MySQL 1 锁&MVCC
█ 1.数据库三范式
| 级别 | 概念 |
|---|---|
| 1NF | 属性不可分 列 原子性 |
| 2NF | 非主键属性,完全依赖于主键属性 满足第一范式 |
| 3NF | 非主键属性无传递依赖 |
█ 2.数据库锁
乐观锁 || 悲观锁 || b共享锁 S锁 || b排它锁 X锁 || b行锁 || b表锁

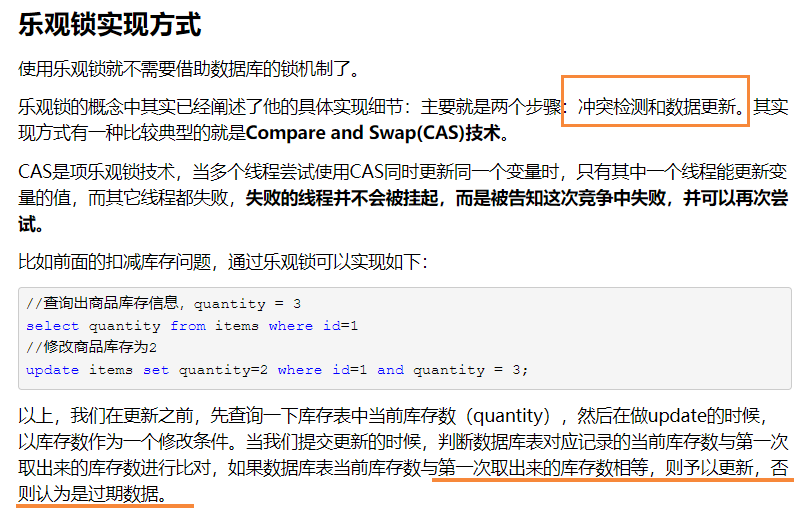
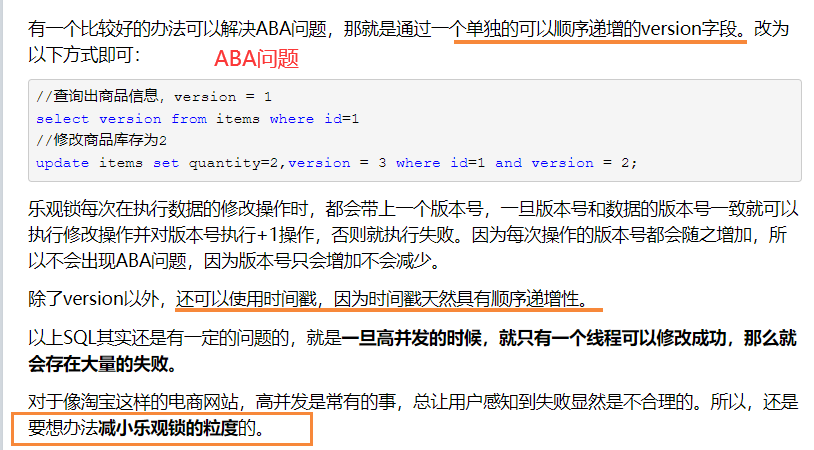
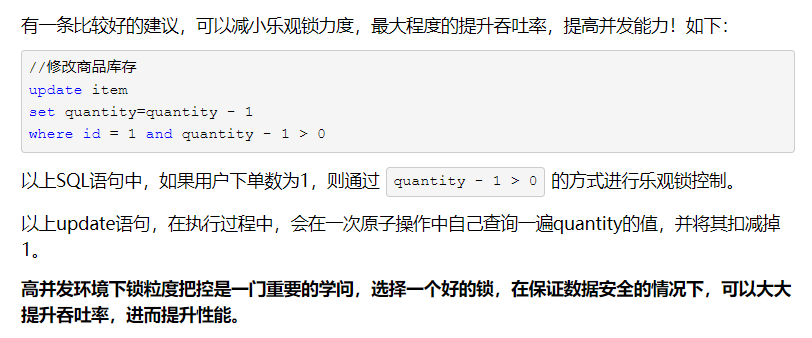
2.1 乐观锁:
一般的实现乐观锁的方式就是记录数据版本。尽可能直接做下去,直到提交的时候才去锁定,所以不会产生任何锁和死锁。
自己实现的锁,认为数据一般不会冲突,实现方式:版本号+时间戳
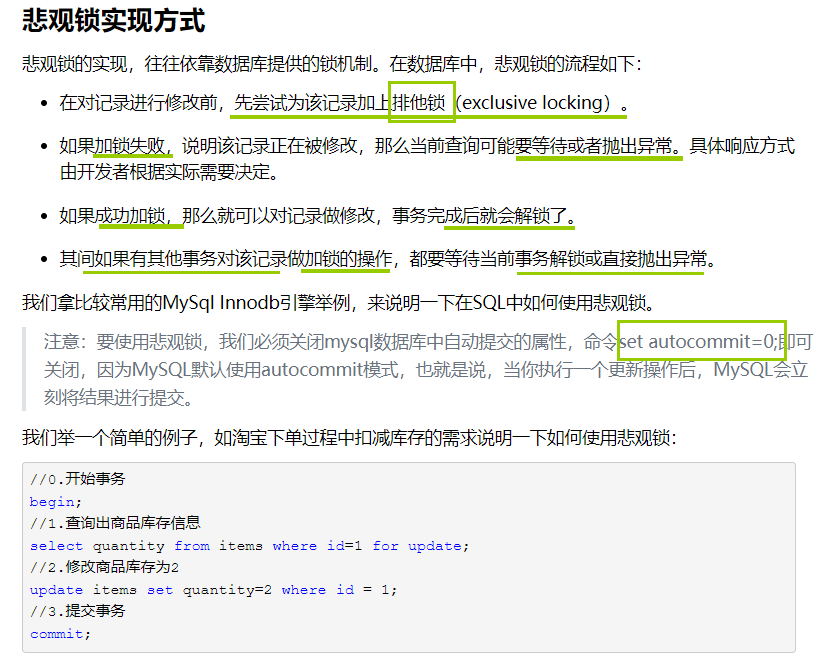
2.2 悲观锁:
一般认为数据被并发修改的概率比较大,所以需要在修改之前先加锁。处理加锁的机制会让数据库产生额外的开销,还有增加产生死锁的机会;降低并行性。
for updata加锁

2.3 b共享锁 S锁 || b排它锁 X锁 || b行锁 || b表锁
b共享锁 S锁 :只读数据操作, 非独占 加 HOLDLOCK
b排它锁 X锁 :一个事务,只能写,加了这个锁,其他事务不能再加任何锁for update
b行锁 : 作用于数据行
b表锁 : 作于用表
█ 3.关系型数据库和非关系型数据库区别
关系型数据库 MySQL SQLserver Oracle
优点
1、容易理解:二维表结构;
2、使用方便:通用的SQL语言使得操作关系型数据库非常方便;
3、易于维护:丰富的完整性,减低了数据冗余和数据不一致的概率;
4、支持SQL,可用于复杂的查询。
5、支持事务
缺点
1、读写性能比较差,维护一致性困难;
2、固定的表结构,灵便度不好;
3、高并发读写时,硬盘I/O存在瓶颈;不支持海量数据的高效率读写;
4、可扩展性不足
非关系型数据库 MongoDB HBase Elasticsearch
1、使用键值对存储数据;
2、分布式;
优点
1)格式灵活:数据存储格式非常多样,应用领域广泛,而关系型数据库则只适用基础的关系模型。
2)性能优越:NOSQL是根据键值对的,不用历经SQL层的分析,因此 性能非常高。
3)可扩展性:基于键值对,数据之间耦合度极低,因此容易水平扩展。
4)低成本:非关系型数据库部署简易,且大部分可以开源使用。
缺点
1)不支持sql,学习和运用成本比较高;
2)无事务处理机制;
3)数据结构导致复杂查询不容易实现。
3.1 关系型与非关系型数据库的区别:
3)储存格式:Nosql的储存文件格式是key,value方式、文本文档方式、照片方式这些,能储存的对象种类灵活;关系数据库则只适用基础类型。
4)可扩展性:关系型数据库有join那样的多表查询机制限定造成拓展性较差。Nosql依据键值对,数据中间沒有耦合度,因此容易水平拓展。
5)数据一致性:非关系型数据库注重最终一致性;关系型数据库注重数据整个生命周期的强一致性。
6)事务处理:SQL数据库支持事务原子性粒度控制,且方便进行事务回滚;NoSQL也支持事务处理,但可靠性不足,其价值在于可扩展性和大数据量处理。
█ 4. MySQL两大引擎MyIsam和InnoDB
○ 4.1 聚簇索引 和 非聚簇索引

○ 4.2 MyIsam 和 InnoDB 区别


○ 4.3 MyIsam 查询流程 InnoDB
4.3.1 MyIsam 查询流程

4.3.2 InnoDB 查询流程


!!!innodb支持全文索引是从mysql5.6开始的
█ 5. 数据库四种隔离级别:
1.读未提交 2.读已提交RC 3.可重复度RR默认,且开启间隙锁 4.串行化<效率差>
串行化:是数据库最高的隔离级别,这种级别下,事务“串行化顺序执行”,也就是一个一个排队执行。
这种级别下,“脏读”、“不可重复读”、“幻读”都可以被避免,但是执行效率奇差,性能开销也最大,所以基本没人会用。
大多数数据库默认的事务隔离级别是Read committed,比如Sql Server , Oracle。
Mysql的默认隔离级别是Repeatable read。
█ 6. 数据库事务四大特性 ACID
ACID
事务的特点:要么都成功,要么都失败
1)原子性Atomicity,要么执行,要么不执行
2)一致性Consistency,事务前后,数据总额一致
3)隔离性Isolation,所有操作全部执行完以前其它会话不能看到过程
4)持久性Durability,一旦事务提交,对数据的改变就是永久的
6.1 a原子性
6.1 undo log
要不全成功,要不全部,
undo log 实现原子性,回滚,如果报错 回滚到执行之前的状态,,
undo log会记录执行的信息,回滚做相反的操作,记录到日志里面

6.2 c一致性:
数据库的完整性。完整性体现在:数据库的主键要唯一 || 字段类型大小长度符合要求 || 外键要符合要求
外键:删除的时候 子表先删除,能删除父表
CREATE TABLE `example1` (
`stu_id` int(11) NOT NULL DEFAULT '0',
`course_id` int(11) NOT NULL DEFAULT '0',
`grade` float DEFAULT NULL,
PRIMARY KEY (`stu_id`,`course_id`)
);
CREATE TABLE `example2` (
`id` int(11) NOT NULL,
`stu_id` int(11) DEFAULT NULL,
`course_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `f_ck` (`stu_id`,`course_id`),
CONSTRAINT `f_ck` FOREIGN KEY (`stu_id`, `course_id`) REFERENCES `example1` (`stu_id`, `course_id`)
);
insert into example1 (stu_id,course_id,grade)values(1,1,98.5),(2,2,89);
insert into example2 (id,stu_id,course_id)values(1,1,1),(2,2,2);
delete from example2 where stu_id=2; 子
delete from example1 where stu_id=2; 父
6.3 d持久性 :
6.3 redo log
buffer:
MySQL 的数据是存在磁盘中的,磁盘IO效率很低,,innodb提供了一个缓存buffer,buffer包含了磁盘中部分数据页的映射,作为访问数据库的缓冲,
读,先buffer,无磁盘,再写入buffer
写,先buffer,定期刷新到磁盘上 --- 数据丢失
redo log 防止数据丢失,,预写式日志,修改先写入日志,再buffer
redo log 速度比 buffer 快的原因:
1)
buffer中的数据持久化 是随机写的IO,每次修改的数据的位置 是 随机的。
redo log 是追加模式,在文件尾部追加,顺序IO 快 kafka也是顺序IO
2)
buffer持久化数据 是以 数据页page为单位的,MySQL默认是16k一个page,只要这个page有修改,就要整个写入
redo log 只要写入真正修改的部分,无效IO大大减少。
3)
redo log 先放到 redo log 缓冲区,,之后写入到磁盘。

○ 6.4 i隔离性:
i隔离性:分为两种情况:
1)写-写操作:锁
2)写-读操作:MVCC 可以解决(脏读/不可重复读/幻读)读写冲突 无锁并发控制
数据库并发场景

█ 7 i写写操作:innodb有 行锁 // 表锁 // 间隙锁
查看锁情况的sql语句:innodb_locks

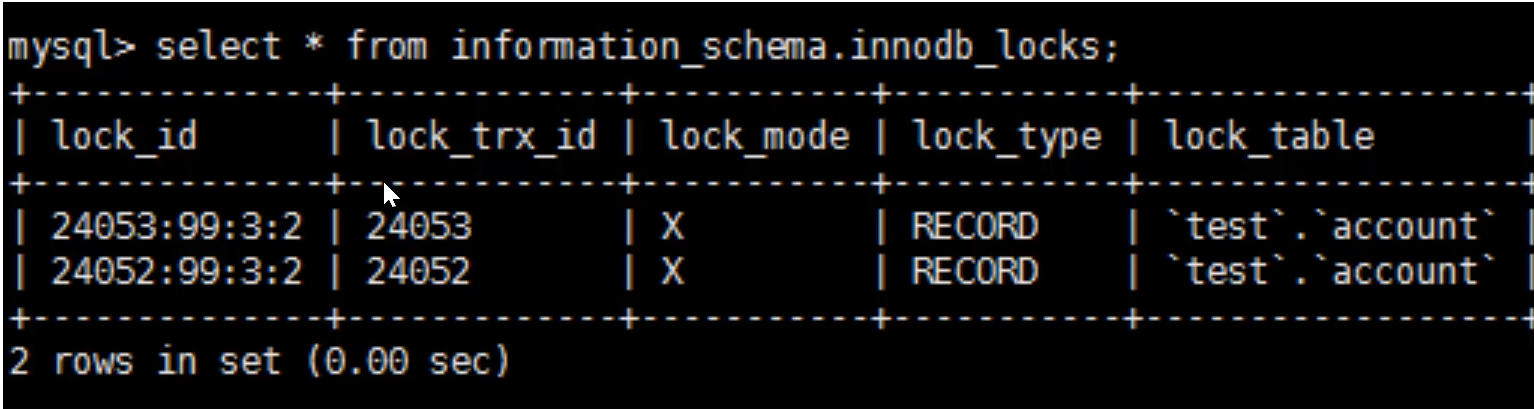
X是排他锁 对应的有共享锁
b共享锁 S锁 :只读数据操作, 非独占 加 HOLDLOCK
b排它锁 X锁 :一个事务,只能写,加了这个锁,其他事务不能再加任何锁for update
○ 7.1 record 行锁
drop table if exists test_innodb_lock;
CREATE TABLE test_innodb_lock (
a INT (11),
b VARCHAR (20)
) ENGINE INNODB DEFAULT charset = utf8;
insert into test_innodb_lock values (1,'a');
insert into test_innodb_lock values (2,'b');
insert into test_innodb_lock values (3,'c');
insert into test_innodb_lock values (4,'d');
insert into test_innodb_lock values (5,'e');
创建索引
create index idx_lock_a on test_innodb_lock(a);
create index idx_lock_b on test_innodb_lock(b);
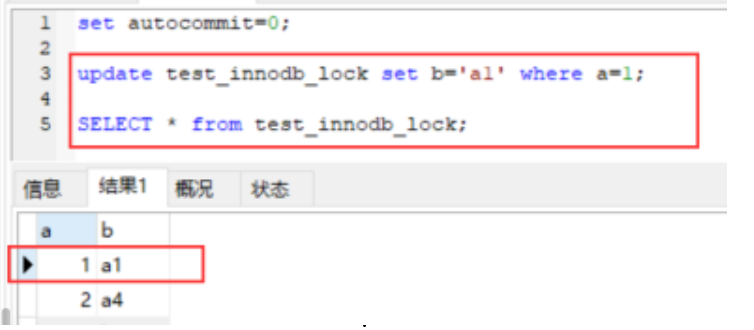
先将自动提交事务改成手动提交:set autocommit=0;
启动两个会话窗口 A 和 B,抢锁
行锁(写&读)"读已提交"
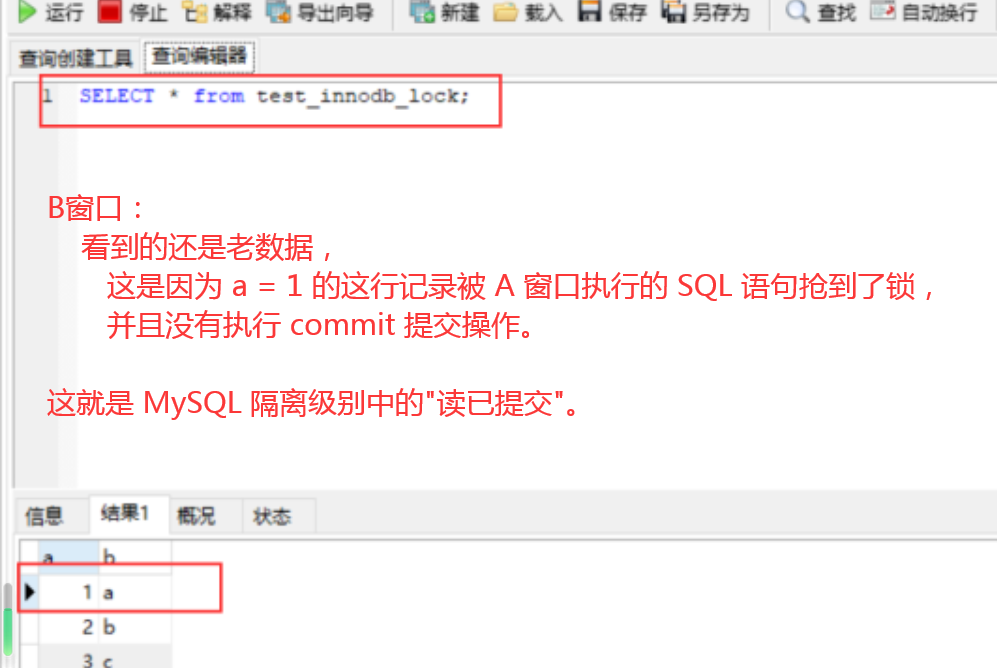
COMMIT;之后就可以了
行锁(写&写)
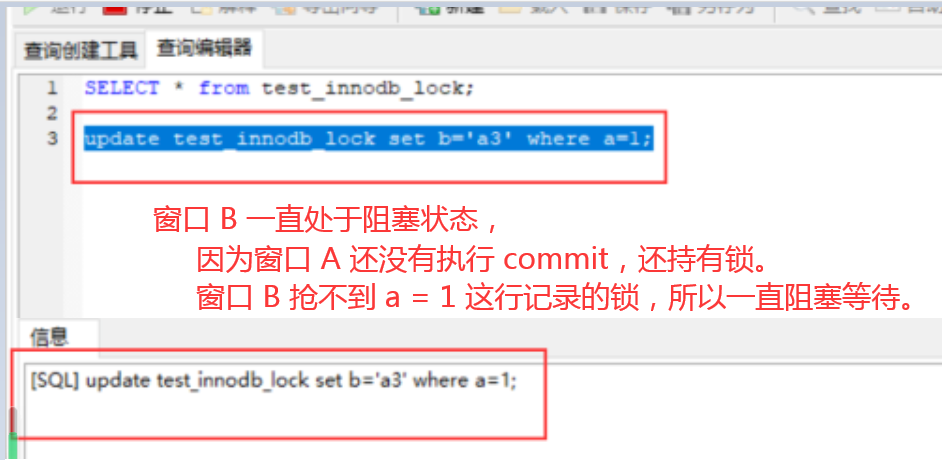
窗口 A 执行 COMMIT;操作,B自动出结果了。
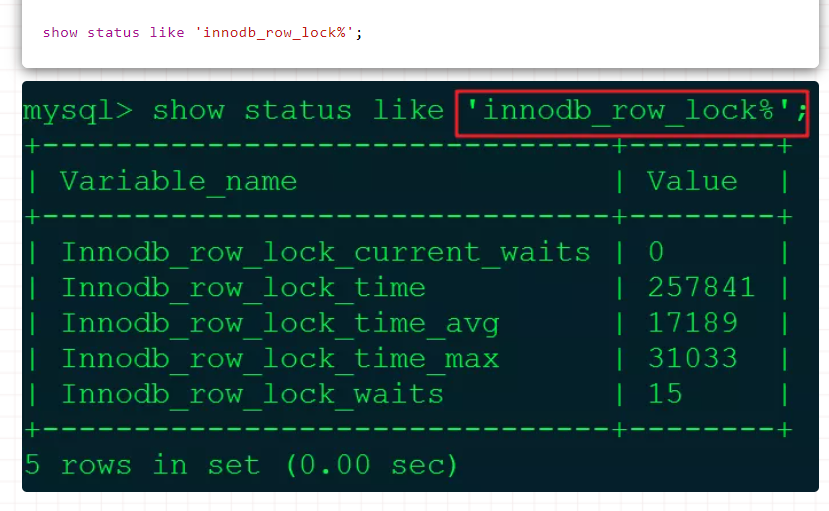
行锁分析命令代码

○ 7.2 表锁 写写操作 i
MyIsam最小锁粒度是 表锁
用了 OR 做连接,索引就会失效。

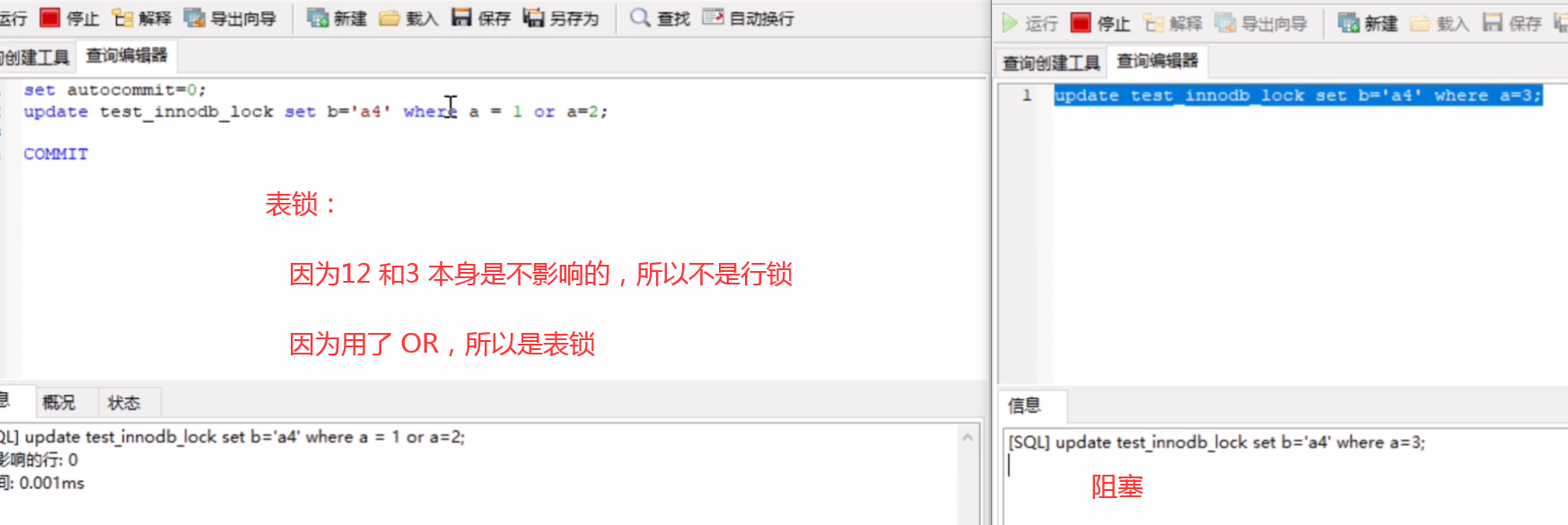
窗口 A 执行 COMMIT;操作,B自动出结果了。表锁的等待时长长。
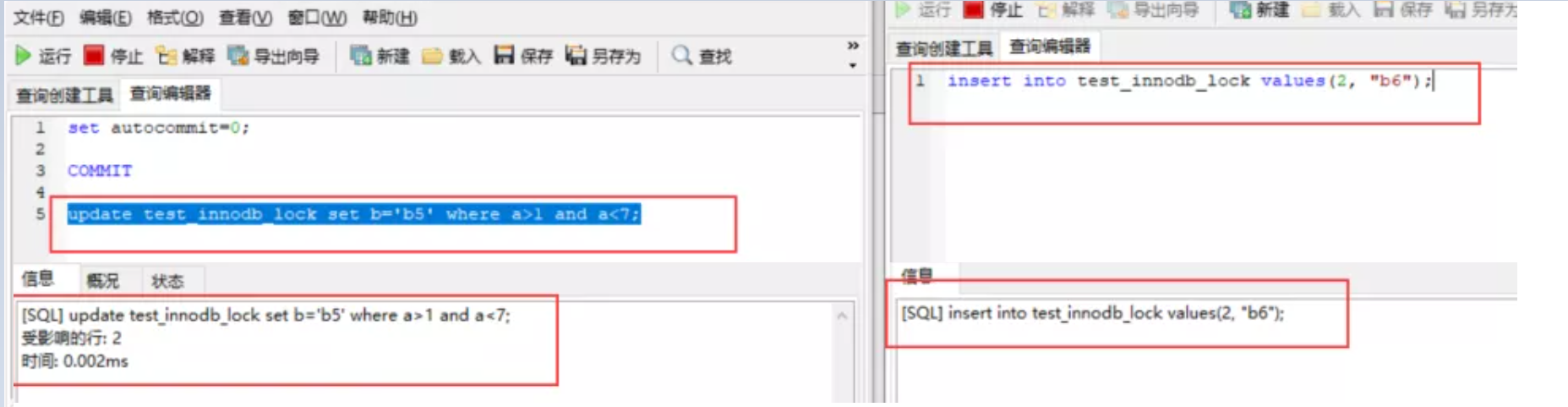
○ 7.3 间隙锁

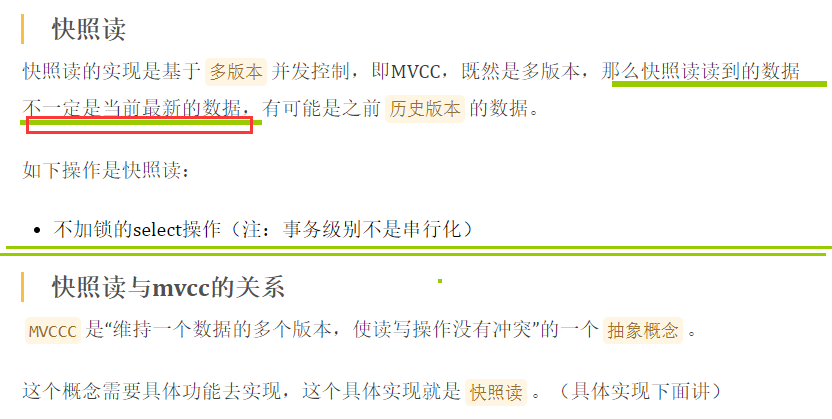
█ 8 当前读 & 快照读
当前读


快照读
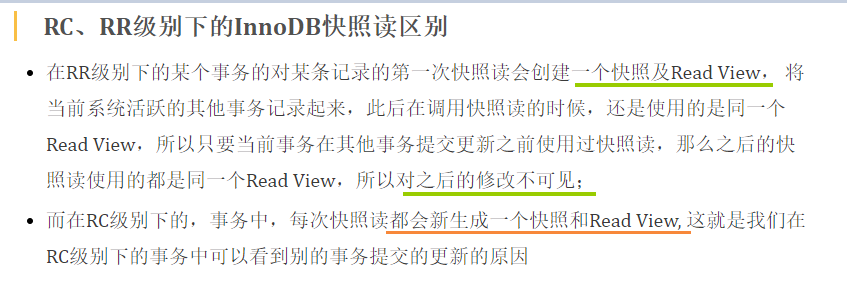
○ 7.4.2 RC、RR级别下的InnoDB快照读区别
█ 9 i读写操作:MVCC
MVCC 是“维持一个数据的多个版本,使读写操作没有冲突”的一个抽象概念。

○ 9.1 MVCC解决并发哪些问题

○ 9.2 MVCC的实现原理
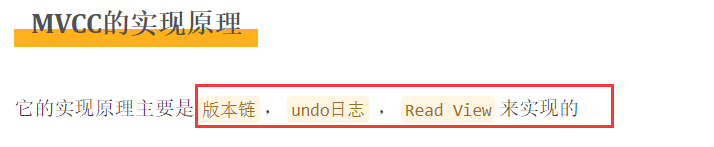

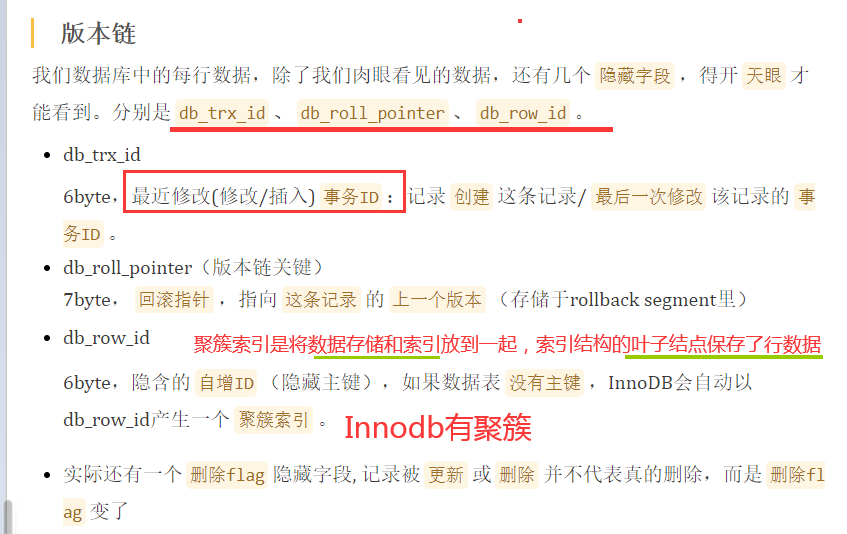

undo log a原子性
redo log d持久性




ReadView



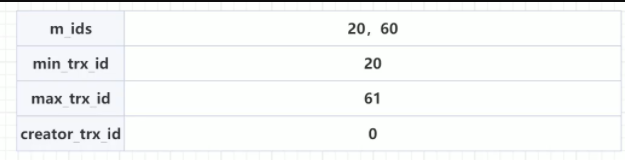

Read View可见性判断条件 代码

○ 9.3 MVCC解决 RC读已提交/脏读 RR可重复度/不可重复读
数据库四种隔离级别:
1.读未提交 2.读已提交RC 3.可重复度RR默认,且开启间隙锁 4.串行化
2.读已提交RC 3.可重复度RR 都是基于 MVCC实现的
RC
活跃事务ID是没有提交的,,提交的事务ID是可以被访问到的,
1)脏读:指一个事务中访问到了另外一个事务未提交的数据,MVCC解决 RC读已提交
2)不可重复读:一个事务查询同一条记录2次,得到的结果不一致。 在一个事务里面,只会生成一个 ReadView,都用的第一个生成的。
RR MySQL默认
在一个事务里面,只会生成一个 ReadView,都用的第一个生成的。
通过版本链和ReadView 就实现了 读已提交,但是没有实现可重复读
在一个事务里面,两个select方法 会生成两个ReadView,
第二个select可能会查到最新提交的 数据
一个事务里 两个select查询到了不同的数据,就不是可重复读RR 违背了数据库四种隔离级别。
3)幻读:一个事务查询2次,得到的记录条数不一致。

(1)什么是幻读
1、在可重复读隔离级别下,普通查询是快照读,是不会看到别的事务插入的数据的,幻读只在**当前读**下才会出现。
2、幻读专指**新插入的行**,读到原本存在行的更新结果不算。因为**当前读**的作用就是能读到所有已经提交记录的最新值。
幻读
保证数据的一致性和事务与事务之间的隔离性。
RR存在幻读的问题,在Innodb搜索引擎里被解决了,
读分为 当前读(锁) + 快照读(MVCC)
快照读(MVCC)一个事务一个ReadView,select结果都相同;
当前读(锁) + 间隙锁(锁住一段事务) ,MySQL默认且开启间隙锁
(2)幻读产生的原因
行锁只能锁住行,即使把所有的行记录都上锁,也阻止不了新插入的记录。

