kafka hbase MR
!!项目解说:
1.实时生成通话记录数据,
2.通过flume 采集 到kafka 传入kafka topic,,
3.Kafka API编写kafka消费者,读取kafka集群中缓存的消息, 将读取出来的数据写入到HBase中
4.HBase输出到MySql;
数据:电话号码和联系人 通话时长 时间SimpleDateFormat
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(filePath,true), "UTF-8");
给flume配置conf 《 source sink channel 》 采集实时产生的数据到kafka集群
/root/sof/flume/bin/flume-ng agent --conf /root/sof/flume/conf/ --name a1 --conf-file /root/sof/flume/jobconf/flume2kafka.conf
配置properties文件,调用API:
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(PropertiesUtil.properties);
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
定义HBaseDAO 把属性列出来;之后hbase操作 消费数据:
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
boolean result = admin.tableExists(TableName.valueOf(tableName));
htd.addFamily(new HColumnDescriptor(cf));
java -Djava.ext.dirs=F:\maven-lib\lib\ -cp F:\maven-lib\ct_consumer-0.0.1-SNAPSHOT.jar com.china.ct_consumer.kafka.HBaseConsumer
使用HBase查找数据时,尽可能的使用rowKey去精准的定位数据位置
█ 1.kafka
○ 1.1 Kafka定义:
Kafka就是一个缓存,可以解耦,可以承载很多数据,性能好。
Redis也可以做缓存
Kafka 是开源消息系统,可以处理实时数据,高通量、低等待的平台。
是一个分布式消息队列,根须topic来归类。发送消息的叫Producer,接收到 Consumer。
Kafka集群中有多个kafka实例组成,每个实例叫做broker
无论是kafka集群,还是producer、consumer 都依赖于 zookeeper 保存元信息,来保证系统可用性
○ 1.2 kafka架构
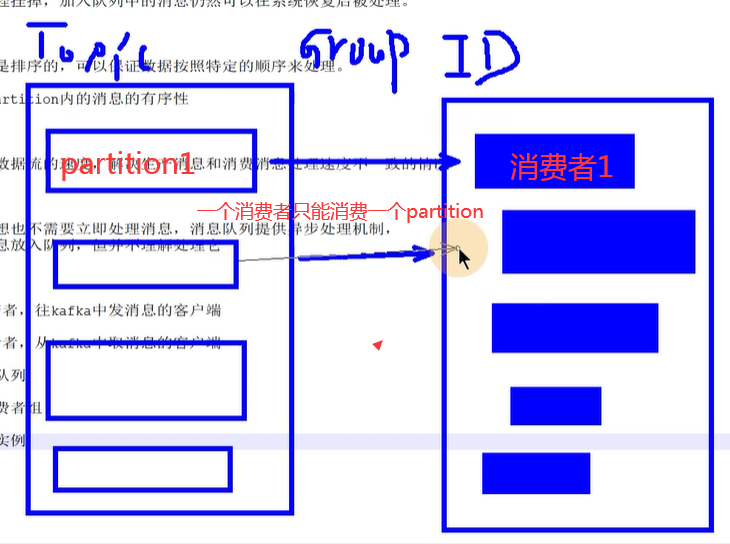
1、Producer 消息生产者,往kafka中发消息的客户端
2、consumer 消息消费者,从kafka中取消息的客户端
3、Topic 可以理解为队列
4、Consumer Group 消费者组
组内有多个消费者实例,他们共享一个公共的ID,即groupID
组内所以消费者协调在一起,消费topic
每个分区,只能有同一个消费者组内的一个consumer消费
5、broker
一个kafka服务器就是一个broker
6、partition :一个topic可以分为多个partition
每个partition都是一个有序队列
kafka保证按一个partition中的顺序,将消息发送给consumer
不能保证topic整体有序
7、offset:
kafka的存储文件都是按照offset.kafka来命名。
用offset做名字的好处是方便查找。
例如:找2049的位置,只要找到2048.kafka。
○ 1.3 消息队列
1、点对点模式:一对一
特点:发送到队列中的消息,只有一个接受者处理
2、发布、订阅模式:类似于公众号,一对多
数据产生后,推送给所有订阅者。
○ 1.4 kafka的优势 为什么需要消息队列
1、解耦
允许你独立扩展或者修改两边的处理过程
2、冗余
消息队列把数据进行持久化直到他们被完全处理。规避数据丢失风险。
3、扩展性
消息队列解耦了处理过程,增大入队和处理的频率很容易,只要增加处理过程即可。
4、灵活、峰值处理能力
访问量突增的情况下,应用依旧要持续发挥作用,但是这样的突发流量不常见。
如果以处理峰值来投入资源随时待命,无疑是巨大的浪费。
消息队列可以顶住突发的访问压力,而且不会造成突发请求超负荷崩溃情况。
5、可恢复性
系统的一部分组件失效时,不会影响整个系统。
即使一个消费者进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
6、顺序保证
大部分的消息队列是排序的,可以保证数据按照特定的顺序来处理。
kafka只保证一个partition内的消息的有序性
7、缓冲
有助于控制和优化数据流的速度,解决生产消息和消费消息处理速度不一致的情况
8、异步通信
很多时候,用户不想也不需要立即处理消息,消息队列提供异步处理机制,
允许用户把一个消息放入队列,但并不理解处理它
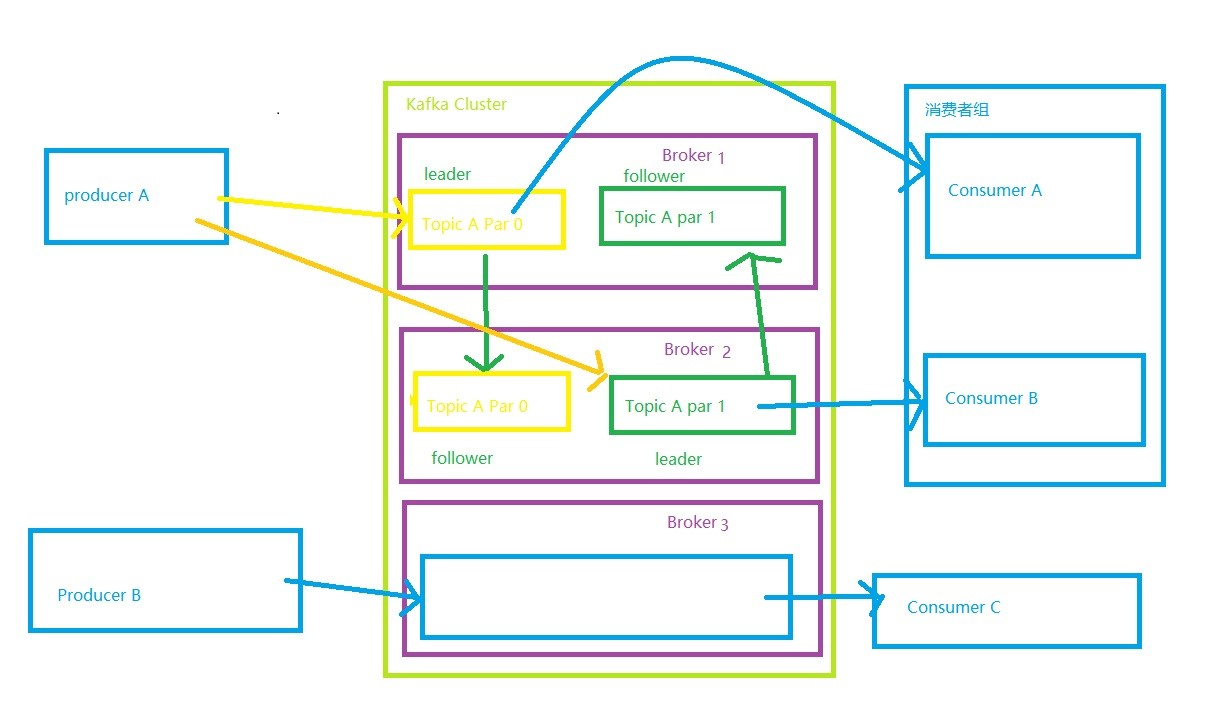
○ 1.5 kafka数据写入读取模型
副本,主从,,往leader里面写,出也是,但是我们不用管,这是内部实现的。
○ 1.6 kafka基本命令
查看当前kafka中所有topic
./bin/kafka-topics.sh --zookeeper node3:2181 --list
创建topic
./bin/kafka-topics.sh --zookeeper node3:2181 --create --replication-factor 2 --partitions 1 --topic topic1122
删除topic
./bin/kafka-topics.sh --zookeeper node3:2181 --delete --topic topic0908
发送消息
./bin/kafka-console-producer.sh --broker-list node3:9092 --topic topic1122
接收消息
./bin/kafka-console-consumer.sh --bootstrap-server node3:9092 --from-beginning --topic topic1122
消费者组
修改consumer.properties文件
启动消费者
./bin/kafka-console-consumer.sh --bootstrap-server node3:9092 --topic topic1122 --consumer.config config/consumer.properties
█ 2.HBase
○ 2.1
HBase是一个分布式的、面向列的开源数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
大:上亿行、百万列
面向列:面向列(簇)的存储和权限控制,列(簇)独立检索
稀疏:对于为空(null)的列,并不占用存储空间,因此,表的设计的非常的稀疏
使用HBase查找数据时,尽可能的使用rowKey去精准的定位数据位置
○ 2.2 HBase的角色
2.2.1、HMaster
功能:
1) 监控RegionServer
2) 处理RegionServer故障转移
3) 处理元数据的变更
4) 处理region的分配或移除
5) 在空闲时间进行数据的负载均衡
6) 通过Zookeeper发布自己的位置给客户端
2.2.2、HRegionServer
功能:
1) 负责存储HBase的实际数据
2) 处理分配给它的Region
3) 刷新缓存到HDFS
4) 维护HLog
5) 执行压缩
6) 负责处理Region分片
组件:
-
Write-Ahead logs
HBase的修改记录,当对HBase读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值
可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。 -
HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。 -
Store
HFile存储在Store中,一个Store对应HBase表中的一个列簇。 -
MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL中之后,RegsionServer会在内存中存储键值对。 -
Region
Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region。
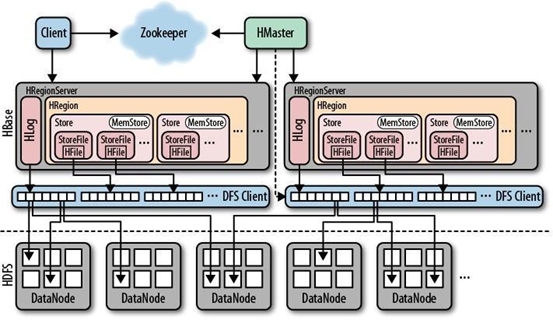
○ 2.3 HBase的架构
一个RegionServer可以包含多个HRegion,每个RegionServer维护一个HLog,和多个HFiles以及其对应的MemStore。RegionServer运行于DataNode上,数量可以与DatNode数量一致,请参考如下架构图:
○ 2.4 HBase优化
2.4.1、预分区
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。那么依照这个原则,我们可以将数据索要投放的分区提前大致的规划好,以提高HBase性能。
1) 手动设定预分区
hbase> create 'staff','info','partition1',SPLITS => ['1000','2000','3000','4000']
2) 生成16进制序列预分区
create 'staff2','info','partition2',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
3) 按照文件中设置的规则预分区
创建splits.txt文件内容如下:
aaaa
bbbb
cccc
dddd
然后执行:
create 'staff3','partition3',SPLITS_FILE => '/opt/module/hbase-1.3.1/splits.txt'
4) 使用JavaAPI创建预分区
//自定义算法,产生一系列Hash散列值存储在二维数组中
byte[][] splitKeys = 某个散列值函数
//创建HBaseAdmin实例
HBaseAdmin hAdmin = new HBaseAdmin(HBaseConfiguration.create());
//创建HTableDescriptor实例
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
//通过HTableDescriptor实例和散列值二维数组创建带有预分区的HBase表
hAdmin.createTable(tableDesc, splitKeys);
2.4.2、RowKey设计
一条数据的唯一标识就是rowkey,那么这条数据存储于哪个分区,取决于rowkey处于哪个一个预分区的区间内,设计rowkey的主要目的 ,就是让数据均匀的分布于所有的region中,在一定程度上防止数据倾斜。接下来我们就谈一谈rowkey常用的设计方案。
1) 生成随机数、hash、散列值
比如:
原本rowKey为1001的,SHA1后变成:dd01903921ea24941c26a48f2cec24e0bb0e8cc7
原本rowKey为3001的,SHA1后变成:49042c54de64a1e9bf0b33e00245660ef92dc7bd
原本rowKey为5001的,SHA1后变成:7b61dec07e02c188790670af43e717f0f46e8913
在做此操作之前,一般我们会选择从数据集中抽取样本,来决定什么样的rowKey来Hash后作为每个分区的临界值。
2) 字符串反转
20170524000001转成10000042507102
20170524000002转成20000042507102
这样也可以在一定程度上散列逐步put进来的数据。
3) 字符串拼接
20170524000001_a12e
20170524000001_93i7
2.4.3、内存优化
HBase操作过程中需要大量的内存开销,毕竟Table是可以缓存在内存中的,一般会分配整个可用内存的70%给HBase的Java堆。但是不建议分配非常大的堆内存,因为GC过程持续太久会导致RegionServer处于长期不可用状态,一般16~48G内存就可以了,如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死。
2.4.4、基础优化
1) 允许在HDFS的文件中追加内容
不是不允许追加内容么?没错,请看背景故事:
http://blog.cloudera.com/blog/2009/07/file-appends-in-hdfs/
hdfs-site.xml、hbase-site.xml
属性:dfs.support.append
解释:开启HDFS追加同步,可以优秀的配合HBase的数据同步和持久化。默认值为true。
2) 优化DataNode允许的最大文件打开数
hdfs-site.xml
属性:dfs.datanode.max.transfer.threads
解释:HBase一般都会同一时间操作大量的文件,根据集群的数量和规模以及数据动作,设置为4096或者更高。默认值:4096
3) 优化延迟高的数据操作的等待时间
hdfs-site.xml
属性:dfs.image.transfer.timeout
解释:如果对于某一次数据操作来讲,延迟非常高,socket需要等待更长的时间,建议把该值设置为更大的值(默认60000毫秒),以确保socket不会被timeout掉。
4) 优化数据的写入效率
mapred-site.xml
属性:
mapreduce.map.output.compress
mapreduce.map.output.compress.codec
解释:开启这两个数据可以大大提高文件的写入效率,减少写入时间。第一个属性值修改为true,第二个属性值修改为:org.apache.hadoop.io.compress.GzipCodec或者其他压缩方式。
5) 优化DataNode存储
属性:dfs.datanode.failed.volumes.tolerated
解释: 默认为0,意思是当DataNode中有一个磁盘出现故障,则会认为该DataNode shutdown了。如果修改为1,则一个磁盘出现故障时,数据会被复制到其他正常的DataNode上,当前的DataNode继续工作。
6) 设置RPC监听数量
hbase-site.xml
属性:hbase.regionserver.handler.count
解释:默认值为30,用于指定RPC监听的数量,可以根据客户端的请求数进行调整,读写请求较多时,增加此值。
7) 优化HStore文件大小
hbase-site.xml
属性:hbase.hregion.max.filesize
解释:默认值10737418240(10GB),如果需要运行HBase的MR任务,可以减小此值,因为一个region对应一个map任务,如果单个region过大,会导致map任务执行时间过长。该值的意思就是,如果HFile的大小达到这个数值,则这个region会被切分为两个Hfile。
8) 优化hbase客户端缓存
hbase-site.xml
属性:hbase.client.write.buffer
解释:用于指定HBase客户端缓存,增大该值可以减少RPC调用次数,但是会消耗更多内存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少RPC次数的目的。
9) 指定scan.next扫描HBase所获取的行数
hbase-site.xml
属性:hbase.client.scanner.caching
解释:用于指定scan.next方法获取的默认行数,值越大,消耗内存越大。
10) flush、compact、split机制
当MemStore达到阈值,将Memstore中的数据Flush进Storefile;compact机制则是把flush出来的小文件合并成大的Storefile文件。split则是当Region达到阈值,会把过大的Region一分为二。
涉及属性:
即:128M就是Memstore的默认阈值
hbase.hregion.memstore.flush.size:134217728
即:这个参数的作用是当单个HRegion内所有的Memstore大小总和超过指定值时,flush该HRegion的所有memstore。RegionServer的flush是通过将请求添加一个队列,模拟生产消费模型来异步处理的。那这里就有一个问题,当队列来不及消费,产生大量积压请求时,可能会导致内存陡增,最坏的情况是触发OOM。
hbase.regionserver.global.memstore.upperLimit:0.4
hbase.regionserver.global.memstore.lowerLimit:0.38
即:当MemStore使用内存总量达到hbase.regionserver.global.memstore.upperLimit指定值时,将会有多个MemStores flush到文件中,MemStore flush 顺序是按照大小降序执行的,直到刷新到MemStore使用内存略小于lowerLimit
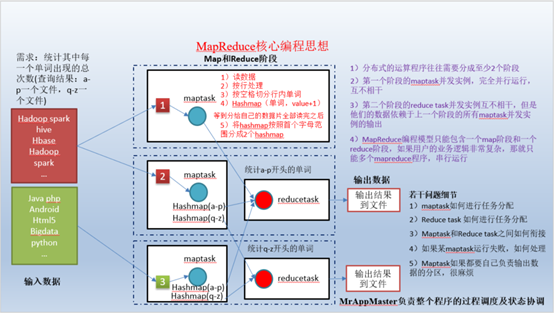
█ 3.MapReduce
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架。
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。
优点
1)MapReduce 易于编程。
2)良好的扩展性。
3)高容错性。
4)适合PB级以上海量数据的离线处理。
缺点
MapReduce不擅长做实时计算、流式计算、DAG(有向图无环图)计算。
1)实时计算。
2)流式计算。
3)DAG(有向图无环图)计算。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号