读后:ClassSR: A General Framework to Accelerate Super-Resolution Networks by Data Characteristic 密码保护
ClassSR: A General Framework to Accelerate Super-Resolution Networks by Data Characteristic
我们的目标是在大图像 (2K-8K) 上加速超分辨率 (SR) 网络。
在实际使用中,大图像通常被分解为小的子图像。
基于这种处理,我们发现不同的图像区域具有不同的恢复难度,可以由不同容量的网络进行处理。直观地说,平滑区域比复杂纹理更容易超级求解。
为了利用这个特性,我们可以采用适当的 SR 网络来处理分解后的不同子图像。
在此基础上,我们提出了一个新的解决方案管道——ClassSR,它将分类和SR结合在一个统一的框架中。
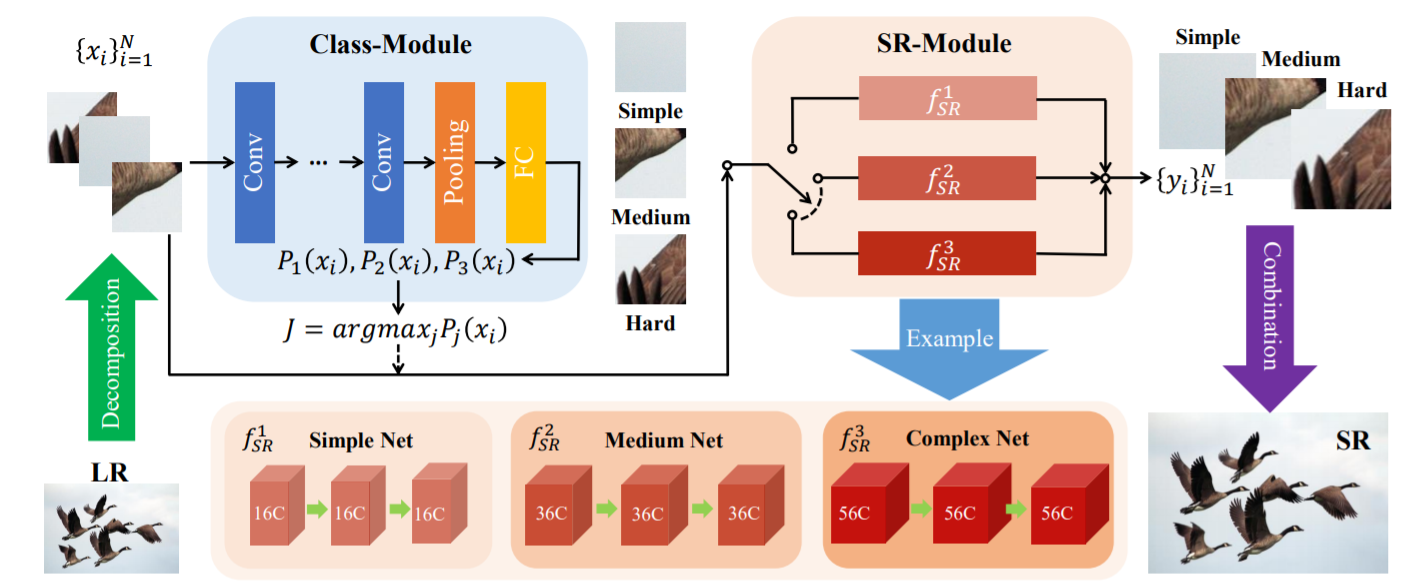
具体来说,它首先使用 Class-Module 将子图像根据恢复难度分为不同的类,然后应用 SR-Module 对不同的类进行 SR。
Class-Module 是一个常规的分类网络,而 SR-Module 是一个网络容器,由待加速的 SR 网络及其简化版本组成。
我们进一步引入了一种具有两个损失的新分类方法——Class-Loss 和 Average-Loss 来产生分类结果。
联合训练后,大部分子图像将通过较小的网络,因此可以显着降低计算成本。
实验表明,我们的 ClassSR 可以帮助大多数现有方法(例如 FSRCNN、CARN、SRResNet、RCAN)在 DIV8K 数据集上节省高达 50% 的 FLOP。这个通用框架也可以应用于其他低级视觉任务。我们进一步引入了一种新的分类方法,它有两个损失——Class-Loss 和 Average-Loss 来产生分类结果。联合训练后,大部分子图像将通过较小的网络,因此可以显着降低计算成本。
在本文中,我们研究如何在“大”输入图像上加速 SR 算法,这些图像将被上采样到至少 2K 分辨率(2048×1080)。而在实际使用中,智能手机和电视显示器的图像/视频分辨率已经达到 4K(4096 × 2160),甚至 8K(7680 × 4320)。由于最新的 SR 算法建立在 CNN 上,因此内存和计算成本将随输入大小成二次方增长。因此需要将输入分解为子图像并不断加速SR算法,以满足对真实图像实时实现的要求。
子图像分解对大图像尤其有益。首先,更多的区域恢复起来相对简单。根据我们的统计,大约 60% 的 LR 子图像 (32 × 32) 属于 DIV8K [7] 数据集的平滑区域,而 DIV2K [1] 数据集的百分比下降到 30%。因此,对于大图像,加速比会更高。其次,子图像分解有助于在实际应用中节省内存空间,对于低内存处理芯片至关重要。将子图像分发到并行处理器以进一步加速也是合理的。
为了解决上述问题并加速现有的 SR 方法,我们提出了一个新的解决方案管道,即 ClassSR,以同时执行分类和超分辨率。
该框架由两个模块组成——Class-Module 和 SR-Module。
Class-Module 是一个简单的分类网络,根据恢复难度将输入分类为特定的类,
SR-Module 是一个网络容器,将分类后的输入与对应类的 SR 网络进行处理。
他们联系在一起,需要共同训练。新颖之处在于分类方法和训练策略。
具体来说,我们引入了两个新的损失来约束分类结果。
第一个是 Class-Loss,它鼓励为单个子图像选择更高概率的类。
另一个是 AverageLoss,确保整体分类结果不会偏向单个类。
这两个损失协同工作,使分类有意义且分布良好。
还添加了 Image-Loss(L1 损失)以保证重建性能。
对于训练策略,我们首先使用 Image-Loss 预训练 SR-Module。
然后我们修复 SR-Module 并优化具有所有三个损失的 Class-Module。
最后,我们同时优化两个模块直到收敛。
该管道对于不同的 SR 网络是通用且有效的。
对于训练策略,我们首先使用 Image-Loss 预训练 SR-Module。然后我们修复 SR-Module 并优化具有所有三个损失的 Class-Module。最后,我们同时优化两个模块直到收敛。该管道对于不同的 SR 网络是通用且有效的。对于训练策略,我们首先使用 Image-Loss 预训练 SR-Module。然后我们修复 SR-Module 并优化具有所有三个损失的 Class-Module。最后,我们同时优化两个模块直到收敛。该管道对于不同的 SR 网络是通用且有效的。
总的来说,我们的贡献有三方面:
(1)我们提出了 ClassSR。它是第一个在子图像级别将分类和超分辨率结合在一起的 SR 管道。
(2)我们通过数据的特性来解决加速度问题。它使 ClassSR 与其他加速网络正交。压缩到极限的网络仍然可以通过 ClassSR 加速。
(3)我们提出了一种具有两个新损失的分类方法。它根据子图像的恢复难度划分子图像,由特定分支而不是预先确定的标签处理,因此它也可以直接应用于其他低级视觉任务。
2. Related work
1)关于加速算法
为了降低计算成本,已经提出了许多加速方法。FSRCNN [6] 和 ESPCN [18] 使用 LR 图像作为输入,并在网络末端放大特征图。LapSRN [12] 引入了一个深度拉普拉斯金字塔网络,逐渐放大特征图。CARN [2] 使用组卷积来设计级联残差网络以进行快速处理。IMDN [9] 通过拆分操作提取层次特征,然后聚合它们以节省计算。PAN [27] 采用像素注意力来获得有效的网络。
所有这些方法都旨在设计一个具有可接受的重建性能的相对轻量级的网络。相比之下,我们的 ClassSR 是一个通用框架,可以加速大多数现有的 SR 方法,即使范围从小型网络到大型网络。
2)关于分类算法:
RAISR [17] 将图像块划分为簇,并为每个簇构建适当的过滤器。它还使用有效的散列方法来降低聚类算法的复杂性。SFTGAN [19] 引入了一种新的空间特征变换层来合并高级语义先验,这是一种处理具有不同参数的不同区域的隐式方式。RL-Restore [23] 和 PathRestore [24] 将图像分解为子图像,并通过强化学习估计合适的处理路径。与它们不同的是,我们提出了一种新的分类方法来确定每个区域的处理。
3. Methods
3.1. 观察
我们首先说明我们对不同类型子图像的观察。具体来说,我们研究了 DIV2K 验证数据集 [1] 1 中 32 × 32 LR 子图像的统计特征。为了评估它们的恢复难度,我们通过 MSRResNet [20] 传递所有子图像,并根据它们的 PSNR 值对这些子图像进行排名。如图 3 所示,我们用蓝色曲线显示这些值,并将它们分成具有相同子图像数量的三类——“简单、中等、困难”。可以观察到,具有高 PSNR 值的子图像通常是平滑的,而具有低 PSNR 值的子图像包含复杂的纹理。
3.2. ClassSR 概述
单图像SR
它由两个模块组成——Class-Module 和 SR-Module,如图 4 所示。Class-Module 将输入图像分为 M 个类,而 SR-Module 包含 M 个分支(SR 网络)处理不同的输入。
具体来说,首先将大输入LR图像X分解为重叠的子图像。
ClassModule 接受每个子图像 xi 并生成一个概率向量 [P1(xi), ..., PM(xi)]。之后,我们通过选择最大概率值 J = arg maxj Pj (xi) 的索引来确定使用哪个 SR 网络。
然后 xi 将由 SR-Module 的第 J 个分支处理:yi = f J SR(xi)。
最后,我们结合所有输出子图像
3.3. 类模块
Class-Module 的目标是通过低级特征判断“输入的子图像是容易重构还是难于重构”。
如图 4 所示,我们将 Class-Module 设计为一个简单的分类网络,它包含五个卷积层、一个平均池化层和一个全连接层。卷积层负责特征提取,池化层和全连接层输出概率向量。
这个网络非常轻量级,几乎不会带来额外的计算成本。
3.4. SR-模块
SR-Module 被设计成一个容器,由几个独立的分支{fj SR}M j=1 组成。
一般来说,每个分支可以是任何基于学习的 SR 网络。
采用这个 SR 网络作为基础网络,并将其设置为最复杂的分支.
其他分支是通过降低fM SR的网络复杂度获得的。
为简单起见,我们使用每个卷积层中的通道数来控制网络复杂度。
那么每个SR分支需要多少通道呢?其原理是分支网络应获得与使用相应类中的所有数据训练的基础网络相当的结果。
例如(见表1和图4),f 1 SR、f 2 SR、f 3 SR的通道数可以是16、36、56、其中 56 是基础网络的通道号。请注意,我们还可以通过其他方式降低网络复杂度,例如减少层数(参见第 4.3.4 节),只要网络性能满足上述原则即可。
3.5. 分类方法
在训练期间,Class-Module 根据子图像对特定分支的恢复难度而不是预先确定的标签进行分类。因此,与测试不同,输入子图像 x 应该通过所有 M 个 SR 分支。此外,为了保证 Class-Module 能够接受来自重建结果的梯度传播,我们将重建的子图像 fi SR(x) 与相应的分类概率 Pi(x) 相乘,生成最终的 SR 输出 y 为:
我们只使用Image-Loss(L1 loss)来约束y,然后我们就可以自动获得分类概率。但是在测试过程中,输入只以最大概率通过 SR 分支。因此,我们提出 Lc(Class-Loss,见第 3.6.1 节)使最大概率接近 1,y 将等于概率为 1 的子图像。 注意,如果我们只采用 Image-Loss和 Class-Loss,训练会很容易收敛到一个极值点,所有图像都被归入最复杂的分支。为了避免这种有偏差的结果,我们设计了 La(Average-Loss,参见第 3.6.2 节)来约束分类结果。这是我们提出的新分类方法。
3.6. 损失函数
损失函数由三个损失组成——一个常用的 L1 损失(Image-Loss)和我们提出的两个损失 Lc(Class-Loss)和 La(Average-Loss)。具体来说,L1 用于保证图像重建质量,Lc 提高分类的有效性,La 确保每个 SR 分支可以被平等地选择。损失函数表示为:
L1: 是输出图像和地面实况之间的 1-norm distance
Lc: Class-Loss约束Class-Module的输出概率分布。 是同一子图像的每个类概率之间距离和的负数。这种损失可以大大扩大不同分类结果之间的概率差距,使最大概率值接近1。
La: 平均损失
只采用Image-Loss和Class-Loss,子图像很容易被分配到最复杂的分支。这是因为最复杂的 SR 网络很容易得到更好的结果。
为了避免这种情况,我们应该确保每个 SR 分支都有平等的机会被选中。因此,我们设计了平均损失来约束分类结果。它被表述为:
其中 B 是批量大小。La 是一个批次中每个类的平均数量(BM)与子图像数量之间的距离之和。我们使用概率和 PB j=1 Pi(xj ) 来计算子图像数量,因为统计数量不传播梯度。有了这种损失,训练期间通过每个 SR 分支的子图像数量将大致相同。
3.7. 培训策略
我们建议通过三个步骤来训练 ClassSR:
1)首先,预训练 SR-Module,
2)然后使用建议的三个损失来训练 Class-Module 并修复 SR-Module,
3)最后联合微调所有网络。
这是因为如果我们从头开始训练 Class-Module 和 SR-Module,性能会很不稳定,分类很容易陷入不好的局部最小值。
为了预训练 SR-Module,我们使用按 PSNR 值分类的数据。
具体来说,所有子图像都通过训练有素的 MSRResNet。
然后根据它们的 PSNR 值对这些子图像进行排序。接下来,前 1/3 的子图像被分配到困难类,而最后 1/3 属于简单类,
然后我们在相应的简单/中等/困难数据上训练简单/中等/复杂 SR 分支。
虽然使用 MSRResNet 获得的 PSNR 来估计不同 SR 分支的恢复难度并不完美,但它可以为 SR 分支提供一个很好的起点。
之后,我们添加 Class-Module 并修复 SR-Module 的参数。
整个模型在所有数据上使用三个损失进行训练。如图 6(a) 和图 6(b) 所示,这个过程可以给类模块一个主要的分类能力。
之后,我们放松所有参数并微调整个模型。在联合训练过程中,Class-Module 根据最终的 SR 结果细化其输出概率向量,SR-Module 根据新的分类结果进行更新。在实验中(见图 6),我们可以发现子图像被分配到不同的 SR 分支,而性能和效率同时提高。
