Sentinel 热点参数限流
https://github.com/alibaba/Sentinel/wiki/%E7%83%AD%E7%82%B9%E5%8F%82%E6%95%B0%E9%99%90%E6%B5%81
何为热点?热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行限制。比如:
- 商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制
- 用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
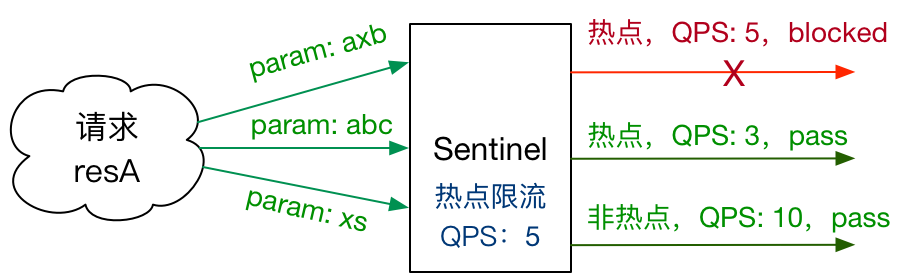
Sentinel 利用 LRU 策略统计最近最常访问的热点参数,结合令牌桶算法来进行参数级别的流控。热点参数限流支持集群模式。
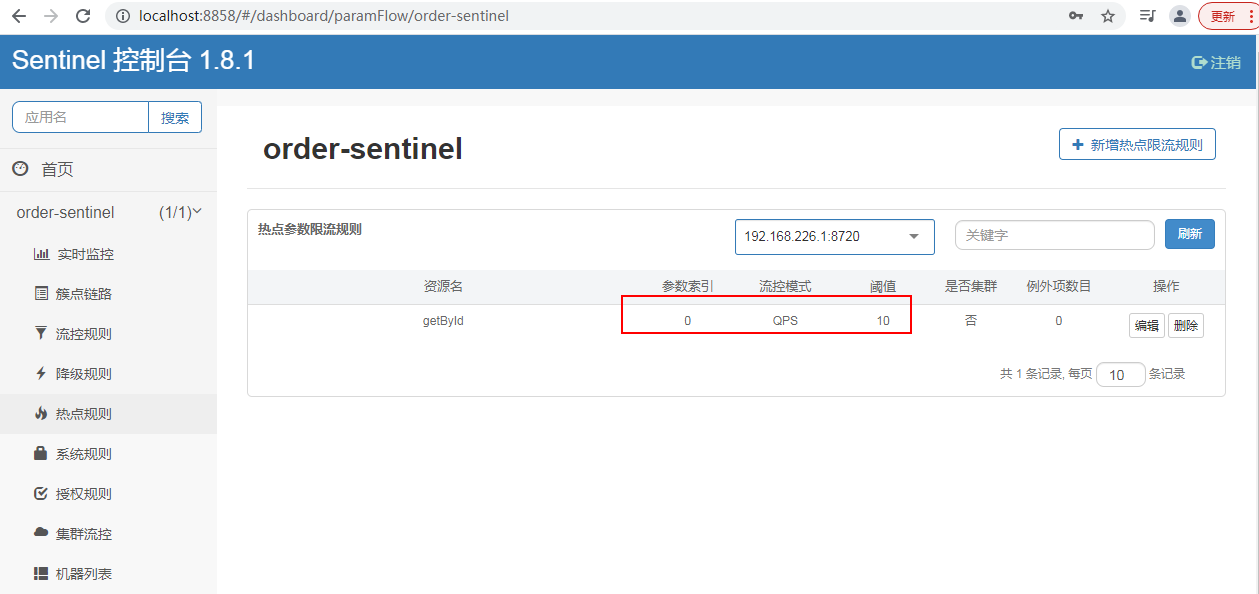
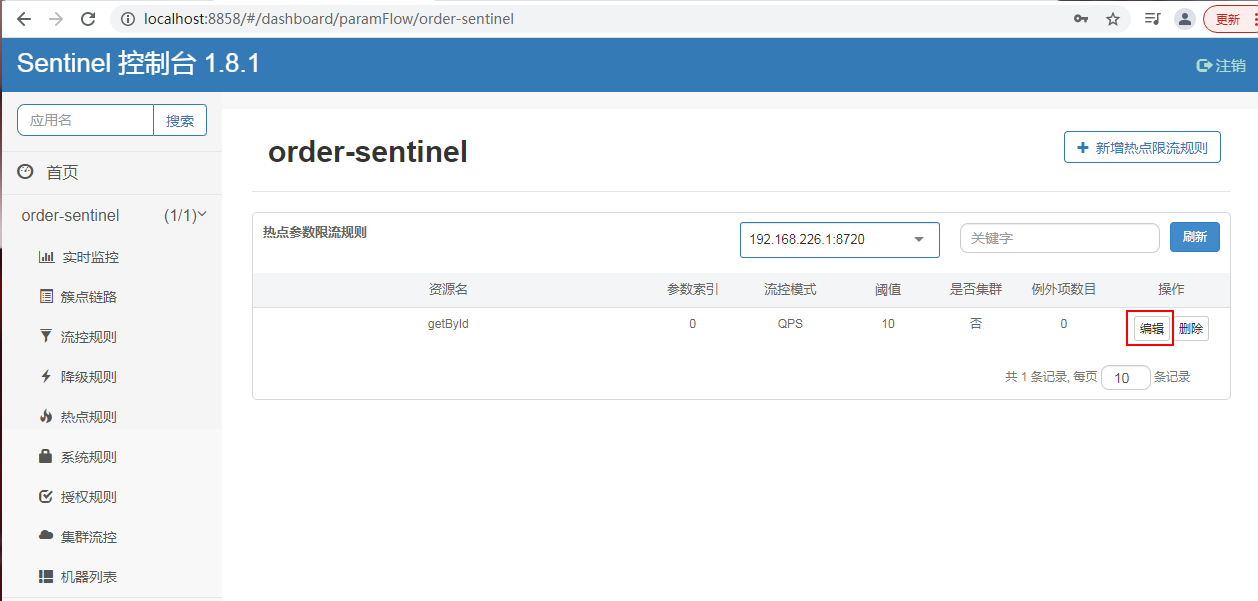
热点参数规则
热点参数规则(ParamFlowRule)类似于流量控制规则(FlowRule):
| 属性 | 说明 | 默认值 |
|---|---|---|
| resource | 资源名,必填 | |
| count | 限流阈值,必填 | |
| grade | 限流模式 | QPS 模式 |
| durationInSec | 统计窗口时间长度(单位为秒),1.6.0 版本开始支持 | 1s |
| controlBehavior | 流控效果(支持快速失败和匀速排队模式),1.6.0 版本开始支持 | 快速失败 |
| maxQueueingTimeMs | 最大排队等待时长(仅在匀速排队模式生效),1.6.0 版本开始支持 | 0ms |
| paramIdx | 热点参数的索引,必填,对应 SphU.entry(xxx, args) 中的参数索引位置 |
|
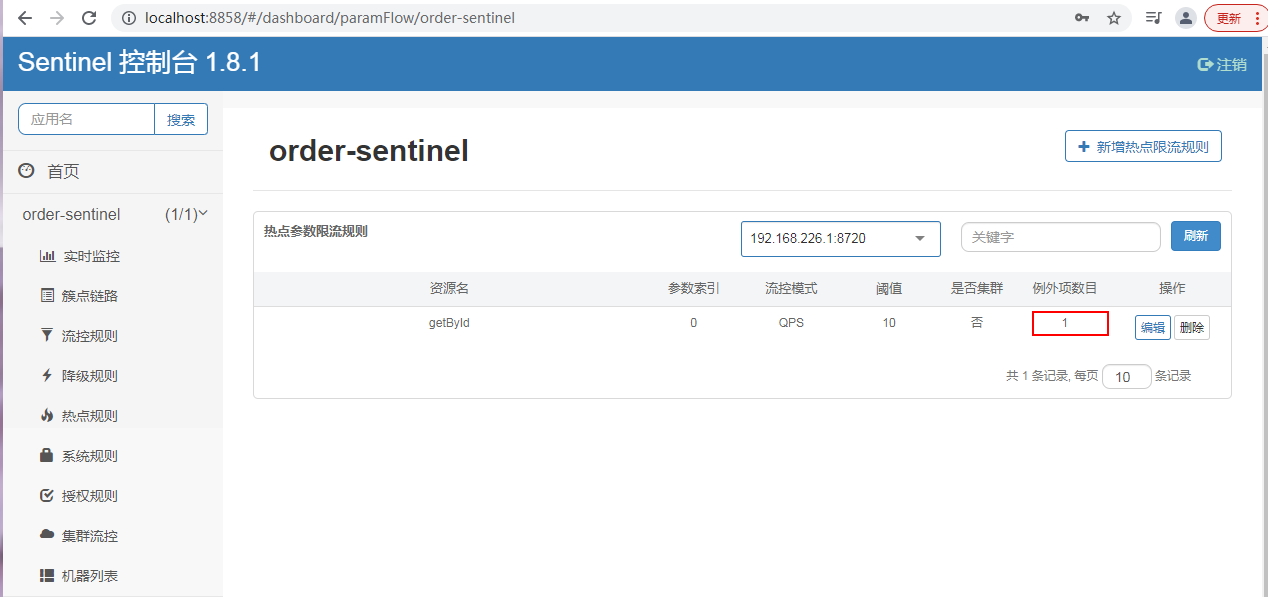
| paramFlowItemList | 参数例外项,可以针对指定的参数值单独设置限流阈值,不受前面 count 阈值的限制。仅支持基本类型和字符串类型 |
|
| clusterMode | 是否是集群参数流控规则 | false |
| clusterConfig | 集群流控相关配置 |
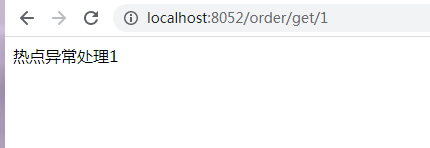
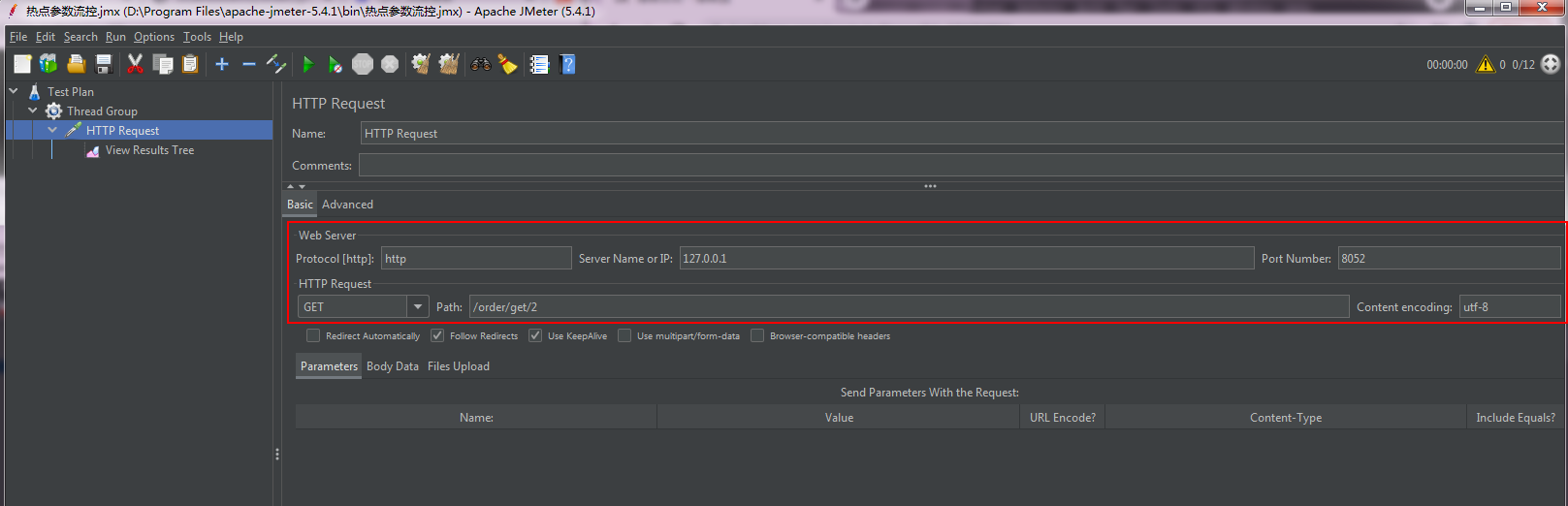
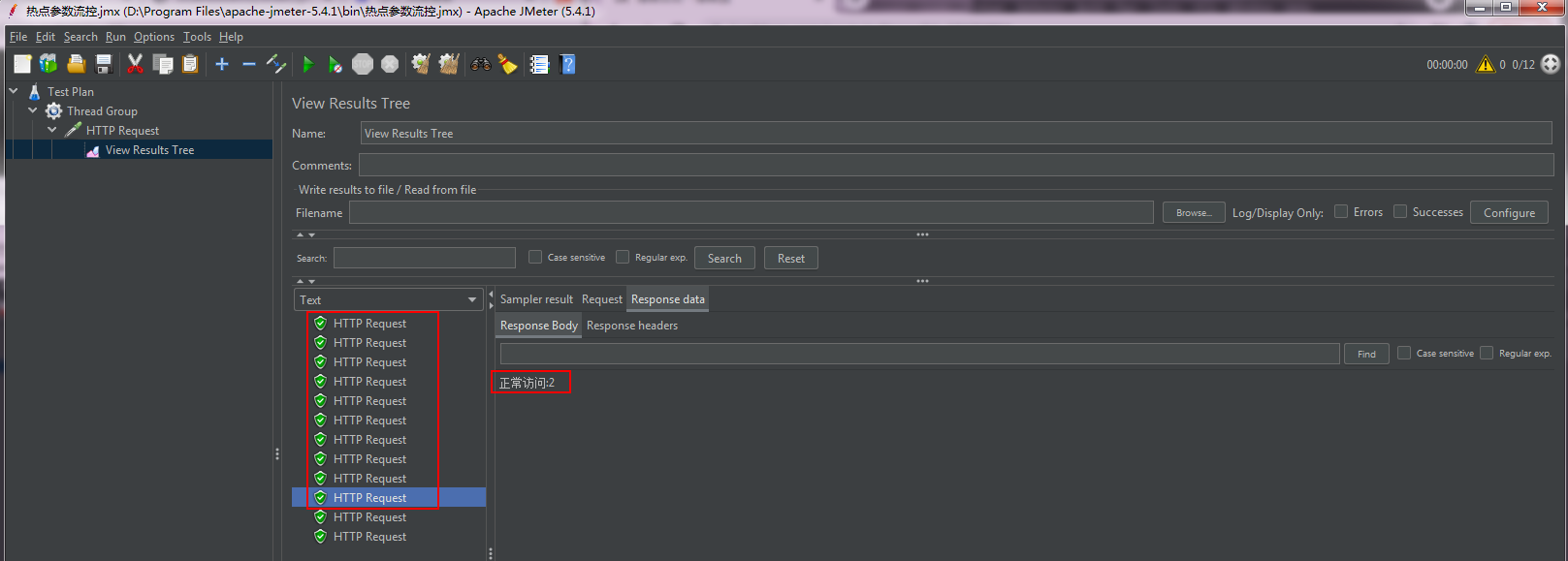
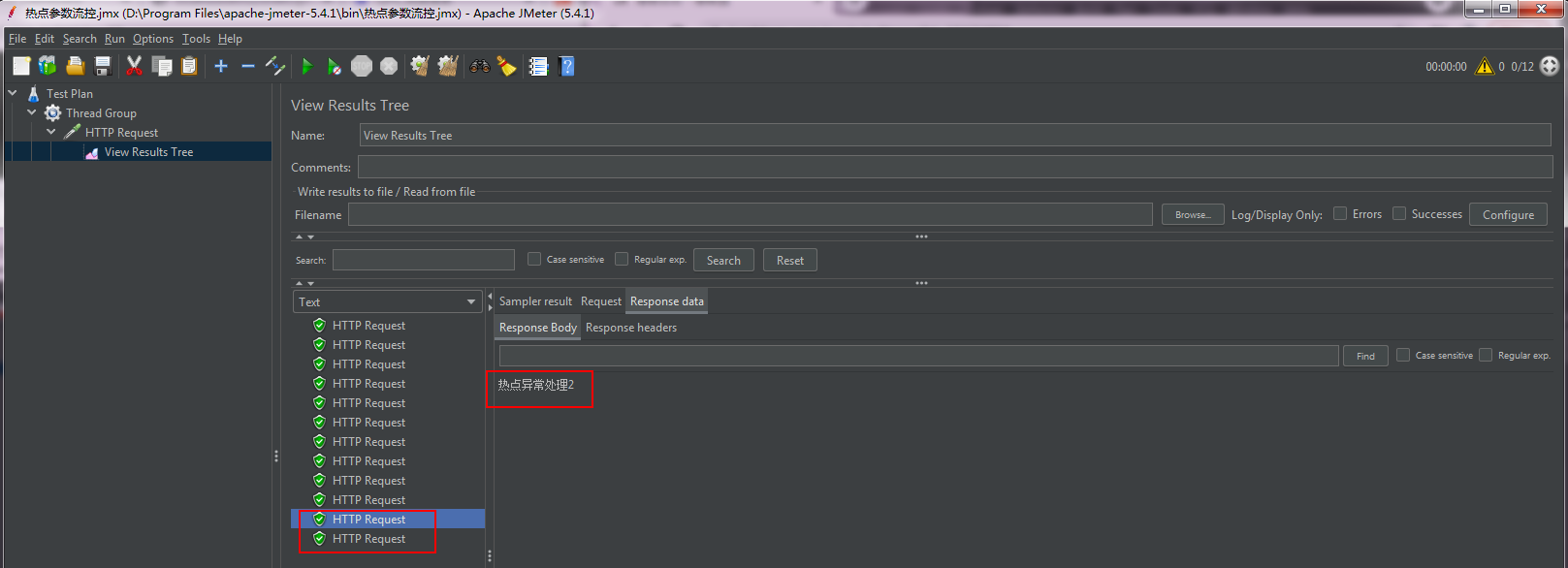
package com.wsm.order.controller; import com.alibaba.csp.sentinel.annotation.SentinelResource; import com.alibaba.csp.sentinel.slots.block.BlockException; import com.wsm.order.service.OrderService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import java.util.concurrent.TimeUnit; @RestController @RequestMapping("/order") public class OrderController { @Autowired OrderService orderService; @RequestMapping("/add") public String add(){ System.out.println("下单成功!"); return "生成订单"; } @RequestMapping("/get") public String get(){ System.out.println("查询订单!"); return "查询订单"; } @RequestMapping("/test1") public String test1(){ return orderService.getUser(); } @RequestMapping("/test2") public String test2(){ return orderService.getUser(); } @RequestMapping("/flow") // @SentinelResource(value = "flow",blockHandler = "flowBlockHandler") public String flow(){ System.out.println("========flow===="); return "正常访问"; } public String flowBlockHandler(BlockException e){ return "流控了"; } @RequestMapping("/flowThread") // @SentinelResource(value = "flowThread",blockHandler = "flowThreadBlockHandler") public String flowThread() throws InterruptedException { TimeUnit.SECONDS.sleep(5); System.out.println("flowThread正常访问"); return "正常访问"; } public String flowThreadBlockHandler(BlockException e){ return "flowThread流控了"; } @RequestMapping("/err") public String err() { int a=1/0; return "err"; } @RequestMapping("/get/{id}") @SentinelResource(value = "getById", blockHandler = "HotBlockHandler") public String getById(@PathVariable("id") Integer id) { System.out.println("正常访问:"+id); return "正常访问:"+id; } public String HotBlockHandler(@PathVariable("id") Integer id,BlockException e) { return "热点异常处理"+id; } }

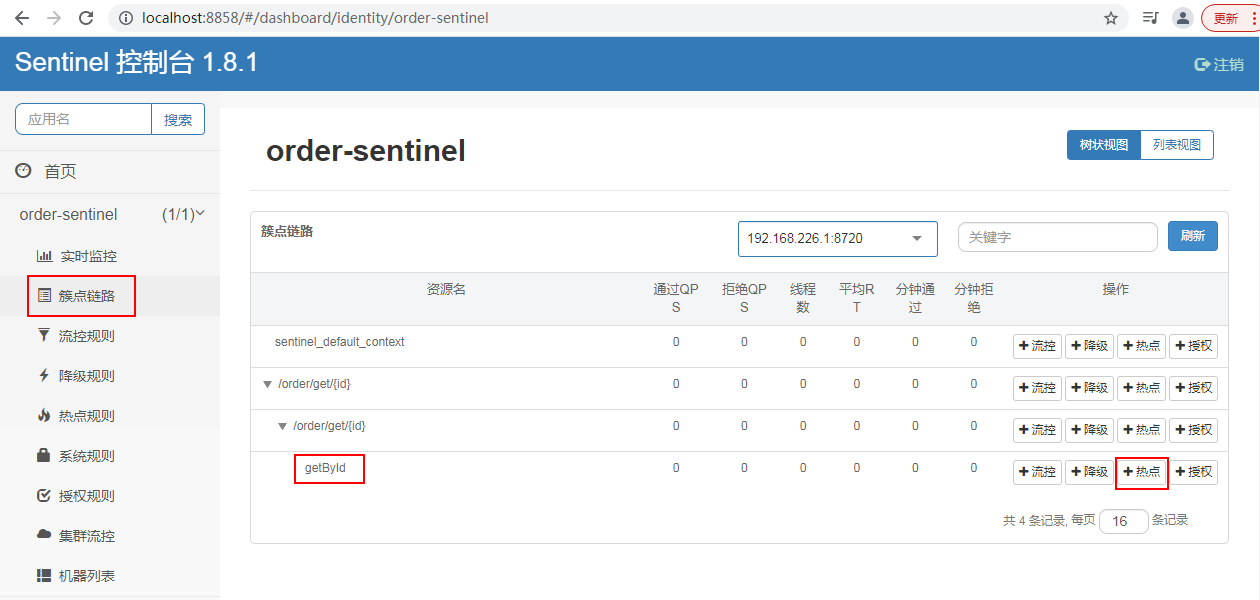
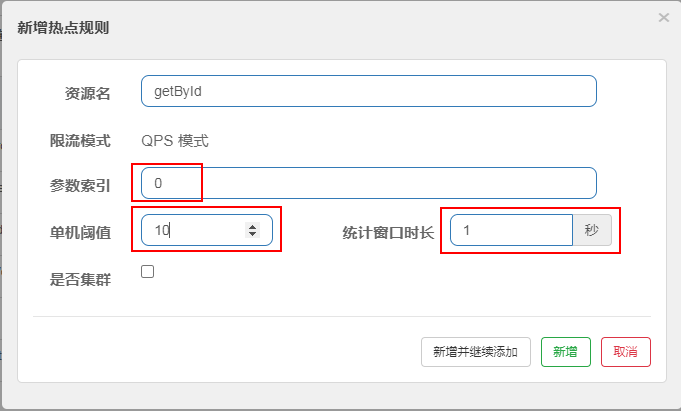
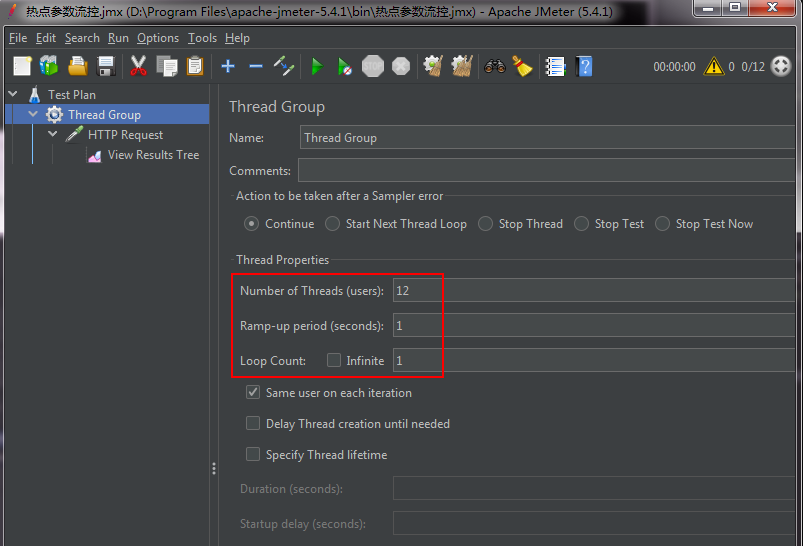
单机阈值:
1、假设 参数大部分值都是热点参数,那单机阈值就主要针对热点参数进行流控。后续再额外针对普通的参数进行流控。
2、假设 参数大部分值都是普通流量,那单机阈值就主要针对普通参数进行流控。
(统计窗口时长 )内 的QPS (单机阈值)
系统吞吐量几个重要参数:QPS(TPS)、并发数、响应时间
QPS(Query Per Second),QPS 其实是衡量吞吐量(Throughput)的一个常用指标,就是说服务器在一秒的时间内处理了多少个请求 —— 我们通常是指 HTTP 请求,显然数字越大代表服务器的负荷越高、处理能力越强。作为参考,一个有着简单业务逻辑(包括数据库访问)的程序在单核心运行时可以提供 50 - 100 左右的 QPS,即每秒可以处理 50 - 100 个请求。
TPS(Transaction Per Second) 每秒钟系统能够处理的事务的数量。
QPS(TPS):每秒钟 request/事务 的数量 (此处 / 表示 或的意思)
并发数: 系统同时处理的request/事务数 (此处 / 表示 或的意思)
响应时间: 一般取平均响应时间
理解了上面三个要素的意义之后,就能推算出它们之间的关系:
QPS(TPS)= 并发数/平均响应时间
一个系统吞吐量通常由QPS(TPS)、并发数两个因素决定,每套系统这两个值都有一个相对极限值,在应用场景访问压力下,只要某一项达到系统最高值,系统的吞吐量就上不去了,如果压力继续增大,系统的吞吐量反而会下降,原因是系统超负荷工作,上下文切换、内存等等其它消耗导致系统性能下降。
并发用户数和QPS两个概念没有直接关系,但是如果要说QPS时,一定需要指明是多少并发用户数下的QPS,否则毫无意义,因为单用户数的400QPS和200并发用户数下的400QPS是两个不同的概念。前者说明该应用可以在一秒内串行执行400个请求,而后者说明在并发200个请求的情况下,一秒内该应用能处理400个请求,当QPS相同时,越大的并发用户数,代表了网站并发处理能力越好。对于当前的web服务器,其处理单个用户的请求肯定戳戳有余,这个时候会存在资源浪费的情况(一方面该服务器可能有多个cpu,但是只处理单个进程,另一方面,在处理一个进程中,有些阶段可能是IO阶段,这个时候会造成CPU等待,但是有没有其他请求进程可以被处理)。而当并发数设置的过大时,每秒钟都会有很多请求需要处理,会造成进程(线程)频繁切换,反正真正用于处理请求的时间变少,每秒能够处理的请求数反而变少,同时用户的请求等待时间也会变大,甚至超过用户的心理底线。所以在最小并发数和最大并发数之间,一定有一个最合适的并发数值,在该并发数下,QPS能够达到最大。但是,这个并发并非是一个最佳的并发,因为当QPS到达最大时的并发,可能已经造成用户的等待时间变得超过了其最优值,所以对于一个系统,其最佳的并发数,一定需要结合QPS,用户的等待时间来综合确定。





 浙公网安备 33010602011771号
浙公网安备 33010602011771号