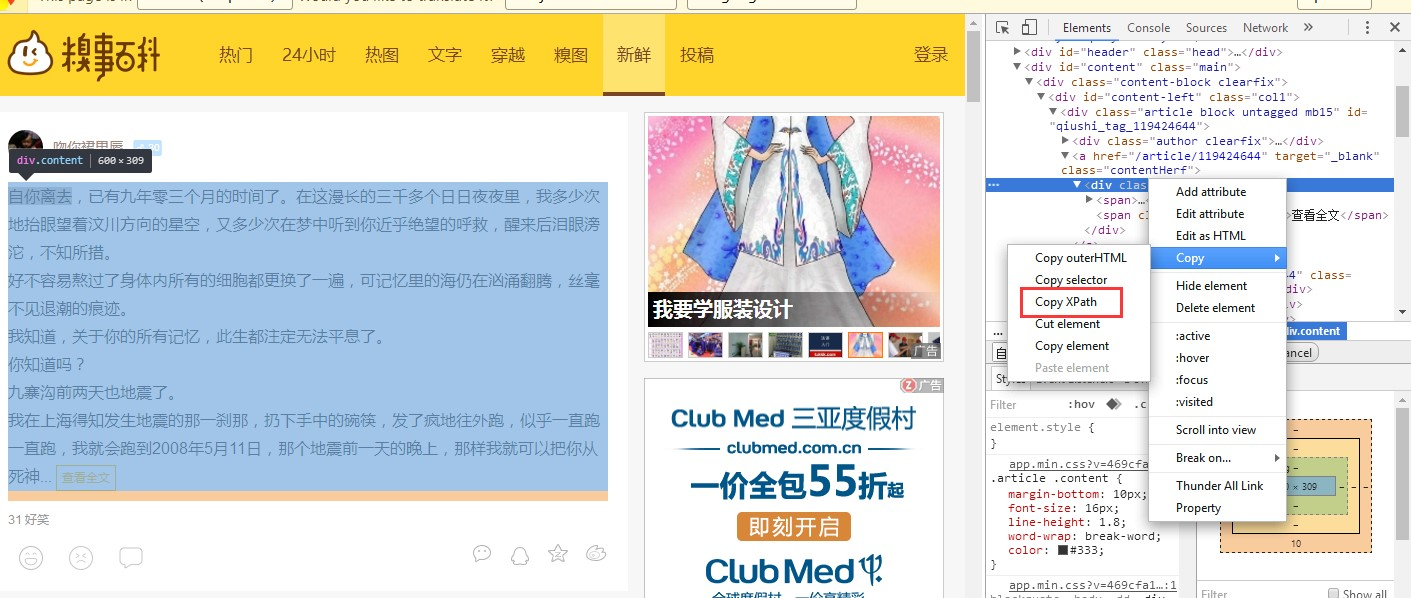
好了, HtmlAgilityPack类库的使用就介绍到这里。
2. 使用HtmlAgilityPack解析糗百
关于糗百的网页结构分析,在这篇文章使用HttpGet协议与正则表达实现桌面版的糗事百科 已经详细介绍了,在此就不在赘述了,下面简介一下抓取糗百段子的关键代码。
/// <summary>
/// 获取笑话列表
/// </summary>
/// <param name="htmlContent"></param>
public static List<JokeItem> GetJokeList(int pageIndex)
{
string htmlContent=GetUrlContent(GetWBJokeUrl(pageIndex));
List<JokeItem> jokeList = new List<JokeItem>();
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(htmlContent);
HtmlNode rootNode=htmlDoc.DocumentNode;
string xpathOfJokeDiv = "//div[@class='article block untagged mb15']";
string xpathOfJokeContent = "./a/div[@class='content']/span";
string xpathOfImg = "./div[@class='author clearfix']/a/img";
try
{
HtmlNodeCollection jokeCollection = rootNode.SelectNodes(xpathOfJokeDiv);
int jokeCount = jokeCollection.Count;
JokeItem joke;
foreach (HtmlNode jokeNode in jokeCollection)
{
joke = new JokeItem();
HtmlNode contentNode = jokeNode.SelectSingleNode(xpathOfJokeContent);
if (contentNode != null)
{
joke.JokeContent = Regex.Replace(contentNode.InnerText, "(\r\n)+", "\r\n");
}
else
{
joke.JokeContent = "";
}
HtmlNode imgornameNode = jokeNode.SelectSingleNode(xpathOfImg);
if (imgornameNode != null)
{
joke.NickName = imgornameNode.GetAttributeValue("alt", "");
joke.HeadImage = GetWebImage("http:"+imgornameNode.GetAttributeValue("src", ""));
joke.HeadImage = joke.HeadImage != null ? new Bitmap(joke.HeadImage, 50, 50) : null;
}
else
{
joke.NickName = "匿名用户";
joke.HeadImage = null;
}
jokeList.Add(joke);
}
}
catch{}
return jokeList;
}
下载图片的代码如下:
private static Image GetWebImage(string webUrl)
{
try
{
Encoding encode = Encoding.GetEncoding("utf-8");//网页编码==Encoding.UTF8
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(new Uri(webUrl));
HttpWebResponse ress = (HttpWebResponse)req.GetResponse();
Stream sstreamRes = ress.GetResponseStream();
return System.Drawing.Image.FromStream(sstreamRes);
}
catch { return null; }
}
需要注意的是:
获取糗百头像的地址为://pic.qiushibaike.com/system/avtnew/3281/32814675/medium/2017070317185381.JPEG" ,一定要在前面加上"http:" 才能正确的下载头像。
效果如下:
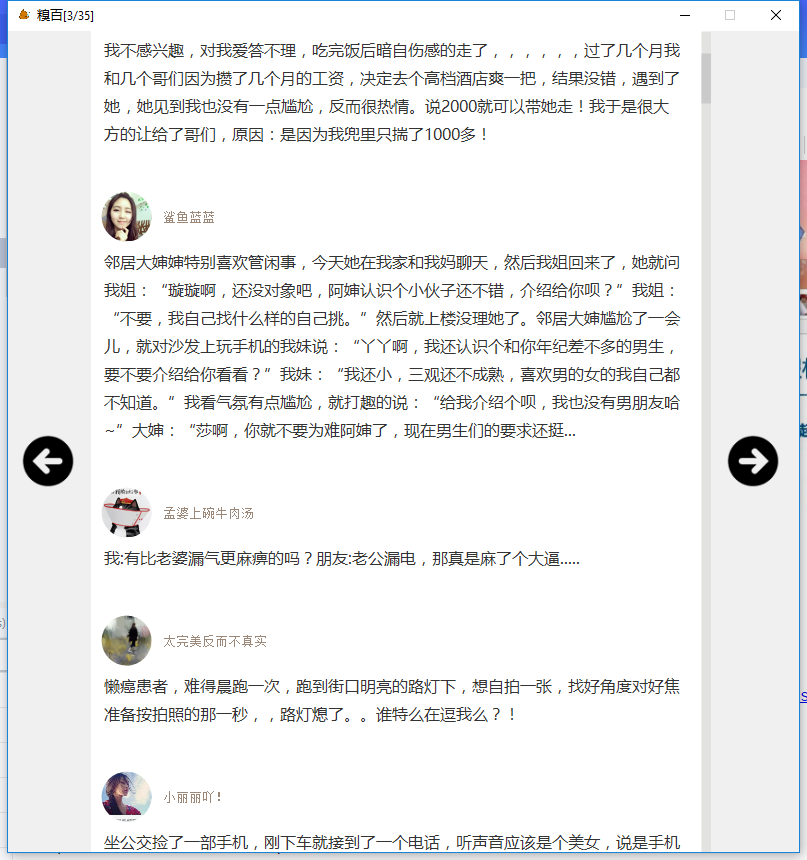
3. 小结
通过HtmlAgilityPack来解析文档,很轻巧灵活,主要是不容易出错。觉得这个解析包和Python的Beautiful Soup 库有异曲同工之妙,都是解析网页的好工具。
本文的源码下载链接:https://github.com/StartAction/qbDesktop

 浙公网安备 33010602011771号
浙公网安备 33010602011771号