通信项目 细抠
快捷键
alt + l 导包????
ctrl + alt + s 打开Settings
ctrl + shift + alt + s 打开配置
shift + F6 批量选中修改对象名字
ctrl+d 复制本行
ctrl + alt+ v 推导出前面 home end
ctrl + p 当前函数的参数类型
alt + insert
ctrl + o 看Implement
ctrl + alt + o 快速干掉依赖包
1.实时生成通话记录数据,
2.通过flume 采集 到kafka 传入kafka topic,,
3.Kafka API编写kafka消费者,读取kafka集群中缓存的消息, 将读取出来的数据写入到HBase中
4.HBase输出到MySql;
数据:整了 电话号码和联系人的map,随机生成主叫被叫 通话时长 时间 这些数据,设置生成1条就flush到文件 就把它们输出到 calllog.csv文件里面去。SimpleDateFormat
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(filePath,true), "UTF-8");
这一块是 producer的代码
还有一块是 consumer的代码,他负责配置 kafka和hbase。
写一个配置文件properties里面配置两部分的内容,kafka的brokerlist topic 和 hbase 的region namespace tablename
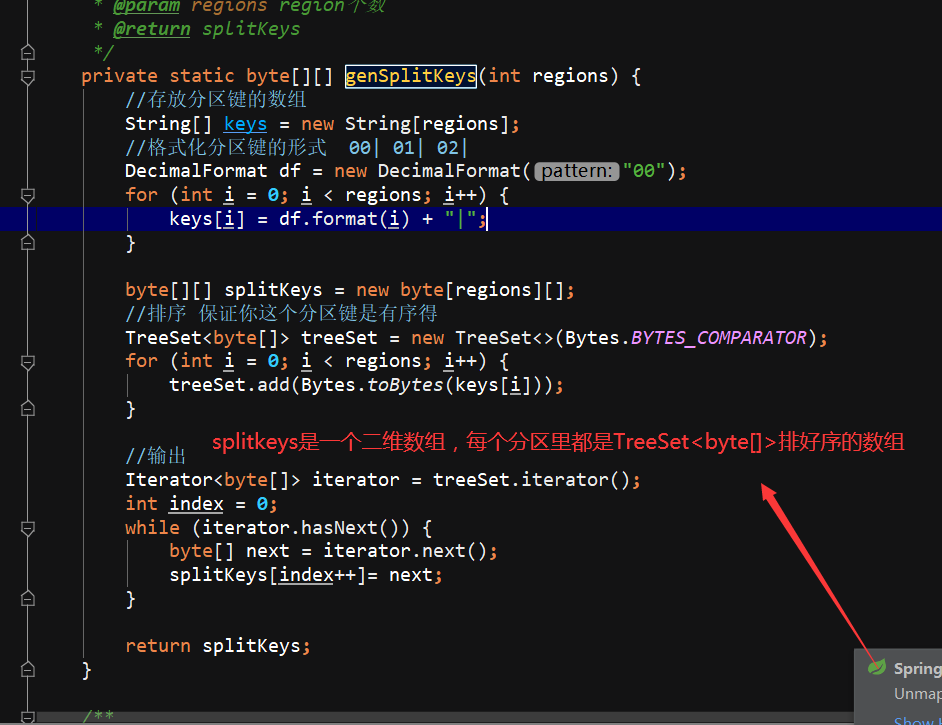
然后用HBase API实现 这些功能: 命名空间 表 判断表是否存在 Region、RowKey、分区键
之后 kafkaConsumer.poll到的 ConsumerRecords<String, String> 数据 ,把value put到 Hbase里面去。
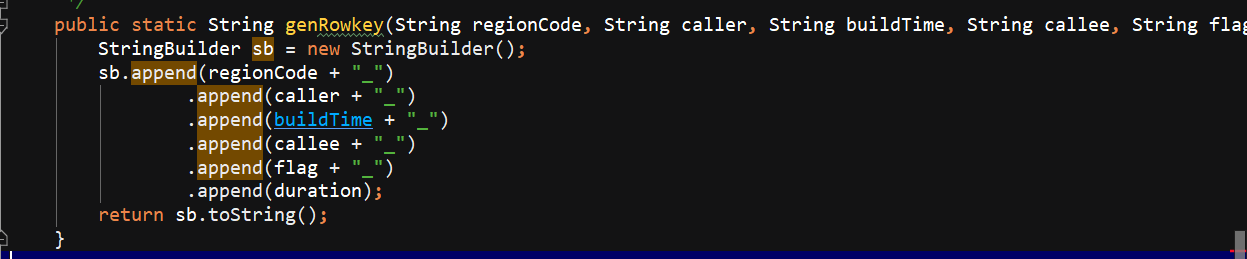
他的rowKey,直接进行的拼接 分区号在前+主叫+建立时间+被叫+flag+通话时长
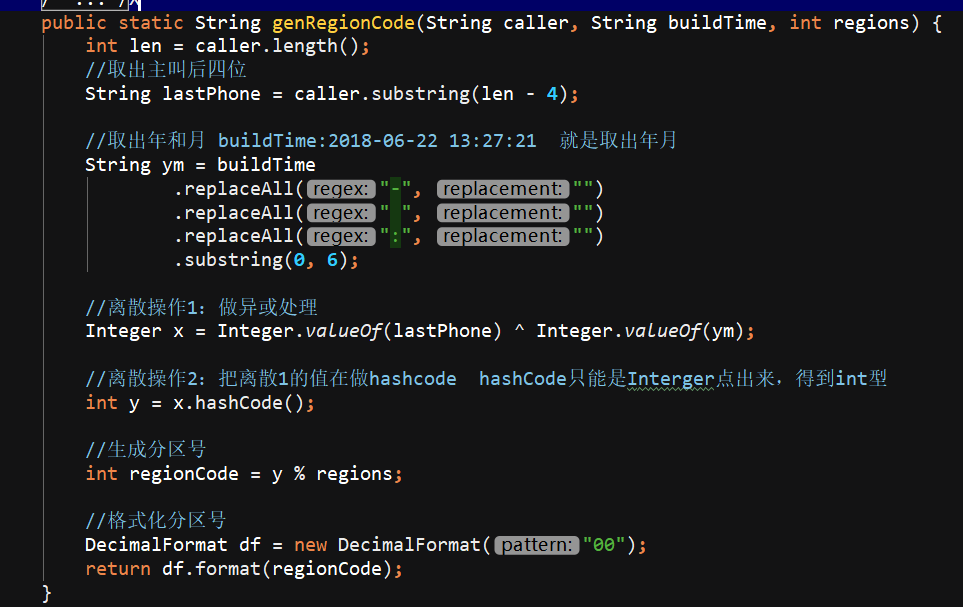
他的分区号:手机号的后4位 ^异或 通话年月201802 ---> 之后x.hashcode(); ---> 之后%regions Decimal格式化
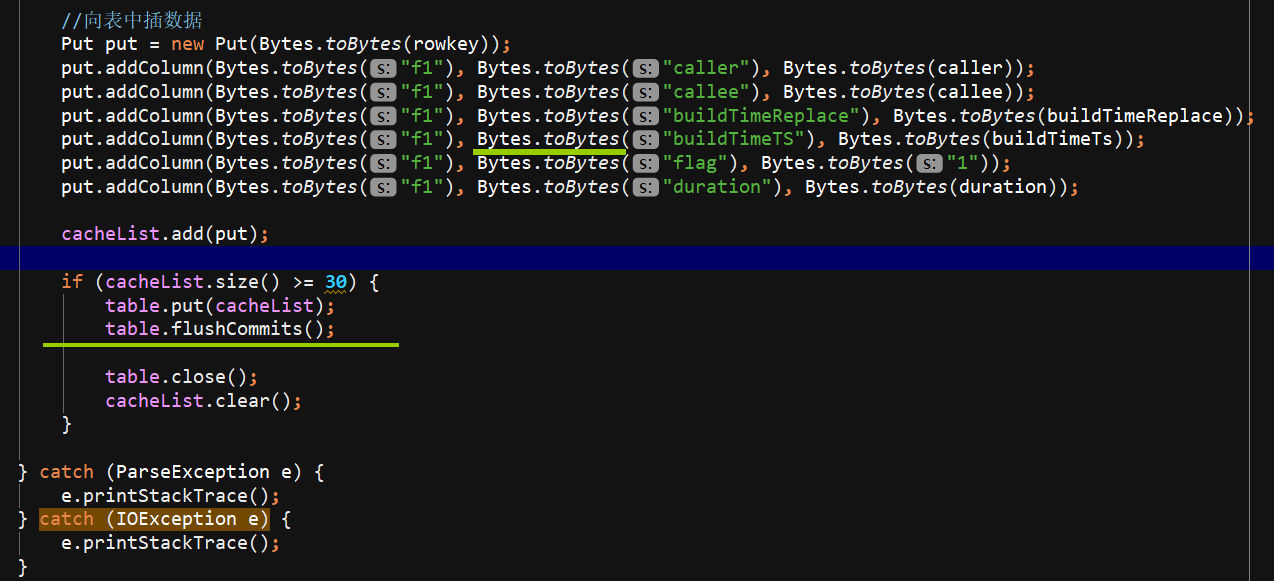
Hbase是 设计batchsize 凑齐30个进行flush,,他的put方法 只定义了 一个列簇的插入,,另外的一个列簇是 主叫和被叫互换,用的是协处理器的方法。
extends BaseRegionObserver { 重写 public void postPut(ObserverContext<RegionCoprocessorEnvironment> e,
Put put,
WALEdit edit,
Durability durability) throws IOException { 方法,数据是通过rowkey拿到的。
消费者的代码 分发到Hbase中的lib目录下;
给flume配置conf 《 source sink channel 》 采集实时产生的数据到kafka集群
source连接的是 exec /calllog.csv的文件
sink 连接的是 org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = bigdata179:9092 180 181
/root/sof/flume/bin/flume-ng agent --conf /root/sof/flume/conf/ --name a1 --conf-file /root/sof/flume/jobconf/flume2kafka.conf
java -Djava.ext.dirs=F:\maven-lib\lib\ -cp F:\maven-lib\ct_consumer-0.0.1-SNAPSHOT.jar com.china.ct_consumer.kafka.HBaseConsumer
使用HBase查找数据时,尽可能的使用rowKey去精准的定位数据位置
█ 1. 生成通话记录:
//存放tel的list集合
private List<String> phoneList = new ArrayList<>();
//存放tel和Name的Map集合
private Map<String, String> phoneNameMap = new HashMap<>();
随机抽取手机号 配对 成 通话记录,如果重复用 while 满足!= break
随机生成时间
SimpleDateFormat sdf1 = new SimpleDateFormat("yyyy-MM-dd");
Date startDate = sdf1.parse(startTime);
Date endDate = sdf1.parse(endTime);
long randomTS = startDate.getTime() + (long) ((endDate.getTime() - startDate.getTime()) * Math.random());
Date resultDate = new Date(randomTS);
SimpleDateFormat sdf2 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String resultTimeString = sdf2.format(resultDate);
return resultTimeString;
输出流每次写一条 之后需要flush,不然可能导致积攒多条数据才输出一次。
public void writeLog(String filePath) {
try {
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(filePath,true), "UTF-8");
while (true) {
Thread.sleep(200);
String log = product();
System.out.println(log);
osw.write(log + "\n");
//一定要手动flush才可以确保每条数据都写入到文件一次
osw.flush();
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e2) {
e2.printStackTrace();
}
}
java -cp /root/work/xin_project/jars/ct_producer-1.0-SNAPSHOT.jar producer.ProductLog /root/work/xin_project/jars/calllog.csv
这个命令太麻烦了,便写成了sh脚本
cat product.sh
#!bin/bash
java -cp /root/work/xin_project/jars/ct_producer-1.0-SNAPSHOT.jar producer.ProductLog /root/work/xin_project/jars/calllog.csv
█ 2. 这个项目启动需要的前置环境
http://192.168.182.179:50070
单个bigdata179上启动
/root/sof/hadoop-2.7.3/sbin/start-all.sh
/root/sof/hadoop-2.7.3/sbin/stop-all.sh
全部 bigdata179 180 181
/root/sof/zookeeper-3.4.10/bin/zkServer.sh start
/root/sof/zookeeper-3.4.10/bin/zkServer.sh stop
单个 bigdata179
/root/sof/hbase-1.3.0/bin/start-hbase.sh
/root/sof/hbase-1.3.0/bin/stop-hbase.sh
每个单个 对应关闭的时候是 每个都要做:
/root/sof/hbase-1.3.0/bin/hbase-daemon.sh stop master
/root/sof/hbase-1.3.0/bin/hbase-daemon.sh stop regionserver
单个
/root/sof/hbase-1.3.0/bin/hbase shell
全部
Kafka的 启动命令 (&表示后台启动):
/root/sof/kafka_2.11-2.1.1/bin/kafka-server-start.sh /root/sof/kafka_2.11-2.1.1/config/server.properties &
全部
Kafka的 关闭命令:
/root/sof/kafka_2.11-2.1.1/bin/kafka-server-stop.sh /root/sof/kafka_2.11-2.1.1/config/server.properties &
█ 3. 配置flume
flume和kafka进行实时数据收集。
source channel sink event
流程:
1)source监控有没有新的数据 ,(某个文件或数据流,数据源产生新的数据)
2)拿到该数据后,将数据封装在一个Event中,
3)并put到channel后commit提交,channel队列先进先出,
4)sink去channel队列中拉取数据,
5)然后写入到HDFS中。
监控端口source:type -->netcat 日志打印sink:type-->logger
监控文件(通过shell命令)source:type -->exec hdfs sink:type-->hdfs
监控目录source:type -->spooldir hdfs sink:type-->hdfs
扇入(fan in):数据汇总,多层
channel : type-->两种:内存、磁盘 (内存会有数据丢失的问题)
bin/flume-ng agent --conf conf/ --name a3 --conf-file myconf/flume33.conf
bin/flume-ng agent -c conf -n a3 -f myconf/flume33.conf
扇出(fan out):数据作用于多个地方
source 1个 replicating
channel 多个
sink 多个
配置文件 dataStream是序列化文件, batchSize sink每次的量
agent.sources.kafkaSource.type=org.apache.flume.source.kafka.KafkaSource
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#type的参数不能写成uuid,得写具体,否则找不到类
a1.sources.r1.interceptors.i1.type = org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder
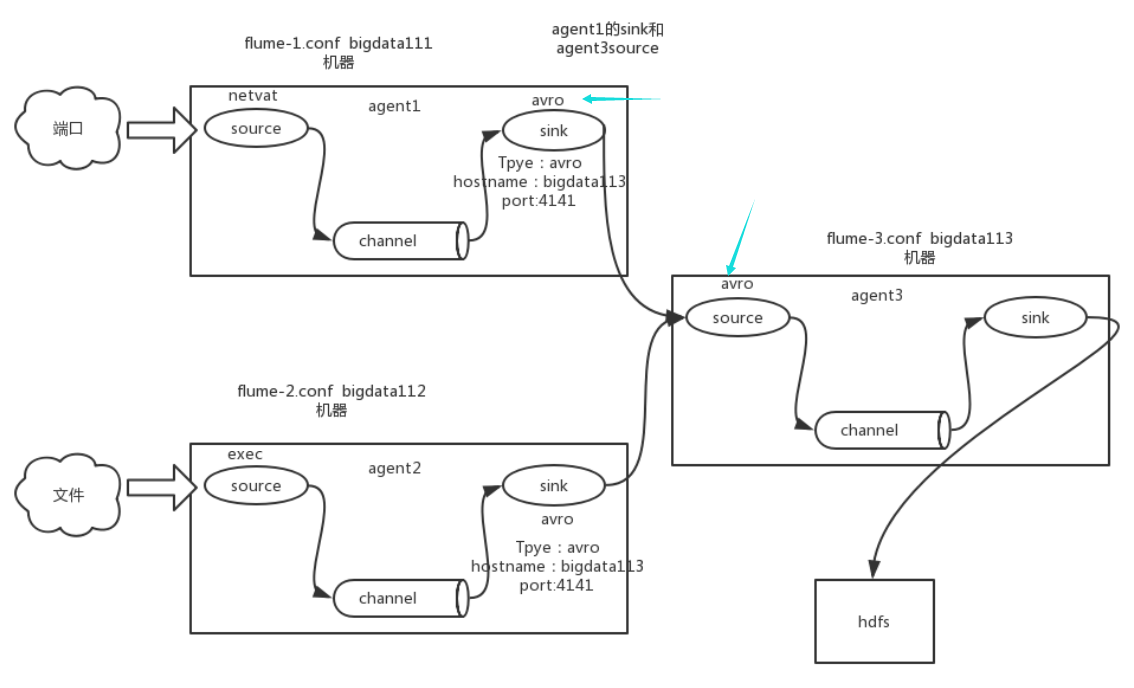
# define
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F -c +0 /root/work/XIN_project/jars/calllog.csv
a1.sources.r1.shell = /bin/bash -c
# sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = bigdata179:9092,bigdata180:9092,bigdata181:9092
a1.sinks.k1.topic = calllog
a1.sinks.k1.batchSize = 20
a1.sinks.k1.requiredAcks = 1
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动命令:
/root/sof/flume/bin/flume-ng agent --conf /root/sof/flume/conf/ --name a1 --conf-file /root/sof/flume/jobconf/flume2kafka.conf
之后开始生产
$ sh productlog.sh
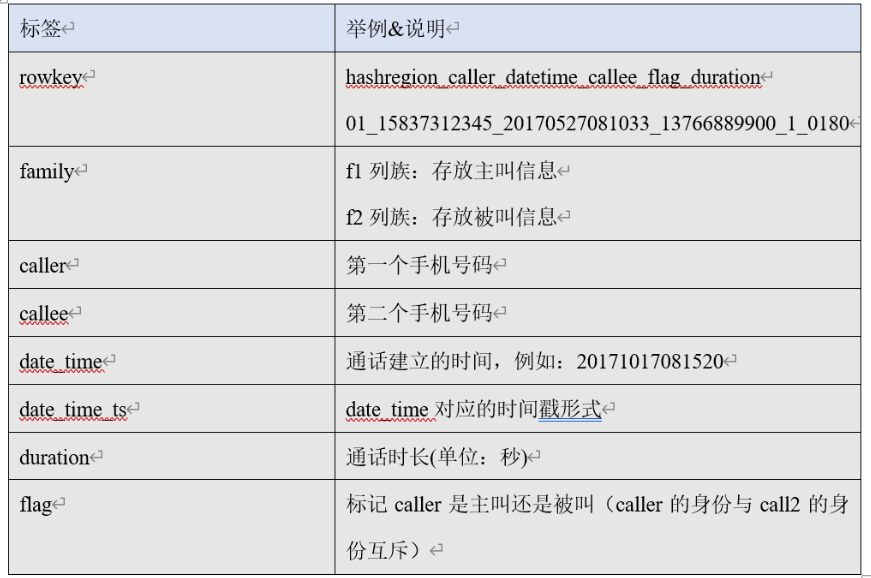
█ 4. HBase 的数据结构
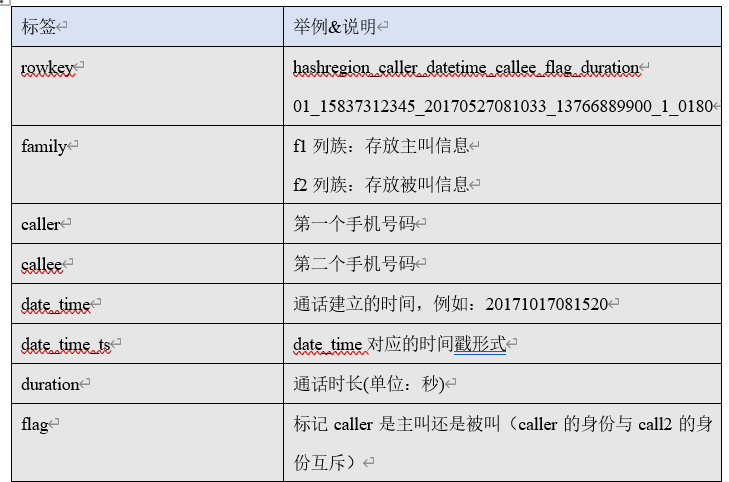
4. 数据消费 consumer:

需要有配置文件说明 kafka的topic kafka的brokerlist:bigdata179:9092
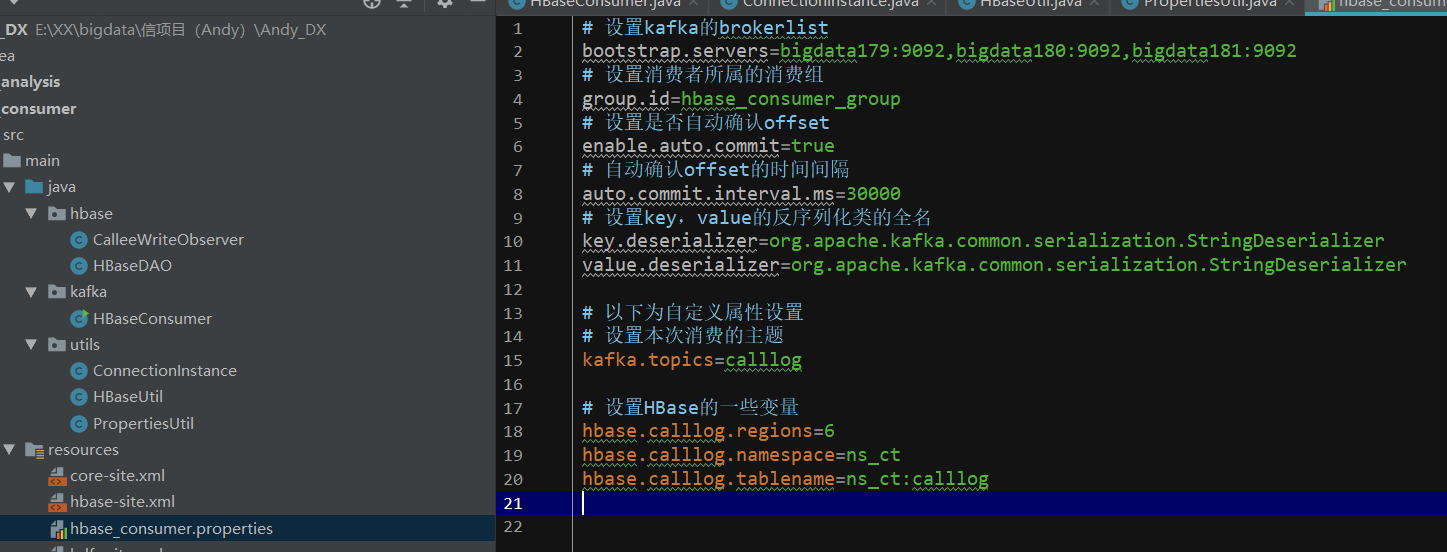

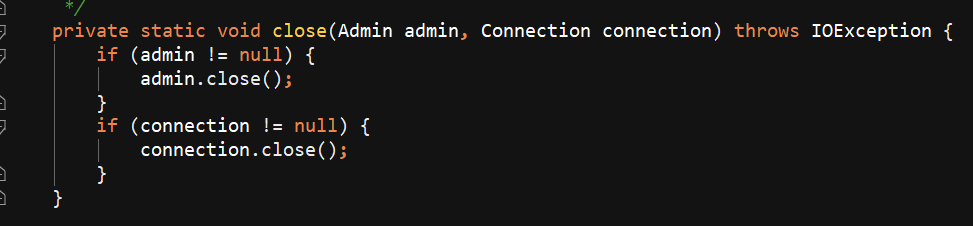
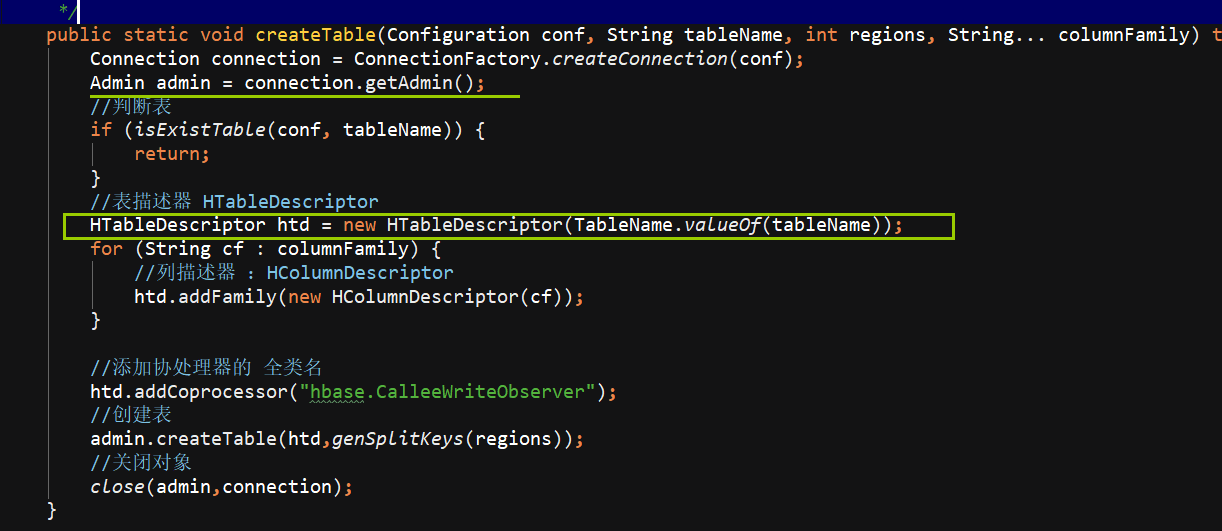
写一个HBaseUtil 里面有 是否存在表 // 初始化命名空间 // 创建表 // 表是否存在


生成rowKey,直接进行的拼接 分区号在前+主叫+建立时间+被叫+flag+通话时长
生成分区号:手机号的后4位 ^异或 通话年月201802 ---> 之后x.hashcode(); ---> 之后%regions Decimal格式化
自定义分区
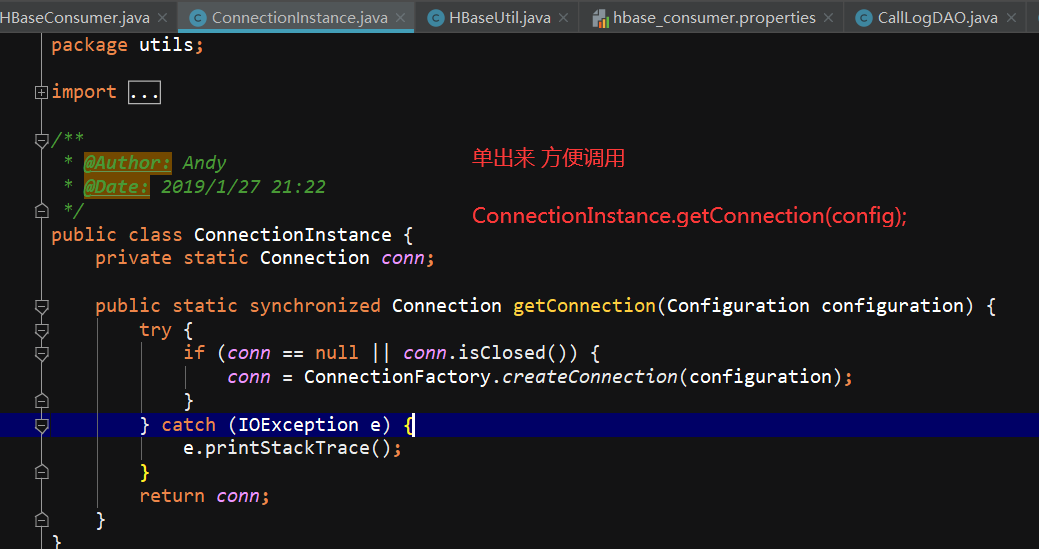
ConnectionInstance设计模式,单出来
HBaseDAO 就是一个关键的 PUT 方法,把数据传进去
先把数据进行切分,因为csv用的是逗号,,要计算分区号,计算rowkey,,设计batchsize 凑齐30个进行flush

█ 5. 协处理器
这里其实还有协处理器生成 f2的 部分
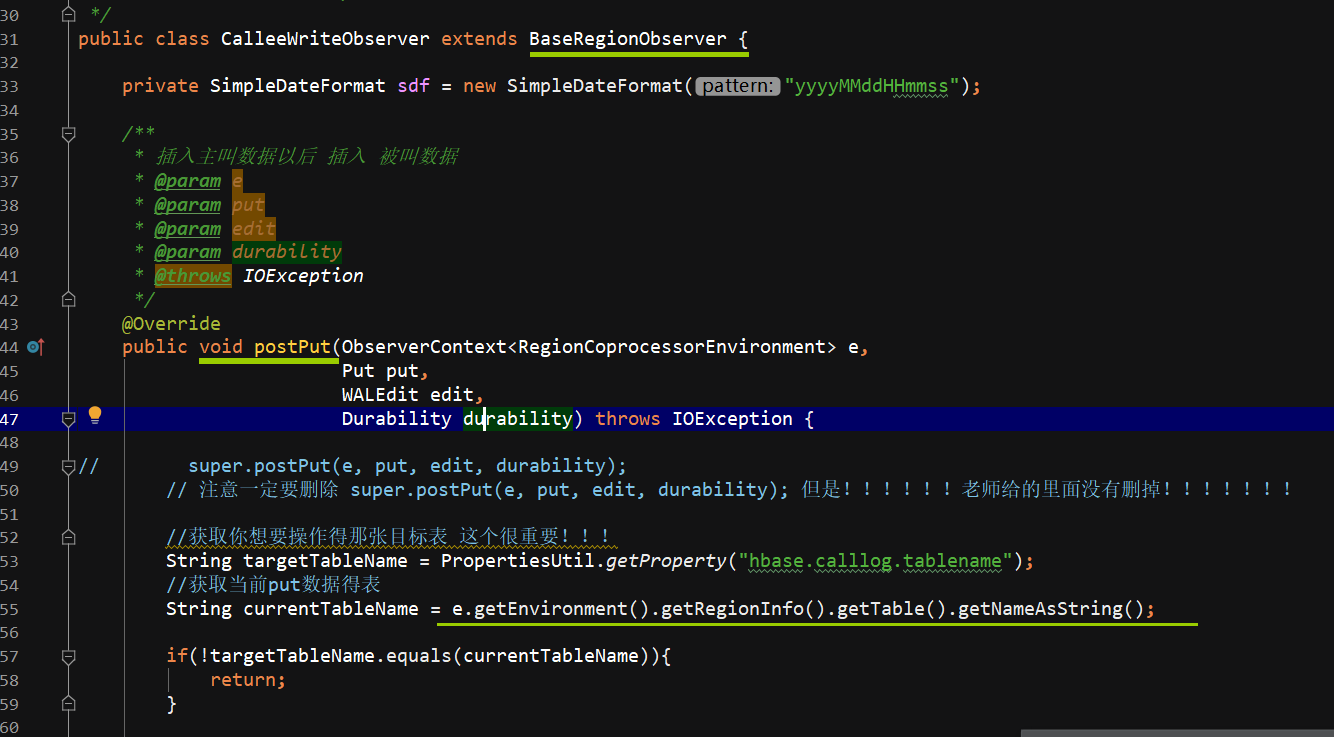
在协处理器中,一条主叫日志成功插入后,将该日志切换为被叫视角再次插入一次,放入到与主叫日志不同的列族中。
修改hbase-site.xml文件,设置协处理器,并群发该hbase-site.xml文件
协处理器放在的是 hbase-site.xml文件 都是传到集群上的所有机器。
插入的数据是 从rowkey里面拿到的 String oriRowKey = Bytes.toString(put.getRow());
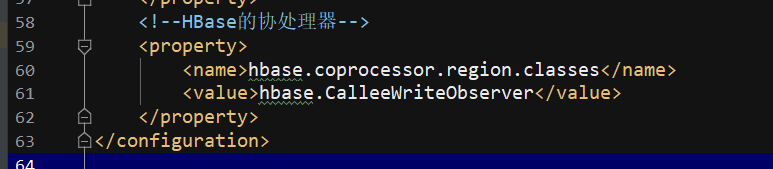
conf : vi hbase-site 里面加上我们的包,也就是添加协处理器!
date
这个也要有!!!
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<!--HBase的协处理器-->
<property>
<name>hbase.coprocessor.region.classes</name>
<value>hbase.CalleeWriteObserver</value>
</property>
发布jar包到hbase的lib目录下(注意需群发):
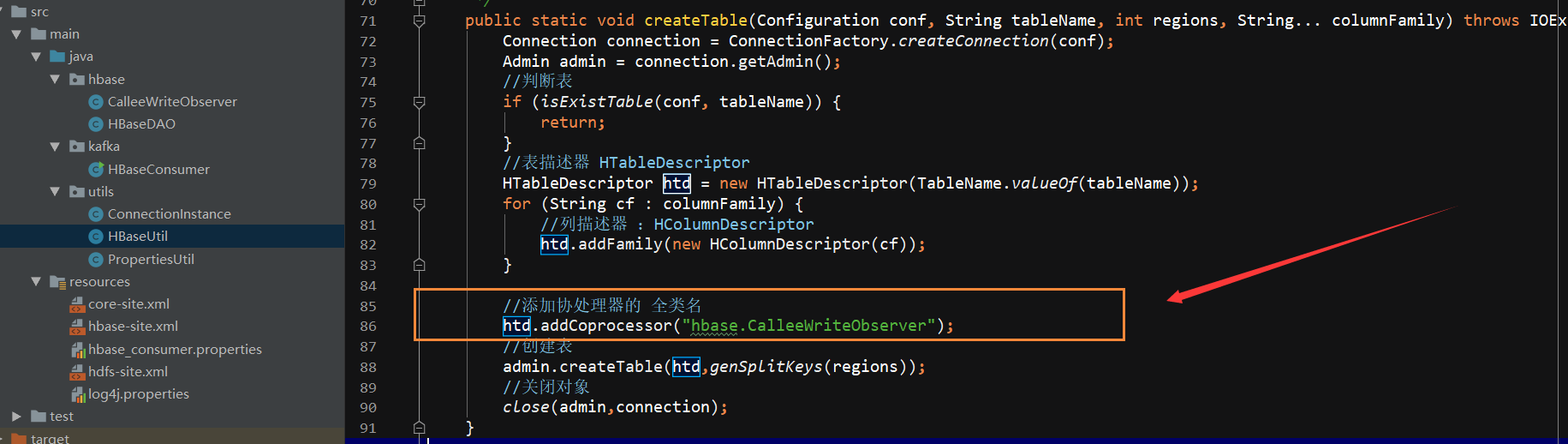
public class CalleeWriteObserver extends BaseRegionObserver {
private SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMddHHmmss");
@Override
public void postPut(ObserverContext<RegionCoprocessorEnvironment> e,
Put put,
WALEdit edit,
Durability durability) throws IOException {
// super.postPut(e, put, edit, durability);
// 注意一定要删除 super.postPut(e, put, edit, durability); 但是!!!!!!老师给的里面没有删掉!!!!!!!
//获取你想要操作得那张目标表 这个很重要!!!
String targetTableName = PropertiesUtil.getProperty("hbase.calllog.tablename");
//获取当前put数据得表
String currentTableName = e.getEnvironment().getRegionInfo().getTable().getNameAsString();
if(!targetTableName.equals(currentTableName)){
return;
}
//05_18549641558_2018-07-20 18:25:43_13980337439_1_0176 这个应该是主叫数据
String oriRowKey = Bytes.toString(put.getRow());
String[] splitOriRowKey = oriRowKey.split("_");
String caller = splitOriRowKey[1];
//如果当前插入的是被叫数据,则直接返回(因为默认提供的数据全部为主叫数据) flag对应 0是被叫数据
String flag = splitOriRowKey[4];
String calleeflag = "0";
if (flag.equals(calleeflag)) {
return;
}
flag = calleeflag;
String duration = splitOriRowKey[5];
Integer regions = Integer.valueOf(PropertiesUtil.getProperty("hbase.calllog.regions"));
String regionCode = HBaseUtil.genRegionCode(caller, buildTime, regions);
String calleeRowKey = HBaseUtil.genRowkey(regionCode, callee, buildTime, caller, flag, duration);
// 貌似每次建立时间 这个 变量的 时候 都是 放在try里面的
String buildTimeTS = "";
try {
buildTimeTS = String.valueOf(sdf.parse(buildTime).getTime());
} catch (ParseException e1) {
e1.printStackTrace();
}
Put calleePut = new Put(Bytes.toBytes(calleeRowKey));
calleePut.addColumn(Bytes.toBytes("f2"), Bytes.toBytes("callee"), Bytes.toBytes(caller));
Table table = e.getEnvironment().getTable(TableName.valueOf(targetTableName));
table.put(calleePut);
table.close();
}
}
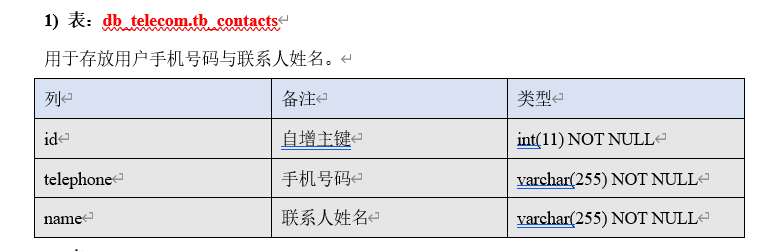
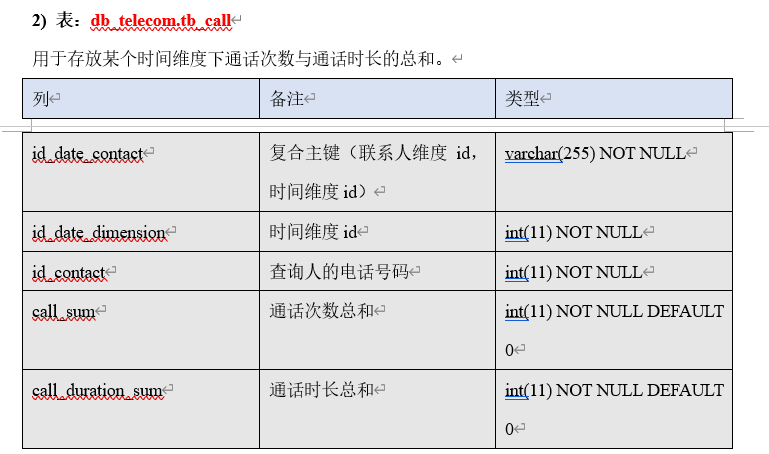
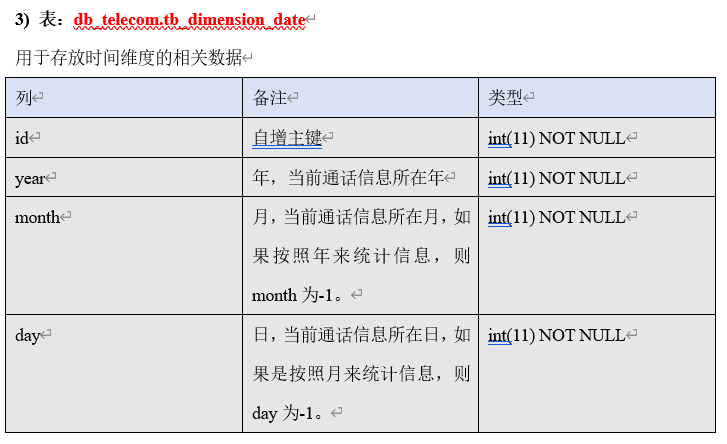
█ 6. 数据分析 MySQL
█ 7. 坑
电信项目在协处理器部分的坑
1. 如果是在16010页面出现了‘红色’的警告 ===> 和协处理器有关
三个都有jar包,包在lib里 还有hbase-site里也要改
2. 如果重新置换ct_消费者。需要的步骤如下
a. 删除ZK的/hbase节点 zkCli.sh ===> rmr /hbase
b. 删除HDFS的/hbase 目录 ===> hadoop fs -rmr /hbase
3. 记得把Hbase_Home中的lib里面替换掉
4. 检查hbase的命名空间和表,记得删了
5. start-hbase.sh群一起启动启动不了,说明机器有问题,
6. 还有出现错误是在代码hbase手写代码中的切割部分split,两个文件HBaseDAO 和 协处理器 CalleeWriteObserver中,检查越界,这里是分割符的问题,改-为\t tab都可以
7. 还有可能是zookeeper和kafka中的机器型号都不一样
zkData里的myid
8. hbase中创建表格的操作的API对应的函数(重写)
把这个包传上去,
conf : vi hbase-site 里面加上我们的包,也就是添加协处理器!
date
这个也要有!!!
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<!--HBase的协处理器-->
<property>
<name>hbase.coprocessor.region.classes</name>
<value>hbase.CalleeWriteObserver</value>
</property>
对应的把它也添加到自行编写的代码中去
customer
一、hbase 爆红:
1. 消费者的代码没有分发到Hbase中的lib目录下;
2. hadoop-env。sh 的里面添加HADOOP_CLASSPATH:
vi hadoop-env.sh的第44行: export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/root/sof/hbase/lib/*
3. 如果还要问题就是代码问题或者历史遗留:
如果stop-hbase.sh不能把整个集群都关掉,说明机器有问题,
输入命令ziCli.sh,输出信息中最后是hbase,则直接输入 rmr /hbase
进入50070中,看HDFS的/hbase 目录 ===> hadoop fs -rmr /hbase
hbase目录下的logs日志 /hbase/logs
代码问题
将customer和analysis都分别分发到各个机器,命令是:
scp -r ct_consumer-1.0-SNAPSHOT.jar root@bigdata180:/root/sof/hbase-1.3.0/lib
启动集群:start-hbase.sh
hbase shell
删除里面的表:
disable 'ns_ct:calllog'
drop 'ns_ct:calllog'
drop_namespace 'ns_ct'
list_namespace
list
16010中爆红error:hbase:meta,.1.1588230740....
首先要把协处理器先关掉:
对应HBaseUtil中的:htd.addCoprocessor("hbase.CalleeWriteObserver");
二、数组下标越界异常(ArrayIndexOutOfBoundsException)
对应HBaseDAO中的: String[] splitOri = ori.split(",");
尝试把它换成其他的分割符多试几次。
analysis:
一、 runner->CountDurationRunner ->58:String tableName = "ns_ct:calllog";
utils-> JDBCUtil -> 179
utils-> JDBCInstance -> 179
二、 cd hadoop/etc/hadoop
vi hadoop-env.sh的第44行: export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/root/sof/hbase-1.3.0/lib/*
ct_web:
一、 ct_web\src\main\resources\dbconfig.properties中修改179
二、添加Tomcat configure -> + -> Tomcat -> deployment server!!
此处有图啊啊啊啊啊啊
靠技术实力称霸,千面鬼手大人万岁!

