数据采集作业二
数据采集作业二
gitee链接:https://gitee.com/wangzm7511/shu-ju/tree/master/作业2
作业报告
作业①:在中国气象网给定城市集的7日天气预报,并保存在数据库
1.1 作业代码与运行结果
作业代码
点击查看代码
def get_weather_forecast(city_code):
url = f'http://www.weather.com.cn/weather/{city_code}.shtml'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
forecast_data = []
seven_day_forecast = soup.find('ul', class_='t clearfix')
if seven_day_forecast:
for li in seven_day_forecast.find_all('li'):
date = li.find('h1').text.strip()
weather = li.find('p', class_='wea').text.strip()
temp_low = li.find('p', class_='tem').span.text.strip() if li.find('p', class_='tem').span else ''
temp_high = li.find('p', class_='tem').em.text.strip() if li.find('p', class_='tem').em else ''
wind = li.find('p', class_='win').i.text.strip()
forecast_data.append((date, weather, temp_low, temp_high, wind))
return forecast_data
def save_forecast_to_csv(city, forecast_data):
with open('weather_forecast.csv', mode='a', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
for data in forecast_data:
writer.writerow([city, data[0], data[1], data[2], data[3], data[4]])
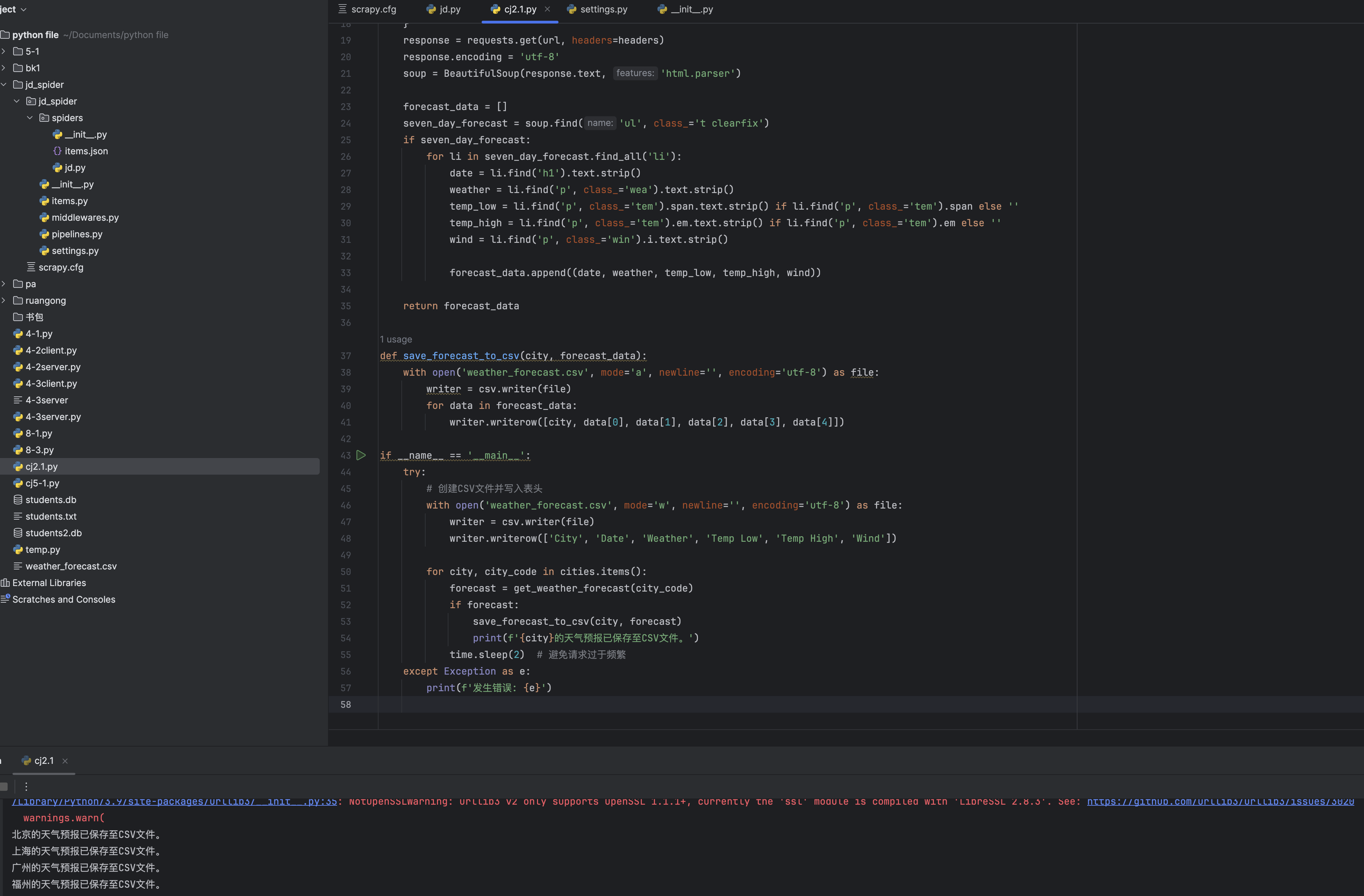
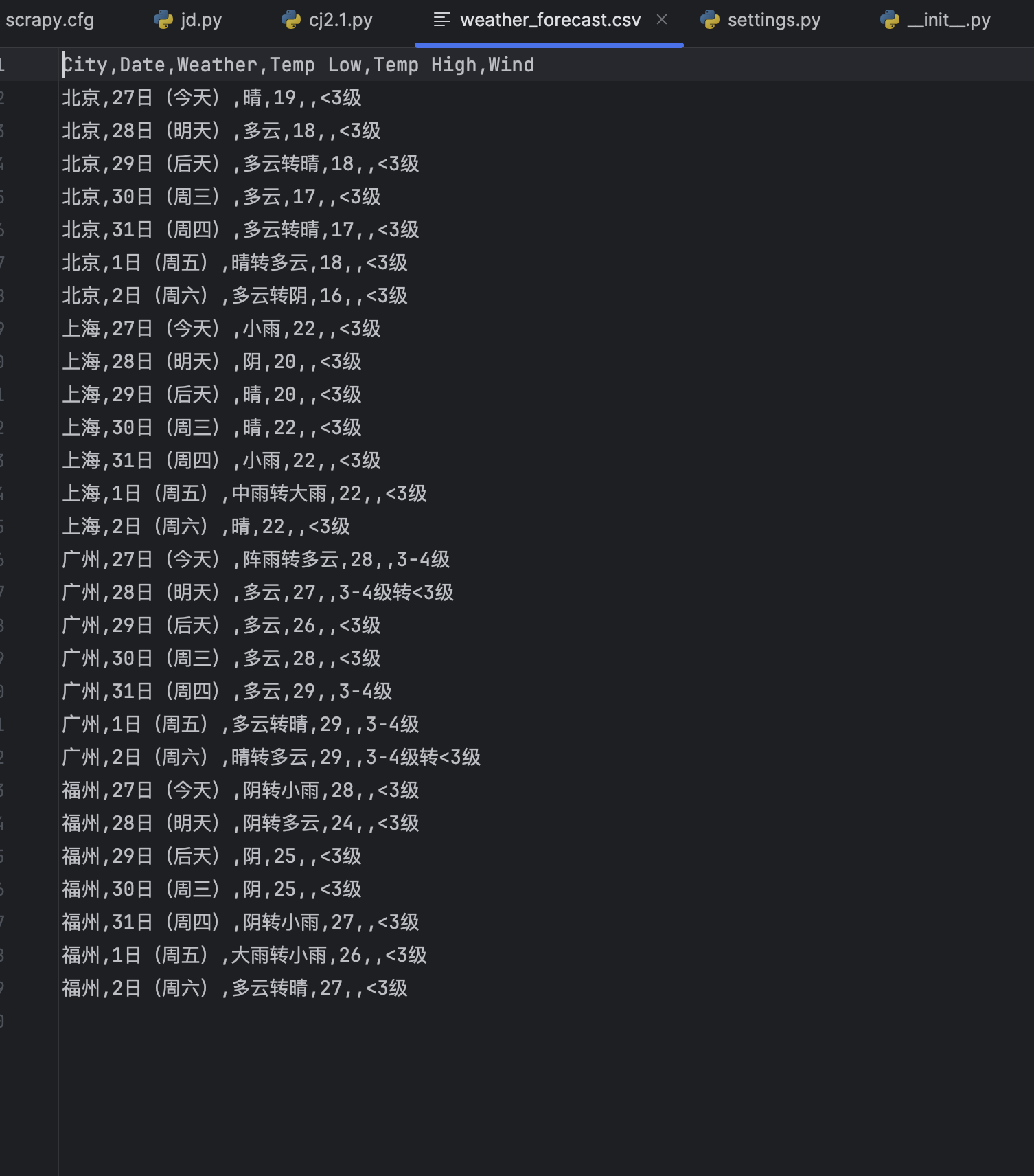
运行结果
1.2 作业心得
在完成作业①的过程中,我学习了如何使用Python的requests库发送HTTP请求,并结合BeautifulSoup库解析HTML内容。通过分析目标网页的结构,我掌握了如何定位并提取所需的数据。
遇到的挑战:
-
动态加载内容:部分网站的数据是通过JavaScript动态加载的,这意味着直接使用
requests获取的HTML内容中可能不包含实际的数据。为了应对这种情况,我尝试使用了更精确的选择器,并根据页面实际情况调整了解析逻辑。 -
反爬虫机制:目标网站可能有反爬虫措施,例如检测频繁请求或限制IP访问。为了减少被封禁的风险,我在请求头中添加了
User-Agent,模拟常见浏览器的访问行为。
收获与体会:
通过此次作业,我深入理解了网页爬取的基本流程,包括发送请求、解析HTML、提取数据以及处理异常情况。同时,我也意识到了实际应用中可能遇到的各种问题,如动态内容加载和反爬虫机制,并学习了相应的应对策略。
作业②:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
2.1 作业代码与运行结果
作业代码
点击查看代码
def fetch_data(page_number):
url = f'https://1.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409952374347191637_1728983306168&pn={page_number}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_={1728983306169 + page_number}'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
try:
response = requests.get(url, headers=headers)
return response
except Exception as err:
print(f"Error fetching data for page {page_number}: {type(err).__name__} - {err}")
return None
# 解析响应数据的函数
def parse_data(response):
if response and response.status_code == 200:
json_data = response.text
json_data = json_data[json_data.index('(') + 1: -2]
data = json.loads(json_data)
return data
else:
print(f'Failed to parse data. Status code: {response.status_code if response else "None"}')
return None
# 翻页爬取数据的函数
def scrape_data(page_number):
response = fetch_data(page_number)
return parse_data(response)
# 爬取多页数据并存储到 DataFrame
def scrape_multiple_pages(max_pages=5):
all_data = [] # 用于存储所有页的数据
for page_number in range(1, max_pages + 1):
print(f"正在爬取第 {page_number} 页数据...")
data = scrape_data(page_number)
if data and 'data' in data and 'diff' in data['data']:
for stock in data['data']['diff']:
stock_info = {
'名称': stock.get('f14'),
'最新价': stock.get('f2'),
'涨跌幅': stock.get('f3'),
'成交量(手)': stock.get('f4'),
'成交额': stock.get('f5'),
'振幅': stock.get('f6'),
'最高价': stock.get('f7'),
'最低价': stock.get('f8')
}
all_data.append(stock_info)
else:
print(f"第 {page_number} 页没有数据或请求失败")
break
return all_data
# 保存股票数据到 CSV 文件
def save_to_csv(stock_data, filename='stock_data.csv'):
with open(filename, mode='w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=['名称', '最新价', '涨跌幅', '成交量(手)', '成交额', '振幅', '最高价', '最低价'])
writer.writeheader()
for data in stock_data:
writer.writerow(data)
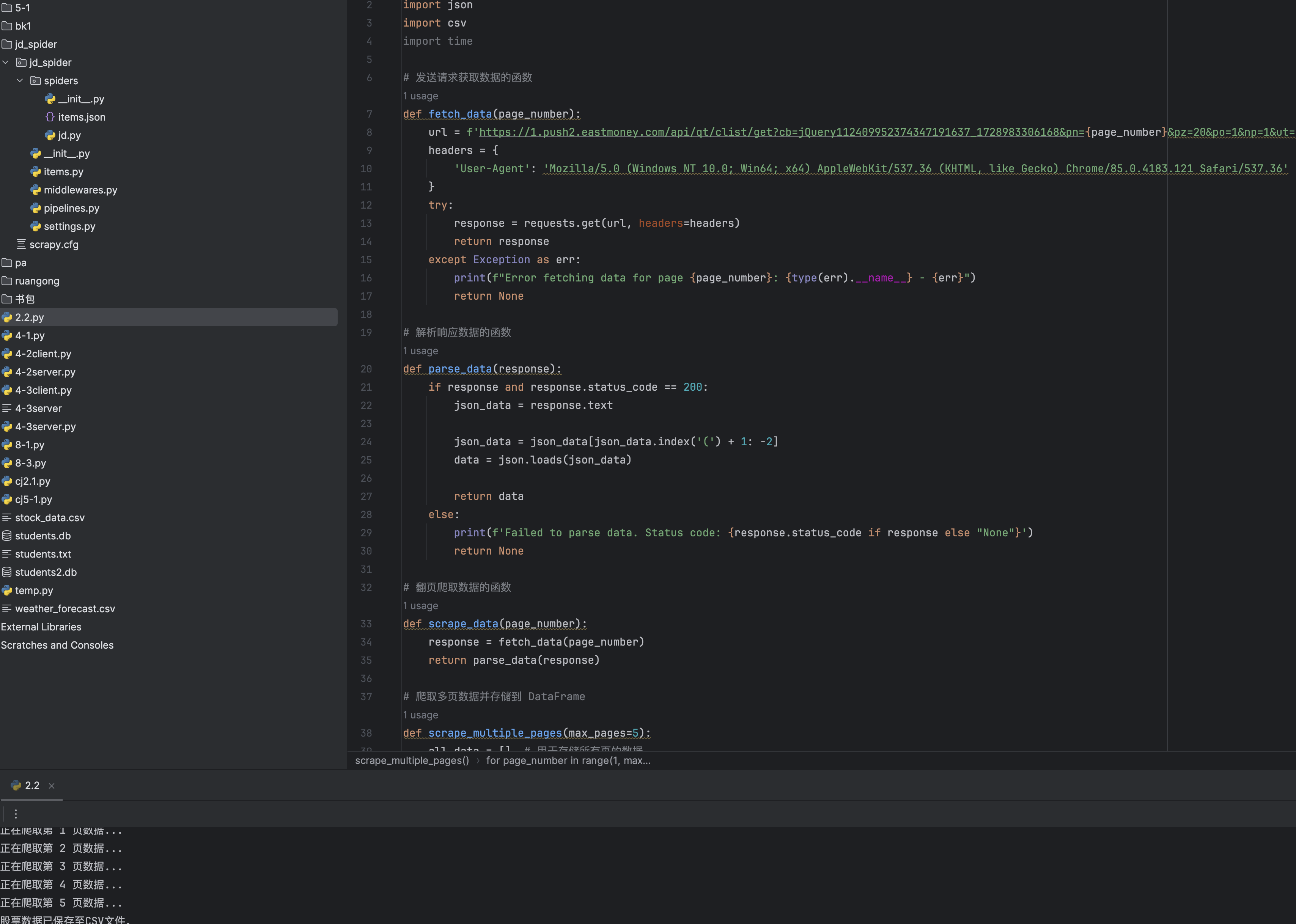
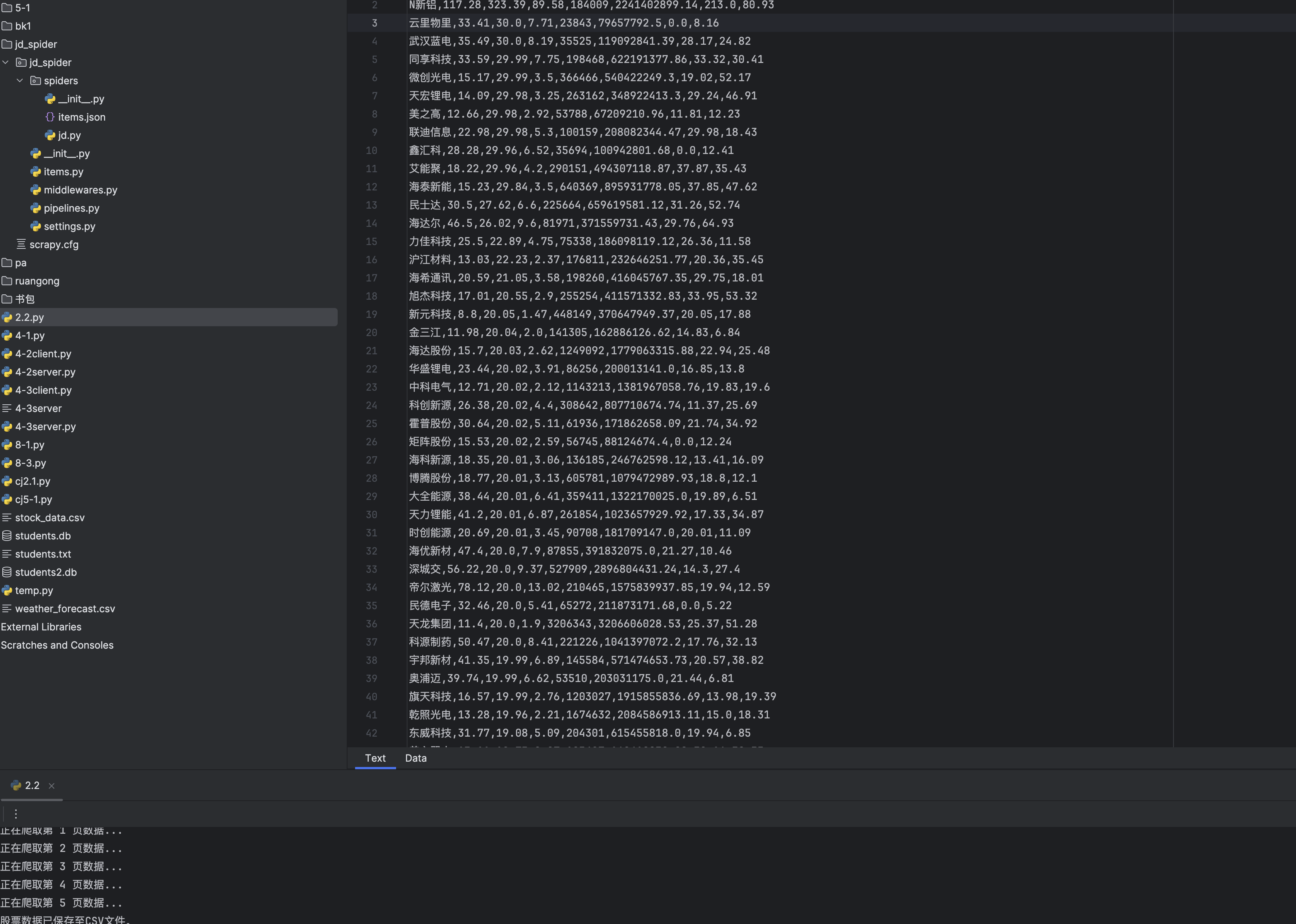
运行结果
2.2 作业心得
遇到的挑战:
- 复杂的页面结构:股市平台的页面结构复杂且频繁变化,需要不断调整爬虫的解析逻辑和正则表达式,以确保能够准确提取所需的数据。
收获与体会:
通过此次作业,我不仅巩固了使用requests和re库进行网页数据抓取的基本技能,还学习了如何应对实际项目中常见的动态内容和反爬虫机制。此外,我也认识到在复杂的平台上进行数据抓取时,可能需要结合多种工具和方法,以实现更高效和稳定的爬虫。
这次作业让我意识到,爬虫开发不仅仅是编写代码,还需要深入理解目标网站的结构和行为,以及灵活应对各种技术挑战。这对于未来从事数据采集和分析工作具有重要的指导意义。
作业③:下载网页中的所有JPEG和JPG文件
3.1 作业代码与运行结果
F12获取api
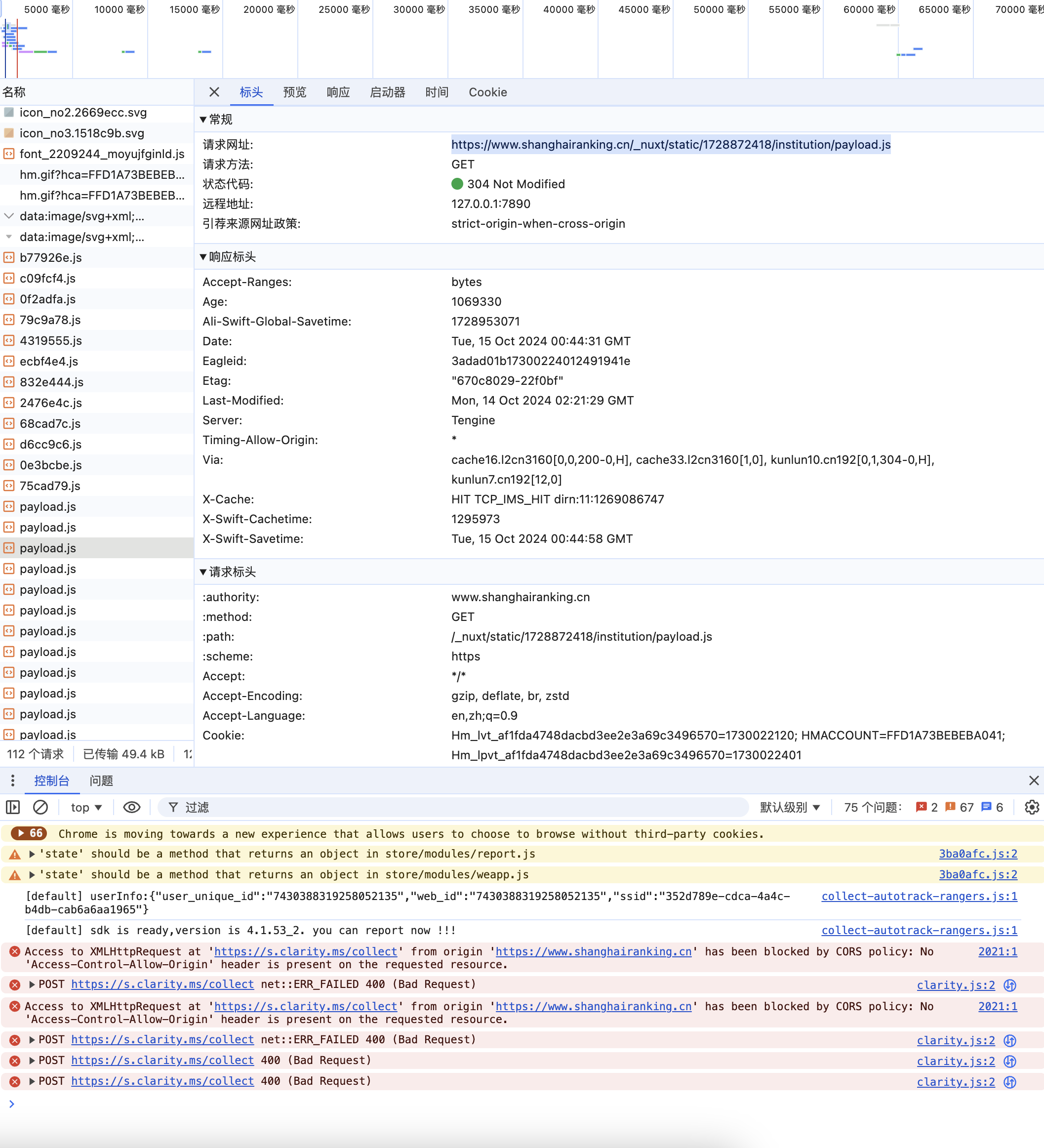
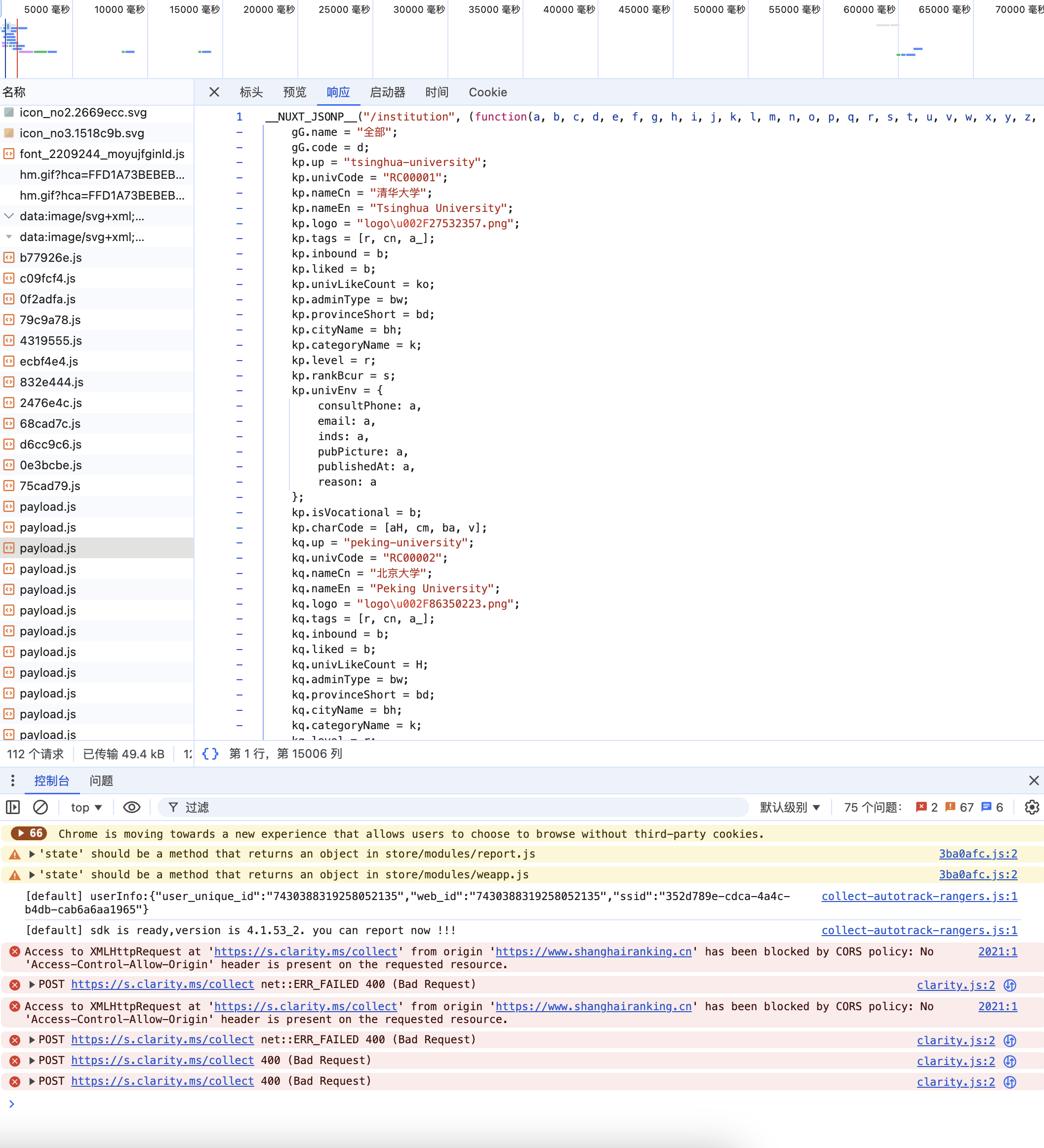
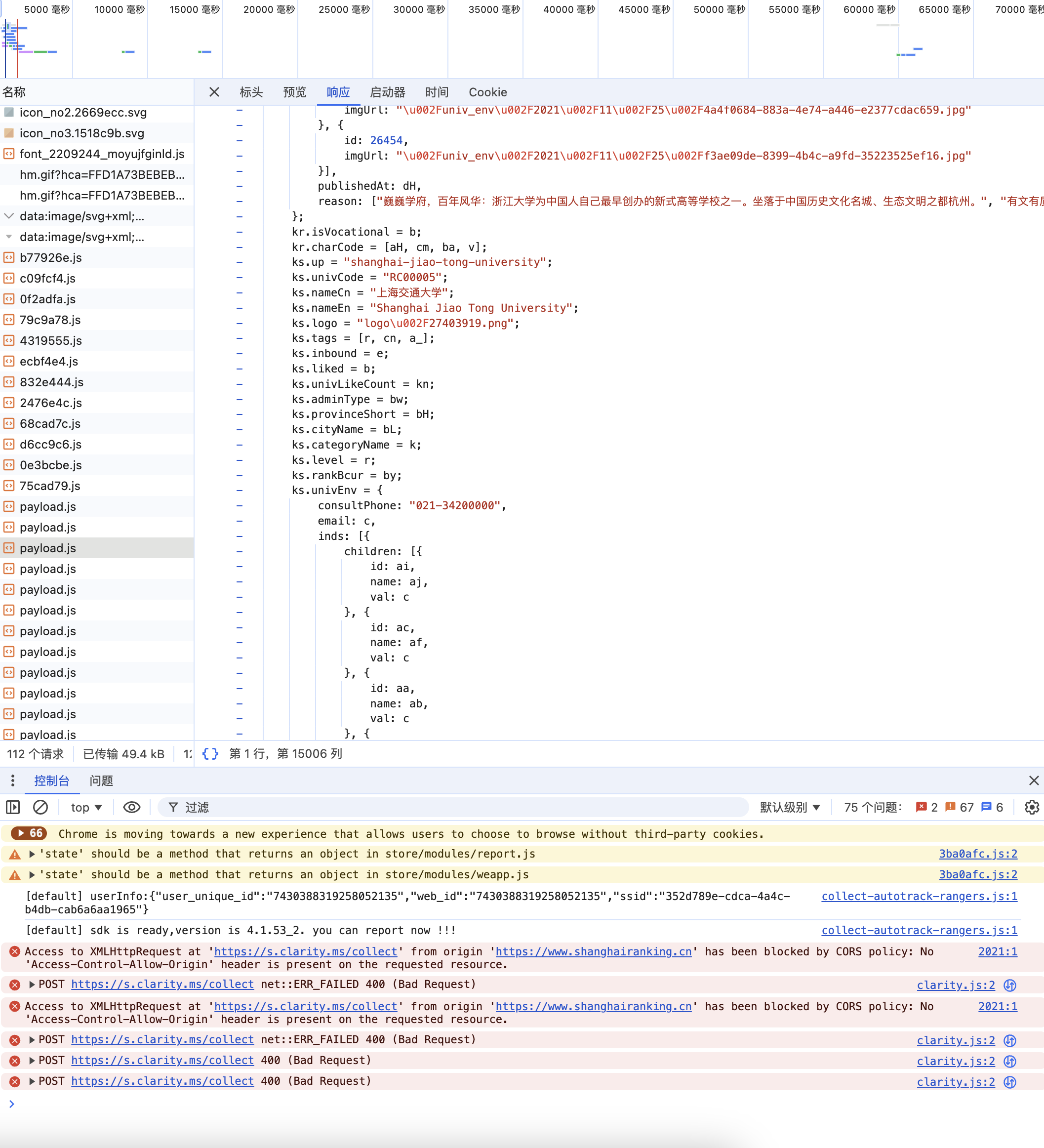
作业代码
点击查看代码
def get_html_content(url):
response = requests.get(url, headers={"User-Agent": "Mozilla/5.0"}, timeout=10)
response.raise_for_status()
response.encoding = response.apparent_encoding
return response.text
def parse_university_info(html_text):
soup = BeautifulSoup(html_text, "html.parser")
university_list = []
tbody = soup.find('tbody')
if not tbody:
return university_list
rows = tbody.find_all('tr')
for row in rows:
columns = row.find_all('td')
if len(columns) < 5:
continue
rank = columns[0].text.strip()
name_tag = columns[1].find('a')
name = name_tag.text.strip() if name_tag else columns[1].text.strip()
labels_to_remove = ['双一流', '985工程', '211工程', '985', '211']
for label in labels_to_remove:
name = name.replace(label, '')
name = re.sub(r'[A-Za-z]', '', name)
name = re.sub(r'[^\u4e00-\u9fa5]', '', name)
province = columns[2].text.strip()
category = columns[3].text.strip()
score = columns[4].text.strip()
university_list.append([rank, name, province, category, score])
return university_list
def save_to_csv(data_list, csv_path='university_rankings.csv'):
with open(csv_path, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ["Rank", "Name", "Province", "Category", "Score"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for uni in data_list:
writer.writerow({
"Rank": uni[0],
"Name": uni[1],
"Province": uni[2],
"Category": uni[3],
"Score": uni[4]
})
def main():
url = "https://www.shanghairanking.cn/rankings/bcur/2021"
html_content = get_html_content(url)
university_data = parse_university_info(html_content)
if not university_data:
print("未获取到大学信息。")
return
save_to_csv(university_data)
print(f"成功将数据存储到 'university_rankings.csv' 中,共 {len(university_data)} 条记录。")
运行结果


总结
通过完成这三个作业,我不仅提升了Python编程技能,尤其是在网页爬取和数据处理方面,还深入理解了实际应用中可能遇到的各种技术挑战和解决方案。这些经验将为我未来的学习和项目开发奠定坚实的基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号