
Data Wrangling
Data Wrangling
以整理系统日志为例,journalctl获取系统中的所有日志
获取ssh中试图登录服务器用户
过滤出ssh的信息
journalctl | grep sshd
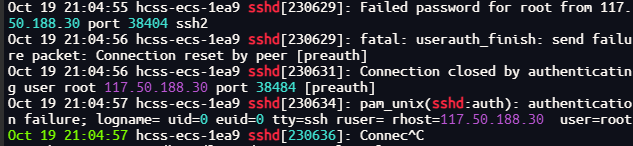
其中的内容,除了登录用户还有其他内容,所以需要进一步过滤
journalctl | grep sshd | grep "Disconnected from"

查找到许多试图登录服务器的用户
将以上内容都保存到ssh.log文件中
journalctl | grep sshd | grep "Disconnected from" > ssh.log
sed
保存的ssh.log文件中仍有许多无用数据,需要进一步通过工具sed进行过滤
sed是一个流式编辑器,修改的只是输出流而不是文件本身
journalctl
| grep sshd
| grep "Disconnected from "
| sed 's/.*Disconnected from//'
s/.*Disconnected from//使用到正则表达式,语法s/REGEX/SUBSTITUTION/
REGEX是正则表达式,SUBSTITUTION是匹配结果的替换内容,这里是将包括Disconnected from之前的内容替换为空
perl
假设有人使用Disconnected from作为用户名
Dec 04 12:46:43 hcss-ecs-1ea9 sshd[2024135]: Disconnected from invalid user Disconnected from 120.86.120.90 port 38342 [preauth]
使用sed过滤将会把该用户名及其前面的内容都删除掉,使用sed过滤时就会变成这样:
120.86.120.90 port 38342 [preauth]
这是因为正则表达式使用了贪婪模式,尽可能的去匹配多的内容,关闭贪婪模式,在*或+后加一个?
但是sed不支持使用?后缀,可以使用perl命令去替换sed
cat ssh.log | perl -pe 's/.*?Disconnected from//'
继续过滤
匹配一整行,并将其替换为空
cat ssh.log | sed -E 's/.*Disconnected from (invalid |authenticating )?user .* [^ ]+ port [0-9]+( \[preauth\])?$//'
捕获组
日志中的内容都被替换了,但是没有输出用户名
在set -E 's/.*Disconnected from (invalid |authenticating )?user .* [^ ]+ port [0-9]+( \[preauth\])?$//'中.*匹配的是用户名内容
为了将.*部分保留,可以使用捕获组,就是将()中得内容,存储到捕获组中,并编号,例:/1,/2......
就可以将上面的过滤正则表达式修改,令其输出用户名
cat ssh.log | sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/'

以上的过滤,都需要在正则表达式的基础上进行
对数据进一步整理
排序
sort会将输入流进行排序
cat ssh.log
| sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/'
| sort

计数
uniq
uniq -c 会对输入流进行计数
cat ssh.log
| sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/'
| sort
| uniq -c
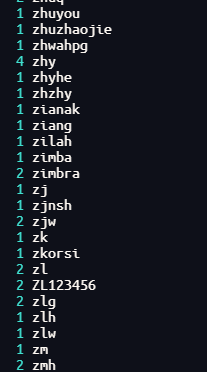
按照计数数字排序
sort -n:将会按照数值进行排序
cat ssh.log
| sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/'
| sort
| uniq -c
| sort -n
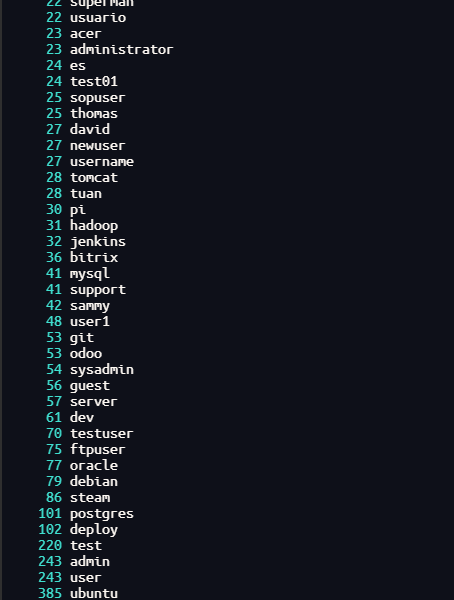
数字越大,说明用户登录次数越多,但是这样的排序并不完全正确
sort -nk1,1
n:只能保证按照数值大小排序
k:可以指定键值,1,1按第一列开始到第一列进行排序,如果是2,3就是第二列到第三列
awk
awk是是一个文本分析工具,提供编程语言功能
cat ssh.log
| sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/'
| sort
| uniq -c
| sort -n
| awk '{print $2}'
awk '{print $2}'输出了输出流中的$2部分
$2:awk会将一行文本分为$n$个区域,命名从$1-$n,$0代表整行,区域与区域之间默认是空格分割(可以使用-F指定分隔符),这里的$2就是用户名
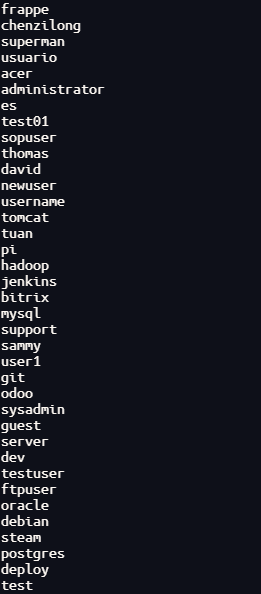
awk还可以进行更深入的编程
awk '$1==1 && $2 ~ /^c[^ ]*e$/ {print $2}'
找出出现次数为一,c开头e结尾的用户名
paste
paste将所有文件都合并为一列
cat ssh.log
| sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/'
| sort
| uniq -c
| sort -n
| awk '{print $2}'
| paste -sd,
-s:可以将多行合并为一行
d,:指定分隔符

数据分析
使用bc对登录次数进行汇总
cat ssh.log
| sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/'
| sort
| uniq -c
| sort -n
| awk '{print $1}'
| paste -sd+
| bc -l

课后作业
-
统计 words 文件 (
/usr/share/dict/words) 中包含至少三个a且不以's结尾的单词个数。这些单词中,出现频率前三的末尾两个字母是什么?sed的y命令,或者tr程序也许可以帮你解决大小写的问题。共存在多少种词尾两字母组合?还有一个很 有挑战性的问题:哪个组合从未出现过?
至少3个a且不以's结尾的单词个数
cat /usr/share/dict/words | tr "[:upper:]" "[:lower:]" | grep -E '^([^a]*a){3}.*$' | grep -v "'s$"
出现频率前三的末尾两个字母
cat /usr/share/dict/words | tr "[:upper:]" "[:lower:]" | grep -E '^([^a]*a){3}.*$' | grep -v "'s$" | sed -E 's/.*([a-z]{2})$/\1/' | sort | uniq -c | sort -nk1,1 | tail -n3
词尾两个字母有多少种组合
cat /usr/share/dict/words | tr "[:upper:]" "[:lower:]" | grep -E '^([^a]*a){3}.*$' | grep -v "'s$" | sed -E 's/.*([a-z]{2})$/\1/' | sort | uniq -c | wc -l
那些词没有出现过
char.sh
#!/bin/bash
for i in {a..z};do
for j in {a..z};do
echo $i$j
done
done
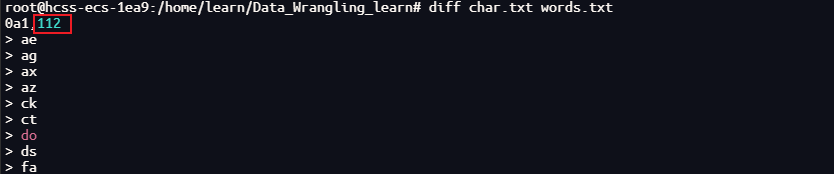
cat /usr/share/dict/words | tr "[:upper:]" "[:lower:]" | grep -E '^([^a]*a){3}.*$' | grep -v "'s$" | sed -E 's/.*([a-z]{2})$/\1/' | sort | uniq -c | sort -nk1,1 | awk '{print $2}' > words.txt
./char.sh > char.txt
diff char.txt words.txt
- 进行原地替换听上去很有诱惑力,例如:
sed s/REGEX/SUBSTITUTION/ input.txt > input.txt。但是这并不是一个明智的做法,为什么呢?还是说只有sed是这样的? 查看man sed来完成这个问题
sed -i.bak `sed s/REGEX/SUBSTITUTION/ input.txt > input.txt`
创建一个备份文件
