spark
分析计算 4040
hadoop都是计算框架
spark是基于流处理,内存
Mockup
hadoop 不适合循环迭代数据流处理 IO会频繁
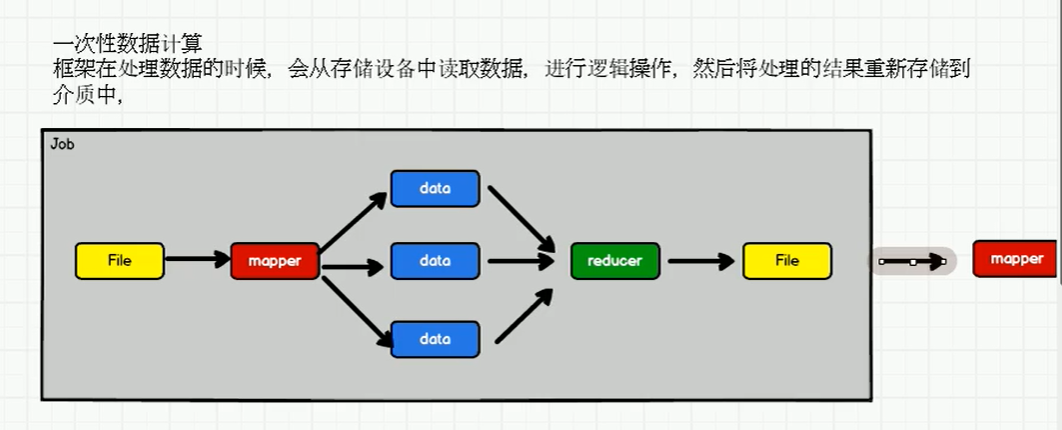
spark,memory会快一些,并将计算单元缩小到更适合并行计算和重复使用的RDD计算模型。
可以支持 复杂的数据挖掘算法和 图形计算算法
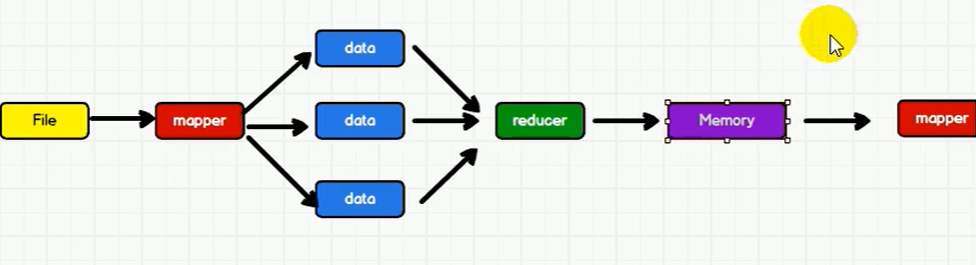
Spark和Hadoop的根本差异是多个作业之间的数据通信问题:
Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘。
Spark Task的启动时间快。Spark采用fork线程的方式,而Hadoop采用创建新的进程的方式。
Spark只有在shuffle的时候将数据写入磁盘,而Hadoop中多个MR作业之间的数据交互都要依赖于磁盘交互
Spark的缓存机制比HDFS的缓存机制高效。
由于内存资源不够导致Job执行失败,此时,MapReduce其实是一个更好的选择,所以Spark并不能完全替代MR.
spark核心模块
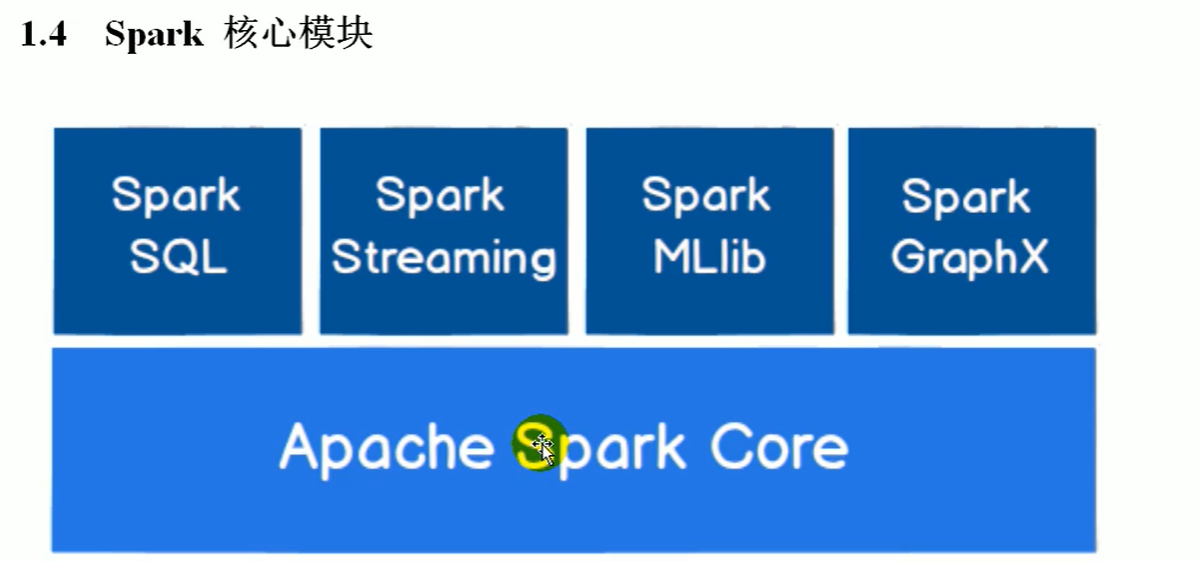
Spark MLlib 机器学习
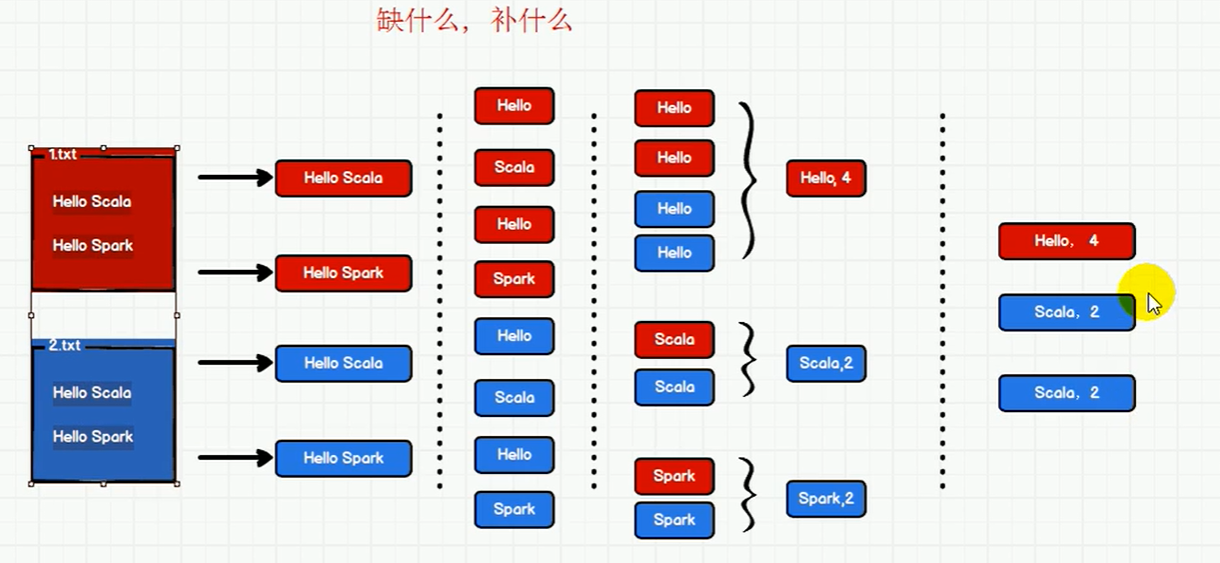
分词
package com.atguigu.bigdata.spark.core.wc
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark02_WordCount1 {
def main(args: Array[String]): Unit = {
// Application Spark框架
// TODO 建立和Spark框架的连接
// JDBC : Connection
val sparConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparConf)
// 1. 读取文件,获取一行一行的数据
// hello world
val lines: RDD[String] = sc.textFile("datas")
// 2. 将一行数据进行拆分,形成一个一个的单词(分词)
// 扁平化:将整体拆分成个体的操作
// "hello world" => hello, world, hello, world
val words: RDD[String] = lines.flatMap(_.split(" "))
// 3. 将单词进行结构的转换,方便统计 word => (word, 1)
val wordToOne = words.map(word=>(word,1))
// 4. 将转换后的数据进行分组聚合
// 相同key的value进行聚合操作
// (word, 1) => (word, sum)
val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_+_)
// 5. 将转换结果采集到控制台打印出来
val array: Array[(String, Int)] = wordToSum.collect()
array.foreach(println)
// TODO 关闭连接
sc.stop()
}
}
spark运行环境
spark运行架构
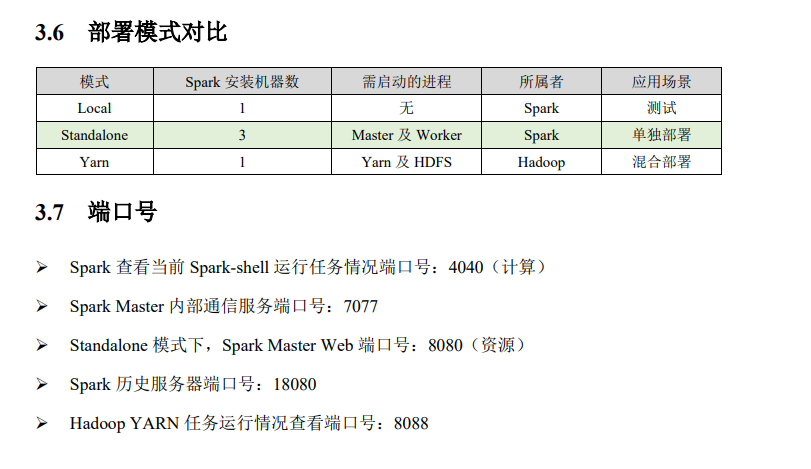
计算引擎,采用了标准 master-slave 的结构。






提交流程:
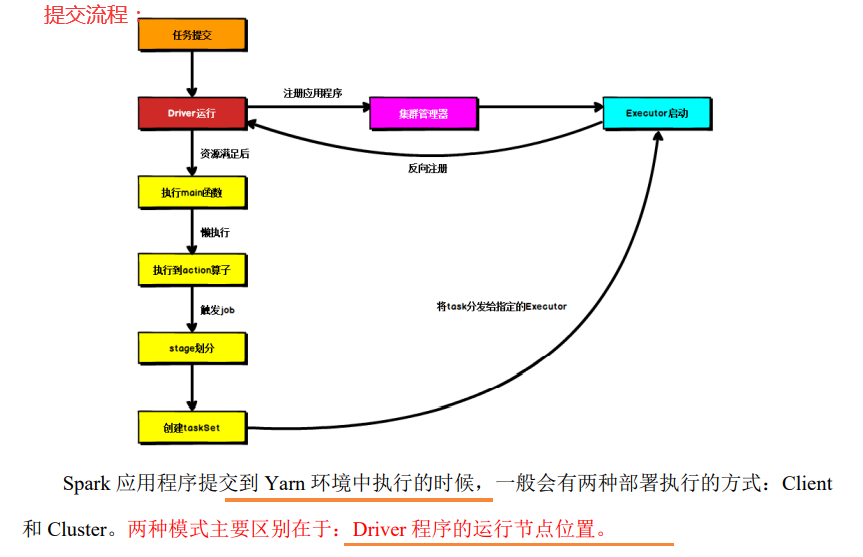
1)Yarn Client 模式


2)Yarn Cluster 模式

5. spark 核心编程
socket
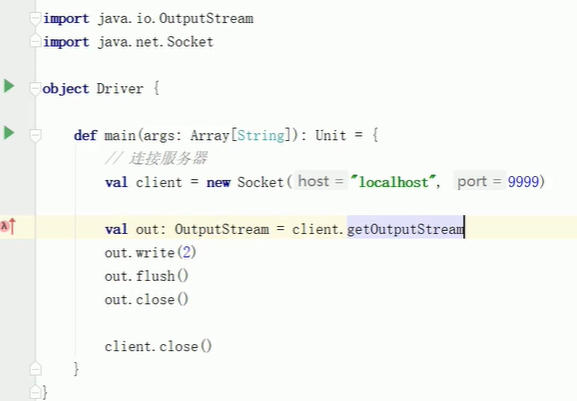
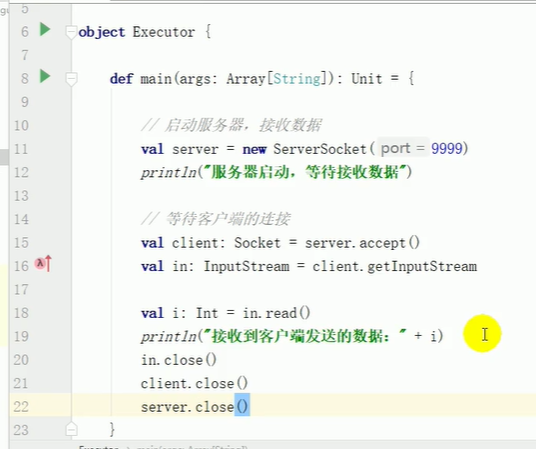
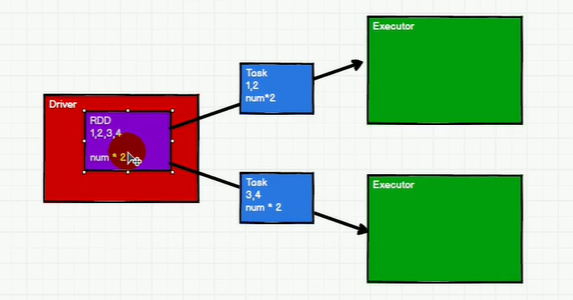
driver
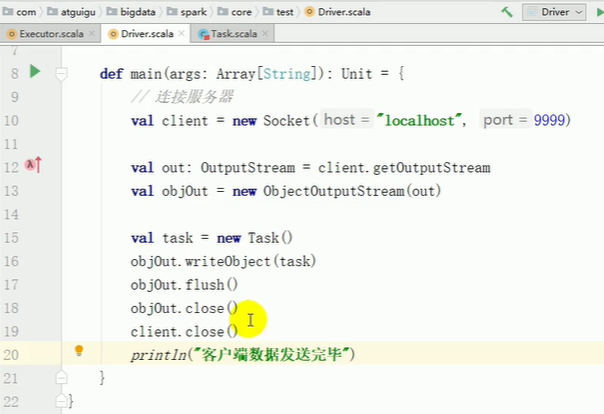
package com.atguigu.bigdata.spark.core.test
import java.io.{ObjectOutputStream, OutputStream}
import java.net.Socket
object Driver {
def main(args: Array[String]): Unit = {
// 连接服务器
val client1 = new Socket("localhost", 9999)
val client2 = new Socket("localhost", 8888)
val task = new Task()
val out1: OutputStream = client1.getOutputStream
val objOut1 = new ObjectOutputStream(out1)
val subTask = new SubTask()
subTask.logic = task.logic
subTask.datas = task.datas.take(2)
objOut1.writeObject(subTask)
objOut1.flush()
objOut1.close()
client1.close()
val out2: OutputStream = client2.getOutputStream
val objOut2 = new ObjectOutputStream(out2)
val subTask1 = new SubTask()
subTask1.logic = task.logic
subTask1.datas = task.datas.takeRight(2)
objOut2.writeObject(subTask1)
objOut2.flush()
objOut2.close()
client2.close()
println("客户端数据发送完毕")
}
}
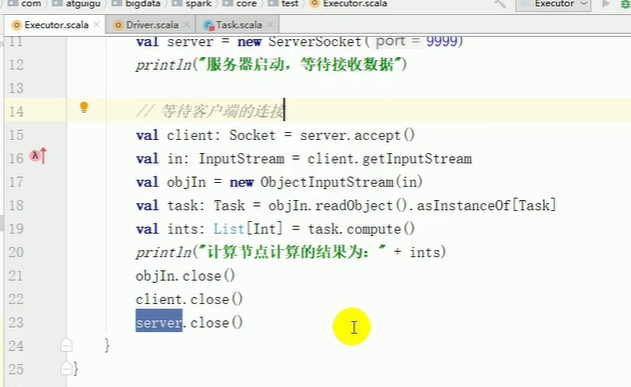
executor
package com.atguigu.bigdata.spark.core.test
import java.io.{InputStream, ObjectInputStream}
import java.net.{ServerSocket, Socket}
object Executor {
def main(args: Array[String]): Unit = {
// 启动服务器,接收数据
val server = new ServerSocket(9999)
println("服务器启动,等待接收数据")
// 等待客户端的连接
val client: Socket = server.accept()
val in: InputStream = client.getInputStream
val objIn = new ObjectInputStream(in)
val task: SubTask = objIn.readObject().asInstanceOf[SubTask]
val ints: List[Int] = task.compute()
println("计算节点[9999]计算的结果为:" + ints)
objIn.close()
client.close()
server.close()
}
}
executor2
package com.atguigu.bigdata.spark.core.test
import java.io.{InputStream, ObjectInputStream}
import java.net.{ServerSocket, Socket}
object Executor2 {
def main(args: Array[String]): Unit = {
// 启动服务器,接收数据
val server = new ServerSocket(8888)
println("服务器启动,等待接收数据")
// 等待客户端的连接
val client: Socket = server.accept()
val in: InputStream = client.getInputStream
val objIn = new ObjectInputStream(in)
val task: SubTask = objIn.readObject().asInstanceOf[SubTask]
val ints: List[Int] = task.compute()
println("计算节点[8888]计算的结果为:" + ints)
objIn.close()
client.close()
server.close()
}
}
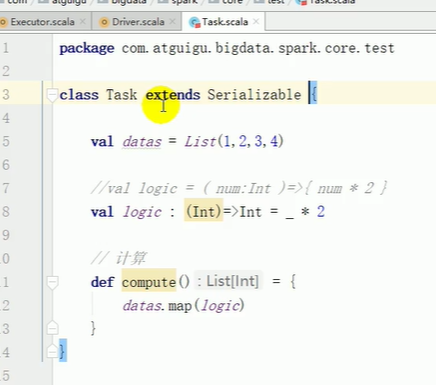
task 相当于数据结构rdd
package com.atguigu.bigdata.spark.core.test
class Task extends Serializable {
val datas = List(1,2,3,4)
//val logic = ( num:Int )=>{ num * 2 }
val logic : (Int)=>Int = _ * 2
}
subtask:
package com.atguigu.bigdata.spark.core.test
class SubTask extends Serializable {
var datas : List[Int] = _
var logic : (Int)=>Int = _
// 计算
def compute() = {
datas.map(logic)
}
}
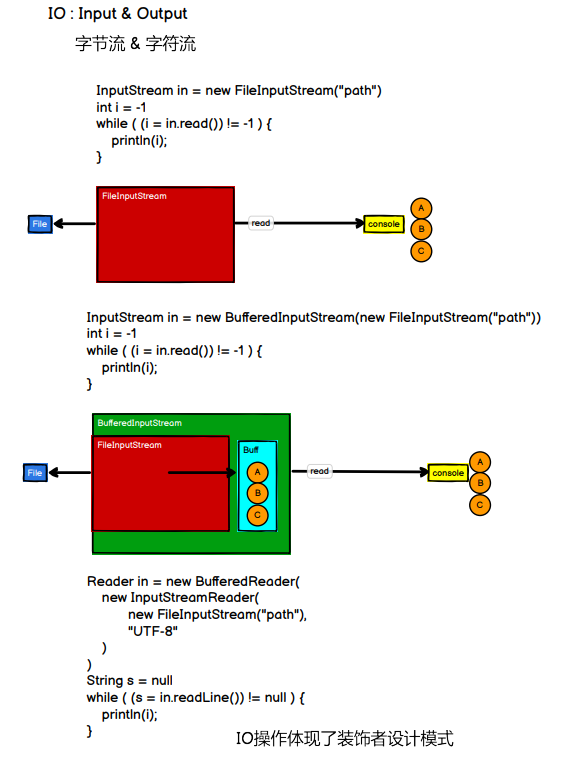
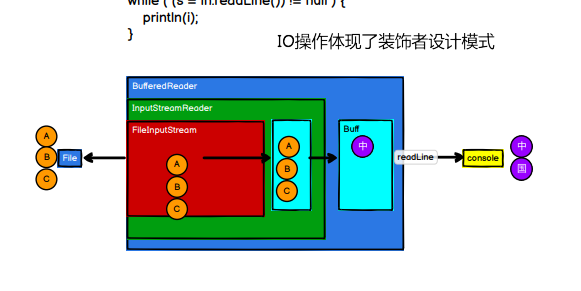
装饰器模式 对应的就是在外层进行拓展
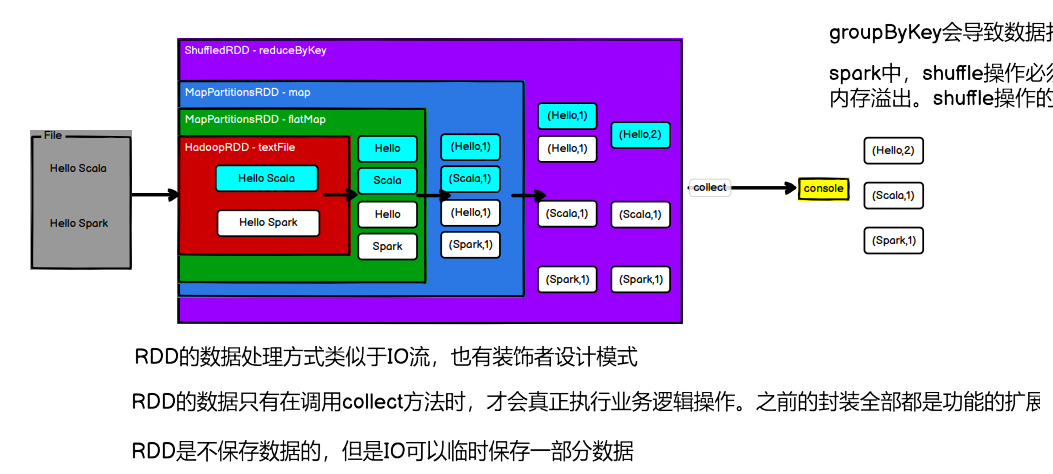
5.1 RDD

有5个核心属性
➢1 分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。

➢2 分区计算函数
Spark 在计算时,是使用分区函数对每一个分区进行计算

➢3 RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建
立依赖关系

➢4 分区器(可选)
当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区

➢5 首选位置(可选)
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算

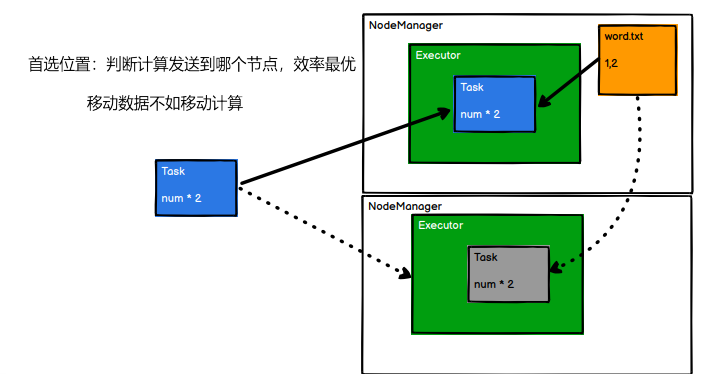
5.1.3 执行原理
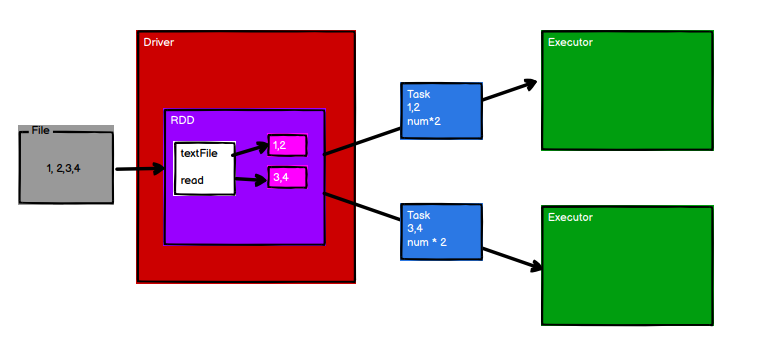
RDD 在整个流程中主要用于将逻辑进行封装,并生成 Task 发送给 Executor 节点执行计算

-
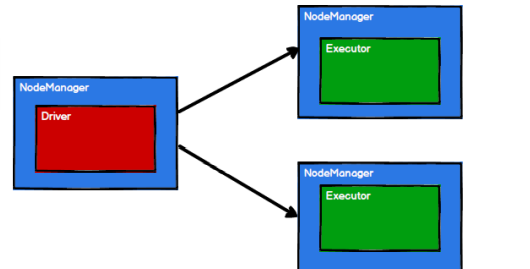
启动 Yarn 集群环境:ResourceManager NodeManager
-
Spark 通过申请资源创建调度节点和计算节点,都是在NodeManager上
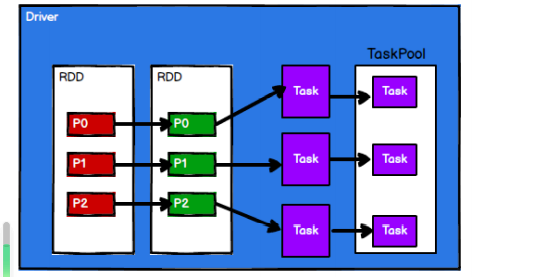
-
Spark 框架根据需求将计算逻辑根据分区划分成不同的任务 taskPool
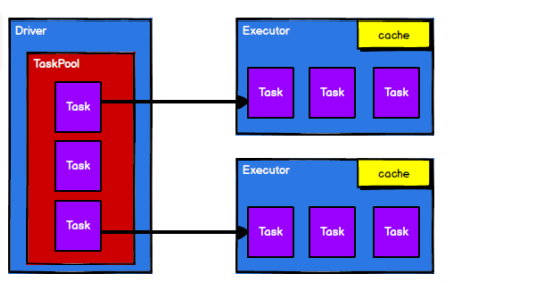
-
调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
5.1.4 RDD创建方式4种:
- 从集合(内存)中创建 RDD
从集合中创建,集合在内存中

object Spark01_RDD_Memory {
def main(args: Array[String]): Unit = {
// TODO 准备环境 local[*]表示几核
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
// TODO 创建RDD
// 从内存中创建RDD,将内存中集合的数据作为处理的数据源
val seq = Seq[Int](1,2,3,4)
// parallelize : 并行
//val rdd: RDD[Int] = sc.parallelize(seq)
// makeRDD方法在底层实现时其实就是调用了rdd对象的parallelize方法。
val rdd: RDD[Int] = sc.makeRDD(seq)
rdd.collect().foreach(println)
// TODO 关闭环境
sc.stop()
}
}

// 从文件中创建RDD,将文件中的数据作为处理的数据源
// path路径默认以当前环境的根路径为基准。可以写绝对路径,也可以写相对路径
//sc.textFile("D:\\mineworkspace\\idea\\classes\\atguigu-classes\\datas\\1.txt")
//val rdd: RDD[String] = sc.textFile("datas/1.txt")
// path路径可以是文件的具体路径,也可以目录名称
//val rdd = sc.textFile("datas")
// path路径还可以使用通配符 *
//val rdd = sc.textFile("datas/1*.txt")
// path还可以是分布式存储系统路径:HDFS
val rdd = sc.textFile("hdfs://linux1:8020/test.txt")
5.1.4.2 RDD 并行度与分区
1)分区规则:读内存数据:positions

object Spark01_RDD_Memory_Par {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
sparkConf.set("spark.default.parallelism", "5")
val sc = new SparkContext(sparkConf)
// TODO 创建RDD
// RDD的并行度 & 分区
// makeRDD方法可以传递第二个参数,这个参数表示分区的数量
// 第二个参数可以不传递的,那么makeRDD方法会使用默认值 : defaultParallelism(默认并行度)
// scheduler.conf.getInt("spark.default.parallelism", totalCores)
// spark在默认情况下,从配置对象中获取配置参数:spark.default.parallelism
// 如果获取不到,那么使用totalCores属性,这个属性取值为当前运行环境的最大可用核数
//val rdd = sc.makeRDD(List(1,2,3,4),2)
val rdd = sc.makeRDD(List(1,2,3,4))
// 将处理的数据保存成分区文件
rdd.saveAsTextFile("output")
// TODO 关闭环境
sc.stop()
}
}
2)分区规则:读文件数据:
设置的是最小分区数,所以有可能会比他大
数据是按照 Hadoop 文件读取的规则进行切片分区,而切片规则和数据读取的规则有些差异,
getSplits(JobConf job, int numSplits)
protected long computeSplitSize(long goalSize, long minSize,
long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
}
2.1)分区数量的确定
object Spark02_RDD_File_Par {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
// TODO 创建RDD
// textFile可以将文件作为数据处理的数据源,默认也可以设定分区。
// minPartitions : 最小分区数量
// math.min(defaultParallelism, 2)
//val rdd = sc.textFile("datas/1.txt")
// 如果不想使用默认的分区数量,可以通过第二个参数指定分区数
// Spark读取文件,底层其实使用的就是Hadoop的读取方式
// 分区数量的计算方式: 统计字节数的总和
// totalSize = 7 (1换行 2 换行 3 :换行算2个,所以一共是7)
// goalSize = 7 / 2 = 3(byte)
// 7 / 3 = 2...1 (1.1) + 1 = 3(分区) 这里是hadoop的思想,
// 1.1是如果多出来的超过了10%,就开辟新的分区33%,否则合并进去
val rdd = sc.textFile("datas/1.txt", 2)
rdd.saveAsTextFile("output")
// TODO 关闭环境
sc.stop()
}
}
2.2)分区数据的存储
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
// TODO 创建RDD
// TODO 数据分区的分配
// 1. 数据以行为单位进行读取
// spark读取文件,采用的是hadoop的方式读取,所以一行一行读取,和字节数没有关系
// 2. 数据读取时以偏移量为单位, 偏移量 不会被重复读取
/*
1@@ => 012
2@@ => 345
3 => 6
*/
// 3. 数据分区的偏移量范围的计算
// 0 => [0, 3] => 12
// 1 => [3, 6] => 3
// 2 => [6, 7] =>
// 【1,2】,【3】,【】
val rdd = sc.textFile("datas/1.txt", 2)
rdd.saveAsTextFile("output")
// TODO 关闭环境
sc.stop()
}

如果数据源 为多个 文件,那么计算 分区时 以文件为单位 进行分区。
5.1.4.3 RDD 转换算子
RDD 根据数据处理方式的不同将算子整体上分为 Value 类型、双 Value 类型和 Key-Value
类型
1)value类型 map && mapPartitions

scala至简原则
//val mapRDD: RDD[Int] = rdd.map(mapFunction)
//val mapRDD: RDD[Int] = rdd.map((num:Int)=>{num*2}) //如果只有一行,可省{}
//val mapRDD: RDD[Int] = rdd.map((num:Int)=>num*2) //类型可推断,省:Int
//val mapRDD: RDD[Int] = rdd.map((num)=>num*2) //参数只有一个,省括号
//val mapRDD: RDD[Int] = rdd.map(num=>num*2) //参数只出现一次,且按顺序,直接省略
val mapRDD: RDD[Int] = rdd.map(_*2)
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 算子 - map
// 1. rdd的计算一个分区内的数据是一个一个执行逻辑
// 只有前面一个数据全部的逻辑执行完毕后,才会执行下一个数据。
// 分区内数据的执行是有序的。
// 2. 不同分区数据计算是无序的。
val rdd = sc.makeRDD(List(1,2,3,4),2)
val mapRDD = rdd.map(
num => {
println(">>>>>>>> " + num)
num
}
)
val mapRDD1 = mapRDD.map(
num => {
println("######" + num)
num
}
)
mapRDD1.collect()
sc.stop()
}
val rdd = sc.makeRDD(List(1,2,3,4), 2)
// mapPartitions : 可以以分区为单位进行数据转换操作
// 但是会将整个分区的数据加载到内存进行引用
// 如果处理完的数据是不会被释放掉,存在对象的引用。
// 在内存较小,数据量较大的场合下,容易出现内存溢出。
val mpRDD: RDD[Int] = rdd.mapPartitions(
iter => {
println(">>>>>>>>>>")
iter.map(_ * 2)
}
)
mpRDD.collect().foreach(println)
// 【1,2】,【3,4】
// 【2】,【4】
val mpRDD = rdd.mapPartitions(
iter => {
List(iter.max).iterator //自己包成iterator就行
}
)
mpRDD.collect().foreach(println)
mapPartitionsWithIndex
val rdd = sc.makeRDD(List(1,2,3,4), 2)
// 【1,2】,【3,4】
val mpiRDD = rdd.mapPartitionsWithIndex(
(index, iter) => {
if ( index == 1 ) {
iter
} else {
Nil.iterator
}
}
)
val mpiRDD = rdd.mapPartitionsWithIndex(
(index, iter) => {
// 1, 2, 3, 4
//(0,1)(2,2),(4,3),(6,4)
iter.map(
num => {
(index, num)
}
)
}
)
val dataRDD1 = dataRDD.mapPartitionsWithIndex(
(index, datas) => {
datas.map(index, _)
}
)
flatMap
val flatRDD = rdd.flatMap(
data => {
data match {
case list:List[_] => list
case dat => List(dat)
}
}
)
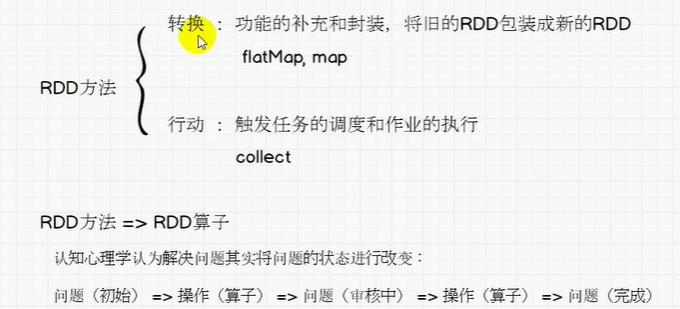
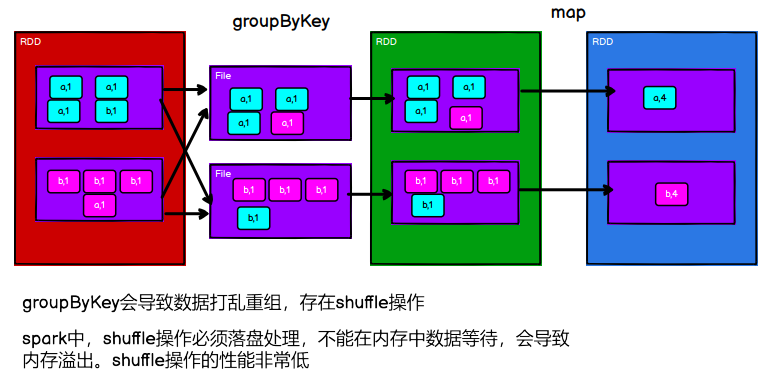
将数据根据指定的规则进行分组, 分区默认不变,但是数据会被打乱重新组合,我们将这样的操作称之为 shuffle。极限情况下,数据可能被分在同一个分区中
一个组的数据在一个分区中,但是并不是说一个分区中只有一个组
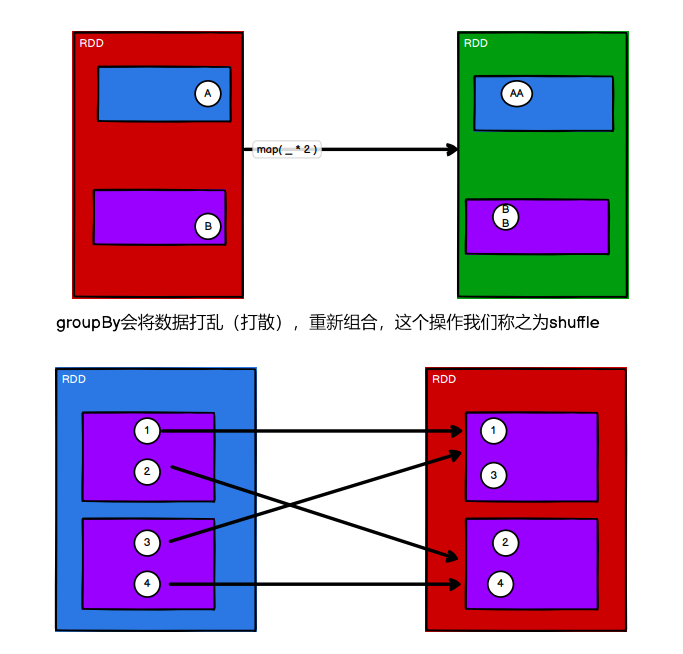
distinct
对于scala中自己的distinct是 HashSet;
在这里是分组聚合。
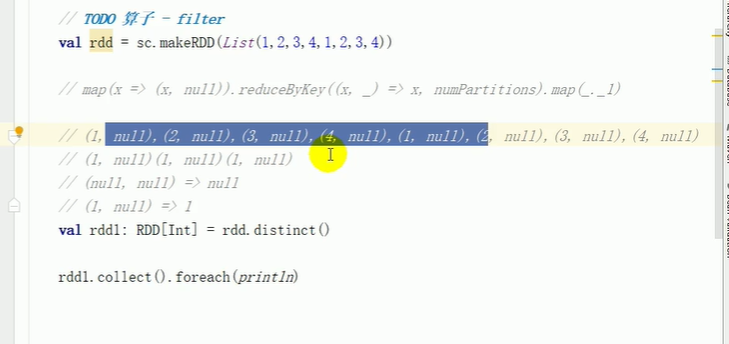
coalesce 缩小分区
不会打乱分组,有可能数据倾斜,可以 进行shuffle处理,默认false,改为true,会完全没有顺序。
如果不shuffle 扩大分区,不能行。必须shuffle=true
但是
扩大分区用 repartition,底层就是coalesce,shuffle=true .
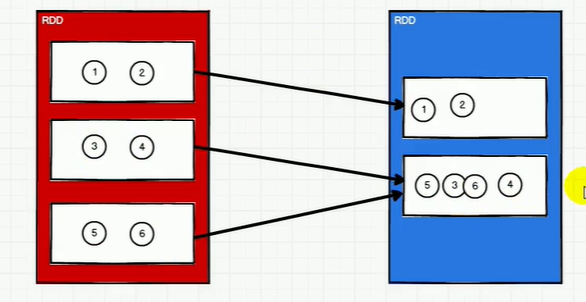
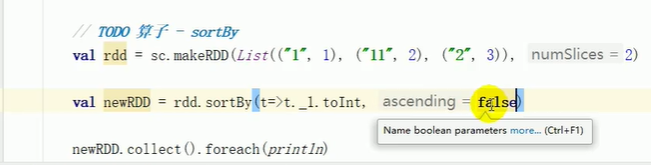
sortBy
默认升序,不会改变分区,但是中间存在shuffle操作。

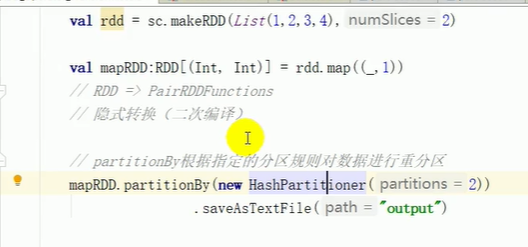
partitionBy
将数据按照指定 Partitioner 重新进行分区。Spark 默认的分区器是 HashPartition
RangePartition一般在sortByKey里面用
可以自定义partition
reduceByKey


groupByKey vs reduceByKey vs aggregateByKey vs foldByKey vs combineByKey
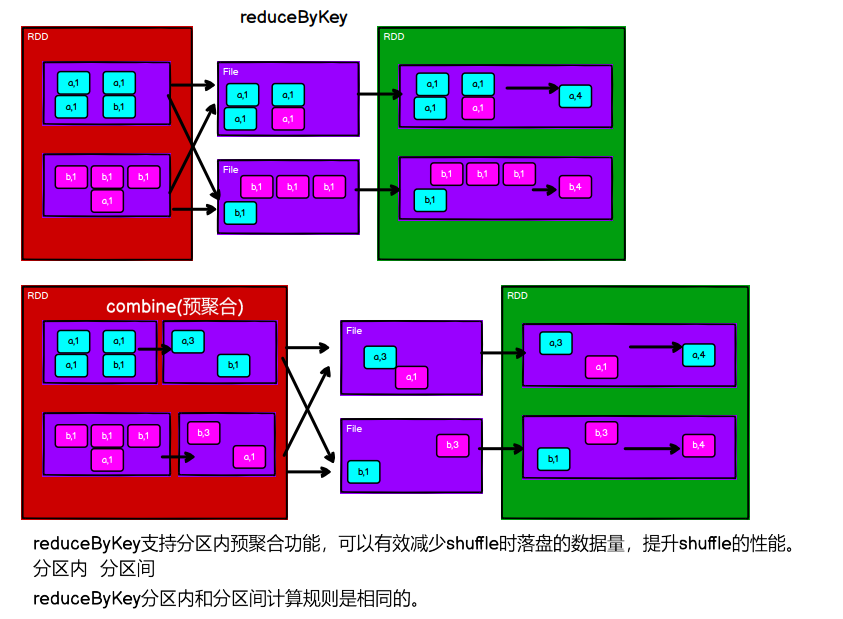

reduceByKey是分区内和分区间 操作一致
分区内求最大值,分区间求和
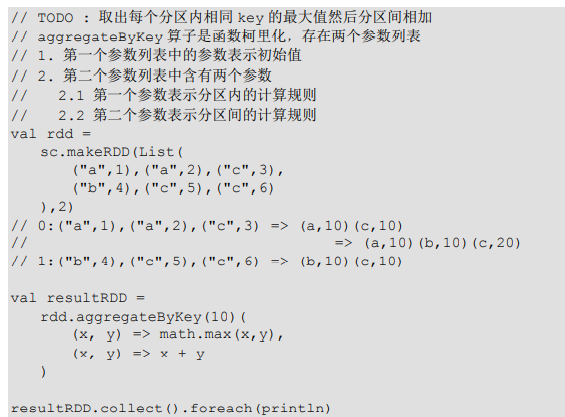
foldByKey


combineByKey
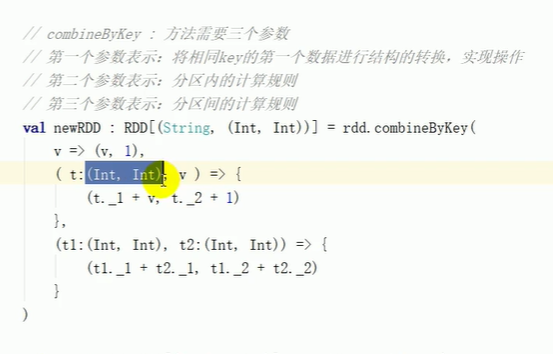
比较:

对应源码 都是三个部分:1.初始值 2.分区内计算规则 3.分区间 4.partition

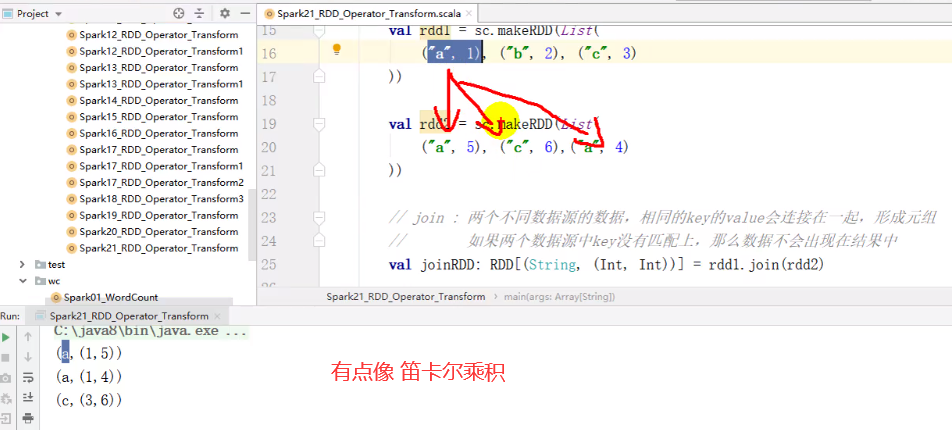
join 性能降低

小项目
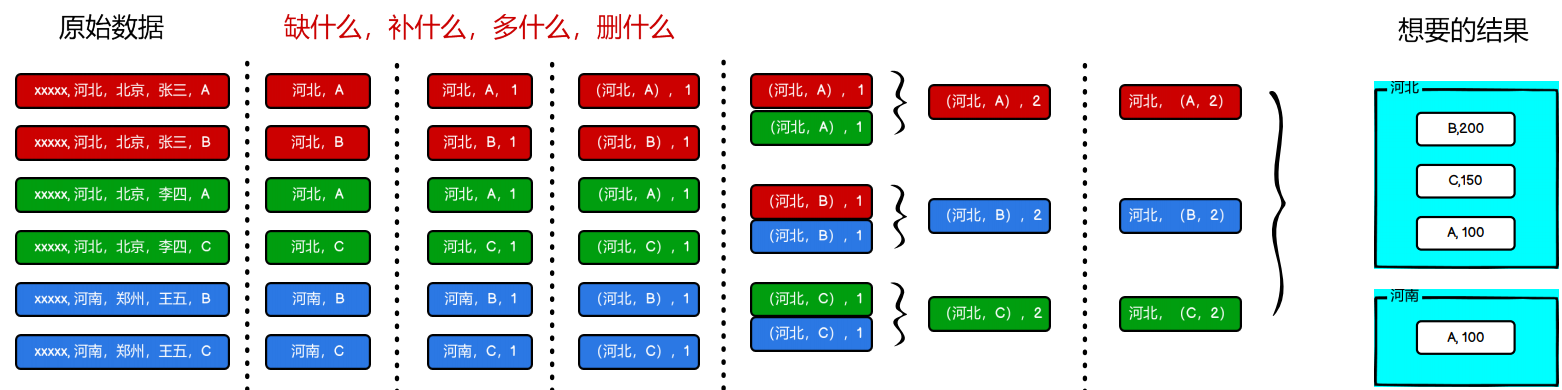
package com.atguigu.bigdata.spark.core.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark24_RDD_Req {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 案例实操
// 1. 获取原始数据:时间戳,省份,城市,用户,广告
val dataRDD = sc.textFile("datas/agent.log")
// 2. 将原始数据进行结构的转换。方便统计
// 时间戳,省份,城市,用户,广告
// =>
// ( ( 省份,广告 ), 1 )
val mapRDD = dataRDD.map(
line => {
val datas = line.split(" ")
(( datas(1), datas(4) ), 1)
}
)
// 3. 将转换结构后的数据,进行分组聚合
// ( ( 省份,广告 ), 1 ) => ( ( 省份,广告 ), sum )
val reduceRDD: RDD[((String, String), Int)] = mapRDD.reduceByKey(_+_)
// 4. 将聚合的结果进行结构的转换
// ( ( 省份,广告 ), sum ) => ( 省份, ( 广告, sum ) )
val newMapRDD = reduceRDD.map{
case ( (prv, ad), sum ) => {
(prv, (ad, sum))
}
}
// 5. 将转换结构后的数据根据省份进行分组
// ( 省份, 【( 广告A, sumA ),( 广告B, sumB )】 )
val groupRDD: RDD[(String, Iterable[(String, Int)])] = newMapRDD.groupByKey()
// 6. 将分组后的数据组内排序(降序),取前3名
val resultRDD = groupRDD.mapValues(
iter => {
iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(3)
}
)
// 7. 采集数据打印在控制台
resultRDD.collect().foreach(println)
sc.stop()
}
}
5.1.4.5 RDD 行动算子
行动算子 底层是 runJob()

转换算子 都是变成了新的 RDD
只有行动算子是 真正触发作业执行。
aggregate 和 aggregateByKey
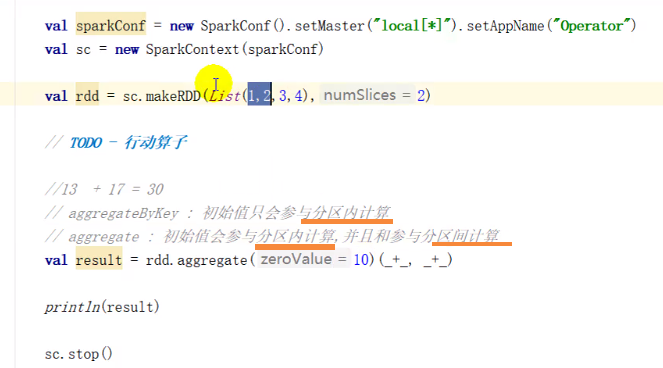
wordcount 的实现 有哪些方法
// 1. 读取文件,获取一行一行的数据
// hello world
val lines: RDD[String] = sc.textFile("datas")
// 2. 将一行数据进行拆分,形成一个一个的单词(分词)
// 扁平化:将整体拆分成个体的操作
// "hello world" => hello, world, hello, world
val words: RDD[String] = lines.flatMap(_.split(" "))
// 3. 将数据根据单词进行分组,便于统计
// (hello, hello, hello), (world, world)
val wordGroup: RDD[(String, Iterable[String])] = words.groupBy(word=>word)
// 4. 对分组后的数据进行转换
// (hello, hello, hello), (world, world)
// (hello, 3), (world, 2)
val wordToCount = wordGroup.map {
case ( word, list ) => {
(word, list.size)
}
}
// 5. 将转换结果采集到控制台打印出来
val array: Array[(String, Int)] = wordToCount.collect()
array.foreach(println)
// 1. 读取文件,获取一行一行的数据
// hello world
val lines: RDD[String] = sc.textFile("datas")
// 2. 将一行数据进行拆分,形成一个一个的单词(分词)
// 扁平化:将整体拆分成个体的操作
// "hello world" => hello, world, hello, world
val words: RDD[String] = lines.flatMap(_.split(" "))
// 3. 将单词进行结构的转换,方便统计
// word => (word, 1)
val wordToOne = words.map(word=>(word,1))
// 4. 将转换后的数据进行分组聚合
// 相同key的value进行聚合操作
// (word, 1) => (word, sum)
val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_+_)
// 5. 将转换结果采集到控制台打印出来
val array: Array[(String, Int)] = wordToSum.collect()
array.foreach(println)
object Spark03_WordCount {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparConf)
wordcount91011(sc)
sc.stop()
}
// groupBy
def wordcount1(sc : SparkContext): Unit = {
val rdd = sc.makeRDD(List("Hello Scala", "Hello Spark"))
val words = rdd.flatMap(_.split(" "))
val group: RDD[(String, Iterable[String])] = words.groupBy(word=>word)
val wordCount: RDD[(String, Int)] = group.mapValues(iter=>iter.size)
}
// groupByKey
def wordcount2(sc : SparkContext): Unit = {
val rdd = sc.makeRDD(List("Hello Scala", "Hello Spark"))
val words = rdd.flatMap(_.split(" "))
val wordOne = words.map((_,1))
val group: RDD[(String, Iterable[Int])] = wordOne.groupByKey()
val wordCount: RDD[(String, Int)] = group.mapValues(iter=>iter.size)
}
// reduceByKey
def wordcount3(sc : SparkContext): Unit = {
val rdd = sc.makeRDD(List("Hello Scala", "Hello Spark"))
val words = rdd.flatMap(_.split(" "))
val wordOne = words.map((_,1))
val wordCount: RDD[(String, Int)] = wordOne.reduceByKey(_+_)
}
// aggregateByKey
def wordcount4(sc : SparkContext): Unit = {
val rdd = sc.makeRDD(List("Hello Scala", "Hello Spark"))
val words = rdd.flatMap(_.split(" "))
val wordOne = words.map((_,1))
val wordCount: RDD[(String, Int)] = wordOne.aggregateByKey(0)(_+_, _+_)
}
// foldByKey
def wordcount5(sc : SparkContext): Unit = {
val rdd = sc.makeRDD(List("Hello Scala", "Hello Spark"))
val words = rdd.flatMap(_.split(" "))
val wordOne = words.map((_,1))
val wordCount: RDD[(String, Int)] = wordOne.foldByKey(0)(_+_)
}
// combineByKey
def wordcount6(sc : SparkContext): Unit = {
val rdd = sc.makeRDD(List("Hello Scala", "Hello Spark"))
val words = rdd.flatMap(_.split(" "))
val wordOne = words.map((_,1))
val wordCount: RDD[(String, Int)] = wordOne.combineByKey(
v=>v,
(x:Int, y) => x + y,
(x:Int, y:Int) => x + y
)
}
// countByKey
def wordcount7(sc : SparkContext): Unit = {
val rdd = sc.makeRDD(List("Hello Scala", "Hello Spark"))
val words = rdd.flatMap(_.split(" "))
val wordOne = words.map((_,1))
val wordCount: collection.Map[String, Long] = wordOne.countByKey()
}
// countByValue
def wordcount8(sc : SparkContext): Unit = {
val rdd = sc.makeRDD(List("Hello Scala", "Hello Spark"))
val words = rdd.flatMap(_.split(" "))
val wordCount: collection.Map[String, Long] = words.countByValue()
}
// reduce, aggregate, fold
def wordcount91011(sc : SparkContext): Unit = {
val rdd = sc.makeRDD(List("Hello Scala", "Hello Spark"))
val words = rdd.flatMap(_.split(" "))
// 【(word, count),(word, count)】
// word => Map[(word,1)]
val mapWord = words.map(
word => {
mutable.Map[String, Long]((word,1))
}
)
val wordCount = mapWord.reduce(
(map1, map2) => {
map2.foreach{
case (word, count) => {
val newCount = map1.getOrElse(word, 0L) + count
map1.update(word, newCount)
}
}
map1
}
)
println(wordCount)
}
}
foreach
// foreach 其实是Driver端内存集合的循环遍历方法
rdd.collect().foreach(println)
println("******************")
// foreach 其实是Executor端内存数据打印
rdd.foreach(println)
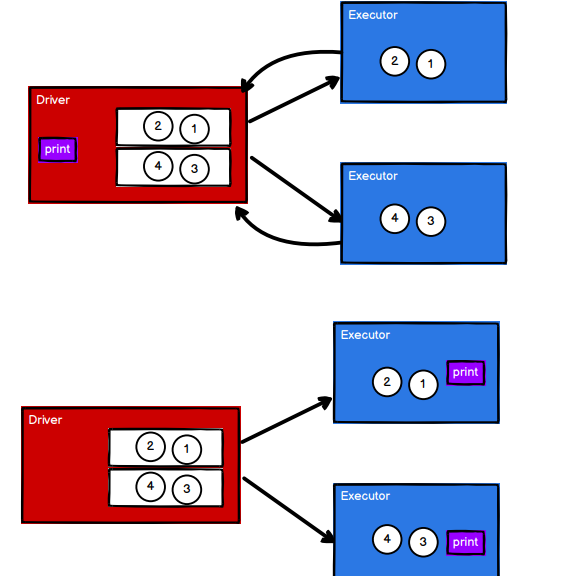
什么是算子
// 算子 : Operator(操作)
RDD的方法和Scala集合对象的方法不一样
集合对象的方法都是在同一个节点的内存中完成的。
RDD的方法可以将计算逻辑发送到Executor端(分布式节点)执行
为了区分不同的处理效果,所以将RDD的方法称之为算子。
RDD的方法外部的操作都是在Driver端执行的,而方法内部的逻辑代码是在Executor端执行。
5.1.4.6 RDD 序列化
算子的外部代码是在 driver端执行的;
foreach算子的内部是在executor端执行的
所以user需要传递到executor端,所以需要序列化
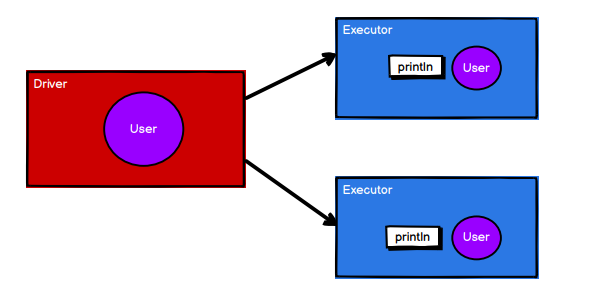
闭包检查

val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List[Int]()) //必须加上类型了就。 ,List(1, 2, 3, 4)
val user = new User()
// SparkException: Task not serializable
// NotSerializableException: com.atguigu.bigdata.spark.core.rdd.operator.action.Spark07_RDD_Operator_Action$User
// RDD算子中传递的函数是会包含闭包操作,那么就会进行检测功能
// 因为闭包要引入外部变量,需要传到executor里面,所以不需要真正的执行,只需要判断 传到闭包来的变量是不是序列化的
// 闭包就是把外部的变量 引入到 内部 形成的闭合的效果,改变变量的 生命周期 isClosure() checkSerializable()
// 闭包检测
rdd.foreach(
num => {
println("age = " + (user.age + num))
}
)
sc.stop()
}
//class User extends Serializable {
// 样例类在编译时,会自动混入序列化特质(实现可序列化接口)
//case class User() {
class User {
var age : Int = 30
}
类的 构造参数 其实是类的属性, 构造参数需要进行闭包检测,其实就等同于类进行闭包检测
所以需要进行序列化的
但是可以
//这样就可以了 val s = query
class Search(query:String){
def getMatch2(rdd: RDD[String]): RDD[String] = {
val s = query
rdd.filter(x => x.contains(s))
}
}
Kryo 序列化框架
这个序列化 比java序列化得到的结果要小,,java序列化 底层加入了transient阻止序列化
Kryo跳过了transient。
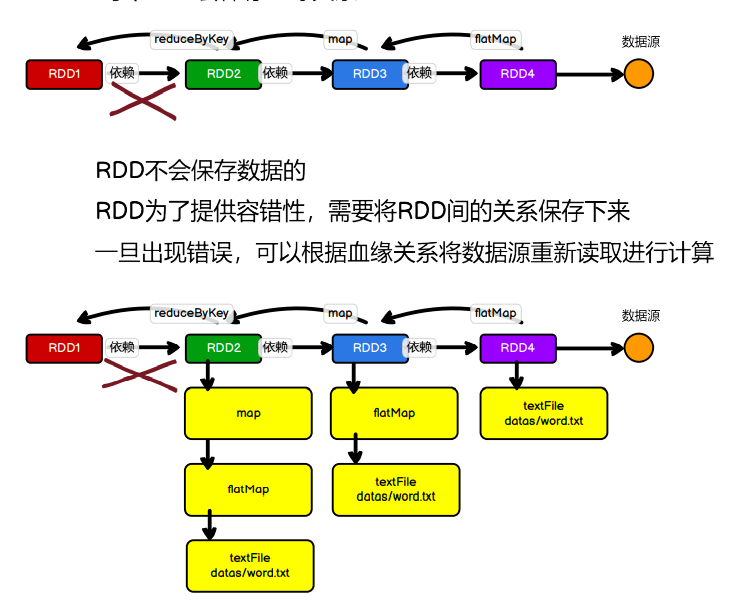
5.1.4.7 RDD 依赖关系
1)血缘关系

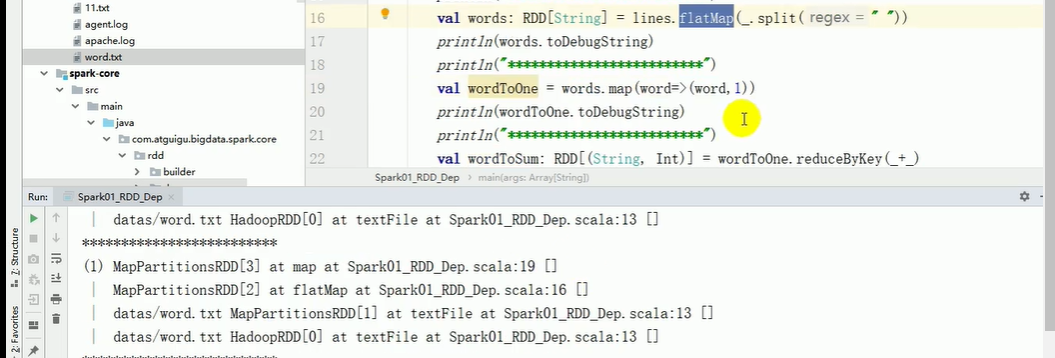
println(fileRDD.toDebugString)
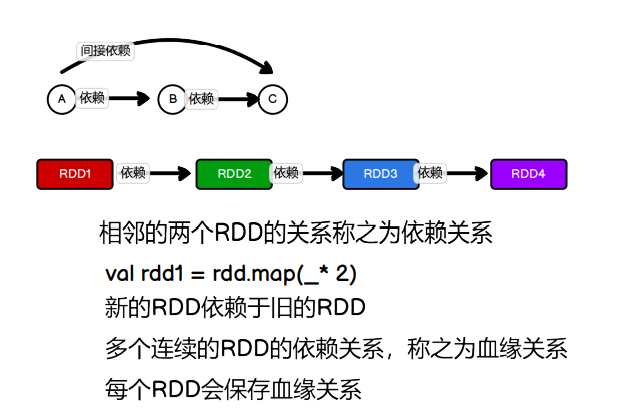
2)依赖关系 相邻两个RDD的关系
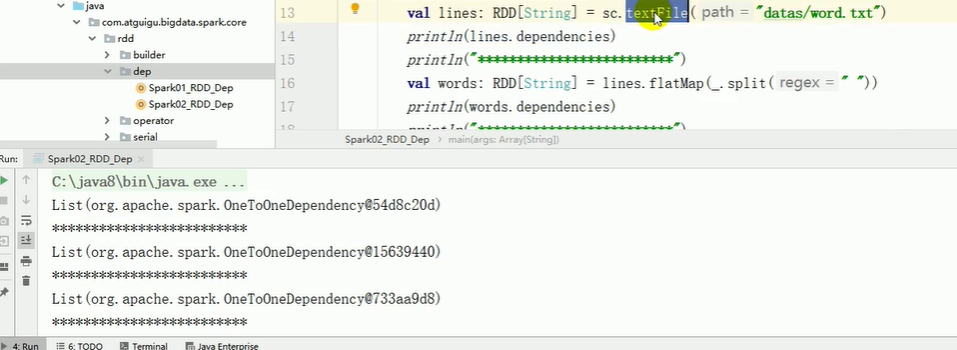
-
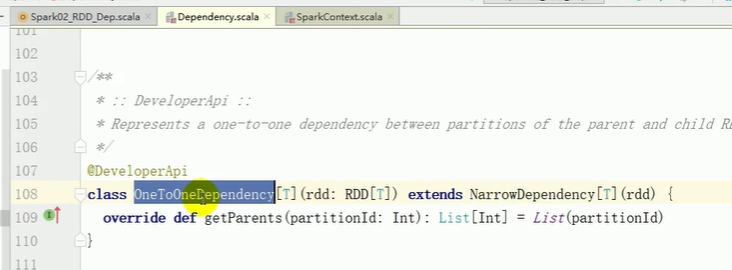
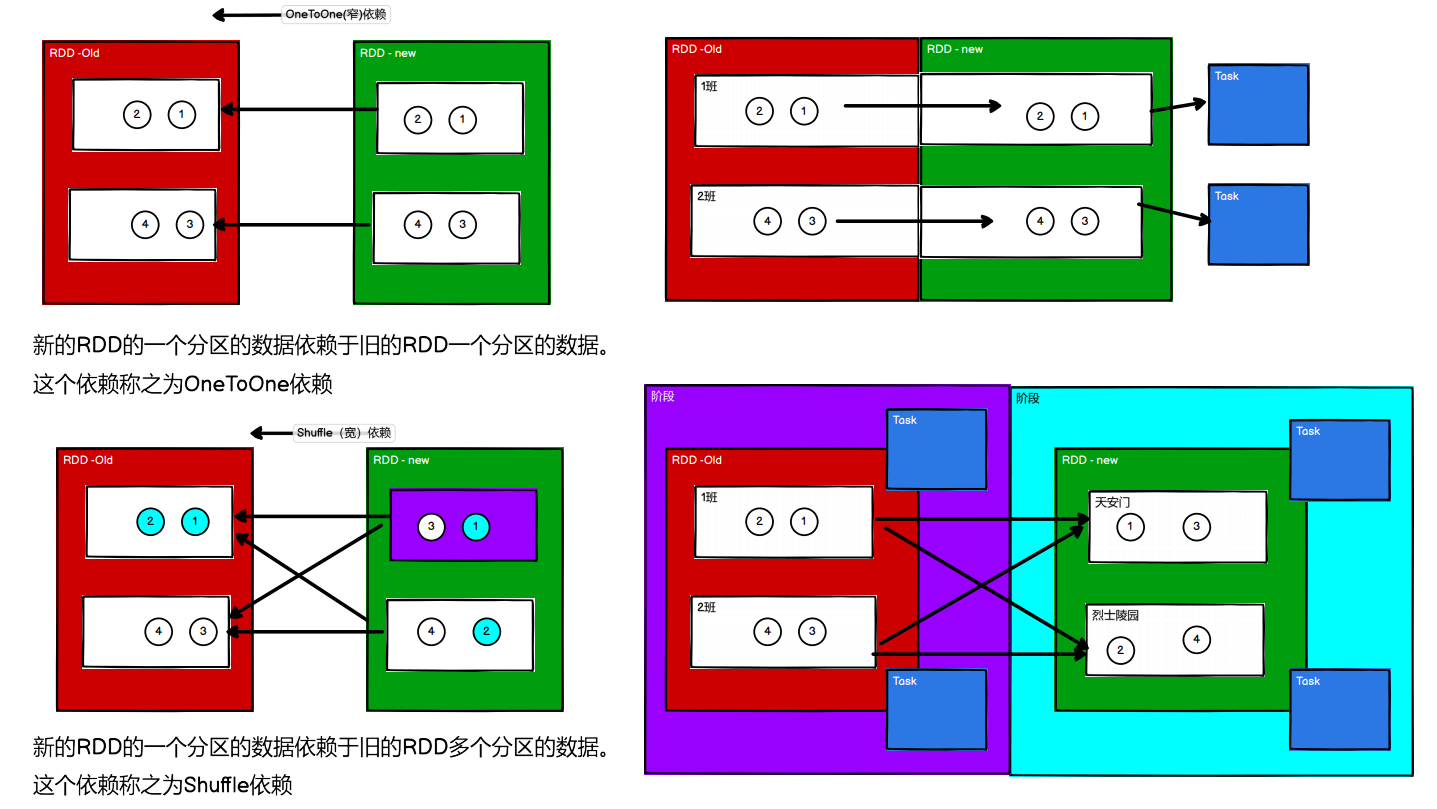
RDD 窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用,
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle,
-
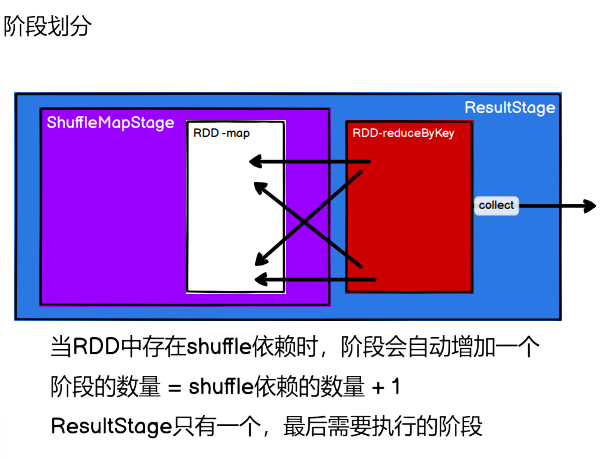
RDD 阶段划分
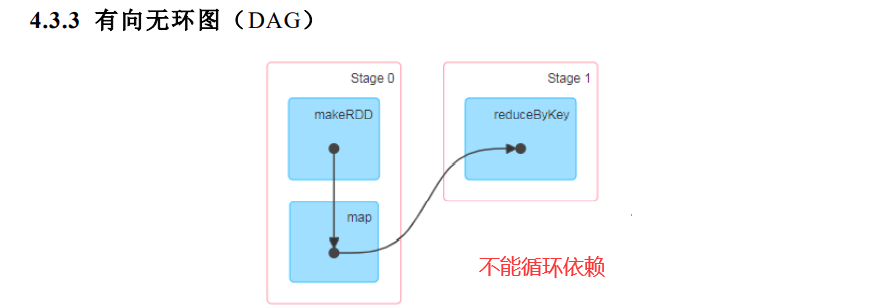
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。例如,DAG 记录了 RDD 的转换过程和任务的阶段。
RDD阶段划分:
流程:
CreateResultStage(里面需要
- getOrCreateParentStages看有没有上一级 上一级结束才行(
传进来的rdd 要 getShuffleDependencies(rdd)找依赖(它之前的rdd)(
判断之前有没有访问过rdd依赖,没有访问过就 遍历所有的依赖 是shuffle依赖就加入shuffle依赖结合
)
getOrCreateShuffleMapStage: 一个shuffleDependency就会转换成一个新的阶段
)
2. newResultStage)
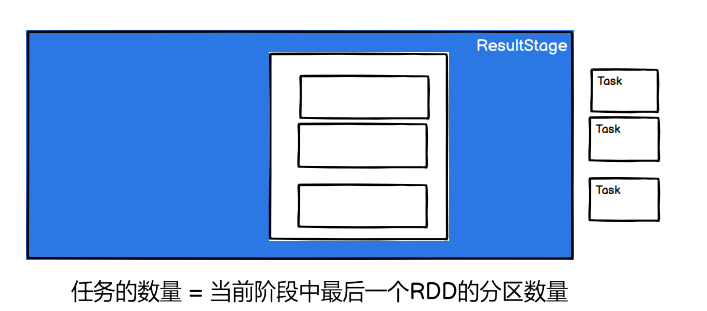
7) RDD 任务划分
行动算子 底层是 runJob()


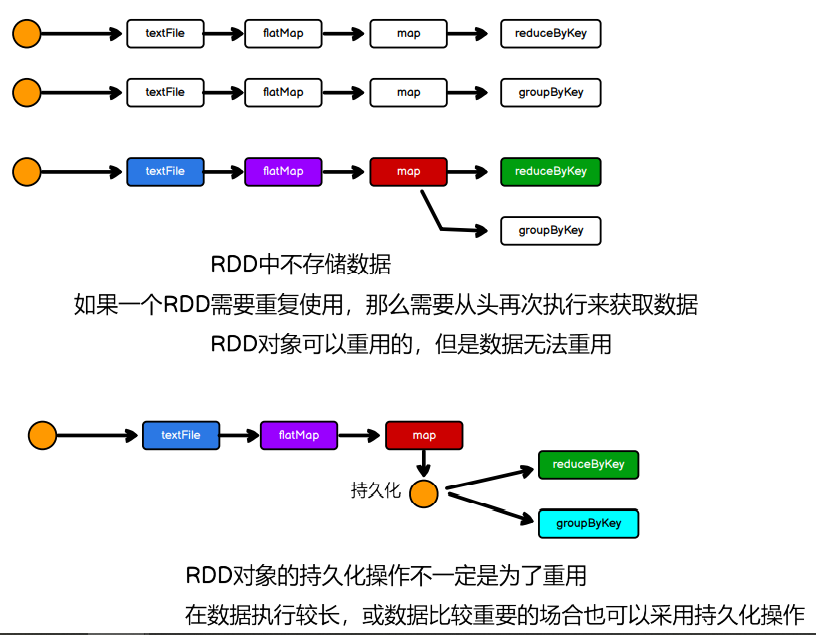
5.1.4.8 RDD 持久化
- RDD Cache 缓存
val list = List("Hello Scala", "Hello Spark")
val rdd = sc.makeRDD(list)
val flatRDD = rdd.flatMap(_.split(" "))
val mapRDD = flatRDD.map(word=>{
println("@@@@@@@@@@@@")
(word,1)
})
// cache默认持久化的操作,只能将数据保存到内存中,如果想要保存到磁盘文件,需要更改存储级别
//mapRDD.cache()
// 持久化操作必须在行动算子执行时完成的。 这个不需要路径,因为运行完就删除了
mapRDD.persist(StorageLevel.DISK_ONLY)
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
reduceRDD.collect().foreach(println)
println("**************************************")
val groupRDD = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
2) RDD CheckPoint 检查点
sc.setCheckpointDir("cp")
// checkpoint 需要落盘,需要指定检查点保存路径
// 检查点路径保存的文件,当作业执行完毕后,不会被删除
// 一般保存路径都是在分布式存储系统:HDFS
mapRDD.checkpoint()
cache persist checkpoint

cache : 将数据临时存储在内存中进行数据重用
会在血缘关系中添加新的依赖。一旦,出现问题,可以重头读取数据
persist : 将数据临时存储在磁盘文件中进行数据重用
涉及到磁盘IO,性能较低,但是数据安全
如果作业执行完毕,临时保存的数据文件就会丢失
checkpoint : 将数据长久地保存在磁盘文件中进行数据重用
涉及到磁盘IO,性能较低,但是数据安全
为了保证数据安全,所以一般情况下,会独立执行作业
执行过程中,会切断血缘关系。重新建立新的血缘关系
checkpoint等同于改变数据源
为了能够提高效率,一般情况下,是需要和cache联合使用
sc.setCheckpointDir("cp")
val list = List("Hello Scala", "Hello Spark")
val rdd = sc.makeRDD(list)
val flatRDD = rdd.flatMap(_.split(" "))
val mapRDD = flatRDD.map(word=>{
println("@@@@@@@@@@@@")
(word,1)
})
mapRDD.cache()
mapRDD.checkpoint()
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
reduceRDD.collect().foreach(println)
println("**************************************")
val groupRDD = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
5.1.4.9 RDD 分区器
- Hash 分区:对于给定的 key,计算其 hashCode,并除以分区个数取余2) Range 分区:将一定范围内的数据映射到一个分区中,尽量保证每个分区数据均匀,而且分区间有序
自定义分区
object Spark01_RDD_Part {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparConf)
val rdd = sc.makeRDD(List(
("nba", "xxxxxxxxx"),
("cba", "xxxxxxxxx"),
("wnba", "xxxxxxxxx"),
("nba", "xxxxxxxxx"),
),3)
val partRDD: RDD[(String, String)] = rdd.partitionBy( new MyPartitioner )
partRDD.saveAsTextFile("output")
sc.stop()
}
class MyPartitioner extends Partitioner{
override def numPartitions: Int = 3
override def getPartition(key: Any): Int = { // 根据数据的key值返回数据所在的分区索引(从0开始)
key match {
case "nba" => 0
case "wnba" => 1
case _ => 2
}
}
}
}
5.1.4.10 RDD 文件读取与保存
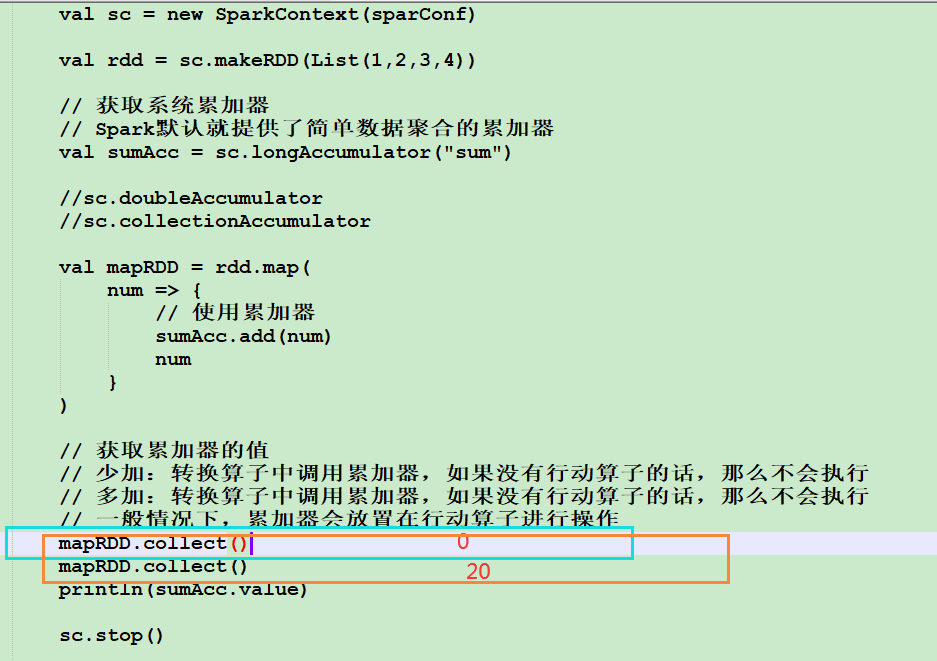
5.2 累加器
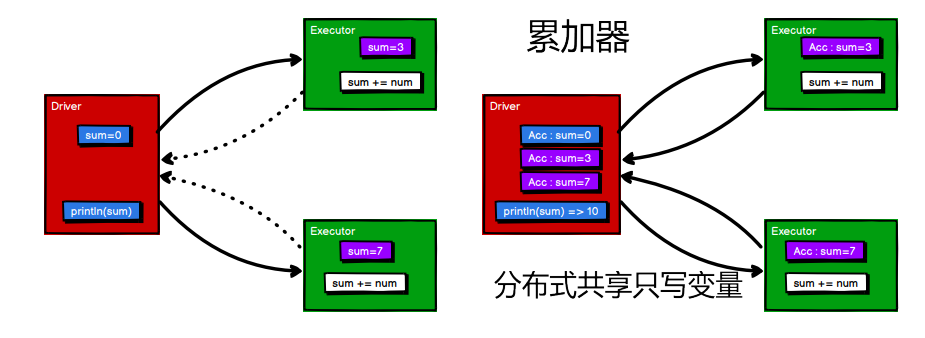
5.2.1 实现原理

package com.atguigu.bigdata.spark.core.acc
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
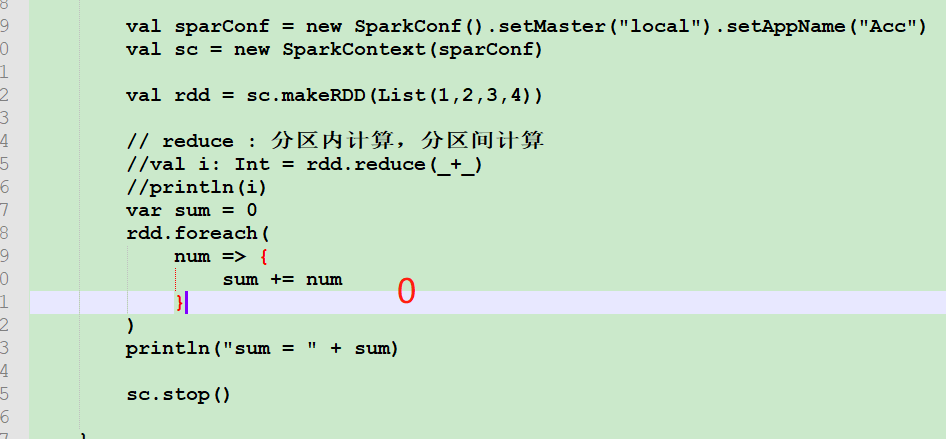
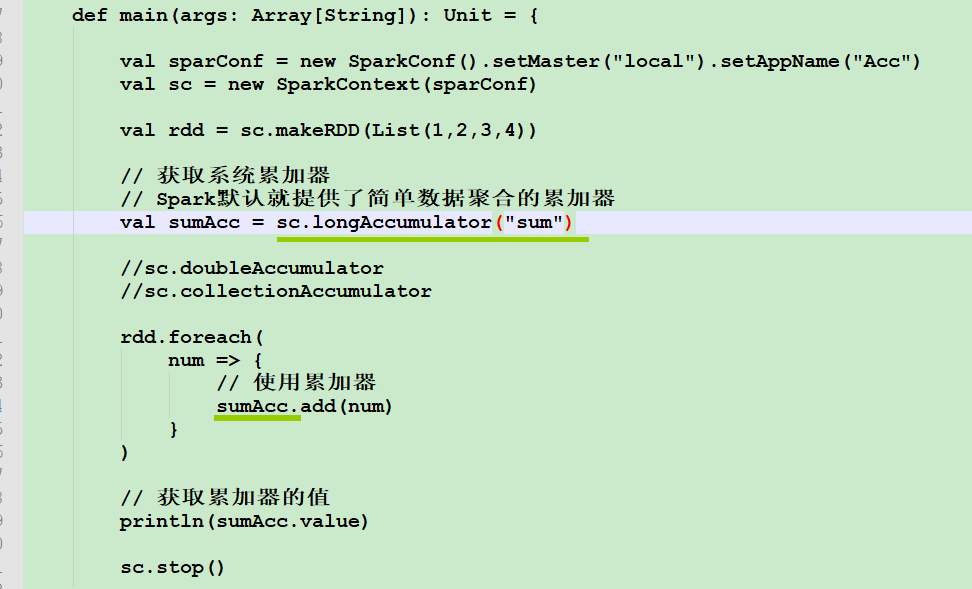
object Spark04_Acc_WordCount {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("Acc")
val sc = new SparkContext(sparConf)
val rdd = sc.makeRDD(List("hello", "spark", "hello"))
// 累加器 : WordCount
// 创建累加器对象
val wcAcc = new MyAccumulator()
// 向Spark进行注册
sc.register(wcAcc, "wordCountAcc")
rdd.foreach(
word => {
// 数据的累加(使用累加器)
wcAcc.add(word)
}
)
// 获取累加器累加的结果
println(wcAcc.value)
sc.stop()
}
/*
自定义数据累加器:WordCount
1. 继承AccumulatorV2, 定义泛型
IN : 累加器输入的数据类型 String
OUT : 累加器返回的数据类型 mutable.Map[String, Long]
2. 重写方法(6)
*/
class MyAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]] {
private var wcMap = mutable.Map[String, Long]()
// 判断是否初始状态
override def isZero: Boolean = {
wcMap.isEmpty
}
override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = {
new MyAccumulator()
}
override def reset(): Unit = {
wcMap.clear()
}
// 获取累加器需要计算的值
override def add(word: String): Unit = {
val newCnt = wcMap.getOrElse(word, 0L) + 1
wcMap.update(word, newCnt)
}
// Driver合并多个累加器
override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = {
val map1 = this.wcMap
val map2 = other.value
map2.foreach{
case ( word, count ) => {
val newCount = map1.getOrElse(word, 0L) + count
map1.update(word, newCount)
}
}
}
// 累加器结果
override def value: mutable.Map[String, Long] = {
wcMap
}
}
}
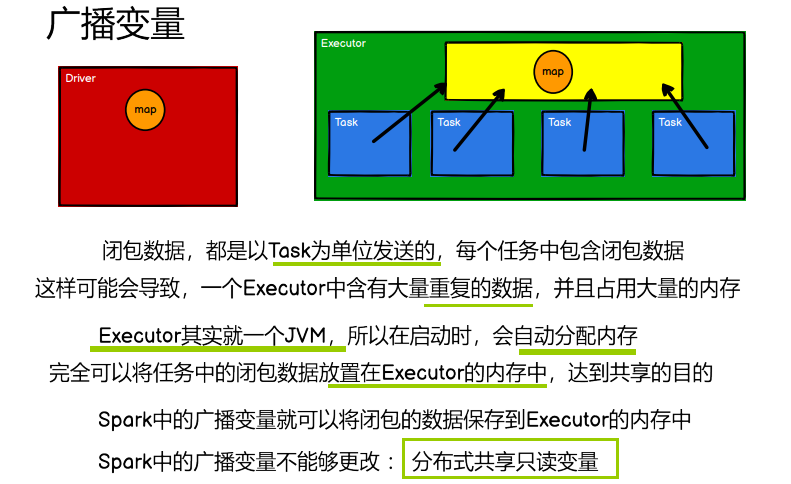
5.3 广播变量
5.3.1 实现原理




 浙公网安备 33010602011771号
浙公网安备 33010602011771号