Python葵花宝典初级(python2.x)
Python2 还是python3 可以通过设置环境变量来绑定,export PATH="$PATH:/usr/local/bin/python" ,我的系统看了下现在是:/usr/bin下,python2.7和python3.5都有,都能用。显式调用就可以。

Python有五个标准的数据类型:
- Numbers(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
Python 数字
Python Number 数据类型用于存储数值。
数据类型是不允许改变的,这就意味着如果改变 Number 数据类型的值,将重新分配内存空间。
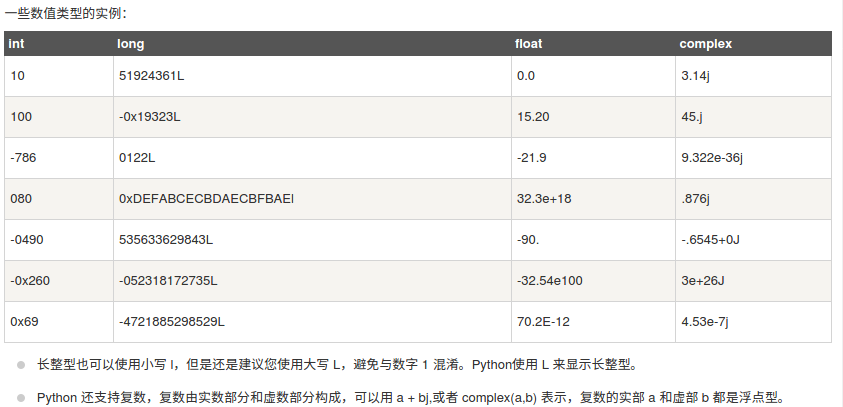
long 类型只存在于 Python2.X 版本中,在 2.2 以后的版本中,int 类型数据溢出后会自动转为long类型。在 Python3.X 版本中 long 类型被移除,使用 int 替代。
Python字符串

python的字符串内建函数
这些方法实现了string模块的大部分方法,如下表所示列出了目前字符串内建支持的方法,所有的方法都包含了对Unicode的支持,有一些甚至是专门用于Unicode的。
| 方法 | 描述 |
|---|---|
|
把字符串的第一个字符大写 |
|
|
返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
|
|
返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
|
|
以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 'ignore' 或 者'replace' |
|
|
以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
|
|
检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
|
|
把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
|
|
检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
|
|
格式化字符串 |
|
|
跟find()方法一样,只不过如果str不在 string中会报一个异常. |
|
|
如果 string 至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
|
|
如果 string 至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False |
|
|
如果 string 只包含十进制数字则返回 True 否则返回 False. |
|
|
如果 string 只包含数字则返回 True 否则返回 False. |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
|
|
如果 string 中只包含数字字符,则返回 True,否则返回 False |
|
|
如果 string 中只包含空格,则返回 True,否则返回 False. |
|
|
如果 string 是标题化的(见 title())则返回 True,否则返回 False |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
|
|
以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
|
|
返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
|
|
转换 string 中所有大写字符为小写. |
|
|
截掉 string 左边的空格 |
|
|
maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
|
|
返回字符串 str 中最大的字母。 |
|
|
返回字符串 str 中最小的字母。 |
|
|
有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
|
|
把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
|
|
类似于 find() 函数,返回字符串最后一次出现的位置,如果没有匹配项则返回 -1。 |
|
|
类似于 index(),不过是从右边开始. |
|
|
返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
|
|
类似于 partition()函数,不过是从右边开始查找 |
|
|
删除 string 字符串末尾的空格. |
|
|
以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+1 个子字符串 |
|
|
按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
|
|
检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
|
|
在 string 上执行 lstrip()和 rstrip() |
|
|
翻转 string 中的大小写 |
|
|
返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
|
|
根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 del 参数中 |
|
|
转换 string 中的小写字母为大写 |
|
|
返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
Python列表
它里面可以存放任意数量、任意类型的数据,如字符,数字,字符串,字典等甚至可以包含列表(即嵌套)。是 python 最通用的复合数据类型,列表和字符串一样也是2种取值顺序。列表的数据项不需要具有相同的类型.
Python 元组
元组是另一个数据类型,类似于 List(列表)。
元组用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。
任意无符号的对象,以逗号隔开,默认为元组.
Python 字典
列表是有序的对象集合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典用"{ }"标识。字典由索引(key)和它对应的值value组成
键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
Python字典包含了以下内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | dict.fromkeys(seq[, val]) 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值 |
| 5 | dict.has_key(key) 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | dict.keys() 以列表返回一个字典所有的键 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 以列表返回字典中的所有值 |
| 11 | pop(key[,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | popitem() 返回并删除字典中的最后一对键和值。 |
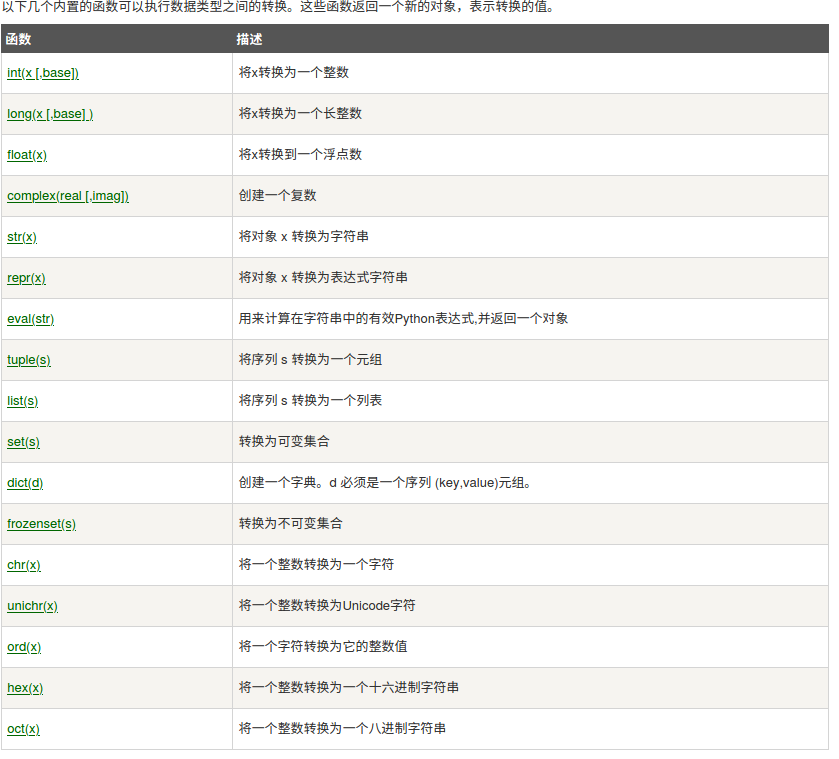
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可
str() 与 repr() 的不同在于:
str()的输出追求可读性,输出格式要便于理解,适合用于输出内容到用户终端。repr()的输出追求明确性,除了对象内容,还需要展示出对象的数据类型信息,适合开发和调试阶段使用。
另外如果想要自定义类的实例能够被 str() 和 repr() 所调用,那么就需要在自定义类中重载 __str__ 和 __repr__ 方法。
链接:https://www.jianshu.com/p/2a41315ca47e
序列索引
序列中,每个元素都有属于自己的编号(索引)。从起始元素开始,索引值从 0 开始递增,如图 1 所示。

图 1 序列索引值示意图
除此之外,Python 还支持索引值是负数,此类索引是从右向左计数,换句话说,从最后一个元素开始计数,从索引值 -1 开始,如图 2 所示。

图 2 负值索引示意图
注意,在使用负值作为列序中各元素的索引值时,是从 -1 开始,而不是从 0 开始。
序列切片
切片操作是访问序列中元素的另一种方法,它可以访问一定范围内的元素,通过切片操作,可以生成一个新的序列。
序列实现切片操作的语法格式如下:
sname[start : end : step]
其中,各个参数的含义分别是:
- sname:表示序列的名称;
- start:表示切片的开始索引位置(包括该位置),此参数也可以不指定,会默认为 0,也就是从序列的开头进行切片;
- end:表示切片的结束索引位置(不包括该位置),如果不指定,则默认为序列的长度;
- step:表示在切片过程中,隔几个存储位置(包含当前位置)取一次元素,也就是说,如果 step 的值大于 1,则在进行切片去序列元素时,会“跳跃式”的取元素。如果省略设置 step 的值,则最后一个冒号就可以省略。
序列相加
Python 中,支持两种类型相同的序列使用“+”运算符做相加操作,它会将两个序列进行连接,但不会去除重复的元素。
这里所说的“类型相同”,指的是“+”运算符的两侧序列要么都是列表类型,要么都是元组类型,要么都是字符串。
序列相乘
Python 中,使用数字 n 乘以一个序列会生成新的序列,其内容为原来序列被重复 n 次的结果。
比较特殊的是,列表类型在进行乘法运算时,还可以实现初始化指定长度列表的功能。例如如下的代码,将创建一个长度为 5 的列表,列表中的每个元素都是 None,表示什么都没有。
- #列表的创建用 []
- list = [None]*5
- print(list)
输出结果为:
[None, None, None, None, None]
检查元素是否包含在序列中
Python 中,可以使用 in 关键字检查某元素是否为序列的成员,其语法格式为:
value in sequence
其中,value 表示要检查的元素,sequence 表示指定的序列。
和 in 关键字用法相同,但功能恰好相反的,还有 not in 关键字,它用来检查某个元素是否不包含在指定的序列中,
和序列相关的内置函数
Python提供了几个内置函数(表 3 所示),可用于实现与序列相关的一些常用操作。
| 函数 | 功能 |
|---|---|
| len() | 计算序列的长度,即返回序列中包含多少个元素。 |
| max() | 找出序列中的最大元素。注意,对序列使用 sum() 函数时,做加和操作的必须都是数字,不能是字符或字符串,否则该函数将抛出异常,因为解释器无法判定是要做连接操作(+ 运算符可以连接两个序列),还是做加和操作。 |
| min() | 找出序列中的最小元素。 |
| list() | 将序列转换为列表。 |
| str() | 将序列转换为字符串。 |
| sum() | 计算元素和。 |
| sorted() | 对元素进行排序。 |
| reversed() | 反向序列中的元素。 |
| enumerate() | 将序列组合为一个索引序列,多用在 for 循环中。 |
Python算术运算符
以下假设变量: a=10,b=20:
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 30 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -10 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 200 |
| / | 除 - x除以y | b / a 输出结果 2 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 0 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的20次方, 输出结果 100000000000000000000 |
| // | 取整除 - 返回商的整数部分(向下取整) |
>>> 9//2
4
>>> -9//2
-5
|
注意:Python2.x 里,整数除整数,只能得出整数。如果要得到小数部分,把其中一个数改成浮点数即可。
Python比较运算符
以下假设变量a为10,变量b为20:
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False。 |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 true. |
| <> | 不等于 - 比较两个对象是否不相等。python3 已废弃。 | (a <> b) 返回 true。这个运算符类似 != 。 |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False。 |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。 | (a < b) 返回 true。 |
| >= | 大于等于 - 返回x是否大于等于y。 | (a >= b) 返回 False。 |
| <= | 小于等于 - 返回x是否小于等于y。 | (a <= b) 返回 true。 |
Python赋值运算符
以下假设变量a为10,变量b为20:
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
Python位运算符
按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下:
下表中变量 a 为 60,b 为 13,二进制格式如下:
a = 0011 1100
b = 0000 1101
-----------------
a&b = 0000 1100
a|b = 0011 1101
a^b = 0011 0001
~a = 1100 0011
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1。 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1 。~x 类似于 -x-1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011,在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0。 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把">>"左边的运算数的各二进位全部右移若干位,>> 右边的数字指定了移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
Python逻辑运算符
Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔"或" - 如果 x 是非 0,它返回 x 的计算值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
Python成员运算符
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
Python身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
注: id() 函数用于获取对象内存地址。
is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个(同一块内存空间), == 用于判断引用变量的值是否相等。
>>> a = [1, 2, 3] >>> b = a >>> b is a True >>> b == a True >>> b = a[:] >>> b is a False >>> b == a True
Python运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 'AND' |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
Python 日期和时间
Python 程序能用很多方式处理日期和时间,转换日期格式是一个常见的功能。
Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间。
时间间隔是以秒为单位的浮点小数。
每个时间戳都以自从1970年1月1日午夜(历元)经过了多长时间来表示。
Python 的 time 模块下有很多函数可以转换常见日期格式。如函数time.time()用于获取当前时间戳, 如下实例:
实例(Python 2.0+)
结果:
当前时间戳为: 1459994552.51
时间戳单位最适于做日期运算。但是1970年之前的日期就无法以此表示了。太遥远的日期也不行,UNIX和Windows只支持到2038年。
什么是时间元组?
很多Python函数用一个元组装起来的9组数字处理时间:
| 序号 | 字段 | 值 |
|---|---|---|
| 0 | 4位数年 | 2008 |
| 1 | 月 | 1 到 12 |
| 2 | 日 | 1到31 |
| 3 | 小时 | 0到23 |
| 4 | 分钟 | 0到59 |
| 5 | 秒 | 0到61 (60或61 是闰秒) |
| 6 | 一周的第几日 | 0到6 (0是周一) |
| 7 | 一年的第几日 | 1到366 (儒略历) |
| 8 | 夏令时 | -1, 0, 1, -1是决定是否为夏令时的旗帜 |
上述也就是struct_time元组。这种结构具有如下属性:
| 序号 | 属性 | 值 |
|---|---|---|
| 0 | tm_year | 2008 |
| 1 | tm_mon | 1 到 12 |
| 2 | tm_mday | 1 到 31 |
| 3 | tm_hour | 0 到 23 |
| 4 | tm_min | 0 到 59 |
| 5 | tm_sec | 0 到 61 (60或61 是闰秒) |
| 6 | tm_wday | 0到6 (0是周一) |
| 7 | tm_yday | 1 到 366(儒略历) |
| 8 | tm_isdst | -1, 0, 1, -1是决定是否为夏令时的旗帜 |
获取当前时间
从返回浮点数的时间戳方式向时间元组转换,只要将浮点数传递给如localtime之类的函数。
实例(Python 2.0+)
结果:
本地时间为 : time.struct_time(tm_year=2016, tm_mon=4, tm_mday=7, tm_hour=10, tm_min=3, tm_sec=27, tm_wday=3, tm_yday=98, tm_isdst=0)
获取格式化的时间
你可以根据需求选取各种格式,但是最简单的获取可读的时间模式的函数是asctime():
实例(Python 2.0+)
结果:
本地时间为 : Thu Apr 7 10:05:21 2016
格式化日期
我们可以使用 time 模块的 strftime 方法来格式化日期,:
time.strftime(format[, t])
实例(Python 2.0+)
import time # 格式化成2016-03-20 11:45:39形式
print time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) # 格式化成Sat Mar 28 22:24:24 2016形式
print time.strftime("%a %b %d %H:%M:%S %Y", time.localtime()) # 将格式字符串转换为时间戳
a = "Sat Mar 28 22:24:24 2016" print time.mktime(time.strptime(a,"%a %b %d %H:%M:%S %Y"))
结果:
2016-04-07 10:25:09
Thu Apr 07 10:25:09 2016
1459175064.0
python中时间日期格式化符号:
- %y 两位数的年份表示(00-99)
- %Y 四位数的年份表示(000-9999)
- %m 月份(01-12)
- %d 月内中的一天(0-31)
- %H 24小时制小时数(0-23)
- %I 12小时制小时数(01-12)
- %M 分钟数(00-59)
- %S 秒(00-59)
- %a 本地简化星期名称
- %A 本地完整星期名称
- %b 本地简化的月份名称
- %B 本地完整的月份名称
- %c 本地相应的日期表示和时间表示
- %j 年内的一天(001-366)
- %p 本地A.M.或P.M.的等价符
- %U 一年中的星期数(00-53)星期天为星期的开始
- %w 星期(0-6),星期天为星期的开始
- %W 一年中的星期数(00-53)星期一为星期的开始
- %x 本地相应的日期表示
- %X 本地相应的时间表示
- %Z 当前时区的名称
- %% %号本身
获取某月日历
Calendar模块有很广泛的方法用来处理年历和月历:
实例(Python 2.0+)
结果:
以下输出2016年1月份的日历:
January 2016
Mo Tu We Th Fr Sa Su
1 2 3
4 5 6 7 8 9 10
11 12 13 14 15 16 17
18 19 20 21 22 23 24
25 26 27 28 29 30 31
Time 模块
Time 模块包含了以下内置函数,既有时间处理的,也有转换时间格式的:
| 序号 | 函数及描述 |
|---|---|
| 1 | time.altzone 返回格林威治西部的夏令时地区的偏移秒数。如果该地区在格林威治东部会返回负值(如西欧,包括英国)。对夏令时启用地区才能使用。 |
| 2 | time.asctime([tupletime]) 接受时间元组并返回一个可读的形式为"Tue Dec 11 18:07:14 2008"(2008年12月11日 周二18时07分14秒)的24个字符的字符串。 |
| 3 | time.clock( ) 用以浮点数计算的秒数返回当前的CPU时间。用来衡量不同程序的耗时,比time.time()更有用。 |
| 4 | time.ctime([secs]) 作用相当于asctime(localtime(secs)),未给参数相当于asctime() |
| 5 | time.gmtime([secs]) 接收时间戳(1970纪元后经过的浮点秒数)并返回格林威治天文时间下的时间元组t。注:t.tm_isdst始终为0 |
| 6 | time.localtime([secs]) 接收时间戳(1970纪元后经过的浮点秒数)并返回当地时间下的时间元组t(t.tm_isdst可取0或1,取决于当地当时是不是夏令时)。 |
| 7 | time.mktime(tupletime) 接受时间元组并返回时间戳(1970纪元后经过的浮点秒数)。 |
| 8 | time.sleep(secs) 推迟调用线程的运行,secs指秒数。 |
| 9 | time.strftime(fmt[,tupletime]) 接收以时间元组,并返回以可读字符串表示的当地时间,格式由fmt决定。 |
| 10 | time.strptime(str,fmt='%a %b %d %H:%M:%S %Y') 根据fmt的格式把一个时间字符串解析为时间元组。 |
| 11 | time.time( ) 返回当前时间的时间戳(1970纪元后经过的浮点秒数)。 |
| 12 | time.tzset() 根据环境变量TZ重新初始化时间相关设置。 |
Time模块包含了以下2个非常重要的属性:
| 序号 | 属性及描述 |
|---|---|
| 1 | time.timezone 属性 time.timezone 是当地时区(未启动夏令时)距离格林威治的偏移秒数(>0,美洲<=0大部分欧洲,亚洲,非洲)。 |
| 2 | time.tzname 属性time.tzname包含一对根据情况的不同而不同的字符串,分别是带夏令时的本地时区名称,和不带的。 |
日历(Calendar)模块
此模块的函数都是日历相关的,例如打印某月的字符月历。
星期一是默认的每周第一天,星期天是默认的最后一天。更改设置需调用calendar.setfirstweekday()函数。模块包含了以下内置函数:
| 序号 | 函数及描述 |
|---|---|
| 1 | calendar.calendar(year,w=2,l=1,c=6) 返回一个多行字符串格式的year年年历,3个月一行,间隔距离为c。 每日宽度间隔为w字符。每行长度为21* W+18+2* C。l是每星期行数。 |
| 2 | calendar.firstweekday( ) 返回当前每周起始日期的设置。默认情况下,首次载入 calendar 模块时返回 0,即星期一。 |
| 3 | calendar.isleap(year) 是闰年返回 True,否则为 False。 >>> import calendar
>>> print(calendar.isleap(2000))
True
>>> print(calendar.isleap(1900))
False
|
| 4 | calendar.leapdays(y1,y2) 返回在Y1,Y2两年之间的闰年总数。 |
| 5 | calendar.month(year,month,w=2,l=1) 返回一个多行字符串格式的year年month月日历,两行标题,一周一行。每日宽度间隔为w字符。每行的长度为7* w+6。l是每星期的行数。 |
| 6 | calendar.monthcalendar(year,month) 返回一个整数的单层嵌套列表。每个子列表装载代表一个星期的整数。Year年month月外的日期都设为0;范围内的日子都由该月第几日表示,从1开始。 |
| 7 | calendar.monthrange(year,month) 返回两个整数。第一个是该月的星期几的日期码,第二个是该月的日期码。日从0(星期一)到6(星期日);月从1到12。 |
| 8 | calendar.prcal(year,w=2,l=1,c=6) 相当于 print calendar.calendar(year,w=2,l=1,c=6)。 |
| 9 | calendar.prmonth(year,month,w=2,l=1) 相当于 print calendar.month(year,month,w=2,l=1) 。 |
| 10 | calendar.setfirstweekday(weekday) 设置每周的起始日期码。0(星期一)到6(星期日)。 |
| 11 | calendar.timegm(tupletime) 和time.gmtime相反:接受一个时间元组形式,返回该时刻的时间戳(1970纪元后经过的浮点秒数)。 |
| 12 | calendar.weekday(year,month,day) 返回给定日期的日期码。0(星期一)到6(星期日)。月份为 1(一月) 到 12(12月)。 |
其他相关模块和函数
在Python中,其他处理日期和时间的模块还有:
参数传递
在 python 中,类型属于对象,变量是没有类型的,她仅仅是一个对象的引用(一个指针).
可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
-
不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a。
-
可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
-
不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
-
可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
参数
以下是调用函数时可使用的正式参数类型:
- 必备参数
- 关键字参数
- 默认参数
- 不定长参数
必备参数
必备参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
关键字参数
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
实例(Python 2.0+)
结果:
Name: miki
Age 50
默认参数
调用函数时,默认参数的值如果没有传入,则被认为是默认值。
不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名。
基本语法如下:
加了星号(*)的变量名会存放所有未命名的变量参数。
实例(Python 2.0+)
结果:
输出:
10
输出:
70
60
50
匿名函数
python 使用 lambda 来创建匿名函数。
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
语法
lambda函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression
实例(Python 2.0+)
以上实例输出结果:
相加后的值为 : 40
变量作用域
一个程序的所有的变量并不是在哪个位置都可以访问的。访问权限决定于这个变量是在哪里赋值的。
变量的作用域决定了在哪一部分程序你可以访问哪个特定的变量名称。两种最基本的变量作用域如下:- 全局变量
- 局部变量
全局变量和局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。
搜索路径
当你导入一个模块,Python 解析器对模块位置的搜索顺序是:
- 1、当前目录
- 2、如果不在当前目录,Python 则搜索在 shell 变量 PYTHONPATH 下的每个目录。
- 3、如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/。
模块搜索路径存储在 system 模块的 sys.path 变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
PYTHONPATH 变量
作为环境变量,PYTHONPATH 由装在一个列表里的许多目录组成。PYTHONPATH 的语法和 shell 变量 PATH 的一样。
在 Windows 系统,典型的 PYTHONPATH 如下:
set PYTHONPATH=c:\python27\lib;
在 UNIX 系统,典型的 PYTHONPATH 如下:
set PYTHONPATH=/usr/local/lib/python
命名空间和作用域
变量是拥有匹配对象的名字(标识符)。命名空间是一个包含了变量名称们(键)和它们各自相应的对象们(值)的字典。
一个 Python 表达式可以访问局部命名空间和全局命名空间里的变量。如果一个局部变量和一个全局变量重名,则局部变量会覆盖全局变量。
每个函数都有自己的命名空间。类的方法的作用域规则和通常函数的一样。
Python 会智能地猜测一个变量是局部的还是全局的,它假设任何在函数内赋值的变量都是局部的。
因此,如果要给函数内的全局变量赋值,必须使用 global 语句。
global VarName 的表达式会告诉 Python, VarName 是一个全局变量,这样 Python 就不会在局部命名空间里寻找这个变量了。
例如,我们在全局命名空间里定义一个变量 Money。我们再在函数内给变量 Money 赋值,然后 Python 会假定 Money 是一个局部变量。然而,我们并没有在访问前声明一个局部变量 Money,结果就是会出现一个 UnboundLocalError 的错误。取消 global 语句前的注释符就能解决这个问题。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
Money = 2000
def AddMoney():
# 想改正代码就取消以下注释:
# global Money
Money = Money + 1
print Money
AddMoney()
print Money
dir()函数
dir() 函数一个排好序的字符串列表,内容是一个模块里定义过的名字。
返回的列表容纳了在一个模块里定义的所有模块,变量和函数。如下一个简单的实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 导入内置math模块
import math
content = dir(math)
print content;
以上实例输出结果:
['__doc__', '__file__', '__name__', 'acos', 'asin', 'atan',
'atan2', 'ceil', 'cos', 'cosh', 'degrees', 'e', 'exp',
'fabs', 'floor', 'fmod', 'frexp', 'hypot', 'ldexp', 'log',
'log10', 'modf', 'pi', 'pow', 'radians', 'sin', 'sinh',
'sqrt', 'tan', 'tanh']
在这里,特殊字符串变量__name__指向模块的名字,__file__指向该模块的导入文件名。
globals() 和 locals() 函数
根据调用地方的不同,globals() 和 locals() 函数可被用来返回全局和局部命名空间里的名字。
如果在函数内部调用 locals(),返回的是所有能在该函数里访问的命名。
如果在函数内部调用 globals(),返回的是所有在该函数里能访问的全局名字。
两个函数的返回类型都是字典。所以名字们能用 keys() 函数摘取。
reload() 函数
当一个模块被导入到一个脚本,模块顶层部分的代码只会被执行一次。
因此,如果你想重新执行模块里顶层部分的代码,可以用 reload() 函数。该函数会重新导入之前导入过的模块。语法如下:
reload(module_name)
在这里,module_name要直接放模块的名字,而不是一个字符串形式。比如想重载 hello 模块,如下:
reload(hello)
Python中的包
包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境。
简单来说,包就是文件夹,但该文件夹下必须存在 __init__.py 文件, 该文件的内容可以为空。__init__.py 用于标识当前文件夹是一个包。
考虑一个在 package_runoob 目录下的 runoob1.py、runoob2.py、__init__.py 文件,test.py 为测试调用包的代码,目录结构如下:
test.py
package_runoob
|-- __init__.py
|-- runoob1.py
|-- runoob2.py
源代码如下:
package_runoob/runoob1.py
package_runoob/runoob2.py
现在,在 package_runoob 目录下创建 __init__.py:
package_runoob/__init__.py
然后我们在 package_runoob 同级目录下创建 test.py 来调用 package_runoob 包
test.py
输出结果:
package_runoob 初始化
I'm in runoob1
I'm in runoob2
Python 文件I/O
本章只讲述所有基本的 I/O 函数,更多函数请参考Python标准文档。
打印到屏幕
最简单的输出方法是用print语句,你可以给它传递零个或多个用逗号隔开的表达式。此函数把你传递的表达式转换成一个字符串表达式,并将结果写到标准输出如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
print "Python 是一个非常棒的语言,不是吗?"
标准屏幕上会产生以下结果:
Python 是一个非常棒的语言,不是吗?
读取键盘输入
Python提供了两个内置函数从标准输入读入一行文本,默认的标准输入是键盘。如下:
- raw_input
- input
raw_input函数
raw_input([prompt]) 函数从标准输入读取一个行,并返回一个字符串(去掉结尾的换行符):
#!/usr/bin/python
# -*- coding: UTF-8 -*-
str = raw_input("请输入:")
print "你输入的内容是: ", str
这将提示你输入任意字符串,然后在屏幕上显示相同的字符串。当我输入"Hello Python!",它的输出如下:
请输入:Hello Python!
你输入的内容是: Hello Python!
input函数
input([prompt]) 函数和 raw_input([prompt]) 函数基本类似,但是 input 可以接收一个Python表达式作为输入,并将运算结果返回。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
str = input("请输入:")
print "你输入的内容是: ", str
这会产生如下的对应着输入的结果:
请输入:[x*5 for x in range(2,10,2)]
你输入的内容是: [10, 20, 30, 40]
打开和关闭文件
现在,您已经可以向标准输入和输出进行读写。现在,来看看怎么读写实际的数据文件。
Python 提供了必要的函数和方法进行默认情况下的文件基本操作。你可以用 file 对象做大部分的文件操作。
open 函数
你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。
语法:
file object =open(file_name,[, access_mode, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None])
参数说明:
- file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。
- access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
- buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
不同模式打开文件的完全列表:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
下图很好的总结了这几种模式:

| 模式 | r | r+ | w | w+ | a | a+ |
|---|---|---|---|---|---|---|
| 读 | + | + | + | + | ||
| 写 | + | + | + | + | + | |
| 创建 | + | + | + | + | ||
| 覆盖 | + | + | ||||
| 指针在开始 | + | + | + | + | ||
| 指针在结尾 | + | + |
File对象的属性
一个文件被打开后,你有一个file对象,你可以得到有关该文件的各种信息。
以下是和file对象相关的所有属性的列表:
| 属性 | 描述 |
|---|---|
| file.closed | 返回true如果文件已被关闭,否则返回false。 |
| file.mode | 返回被打开文件的访问模式。 |
| file.name | 返回文件的名称。 |
| file.softspace | 如果用print输出后,必须跟一个空格符,则返回false。否则返回true。 |
如下实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "w")
print "文件名: ", fo.name
print "是否已关闭 : ", fo.closed
print "访问模式 : ", fo.mode
print "末尾是否强制加空格 : ", fo.softspace
以上实例输出结果:
文件名: foo.txt
是否已关闭 : False
访问模式 : w
末尾是否强制加空格 : 0
close()方法
File 对象的 close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。
当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
语法:
fileObject.close()
例子:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "w")
print "文件名: ", fo.name
# 关闭打开的文件
fo.close()
以上实例输出结果:
文件名: foo.txt
读写文件:
file对象提供了一系列方法,能让我们的文件访问更轻松。来看看如何使用read()和write()方法来读取和写入文件。
write()方法
write()方法可将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
write()方法不会在字符串的结尾添加换行符('\n'):
语法:
fileObject.write(string)
在这里,被传递的参数是要写入到已打开文件的内容。
例子:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "w")
fo.write( "www.runoob.com!\nVery good site!\n")
# 关闭打开的文件
fo.close()
上述方法会创建foo.txt文件,并将收到的内容写入该文件,并最终关闭文件。如果你打开这个文件,将看到以下内容:
$ cat foo.txt
www.runoob.com!
Very good site!
read()方法
read()方法从一个打开的文件中读取一个字符串。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
语法:
fileObject.read([count])
在这里,被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
例子:
这里我们用到以上创建的 foo.txt 文件。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "r+")
str = fo.read(10)
print "读取的字符串是 : ", str
# 关闭打开的文件
fo.close()
以上实例输出结果:
读取的字符串是 : www.runoob
下表列出了 file 对象常用的函数:
| 序号 | 方法及描述 |
|---|---|
| 1 |
关闭文件。关闭后文件不能再进行读写操作。 |
| 2 |
刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| 3 |
返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| 4 |
如果文件连接到一个终端设备返回 True,否则返回 False。 |
| 5 |
返回文件下一行。 |
| 6 |
从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| 7 |
读取整行,包括 "\n" 字符。 |
| 8 |
读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。 |
| 9 |
设置文件当前位置 |
| 10 |
返回文件当前位置。 |
| 11 |
截取文件,截取的字节通过size指定,默认为当前文件位置。 |
| 12 |
将字符串写入文件,返回的是写入的字符长度。 |
| 13 |
向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
文件定位
tell()方法告诉你文件内的当前位置, 换句话说,下一次的读写会发生在文件开头这么多字节之后。
seek(offset [,from])方法改变当前文件的位置。Offset变量表示要移动的字节数。From变量指定开始移动字节的参考位置。
如果from被设为0,这意味着将文件的开头作为移动字节的参考位置。如果设为1,则使用当前的位置作为参考位置。如果它被设为2,那么该文件的末尾将作为参考位置。
例子:
就用我们上面创建的文件foo.txt。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "r+")
str = fo.read(10)
print "读取的字符串是 : ", str
# 查找当前位置
position = fo.tell()
print "当前文件位置 : ", position
# 把指针再次重新定位到文件开头
position = fo.seek(0, 0)
str = fo.read(10)
print "重新读取字符串 : ", str
# 关闭打开的文件
fo.close()
以上实例输出结果:
读取的字符串是 : www.runoob
当前文件位置 : 10
重新读取字符串 : www.runoob
重命名和删除文件
Python的os模块提供了帮你执行文件处理操作的方法,比如重命名和删除文件。
要使用这个模块,你必须先导入它,然后才可以调用相关的各种功能。
rename() 方法
rename() 方法需要两个参数,当前的文件名和新文件名。
语法:
os.rename(current_file_name, new_file_name)
例子:
下例将重命名一个已经存在的文件test1.txt。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
# 重命名文件test1.txt到test2.txt。
os.rename( "test1.txt", "test2.txt" )
remove()方法
你可以用remove()方法删除文件,需要提供要删除的文件名作为参数。
语法:
os.remove(file_name)
例子:
下例将删除一个已经存在的文件test2.txt。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
# 删除一个已经存在的文件test2.txt
os.remove("test2.txt")
Python里的目录:
所有文件都包含在各个不同的目录下,不过Python也能轻松处理。os模块有许多方法能帮你创建,删除和更改目录。
mkdir()方法
可以使用os模块的mkdir()方法在当前目录下创建新的目录们。你需要提供一个包含了要创建的目录名称的参数。
语法:
os.mkdir("newdir")
例子:
下例将在当前目录下创建一个新目录test。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
# 创建目录test
os.mkdir("test")
chdir()方法
可以用chdir()方法来改变当前的目录。chdir()方法需要的一个参数是你想设成当前目录的目录名称。
语法:
os.chdir("newdir")
例子:
下例将进入"/home/newdir"目录。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
# 将当前目录改为"/home/newdir"
os.chdir("/home/newdir")
getcwd()方法:
getcwd()方法显示当前的工作目录。
语法:
os.getcwd()
rmdir()方法
rmdir()方法删除目录,目录名称以参数传递。
在删除这个目录之前,它的所有内容应该先被清除。
目录的完全合规的名称必须被给出,否则会在当前目录下搜索该目录
语法:
os.rmdir('dirname')
os 模块提供了非常丰富的方法用来处理文件和目录。常用的方法如下表所示:
| 序号 | 方法及描述 |
|---|---|
| 1 |
检验权限模式 |
| 2 |
改变当前工作目录 |
| 3 |
设置路径的标记为数字标记。 |
| 4 |
更改权限 |
| 5 |
更改文件所有者 |
| 6 |
改变当前进程的根目录 |
| 7 |
关闭文件描述符 fd |
| 8 |
os.closerange(fd_low, fd_high) 关闭所有文件描述符,从 fd_low (包含) 到 fd_high (不包含), 错误会忽略 |
| 9 |
复制文件描述符 fd |
| 10 |
将一个文件描述符 fd 复制到另一个 fd2 |
| 11 |
通过文件描述符改变当前工作目录 |
| 12 |
改变一个文件的访问权限,该文件由参数fd指定,参数mode是Unix下的文件访问权限。 |
| 13 |
修改一个文件的所有权,这个函数修改一个文件的用户ID和用户组ID,该文件由文件描述符fd指定。 |
| 14 |
强制将文件写入磁盘,该文件由文件描述符fd指定,但是不强制更新文件的状态信息。 |
| 15 |
os.fdopen(fd[, mode[, bufsize]]) 通过文件描述符 fd 创建一个文件对象,并返回这个文件对象 |
| 16 |
返回一个打开的文件的系统配置信息。name为检索的系统配置的值,它也许是一个定义系统值的字符串,这些名字在很多标准中指定(POSIX.1, Unix 95, Unix 98, 和其它)。 |
| 17 |
返回文件描述符fd的状态,像stat()。 |
| 18 |
返回包含文件描述符fd的文件的文件系统的信息,像 statvfs() |
| 19 |
强制将文件描述符为fd的文件写入硬盘。 |
| 20 |
裁剪文件描述符fd对应的文件, 所以它最大不能超过文件大小。 |
| 21 |
返回当前工作目录 |
| 22 |
返回一个当前工作目录的Unicode对象 |
| 23 |
如果文件描述符fd是打开的,同时与tty(-like)设备相连,则返回true, 否则False。 |
| 24 |
设置路径的标记为数字标记,类似 chflags(),但是没有软链接 |
| 25 |
修改连接文件权限 |
| 26 |
更改文件所有者,类似 chown,但是不追踪链接。 |
| 27 |
创建硬链接,名为参数 dst,指向参数 src |
| 28 |
返回path指定的文件夹包含的文件或文件夹的名字的列表。 |
| 29 |
设置文件描述符 fd当前位置为pos, how方式修改: SEEK_SET 或者 0 设置从文件开始的计算的pos; SEEK_CUR或者 1 则从当前位置计算; os.SEEK_END或者2则从文件尾部开始. 在unix,Windows中有效 |
| 30 |
像stat(),但是没有软链接 |
| 31 |
从原始的设备号中提取设备major号码 (使用stat中的st_dev或者st_rdev field)。 |
| 32 |
以major和minor设备号组成一个原始设备号 |
| 33 |
递归文件夹创建函数。像mkdir(), 但创建的所有intermediate-level文件夹需要包含子文件夹。 |
| 34 |
从原始的设备号中提取设备minor号码 (使用stat中的st_dev或者st_rdev field )。 |
| 35 |
以数字mode的mode创建一个名为path的文件夹.默认的 mode 是 0777 (八进制)。 |
| 36 |
创建命名管道,mode 为数字,默认为 0666 (八进制) |
| 37 |
os.mknod(filename[, mode=0600, device]) |
| 38 |
打开一个文件,并且设置需要的打开选项,mode参数是可选的 |
| 39 |
打开一个新的伪终端对。返回 pty 和 tty的文件描述符。 |
| 40 |
返回相关文件的系统配置信息。 |
| 41 |
创建一个管道. 返回一对文件描述符(r, w) 分别为读和写 |
| 42 |
os.popen(command[, mode[, bufsize]]) 从一个 command 打开一个管道 |
| 43 |
从文件描述符 fd 中读取最多 n 个字节,返回包含读取字节的字符串,文件描述符 fd对应文件已达到结尾, 返回一个空字符串。 |
| 44 |
返回软链接所指向的文件 |
| 45 |
删除路径为path的文件。如果path 是一个文件夹,将抛出OSError; 查看下面的rmdir()删除一个 directory。 |
| 46 |
递归删除目录。 |
| 47 |
重命名文件或目录,从 src 到 dst |
| 48 |
递归地对目录进行更名,也可以对文件进行更名。 |
| 49 |
删除path指定的空目录,如果目录非空,则抛出一个OSError异常。 |
| 50 |
获取path指定的路径的信息,功能等同于C API中的stat()系统调用。 |
| 51 |
os.stat_float_times([newvalue]) |
| 52 |
获取指定路径的文件系统统计信息 |
| 53 |
创建一个软链接 |
| 54 |
返回与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组 |
| 55 |
设置与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组为pg。 |
| 56 |
返回唯一的路径名用于创建临时文件。 |
| 57 |
返回一个打开的模式为(w+b)的文件对象 .这文件对象没有文件夹入口,没有文件描述符,将会自动删除。 |
| 58 |
为创建一个临时文件返回一个唯一的路径 |
| 59 |
返回一个字符串,它表示与文件描述符fd 关联的终端设备。如果fd 没有与终端设备关联,则引发一个异常。 |
| 60 |
删除文件路径 |
| 61 |
返回指定的path文件的访问和修改的时间。 |
| 62 |
os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]]) 输出在文件夹中的文件名通过在树中游走,向上或者向下。 |
| 63 |
写入字符串到文件描述符 fd中. 返回实际写入的字符串长度 |
| 64 |
获取文件的属性信息。 |
Python 异常处理
python提供了两个非常重要的功能来处理python程序在运行中出现的异常和错误。你可以使用该功能来调试python程序。
- 异常处理:
- 断言(Assertions)
python标准异常
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
什么是异常?
异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。
一般情况下,在Python无法正常处理程序时就会发生一个异常。
异常是Python对象,表示一个错误。
当Python脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
异常处理
捕捉异常可以使用try/except语句。
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。
如果你不想在异常发生时结束你的程序,只需在try里捕获它。
语法:
以下为简单的try....except...else的语法:
try:
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了'name'异常
except <名字>,<数据>:
<语句> #如果引发了'name'异常,获得附加的数据
else:
<语句> #如果没有异常发生
try的工作原理是,当开始一个try语句后,python就在当前程序的上下文中作标记,这样当异常出现时就可以回到这里,try子句先执行,接下来会发生什么依赖于执行时是否出现异常。
- 如果当try后的语句执行时发生异常,python就跳回到try并执行第一个匹配该异常的except子句,异常处理完毕,控制流就通过整个try语句(除非在处理异常时又引发新的异常)。
- 如果在try后的语句里发生了异常,却没有匹配的except子句,异常将被递交到上层的try,或者到程序的最上层(这样将结束程序,并打印默认的出错信息)。
- 如果在try子句执行时没有发生异常,python将执行else语句后的语句(如果有else的话),然后控制流通过整个try语句。
实例
下面是简单的例子,它打开一个文件,在该文件中的内容写入内容,且并未发生异常:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError:
print "Error: 没有找到文件或读取文件失败"
else:
print "内容写入文件成功"
fh.close()
以上程序输出结果:
$ python test.py
内容写入文件成功
$ cat testfile # 查看写入的内容
这是一个测试文件,用于测试异常!!
实例
下面是简单的例子,它打开一个文件,在该文件中的内容写入内容,但文件没有写入权限,发生了异常:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError:
print "Error: 没有找到文件或读取文件失败"
else:
print "内容写入文件成功"
fh.close()
在执行代码前为了测试方便,我们可以先去掉 testfile 文件的写权限,命令如下:
chmod -w testfile
再执行以上代码:
$ python test.py
Error: 没有找到文件或读取文件失败
使用except而不带任何异常类型
你可以不带任何异常类型使用except,如下实例:
try:
正常的操作
......................
except:
发生异常,执行这块代码
......................
else:
如果没有异常执行这块代码
以上方式try-except语句捕获所有发生的异常。但这不是一个很好的方式,我们不能通过该程序识别出具体的异常信息。因为它捕获所有的异常。
使用except而带多种异常类型
你也可以使用相同的except语句来处理多个异常信息,如下所示:
try:
正常的操作
......................
except(Exception1[, Exception2[,...ExceptionN]]]):
发生以上多个异常中的一个,执行这块代码
......................
else:
如果没有异常执行这块代码
try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。
try:
<语句>
finally:
<语句> #退出try时总会执行
raise
实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
try:
fh = open("testfile", "w")
try:
fh.write("这是一个测试文件,用于测试异常!!")
finally:
print "关闭文件"
fh.close()
except IOError:
print "Error: 没有找到文件或读取文件失败"
当在try块中抛出一个异常,立即执行finally块代码。
finally块中的所有语句执行后,异常被再次触发,并执行except块代码。
异常的参数
一个异常可以带上参数,可作为输出的异常信息参数。
你可以通过except语句来捕获异常的参数,如下所示:
try:
正常的操作
......................
except ExceptionType, Argument:
你可以在这输出 Argument 的值...
变量接收的异常值通常包含在异常的语句中。在元组的表单中变量可以接收一个或者多个值。
元组通常包含错误字符串,错误数字,错误位置。
实例
以下为单个异常的实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 定义函数
def temp_convert(var):
try:
return int(var)
except ValueError, Argument:
print "参数没有包含数字\n", Argument
# 调用函数
temp_convert("xyz");
以上程序执行结果如下:
$ python test.py
参数没有包含数字
invalid literal for int() with base 10: 'xyz'
触发异常
我们可以使用raise语句自己触发异常
raise语法格式如下:
raise [Exception [, args [, traceback]]]
语句中 Exception 是异常的类型(例如,NameError)参数标准异常中任一种,args 是自已提供的异常参数。
最后一个参数是可选的(在实践中很少使用),如果存在,是跟踪异常对象。
实例
一个异常可以是一个字符串,类或对象。 Python的内核提供的异常,大多数都是实例化的类,这是一个类的实例的参数。
定义一个异常非常简单,如下所示:
def functionName( level ):
if level < 1:
raise Exception("Invalid level!", level)
# 触发异常后,后面的代码就不会再执行
注意:为了能够捕获异常,"except"语句必须有用相同的异常来抛出类对象或者字符串。
例如我们捕获以上异常,"except"语句如下所示:
try:
正常逻辑
except Exception,err:
触发自定义异常
else:
其余代码
实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 定义函数
def mye( level ):
if level < 1:
raise Exception,"Invalid level!"
# 触发异常后,后面的代码就不会再执行
try:
mye(0) # 触发异常
except Exception,err:
print 1,err
else:
print 2
执行以上代码,输出结果为:
$ python test.py
1 Invalid level!
用户自定义异常
通过创建一个新的异常类,程序可以命名它们自己的异常。异常应该是典型的继承自Exception类,通过直接或间接的方式。
以下为与RuntimeError相关的实例,实例中创建了一个类,基类为RuntimeError,用于在异常触发时输出更多的信息。
在try语句块中,用户自定义的异常后执行except块语句,变量 e 是用于创建Networkerror类的实例。
class Networkerror(RuntimeError):
def __init__(self, arg):
self.args = arg
在你定义以上类后,你可以触发该异常,如下所示:
try:
raise Networkerror("Bad hostname")
except Networkerror,e:
print e.args
在Python中,异常也可以嵌套
1.当内层代码出现异常时,指定异常类型与实际类型不符时,则向外传,如果与外面的指定类型符合,则异常被处理,直至最外层,运用默认处理方法进行处理,即停止程序,并抛出异常信息。如下代码:

try:
try:
raise IndexError
except TypeError:
print('get handled')
except SyntaxError:
print('ok')
运行程序:
Traceback (most recent call last):
File "<pyshell#47>", line 3, in <module>
raise IndexError
IndexError
2.需要提到的是raise A from B,将一个异常与另一个异常关联起来,如果from后面的B没有被外层捕获,那么A,B异常都将抛出,例如:
try:
1/0
except Exception as E:
raise TypeError('bad') from E
运行:
Traceback (most recent call last):
File "<pyshell#4>", line 2, in <module>
1/0
ZeroDivisionError: division by zero
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<pyshell#4>", line 4, in <module>
raise TypeError('bad') from E
TypeError: bad
相反,如果外层捕获了B.则都将A异常也不会抛出:
try:
try:
1/0
except Exception as E:
raise TypeError from E
except TypeError:
print('no')
运行:
no
3.不管有没有异常发生,或者其是否被处理,finally的代码都要执行.内层被处理,先执行处理,最终执行finally.外层被处理,先执行finally,再执行处理。
try:
try:
1/0
finally:
print('finally')
except:
print('ok')
运行:
finally
ok
如果异常被处理,则停止,如果没有被处理,向外抛出,直至最终没处理,采用默认方法处理即停止程序,并抛出异常信息。
try:
try:
1/0
except Exception as E:
print('happens')
finally:
print('finally')
except E:
print('get handled')
运行:
happens
finally
Python 内置函数列表
dir() 函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。如果参数包含方法__dir__(),该方法将被调用。如果参数不包含__dir__(),该方法将最大限度地收集参数信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号