
Nvidia GPU architecture
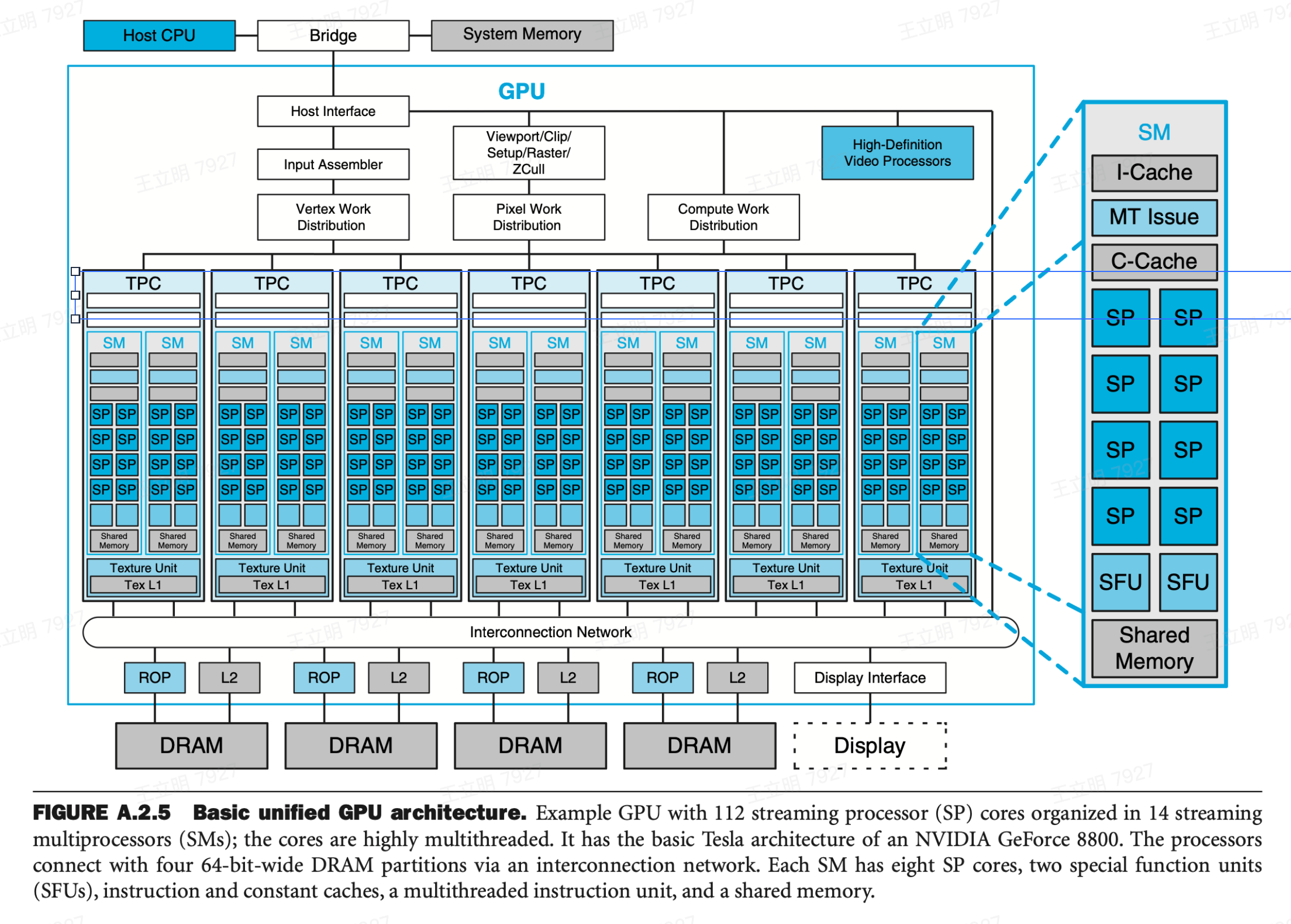
TPC texture/processor cluster
SM streaming multiprocessor
SP streaming processor 普通计算器mad之类的
SFU special function unit --超越函数。。。。三角函数 log 指数函数
ROP Raster Operation processor--做om阶段的很多事情 测试混合aa。。。。
L2 l2cache
DRAM 内存
I-cache instruction cache
C-cache constant cache
MT issue :multithreaded instruction fetch and issue unit --这货看名字像是为sp的task做调度的
https://www.cc.gatech.edu/fac/hyesoon/gputhread.pdf
mt issue给SM拿 一个instruction 给一个warp里面的所有sp用 这个instruction需要多个cycle才能执行完
一个sm一段时间会并行多个warp 因为资源约束和性能的缘故就需要调度
指令也属于一种资源,一个指令一般需要4cycle
以上是1.0版本的认识 可能需要迭代

fetch策略基本上是通过负载均衡让性能吞吐量最大化,让选到这个intruction可以被立刻执行 不stall
这事情和powervr的thread scheduling是一样的 想要的结果一样 这里手段可能更先进一些 前者像粗粒度的 后者simt 并发多线程
这里需要迭代
fetch有各种策略
比如轮询
比如挑最长时间没被fetch的
比如先挑剩下最多的
或者memory占用最多的
可以看到各种策略都是为了 更平衡
看上图那三个distribution TPC处理这三种工作 vertex pixel compute 是unified的架构
warp The set of parallel threads that execute the same instruction together in a SIMT architecture.
SIMD--vector
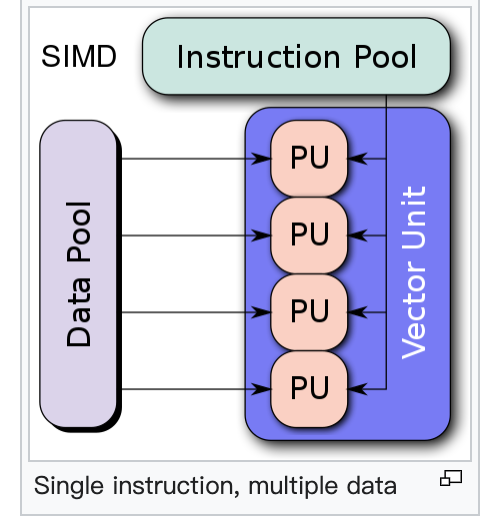
SIMT--scalor
Single instruction, multiple thread (SIMT) is an execution model used in parallel computing where single instruction, multiple data (SIMD) is combined with multithreading.
simt的warp理解起来一个很重要的点是 那四个cycles
一个instrucion 4 cycles
8 sp core x4
一段时间 32thread

一个sp里有64个thread 一个thread一个cycle可以跑一个scaler instruction

 浙公网安备 33010602011771号
浙公网安备 33010602011771号