读后:DeFMO: Deblurring and Shape Recovery of Fast Moving Objects (CVPR 2021)
fast moving objects (FMOs)
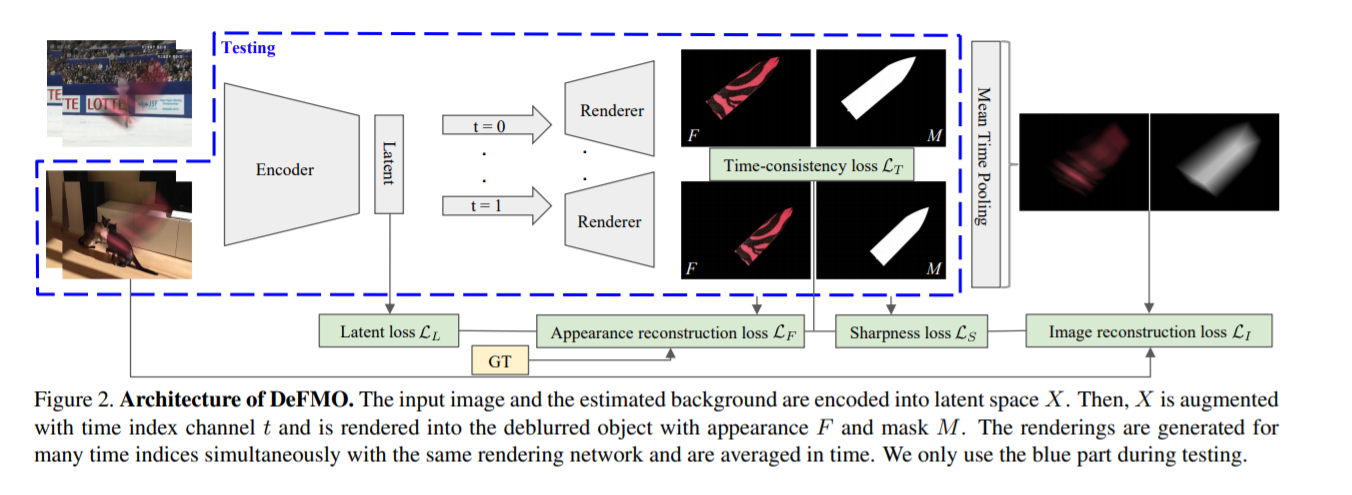
图 2. DeFMO 的架构。输入图像和估计的背景被编码到潜在空间 X。然后,X 被时间索引通道 t 增强,并被渲染成具有外观 F 和掩码 M 的去模糊对象。渲染网络并按时间平均。我们在测试时只使用蓝色部分。
FMOs are defined as objects that move over a distance larger than their size within the camera exposure time (or within a single time frame in video).
FMO 被定义为在相机曝光时间内(或在视频中的单个时间帧内)移动距离大于其尺寸的对象。
在自动驾驶中检测石头、鸟类或其他野生动物的影响也有好处。在捕获掉落或抛出的物体(如水果、树叶、飞虫、冰雹或雨)时,经常会发现 FMO。在弱光条件下或长时间曝光时,任何移动的物体都会成为 FMO。
提出了 DeFMO——第一个通过处理在 3D 旋转的 3D 轨迹上移动的快速移动物体随时间变化的复杂外观来超越这些假设的方法。
DeFMO 是一种生成模型,可重建 FMO 的清晰轮廓和外观。
1)首先,我们将模糊的快速移动物体从背景中解开到潜在空间中。
2)然后,渲染网络的目标是在一系列子帧中渲染清晰的对象,及时捕捉运动。该网络在具有复杂、高度纹理化对象的合成数据集上进行端到端训练。
3)由于受 FMO 图像形成模型启发的自监督损失函数项,我们的方法很容易推广到现实世界的数据,如图 1 所示。 DeFMO 可以应用于许多领域,例如视频时间超分辨率,数据压缩、监视、天文学和显微镜学。总的来说,本文做出了以下贡献:
• 我们展示了第一个用于 FMO 去模糊的全神经网络模型,它弥合了 FMO 去模糊、3D 建模和子帧跟踪之间的差距。
• 仅对具有新型自我监督损失的合成数据进行训练,在 FMO 的轨迹和清晰外观重建方面树立了新的艺术状态。
• 我们引入了一个具有复杂对象、纹理和背景的新合成数据集。数据集和模型实现是公开的。


deblurring model
该方法的输入是:
RGB 图像 I : D ⊂ R 2 → R 3 ,其中包含模糊 FMO 和背景 B : D → R 3 的估计值,其中不包括感兴趣的对象。
在大多数情况下,视频流是可用的,B 可以估计为几个先前帧的中值,因为这样的操作将删除所有 FMO [11]。
所需的输出是在预定义的子帧时间索引 t ∈ [0, 1] 处对所有子帧的 FMO 的清晰渲染,
为此我们估计了 4 通道 RGBA 渲染 Rt : D → R4 。
这些渲染由 RGB 部分 Ft : D → R3(FMO 的锐利外观)和 alpha matting mask Mt 😄 → R(分割为前景 FMO 和背景,图 2)组成。
我们将输入图像 I 和背景 B 编码到潜在空间 X ∈ RK。
然后,我们渲染一组子帧外观,这些外观被推为清晰、时间一致、独立于背景,并重建具有以下图像形成模型的输入图像

这是分段常数 FMO 形成模型 (2) 的推广。我们直接在所需位置渲染对象,而不是 (1) 和 (2)。我们没有解开轨迹模糊内核 Ht,它们只是我们概括 (3) 中的狄拉克增量。
外观 Ft 乘以掩码 Mt 取代了约束 Ft ≤ Mt,例如预测掩码中的低值将意味着 FtMt 中的低值。
我们假设输入图像 I = I0:1。
对于训练,我们将输入帧的持续时间划分为 N 个等距部分以生成子帧,并在集合 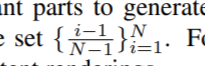
上评估 t。对于测试,任何 t ∈ [0, 1] 都会产生一致的渲染。
从技术上讲,我们渲染图像,因为它们是在几乎为零的曝光时间下捕获的。子帧时间索引 t 处的此类图像被捕获为 It = limδ→0 It−δ:t+δ = FtMt + (1 − Mt)B。
在实践中,我们特意为定量评估添加时间模糊以匹配高速相机帧(参见评估第 5 节)。这种时间模糊是由 l 产生的时间超分辨率,{Ik/l:(k+?)/l} l−1 k=0,其中 ? 是暴露分数。
生成零曝光时间图像的能力可以在任何曝光时间下创建任何帧速率。
3.1. 训练损失
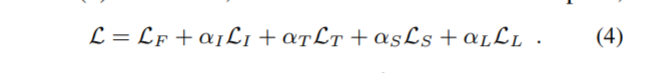
主要目标是获得不包含背景 (LL) 的对象 (LF) 的清晰 (LS) 重建,随时间平滑移动 (LT),并根据广义形成模型 (LI) 重建输入图像 (LI) 3)。
Appearance reconstruction loss LF
外观重建损失 LF :捕获对象外观和蒙版的监督子帧重建。
由于输入是单个模糊图像,我们不知道时间是向前还是向后。事实上,它们都会生成相同的模糊图像。这两种情况是无法区分的。
因此,我们评估两个方向并仅计算与ground truth 最相符的时间方向的损失。更准确地说,我们将 LF 定义为
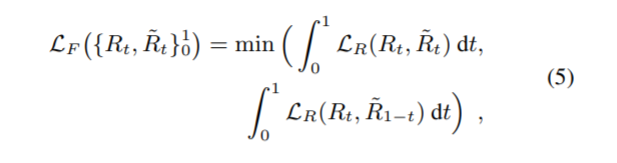

Image reconstruction loss LI 我们惩罚输入图像与从输入背景和 FMO 渲染重建的合成图像之间的差异。
Time-consistency loss LT 时间一致性损失 LT 捕获子帧渲染的时间平滑度。
Sharpness loss LS 强制进行清晰的图像重建,这是去模糊的主要任务。
Latent learning loss 对潜在空间进行建模,使得同一 FMO 的模糊图像沿相同轨迹移动但在不同背景前会生成相同的潜在表示。
Joint loss 联合损失即使是完美优化的联合损失也不一定会产生真实的渲染,因为损失函数的某些部分是有偏差的。
例如,时间一致性和锐度损失不会被地面实况渲染最小化,因为地面实况掩码在边界上不是二进制的,而且外观也不是静态的。ground truth渲染是否是联合损失的全局最小化是一个开放的研究问题。
4. 他的数据集
5. 消融实验
表 1 中的消融研究验证了自监督损失(即除监督外观重建损失 LF 之外的所有损失)对整个模型的收敛和泛化具有积极影响。
忽略锐度损失 LS 会生成更模糊的对象边界,这会保留重建质量,但会降低轨迹的精确度。仅使用外观重建损失进行训练会导致对训练集的过度拟合。
在另一个极端,完全自我监督的训练完全失败(表 1,第 4 行)。我们观察到主要问题在于识别感兴趣的对象和平衡背景运动的重要性。监督和自监督损失的组合显示出最佳性能。
讨论 ShapeNet 中不存在测试数据集中的任何对象,但仍通过我们的方法成功重建。DeFMO 还可以重建变形对象(图 5,有氧运动),即使在训练期间仅使用刚体。如果其他动态对象的运动与感兴趣的对象(例如图 1 中的排球)相似,则该方法能够同时对其他动态对象进行去模糊。
限制 当对象的外观与背景颜色相似时,问题就会变得严重不适定。例如,图 7 中标记的黑色尖端没有被重建,因为对象在黑色背景前面移动,并且有和没有尖端的重建都正确地导致几乎相同的输入图像。
该方法不适用于由透明材料制成的物体,例如瓶子、玻璃。透明度的两个来源,快速运动导致的背景-前景混合和透明材料,很难区分。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号