TTSR 纹理transformer超分辨率
纹理 Transformer 模型包括:
1)可学习的纹理提取器模块(Learnable Texture Extractor)、
2)相关性嵌入模块(Relevance Embedding)、
3)硬注意力模块(Hard Attention)、
4)软注意力模块(Soft Attention)。
后面两个是本次的重点
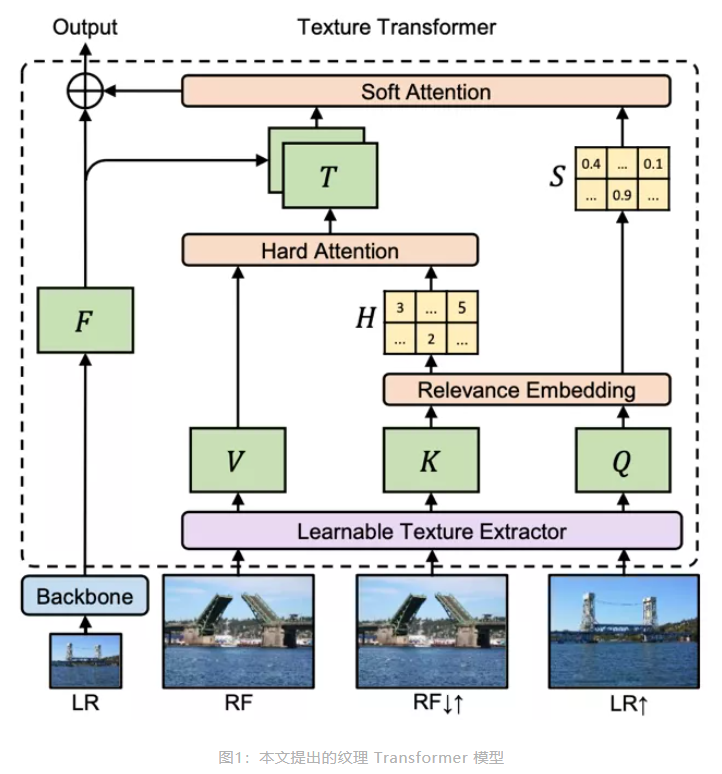
1)可学习的纹理提取器模块(Learnable Texture Extractor)
用预训练好的vgg 提取中间的浅层特征,
存在缺陷: 1. vgg做的是以 语义 为导向的 图像类别标签,以此为训练目标,,所以会跟纹理信息有差异。另,我们要的是 低层级的纹理信息。
- vgg对应的是 固定权重的 预训练好的,,缺乏灵活性。。对于不同的任务,需要提取的纹理信息是不同的。
在纹理 Transformer 中提出了一种可学习的纹理提取器。
我们做的就是 可学习的纹理提取器,,好像很有道理的亚子
2)相关性嵌入模块(Relevance Embedding)
transformer 同样有 QKV三要素,
1,Q “query”,从 LR 提取出纹理特征信息,用来进行纹理搜索 ???对应上采样???
2,K “key” ,HR ref 先下采样 再 上采样 得到跟 LR 一致的图像的纹理特征信息,
3,V “value”,HR ref 图像
!!!Q 和 K,上接 一个相关性嵌入模块来 建立 LR 输入图像和 Ref 之间的关系。
以内积的方式计算 Q 和 K 中的特征块两两之间的相关性。
内积越大的地方代表两个特征块之间的相关性越强,可迁移的高频纹理信息越多。
相关性嵌入模块会输出一个硬注意力图和一个软注意力图。
硬注意力图 记录了 对 Q 中的每一个特征块,K 中对应的 最相关的特征块的 位置;
软注意力图 记录了 这个最相关的特征块的具体相关性,即内积大小。
3)硬注意力模块(Hard Attention)
利用硬注意力图中所记录的位置,,从 V 中迁移对应位置的特征块,进而组合成一个迁移纹理特征图 T。
T 的每个位置包含了参考图像中最相似的位置的高频纹理特征。
T 随后会与骨干网络中的特征进行通道级联,并通过一个卷积层得到融合的特征
4)软注意力模块(Soft Attention)
硬注意力模块 融合的特征会与软注意力图进行对应位置的点乘。
基于这样的设计,相关性强的纹理信息能够赋予相对更大的权重;相关性弱的纹理信息,能够因小权重得到抑制。
因此,软注意力模块能够使得迁移过来的高频纹理特征得到更准确的利用。
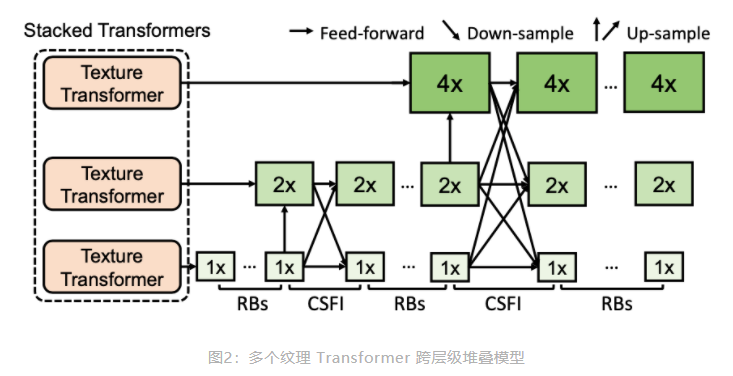
跨层级特征融合
传统 Transformer 通过堆叠使得模型具有更强的表达能力
但是对于图像,直接堆叠 效果不会太好。
!!!提出了跨层级的特征融合机制。
将所提出的纹理Transformer 应用于 x1、x2、x4 三个不同的层级,并将不同层级间的特征通过上采样或带步长的卷积进行交叉融合。
通过上述方式,不同粒度的参考图像信息会渗透到不同的层级,从而使得网络的特征表达能力增强,提高生成图像的质量。