读后:Multi-Stage Feature Fusion Network for Video Super-Resolution
https://ieeexplore.ieee.org/document/9351768/references#references
在本文中,我们提出了一种端到端的多阶段特征融合网络,
该网络在前馈神经网络架构的不同阶段融合了支持框架的时间对齐特征和原始参考框架的空间特征。
在我们的网络中,时间对齐分支被设计为帧间时间对齐模块,用于减轻支撑框架和参考框架之间的错位。
具体来说,我们应用多尺度扩张可变形卷积作为基本操作来生成支撑框架的时间对齐特征。之后,调制特征融合分支,我们网络的另一个分支接受时间对齐的特征图作为条件输入,并在分支主干的不同阶段调制参考帧的特征。
这使得在特征融合过程的每个阶段都可以参考参考帧的特征,从而导致从 LR 到 HR 的增强特征。
利用从参考帧和每个支撑帧中提取的特征来预测采样卷积核的偏移量,
通过将学习到的动态核应用于支撑特征的特征以进行时间对齐。
基于支撑帧和参考帧的对齐特征,进行融合操作,将所有特征聚合成整个时间序列的整体特征表示,然后作为输入用于重建 HR 帧。
问题:
主要问题是特征融合操作没有考虑融合特征与原始 LR 参考帧中的视觉信息之间的差异。
这种差异可能是由于视频中的强烈运动导致的不完美的特征对齐或严重模糊造成的,
如果处理不当,可能会在上游 HR 帧重建操作中进一步放大,导致 VSR 性能下降,
理想情况下,特征融合应该以渐进的方式进行,其中原始 LR 参考帧可以在融合过程的多个阶段介入融合,使融合的特征能够忠实地保留参考帧中的视觉信息,并用于准确地重建 HR 帧(参见图 1 中的我们)。
多阶段特征融合网络
该网络在前馈神经网络架构的不同阶段融合了支撑框架的时间对齐特征和原始参考框架的空间特征.
图 2说明了我们的多阶段融合方法与现有的单阶段融合方法[1]、[16]、[17]、[20]之间的区别。
在我们的网络中,时间对齐分支在帧间时间对齐模块中设计,可用于在特征级别减轻支撑帧和参考帧之间的错位。
给定一个参考框架和一个支撑框架,我们采用VSR [16]、[17] 中常用的 DConv [21 ]来对齐它们的特征。
为了有效地探索视频帧中的上下文信息,我们建议使用多尺度扩张卷积作为基本操作来学习采样卷积核的偏移量,以便不同尺度的对象/场景可以更好地跨帧对齐(参见第 III 节-B)。
我们的实验结果表明,这样一个简单的多尺度扩张可变形对齐模块优于现有的金字塔、级联和可变形 (PCD) 对齐[17](见表 V,在 Vid4 数据集上 PSNR 得分的显着增益 = 0.14 dB)。时间对齐分支的输出是所有支持帧的特征图。
该经过调节后特征融合科接受上述时间对准特征映射作为条件输入到多个经过调节后的残余块的融合(MRFB) 作为分支主干级联。
每个 MRFB 都接受参考帧的空间变换特征图和时间对齐的条件输入特征图作为输入。
时间对齐的条件特征图用于学习一对调制参数,这些参数可以作为参考帧的空间特征图上的仿射变换应用。
在空间特征图上应用调制参数,我们最终得到一个时间调制的空间特征图,它保留了原始参考中的视觉信息(通过跳过连接),并且可以传递给下一个 MRFB 以进行下一阶段的融合。我们还将最后一个 MRFB 的输出反馈给第一个,以有效地结合低级和高级融合特征图。我们方法的优点是参考帧的视觉信息可以在特征融合过程的不同阶段流动,允许空间和时间特征在 VSR 学习目标的指导下进行深度交互。我们将通过实验证明,当在基准 VSR 数据集上进行评估时,所提出的方法可以实现优于现有技术的良好性能。
我们强调了我们工作的主要贡献:
一种新颖的 VSR 特征融合方法,允许在网络主干的不同阶段聚合空间和时间特征。
一个多尺度可变形对齐模块,用于在特征级别对齐帧。
在基准 VSR 数据集上的最先进性能。
EDVR
为了区别对待框架和其中的空间位置,Wang等人。[17]提出了一个时间和空间注意 (TSA) 特征融合模块来合并多个帧,这些帧的特征通过 PCD 对齐模块对齐,其灵感来自[16] 中提出的 TDAN 方法.
然而,这些现有方法的问题在于它们只是以一阶段的方式进行特征融合,可能无法忠实地保留参考帧中的原始视觉信息。
我们的方法接受支撑框架的时间对齐特征作为条件,并使用它们来学习多组调制参数,用于在网络骨干的不同阶段转换参考框架的空间特征。
据我们所知,这是第一项将条件特征应用于多阶段特征融合的工作。
可变形卷积的概念:
其中学习额外的偏移量以允许网络从其常规 局部邻域 获取信息,提高常规卷积的能力。
[15]首先将 DConvs 引入 VSR 并使用它们在特征级别对齐输入帧,而无需显式运动估计或图像扭曲。受 TDAN [15] 的启发,Wang等人。[17]设计一个 PCD 对齐模块,将其扩展到金字塔架构并将特征从粗到细对齐。
我们的解决方案:
我们还应用 DConvs 在特征级别对齐帧,但关键区别在于我们的 DConvs 中的偏移量是通过多尺度扩张卷积学习的,可以很好地保留对象边界细节[37],因此带来了有用的多尺度上下文信息进入对齐程序。
多尺度扩张卷积:是不是师兄们的融合部分????????
Methodology
A. Overview of the Proposed Framework
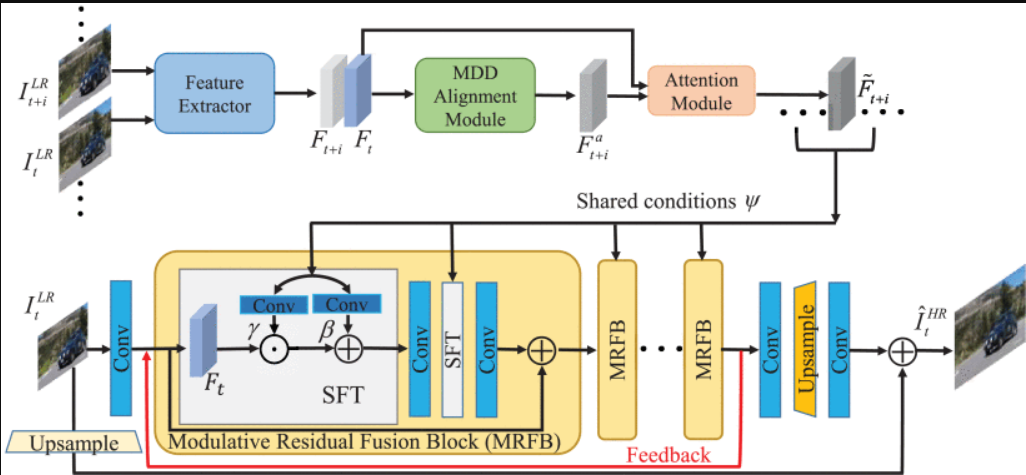
图 3。
为 VSR 提议的 MSFFN 概述。顶部分支是时间对齐子网络fTAN . 在这里,我们只用一个支撑架来演示。
底部分支是调制特征融合子网络 fMFFN ,其中时间对齐的特征来自 fTAN 被接受为共享条件来逐步调整中间特征图 fMFFN 并对其进行编码以编码对准确 VSR 至关重要的丰富时间信息。
MSFFN:
including two sub-networks: a Temporal Alignment Network (TAN) fTAN and a Modulative Feature Fusion Network (MFFN) fMFFN .
fTAN 接受参考框架 ILRt 和一个支撑框架 ILRt+i 作为输入,并将对应支撑框架的对齐特征 F~t+i 估计为,,然后,支撑框架的所有对齐特征连接为

受 [33] 中的空间特征变换 (SFT—— spatial feature transform) 的启发,我们将 ψ 作为共享的 SFT 条件,对有用的时间对齐特征信息进行编码以逐步与 ILRt 的多阶段特征融合,从而产生预测的 HR 参考帧 I^HRt 作为
B. Temporal Alignment Network
通过查看像素的时空邻域,可以避免显式运动补偿。spatio-temporal neighborhoods of pixels
explicit motion compensation
The fTAN includes three modules: feature extraction module, Multi-scale Dilated Deformable (MDD) alignment module and attention module.
特征提取模块、多尺度扩张变形(MDD)对齐模块和注意力模块。
1)Feature Extraction Module: 特征提取模块:
由一个卷积层和 5 个带有 ReLU 激活函数的残差块[38] 组成。
使用共享特征提取模块,并将它们输入到 MDD 对齐模块中。
- MDD Alignment Module: MDD对齐模块:
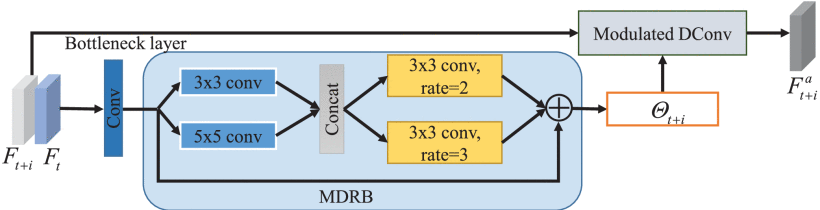
图 4。
MDD 对齐模块的图示。 特征 Ft+i 和 Ft 由卷积层组合并输入 MDRB 以预测采样参数 Θt+i 。
MDRB 由两个并行的 {3×3,5×5} 内核和两个具有不同扩张率 {2,3} 的 3×3 内核组成,可以提取具有放大感受野的多尺度特征。
最后,参数为 Θt+i 的调制 DConv 接受特征 Ft+i 作为输入,生成相应的对齐特征 Fat+i。
图 4 显示了所提出的 MDD 对齐模块的架构。
输入 Ft+i 和 Ft 连接并馈入 3×3 瓶颈层以减少特征图的通道。
遇到的问题:
最近,TDAN [16] 直接将特征图输入卷积层以预测 DConv [34] 的采样参数 Θ。然而,特征图具有有限的感受野,这可能使其无法看到帧 t+i 和 t 之间的相应像素对,尤其是在遭受大而复杂的运动时。
之后,EDVR [17] 通过探索由跨步卷积滤波strided convolution filterin生成的多尺度特征图,扩展了 TDAN 中的采样参数估计。
然而,由于特征图上的跨步操作卷积,EDVR 错过了对象边界的详细信息,导致估计不准确。
解决方案:
为了解决上述问题,我们设计了一种多尺度扩张残差块(MDRB)fMDRB multi-scale dilated residual block (MDRB),它不仅可以有效地扩大感受野 receptive field 以感知帧之间的大像素运动,
还可以 在扩张卷积的帮助下可以很好地保留对象边界细节 捕获多尺度上下文信息。
具体的是:
首先堆叠两个 3 × 3 和 5 × 5 卷积核并行提取多尺度特征。然后,将特征输入到两个3 × 3 的 且 具有不同扩张率 = 2,3 的内核有利于扩大感受野,同时减少网格效应[39]。
这种简单的设计可以有效地扩大感受野,而计算成本比 EDVR [17] 中的 PCD 对齐模块低得多。
因此,即使在遭受复杂和大运动的情况下,MDRB 也有助于利用帧之间像素的时间依赖性,生成准确的采样参数Θ 作为
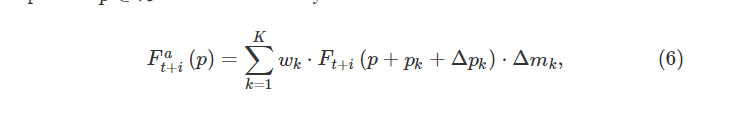
其中 pk 表示 K 个采样位置的第 k 个采样网格,wk 表示相应的权重。 例如,一个 3×3 的内核定义为 K=9 和 pk∈{(−1,−1),(−1,0),…,(1,1)} 。 由于 p+pk+Δpk 可能是小数,我们使用 [34] 中的双线性插值。
在(6)中,DConv 是在不规则位置上以动态权重进行操作,可以自适应地对输入特征进行采样。从概念上讲,(6)中的自适应采样取决于像素运动作为其采样参数Θt + i (5)是通过查看像素的宽时空邻域来预测的,使我们能够很好地处理大型和复杂的运动。
- Attention Module:注意力模块:
尽管 MDD 对齐模块具有将 Ft+i 与 Ft 对齐的潜力,但由于遮挡、区域模糊和视差问题,容易出现一些未对齐,使得不同空间位置的对齐特征信息不均等,从而导致较大的差异 到某些特征的参考系。
为了解决这个问题,我们设计了一个空间注意力掩码 M 来加权(6)中的 Fat+i
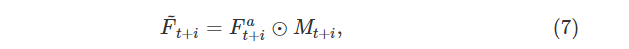
其中 Mt+i 测量 Ft 和 Fat+i 之间的像素相似度,定义为
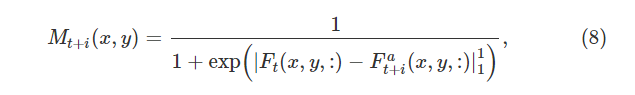
我们利用 L1 距离 |⋅|11 来更多地关注高度置信位置 (x,y)∈R2 的特征。
C. Modulative Feature Fusion Network 调制特征融合网络
通常首先通过串联融合参考框架和对齐的支撑框架的特征,然后将它们馈入重建网络以生成 HR 输出。
存在的问题:
然而,这种简单的一步融合策略有两个局限性:第一,对齐的支撑框架和参考框架在特征层面有大量相似的模式,所以简单地将它们连接起来会给重建网络带来大量的冗余,导致到昂贵的计算成本。
其次,融合只发生在开始层,因此随着深层网络的层数越来越深,来自支撑框架的互补时间信息将逐渐减弱。
- 为了解决上述问题,
如图 3的底部分支所示,我们提出了 fMFFN 它级联了一组插入在分支主干不同深度的 MRFB。
我们采用 SRResNet [8]的高级架构作为分支主干。
每个 MRFB 包含一个 SFT 层 [33],它将 (3) 中的时间对齐特征 ψ 作为共享条件,以从参考帧调制其输入特征映射 Ft。
SFT 层通过缩放和移位操作输出以 ψ 为条件的 Ft 仿射变换为
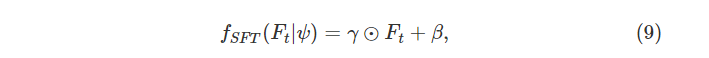
其中 γ 和 β 是缩放和移位的参数,⊙ 表示像素级乘法。 变换参数 γ 和 β 可以通过将 ψ 输入几个不同权重的卷积层来生成。
我们在每个 MRFB 的所有卷积层之后注入 SFT 层,这在多阶段融合过程中一致地增强了参考帧的视觉信息与对齐的时间信息。
最后,我们通过反馈跳过连接将从最后一个 MRFB 学到的高级特征反馈回第一个的输入层。
这种反馈机制用高层信息细化低层特征,细化特征通过调制特征融合网络,便于学习从 LR 到 HR 图像空间的复杂非线性映射,无需额外参数。
4 实验
结果:
1)定量:获得了更高的 PSNR 和 SSIM 分数。
表三反映了我们的方法能够有效地利用多帧之间的信息,灵活地解决各种运动问题
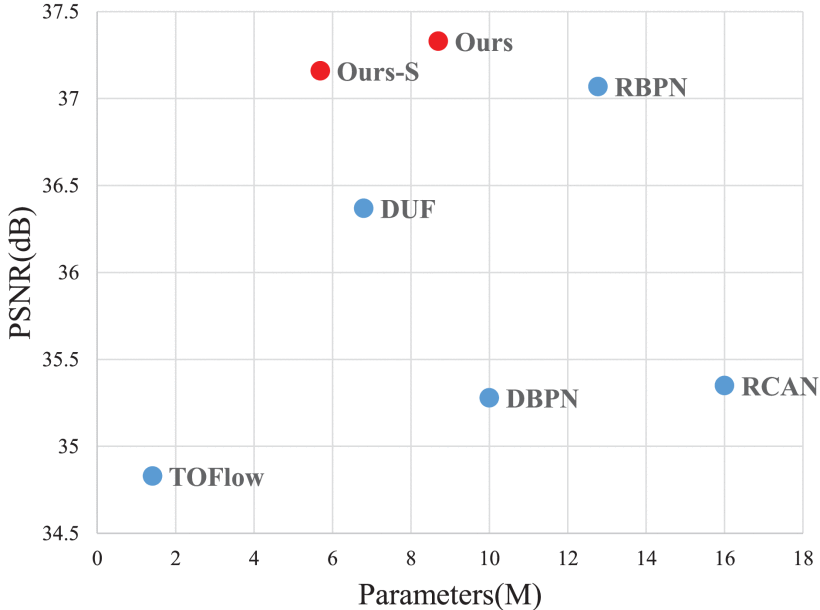
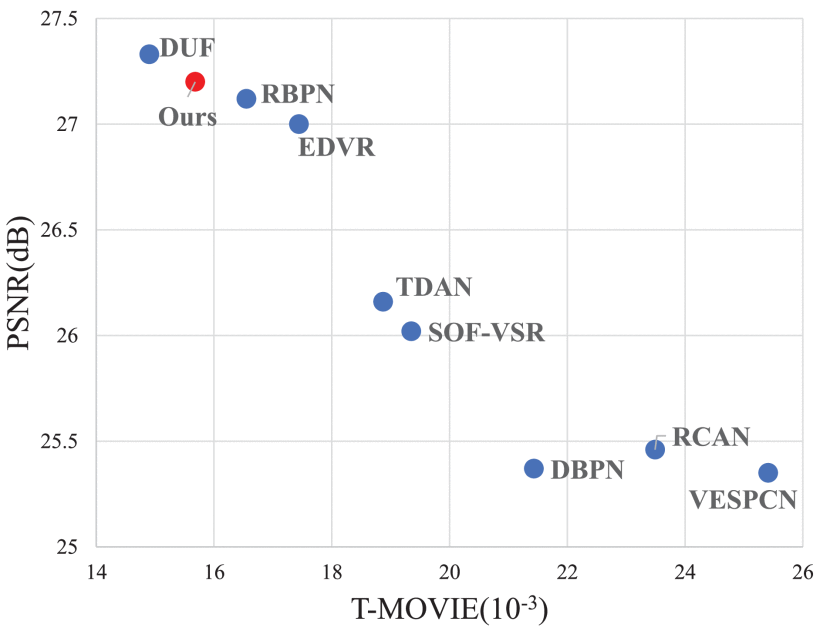
2)定性:
我们的方法是还原丰富细节和干净边缘的独特方法。



3)对于时间一致性的比较:
产生比 DBPN 更清晰的结果,但是它们仍然有不同程度的闪烁伪影。特别是,图 8(a) 中DUF 结果中的蓝线表现出严重的边界效应。相比之下,我们的方法产生的结果具有最丰富的纹理和边缘信息,忠实地描述了每幅图像中更精细的细节。

4)模型效率对比:

