

22.Python基础篇-内置模块
collections模块
collections模块提供了一些数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple():具名元组
from collections import namedtuple Point = namedtuple('坐标', ['x', 'y']) p = Point(1, 2) print(p.x) # 结果:1 print(p.y) # 结果:2
2.deque():双端队列
可以在两端插入和删除元素,适合实现队列和栈

from collections import deque d = deque([1, 2, 3]) d.append(4) # 添加到右端 d.appendleft(0) # 添加到左端 print(d) # deque([0, 1, 2, 3, 4]) d.pop() # 删除右端元素 d.popleft() # 删除左端元素 print(d) # deque([1, 2, 3])
3.OrderedDict():有序字典
保持插入顺序。与普通字典不同,OrderedDict 保证在遍历时元素按插入顺序排列。
from collections import OrderedDict od = OrderedDict() od['a'] = 1 od['b'] = 2 od['c'] = 3 print(od) # 输出:OrderedDict([('a', 1), ('b', 2), ('c', 3)])
4.defaultdict():字典的变体,在访问不存在的键时会自动创建一个键并将其初始化为默认值。
语法:collections.defaultdict(default_factory)
default_factory:提供默认值的函数(如 int、list、str 等)。
default_factory:提供默认值的函数(如 int、list、str 等)。
from collections import defaultdict values = [11, 22, 33,44,55,66,77,88,99,90] d = defaultdict(list) # 默认值的函数 # 大于66的加入到key1中,小于等于加到key2中。虽然key1和key2都没有添加,正常字典这样使用会报错,但是使用defaultdict不会报错 for value in values: if value>66: d['key1'].append(value) else: d['key2'].append(value) print(d) # 结果:defaultdict(<class 'list'>, {'key2': [11, 22, 33, 44, 55, 66], 'key1': [77, 88, 99, 90]})
5.Counter():统计可迭代对象中每个元素出现的次数
from collections import Counter counter = Counter('aabbccddeeff') # 将要统计的数据在这一步传过去 print(counter) # Counter({'a': 2, 'b': 2, 'c': 2, 'd': 2, 'e': 2, 'f': 2})
time模块
1.time.time()
返回当前时间的时间戳,即从 Unix 纪元(1970年1月1日 00:00:00 UTC)开始到当前时间的秒数。
print(time.time()) # 1730884286.9802155
2.time.sleep():
让程序暂停指定的秒数,常用于延时操作。
time.sleep(5) # 等待五秒
时间戳转struct_time对象一类
3.localtime()
将时间戳转换为当前本地时间的struct_time 对象,若不提供时间戳,则使用当前时间。
print(time.localtime()) # 将时间戳转换为当前本地时间的struct_time 对象,若不提供时间戳,则使用当前时间。 print(time.localtime(3730884286.9802155)) # 提供时间戳,将时间戳转换为struct_time对象
4.gmtime()
将时间戳转换为 UTC(世界协调时间)的 struct_time 对象。同样可以传入指定的时间戳
import time print(time.gmtime()) # 输出:time.struct_time(tm_year=2024, tm_mon=11, tm_mday=7, tm_...
struct_time对象转换为时间戳一类
5.time.localtime()
获取本地时间,struct_time类型的对象
local_time_struct_time = time.localtime() # 获取本地时间,struct_time类型的对象 # 将struct_time对象传过去。会获取一个时间戳 print(time.mktime(local_time_struct_time)) # 输出:1730885093.0
struct_time对象转换格式化字符串一类
6.time.strftime()
将 struct_time 对象格式化为字符串,常用于自定义时间格式输出。
语法:time.strftime(format, [t])
format:指定格式化字符串。
%Y:四位数年份
%m:月份(01-12)
%d:日期(01-31)
%H:小时(24小时制,00-23)
%M:分钟(00-59)
%S:秒(00-59)
t:可选参数,struct_time 对象,默认为当前时间。
format:指定格式化字符串。
%Y:四位数年份
%m:月份(01-12)
%d:日期(01-31)
%H:小时(24小时制,00-23)
%M:分钟(00-59)
%S:秒(00-59)
t:可选参数,struct_time 对象,默认为当前时间。
local = time.localtime() print(time.strftime('%Y-%m-%d %H:%M:%S', local)) # 输出:2024-11-07 10:36:19。将local的时间转换为格式化输出
7.time.asctime()
将 struct_time 对象转换为字符串,格式类似 'Sun Oct 1 15:23:43 2023'
语法:time.asctime([t])
t:可选,默认为当前时间的 struct_time 对象。
返回值:格式化的时间字符串。
t:可选,默认为当前时间的 struct_time 对象。
返回值:格式化的时间字符串。
lcoal_t = time.localtime(2730884286) print(time.asctime(lcoal_t)) # 输出:Sat Jul 15 18:58:06 2056
将字符串转化为struct_time类型的对象一类
8.time.strptime()
将字符串时间转换为 struct_time 对象,格式要与输入字符串一致。
语法:time.strptime(string, format)
string:时间字符串。
format:字符串的时间格式。
返回值:struct_time 对象。
语法:time.strptime(string, format)
string:时间字符串。
format:字符串的时间格式。
返回值:struct_time 对象。
time_str = "2023-07-15 14:23:45" print(time.strptime(time_str, "%Y-%m-%d %H:%M:%S")) # 输出:time.struct_time(tm_year=2023, tm_mon=7, ...
9.time.ctime()
将时间戳转换为类似 'Sun Oct 1 15:23:43 2023' 的字符串。
语法:time.ctime([secs])
secs:可选时间戳,默认当前时间。
返回值:格式化时间字符串。
secs:可选时间戳,默认当前时间。
返回值:格式化时间字符串。
print(time.ctime()) # 输出:Thu Nov 7 10:49:33 2024
格式转换必须先转成struct_time类型再转换大盘format string或timestamp,如下图:
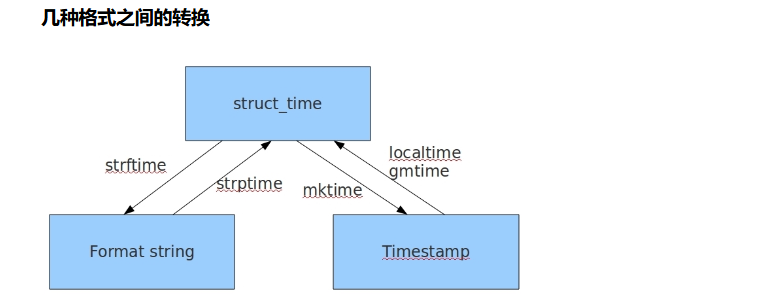
datetime模块
1.datetime.now()
获取当前datetime
print(datetime.now()) # 输出:2024-11-07 10:52:06.581579
random模块
random 模块用于生成随机数和执行随机选择,适用于模拟随机性和生成伪随机数据。
1.random.random()
生成一个 [0.0, 1.0) 范围的随机浮点数。
print(random.random()) # 输出: 例如 0.783456
2.random.randint()
生成指定范围内的随机整数,包括范围的两端。
语法:random.randint(a, b)
a:起始整数。
b:结束整数(包含)。
a:起始整数。
b:结束整数(包含)。
# 打印1 到 10 之间的随机整数 print(random.randint(1, 10)) # 输出:9
3.random.uniform()
生成指定范围内的随机浮点数。
语法:random.uniform(a, b)
a:范围的起始值。
b:范围的结束值。
语法:random.uniform(a, b)
a:范围的起始值。
b:范围的结束值。
# 1.5-10之间的随机浮点数 print(random.uniform(1.5, 10)) # 输出:1.8421062911102681
4.random.choice()
从序列中随机选择一个元素。
语法:random.choice(sequence)
sequence:一个非空序列,如列表、字符串或元组。
语法:random.choice(sequence)
sequence:一个非空序列,如列表、字符串或元组。
num_list = [1, 2, 3, 4, 'a', 'b'] # 从num_list随机抽取一个值 print(random.choices(num_list)) # 输出:['b']
5.random.choices()
从序列中随机选择多个元素,可指定权重和选择数量。
语法:random.choices(population, weights=None, k=1)
population:选择的序列。
weights:可选的权重序列,用于控制每个元素的选中概率。
k:选择的数量。
语法:random.choices(population, weights=None, k=1)
population:选择的序列。
weights:可选的权重序列,用于控制每个元素的选中概率。
k:选择的数量。
colors = ['red', 'blue', 'green'] print(random.choices(colors, weights=[5, 1, 1], k=3)) # 输出: 按权重多次随机选择
6.random.sample()
功能:随机选择指定数量的唯一元素。它不允许重复,即每个元素只能被选中一次。
语法:random.sample(population, k)
population:选择的序列。
k:选择的数量,不能超过序列的长度。
numbers = range(1, 20)
语法:random.sample(population, k)
population:选择的序列。
k:选择的数量,不能超过序列的长度。
numbers = range(1, 20)
# 从 1 到 19 之间随机选择 5 个不同的数 print(random.sample(numbers, 5)) # [7, 4, 6, 11, 18]
7.random.shuffle()
功能:对序列进行就地随机打乱。
语法:random.shuffle(sequence)
sequence:要打乱的列表(需要是可变数据类型)。
语法:random.shuffle(sequence)
sequence:要打乱的列表(需要是可变数据类型)。
cards = [1, 2, 3, 4, 5] random.shuffle(cards) # 将cards列表的顺序随机打乱 print(cards) # 输出:[3, 4, 5, 1, 2]
os模块
os 模块提供了一些与操作系统交互的功能,包括文件和目录的操作、环境变量的获取、进程管理等。os 模块提供了跨平台的接口,适用于多种操作系统。
1.os.getcwd():返回当前工作目录的路径
2.os.makedirs:递归创建目录,即可创建多层嵌套的目录。
print(os.getcwd()) # C:\Users\15801\PycharmProjects\pythonProject\模块
3.os.removedirs:递归删除空目录,即从最深层目录向外逐层删除。
4.os.mkdir() :创建一个目录
5.os.rmdir() :删除指定目录
6.os.listdir():列出目录下的所有文件和子目录。
7.os.remove() :删除指定文件
8.os.rename('旧文件名', '新文件名') : 重命名文件
9.os.stat():获取文件或目录的信息
10.os.system() :执行系统命令,参数为字符串类型的shell命令
11.os.popen() :打开一个管道并执行系统命令,,将命令的输入或输出作为文件对象(类似于文件句柄)来处理。通过这种方式,程序可以读取或写入系统命令的标准输入/输出。
os.makedirs('dir1/dir2') # 在当前py文件所属的目录下创建一个dir1的目录,并创建一个其子目录dir2 os.removedirs('dir1/dir2')
os.mkdir('dirname') # 创建一个目录,命名为dirname
os.rmdir('dirname') # 删除名字为dirname的目录
print(os.listdir('../模块')) # ['dirname1', '__init__.py', '模块.py']
os.remove('test_file.txt') # 删除test_file.txt这个文件
os.rename('dirname1', 'dirname2') # 将dirname1改成dirname2
print(os.stat('dirname2')) # 输出:os.stat_result(st_mode=16895, st_ino=5629499534306718, st_dev=2364210496, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1731056109, st_mtime=1731053195, st_ctime=1731053195)
os.system('chcp 65001') # 将终端编码设为 UTF-8 os.system('ipconfig') # Windows下查看IP的命令
with os.popen('dir') as stream: # 终端输入dir命令,将返回值存到stream句柄中 for i in stream: print(i)
打印结果:
12.os.chdir() :改变当前工作目录。
14.os.path.split() :分割路径和文件名,返回二元祖。索引0位置路径,1位置文件名
15.os.path.splitext() :分割文件名和扩展名,返回二元组。索引0文件名,1拓展名
16.os.path.dirname(path) :返回path的目录,相当于os.path.split中的第0个元素
17.os.path.basename(path):返回path的文件名,相当于os.path.split中的第1个元组
18.os.path.exists(path) :path是否存在,存在返true,不存在返false
19.os.path.isabs(path) :path是否是绝对路径,是返true,不是返false
20.os.path.isfile(path):path是否是一个存在的文件。是返true,不是false
21.os.path.isdir(path) :path是否是一个存在目录。是返true,不存在或不是目录返false
print('当前工作路径:' + os.getcwd()) os.chdir('C:\\') print('切换之后的工作路径:' + os.getcwd()) 输出: print('当前工作路径:' + os.getcwd()) os.chdir('C:\\') print('切换之后的工作路径:' + os.getcwd())
os.path
13.os.path.abspath():将相对路径转换为绝对路径。print(os.path.abspath('testfile.txt')) # C:\Users\15801\PycharmProjects\pythonProject\模块\testfile.txt
15.os.path.splitext() :分割文件名和扩展名,返回二元组。索引0文件名,1拓展名
path = '/folder/subfolder/file.txt' print(os.path.split(path)) # ('/folder/subfolder', 'file.txt') print(os.path.splitext(path)) # ('/folder/subfolder/file', '.txt')
17.os.path.basename(path):返回path的文件名,相当于os.path.split中的第1个元组
print(os.path.dirname(path)) # /folder/subfolder print(os.path.basename(path)) # file.txt
print(os.path.exists('dirname1/dirname2')) # True
print(os.path.isabs('dirname1/dirname2')) # False print(os.path.isabs('C:\\Users\\15801\\PycharmProjects\\pythonProject\\模块\\dirname1\\dirname2')) # True
path = 'dirname1\\dirname2\\test_file.txt' print(os.path.isfile(path)) # True
path = 'dirname1\\dirname2\\test_file.txt' print(os.path.isdir(path)) # False path2 = 'dirname1' print(os.path.isdir(path2)) # True
path = os.path.join("folder", "subfolder", "file.txt") print(path) # 输出:folder\subfolder\file.txt
24.os.path.getmtime(path) : 获取文件或目录的最近修改时间
25.os.path.getsize(path) :获取文件或目录的大小。单位:字节
path = 'dirname1\\dirname2\\test_file.txt' print(os.path.getatime(path)) # 输出最近一次访问的时间戳:1731198511.4716766 print(os.path.getmtime(path)) # 输出最近一次修改的时间戳:1731198511.4716766 print(os.path.getsize(path)) # 输出文件的大小,单位字节。输出结果:6
序列化模块
什么叫序列化:将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化
比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给? 现在我们能想到的方法就是存在文件里,然后另一个python程序再从文件里读出来。 但是我们都知道,对于文件来说是没有字典这个概念的,所以我们只能将数据转换成字典放到文件中。 你一定会问,将字典转换成一个字符串很简单,就是str(dic)就可以办到了,为什么我们还要学习序列化模块呢? 没错序列化的过程就是从dic 变成str(dic)的过程。现在你可以通过str(dic),将一个名为dic的字典转换成一个字符串, 但是你要怎么把一个字符串转换成字典呢? 聪明的你肯定想到了eval(),如果我们将一个字符串类型的字典str_dic传给eval,就会得到一个返回的字典类型了。 eval()函数十分强大,但是eval是做什么的?e官方demo解释为:将字符串str当成有效的表达式来求值并返回计算结果。 BUT!强大的函数有代价。安全性是其最大的缺点。 想象一下,如果我们从文件中读出的不是一个数据结构,而是一句"删除文件"类似的破坏性语句,那么后果实在不堪设设想。 而使用eval就要担这个风险。 所以,我们并不推荐用eval方法来进行反序列化操作(将str转换成python中的数据结构)
序列化的目的
1、以某种存储形式使自定义对象持久化;
2、将对象从一个地方传递到另一个地方。
3、使程序更具维护性。
2、将对象从一个地方传递到另一个地方。
3、使程序更具维护性。
将列表字典等数据类型转换为str的过程,被称为序列化;
将str转换为列表字典等数据类型的过程,被称为反序列化。

json
json 是一个轻量级数据交换格式,适合用于不同编程语言之间的数据交换。仅支持 Python 的基础数据类型(如字典、列表、字符串等)。
json.dumps:序列化,列表/字典转字符串
json.loads:反序列化,字符串转列表/字典
# 序列化对象 data = {'name': 'Alice', 'age': 25} json_data = json.dumps(data) # 将dict类型的数据data序列化 print(json_data) print(type(json_data)) # 输出: # {"name": "Alice", "age": 25} # <class 'str'> # 反序列化对象 load_json = json.loads(json_data) # 使用loads将字符串类型的数据反序列化 print(load_json) print(type(load_json)) # 输出: # {'name': 'Alice', 'age': 25} # <class 'dict'>
json.dump:序列化方法,将Python对象序列化后写入到文件
json.load:反序列化方法,从文件中字符串转换为Python对象
但是dump与load能完成的事情,使用dumps也能完成。所以只需要掌握dumps与loads就行。
pickle
pickle可以把python中任意的数据类型序列化。但是json数据适用于所有语言,发送Python数据java语言也可以识别。pickle只在Python能使用,序列化时需要Python完成,反序列也是需要Python完成。
pickle支持四种与json模块一样的方法,其用法也是一致,它们分别是:
pickle.dump
pickle.dumps
pickle.load
pickle.loads
# 序列化 data = {'name': 'Alice', 'age': 25} data_dump = pickle.dumps(data) print(data_dump) # # b'\x80\x04\x95\x1c\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x04name\x94\x8c\x05Alice\x94\x8c\x03age\x94K\x19u.' struct_time = time.localtime() print(pickle.dumps(struct_time)) # b'\x80\x04\x95e\x00\x00\x00\x00\x00\x00\x00\x8c\x04time\x94\x8c\x0bstruct_time\x94\x93\x94(M\xe8\x07K\x0bK\nK\x0bK\rK\x0cK\x06M;\x01K\x00t\x94}\x94(\x8c\x07tm_zone\x94\x8c\x12\xe4\xb8\xad\xe5\x9b\xbd\xe6\xa0\x87\xe5\x87\x86\xe6\x97\xb6\xe9\x97\xb4\x94\x8c\ttm_gmtoff\x94M\x80pu\x86\x94R\x94.' # 反序列化 print(pickle.loads(data_dump)) # {'name': 'Alice', 'age': 25}
sys模块
Python 解释器和系统交互的功能。
sys.argv
在命令行运行脚本时传入的命令行参数。其中第一个元素 sys.argv[0] 是脚本名。
# 脚本内容 print(sys.argv) # 命令行输入的内容: # C:\Users\15801>python C:\Users\15801\PycharmProjects\pythonProject\模块\模块.py '第一个参数' '第二个参数' # 打印结果:['C:\\Users\\15801\\PycharmProjects\\pythonProject\\模块\\模块.py', "'第一个参数'", "'第二个参数'"]
sys.exit
终止 Python 程序。可以传入一个整数表示退出状态,其中 0 表示正常退出,非零值表示异常退出。
sys.exit('Error: some_condition is False')
sys.version
获取Python解释程序的版本信息
print(sys.version) # 3.8.10 (tags/v3.8.10:3d8993a, May 3 2021, 11:48:03) [MSC v.1928 64 bit (AMD64)]
sys.path
print(sys.path) # 用于返回模块搜索路径的列表(即 PYTHONPATH)。可以在代码中添加路径,便于导入不在标准路径中的模块。 sys.path.append('/path/to/dir') # 添加新路径
sys.platform
print(sys.platform) # Python当前的运行系统是win还是Linux


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!