阳哥:juc多线程及高并发
█ 1.volatile
volatile int
轻量级的同步机制
三大特性:保证可见性 || 不保证原子性(一个线程做 不能被加塞,同时成功/失败) || 禁止指令重排
要保证原子性 就 加 1.volatile 2.synchronize int() /// AtomicInteger .getAndIncrement
指令重排:

禁止指令重排,是加了内存屏障,内存屏障CPU指令:1.保证执行顺序 其前后都不能换 2.保证可见性
volatile 写操作:storestore屏障 StoreLoad屏障
volatile 读操作:loadload屏障 loadStore屏障
○ 1.2 jmm内存模型
他是一个规范,不是真实是存在的
java内存模型 规定所有的变量都在 主内存 是共享内存空间
jvm运行实体是线程,线程的工作内存是 私有数据区域
线程把 主内存的变量数据 拷贝到工作内存,完事 在放回主内存 更新上。
jmm的三个特性:1.可见性 || 2.原子性 || 3.有序性《相当于了禁止指令重排》
验证代码:
代码1 可见性:构造一个Thread让他sleep 并改了,main就拿不到改的
代码2 原子性:number++,开20个线程,每个添加1000回,最后不是20000个,,需要1.volatile int number 2. synchronize int() /// AtomicInteger .getAndIncrement
○ 1.3 volatile 应用(1单例+双端检索//2读写锁//3.CAS):
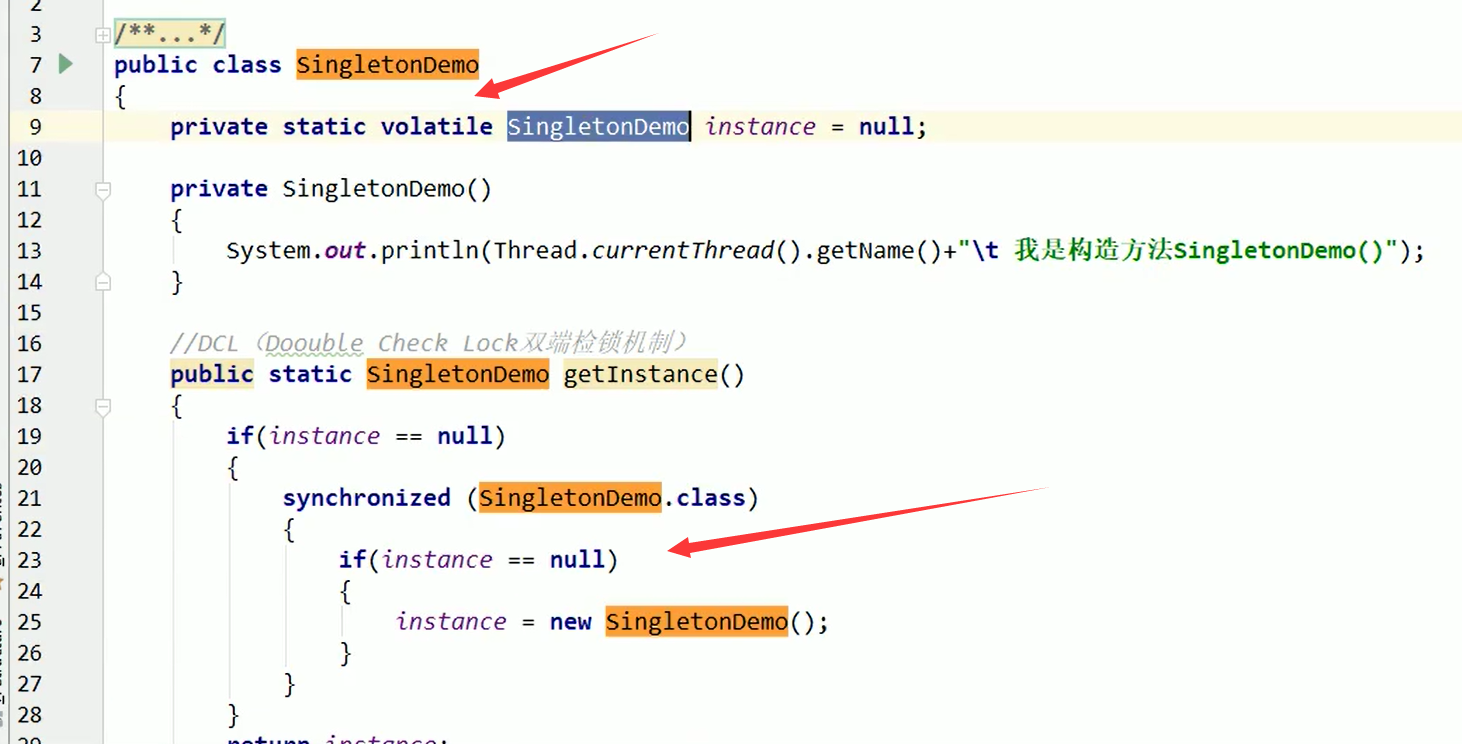
1.3.1 单例模式 : volatile 类名instance + DCL双端检索机制(线程不安全)
双端检锁 线程不安全 因为指令重排
sychronized前判断instance==null,后也加上
他做的是 1.分配对象内存空间//2.初始化对象//3.instance指向分配的内存地址。
1.3.2 读写锁 手写缓存的时候
new CopyOnWriteArrayList() 写时复制 里面是volatile array数组,添加的时候复制一个容器,完事后指向他的setArray方法;;;;;;读不加锁。
1.3.3 CAS底层也是
自旋
unsafe类里都是native方法,unsafe可以直接操作 特定内存数据
unsafe unsafe.getAndAddInt() 传一个内存偏移地址,里面有个do-while,根据jmm内存模型 直到工作内存跟主内存的值一样,才退出循环,,,自旋。
do-while循环里面的 compareAndSwapInt,就是CPU并发原语,保证原子性。有Atomic
value用volatile修饰保证可见性**。
█ 2.CAS = unsafe+自旋
比较并交换Compare-And-Swap
CPU并发原语。是硬件的,就是原子性的。
自旋锁和unsafe类
2.1 unsafe
rt.jar 里 sun.misc.unsafe
CAS保证线程安全 靠的是 unsafe类,没有加锁。
2.2 自旋
unsafe类里都是native方法,unsafe可以直接操作 特定内存数据
unsafe unsafe.getAndAddInt() 传一个内存偏移地址,里面有个do-while,根据jmm内存模型 直到工作内存跟主内存的值一样,才退出循环,,,自旋。
do-while循环里面的 compareAndSwapInt,就是CPU并发原语,保证原子性。有Atomic
value用volatile修饰保证可见性**。
AtomicInteger里面 是 UNsafe+CAS
○ 2.3 CAS的缺点:
1.循环时间长开销大。CAS失败,就一直尝试。do-while一直
2.只能保证一个共享变量的原子操作。没有加锁。
3.ABA问题。
○ ○ 2.3.1 ABA问题
头尾相同,中间被改过。加上时间戳用
AtomicReference<Integer> atomicStampedReference = new AutomicStampedReference<>(100,version);
atomicStampedReference.getStamp();
█ 3.原子类AtomicInteger的ABA问题,原子引用更新
AtomicInteger里面 是 UNsafe+CAS
自旋:
unsafe类里都是native方法,unsafe可以直接操作 特定内存数据
unsafe unsafe.getAndAddInt() 传一个内存偏移地址,里面有个do-while,根据jmm内存模型 直到工作内存跟主内存的值一样,才退出循环,,,自旋。
do-while循环里面的 compareAndSwapInt,就是CPU并发原语,保证原子性。有Atomic
value用volatile修饰保证可见性**。
ABA:
头尾相同,中间被改过。加上时间戳用
AtomicReference<Integer> atomicStampedReference = new AutomicStampedReference<>(100,version);
atomicStampedReference.getStamp();
█ 5.锁
○ 5.1 synchronized和lock的区别:
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition(); condition.await();.signalAll();
○ 5.2 锁的种类
公平锁 非公平锁/可重入锁(又名递归锁)/独占锁 共享锁/自旋锁
公平锁: 先来后到。FIFO
非公平锁:优先级。ReentrantLock默认是false 不公平.;;;;;synchronized
缺点:优先级反转 // 饥饿现象
优点: 吞吐量比公平锁大。
可重入锁:ReentrantLock synchronized 外层有锁,内层自动也有锁,,线程可以进入有锁的同步代码块。对应的线程是同一个线程
优点:避免死锁
自旋锁:循环的去尝试获取锁
缺点:循环消耗CPU
优点:减少线程上下文切换的消耗
代码:两个线程强,一个调用mylock不是null了,另一个只能等
AtomicReference<Thread> void mylock{while(!automicReference.compareAndSet()){}}
独占锁:一个锁只能被一个线程持有
共享锁:多个线程持有。ReentrantReadWriteLock 读锁是共享锁,写锁是独占锁
写操作:原子+独占
.lock() .unlock() .
○ 5.3 死锁
争抢资源 互相等待。
代码:自己持有锁,还想要别人的
○ ○ 5.3.1 产生死锁的原因:
1.系统资源不足 // 2.资源分配 // 3.进程运行顺序不合适
○ ○ 5.3.2 产生死锁的四个必要条件:
1、互斥条件:一个资源每次只能被一个进程使用。
2、请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
3、不剥夺条件: 进程已获得的资源,在末使用完之前,不能强行剥夺。
4、循环等待条件: 若干进程之间形成一种头尾相接的循环等待资源关系。
○ ○ 5.3.3 解决方式 命令行:
jps -l 查看pid
jstack pid
○ ○ 5.3.4 避免死锁
1、按同一顺序访问对象。
2、避免事务中的用户交互。
3、保持事务简短并处于一个批处理中。
4、使用较低的隔离级别。
5、使用基于行版本控制的隔离级别。
6、使用绑定连接。
█ 6.CountDownLatch/CyclicBarrier/Semaphore
CountDownLatch 一个一个减
CountDownLatch countDownLatch= new CountDownLatch(7);先countDown(),再await()
await(),调用线程会阻塞,其他线程调用 xxx.countDown();计数器会-1 不会阻塞,
变为0是,await阻塞的会被唤醒。
CyclicBarrier 集齐召唤 全部到达屏障之后开门
CyclicBarrier cyclicBarrier = new CyclicBarrier(7,()->{Syop}); await()
Semaphore信号量:1.用于多个共享资源互斥使用;2.用于并发编程数的控制。
Semaphore semaphore= new Semaphore(7) ; semaphore.acquire(); semaphore.release();
█ 7.阻塞队列
阻塞队列空,取阻塞;;阻塞队列满,插阻塞
好处:不得不阻塞,商家欢迎阻塞。
BlockingQueue<String> queue = new ArrayBlockingQueue<>(capacity3);
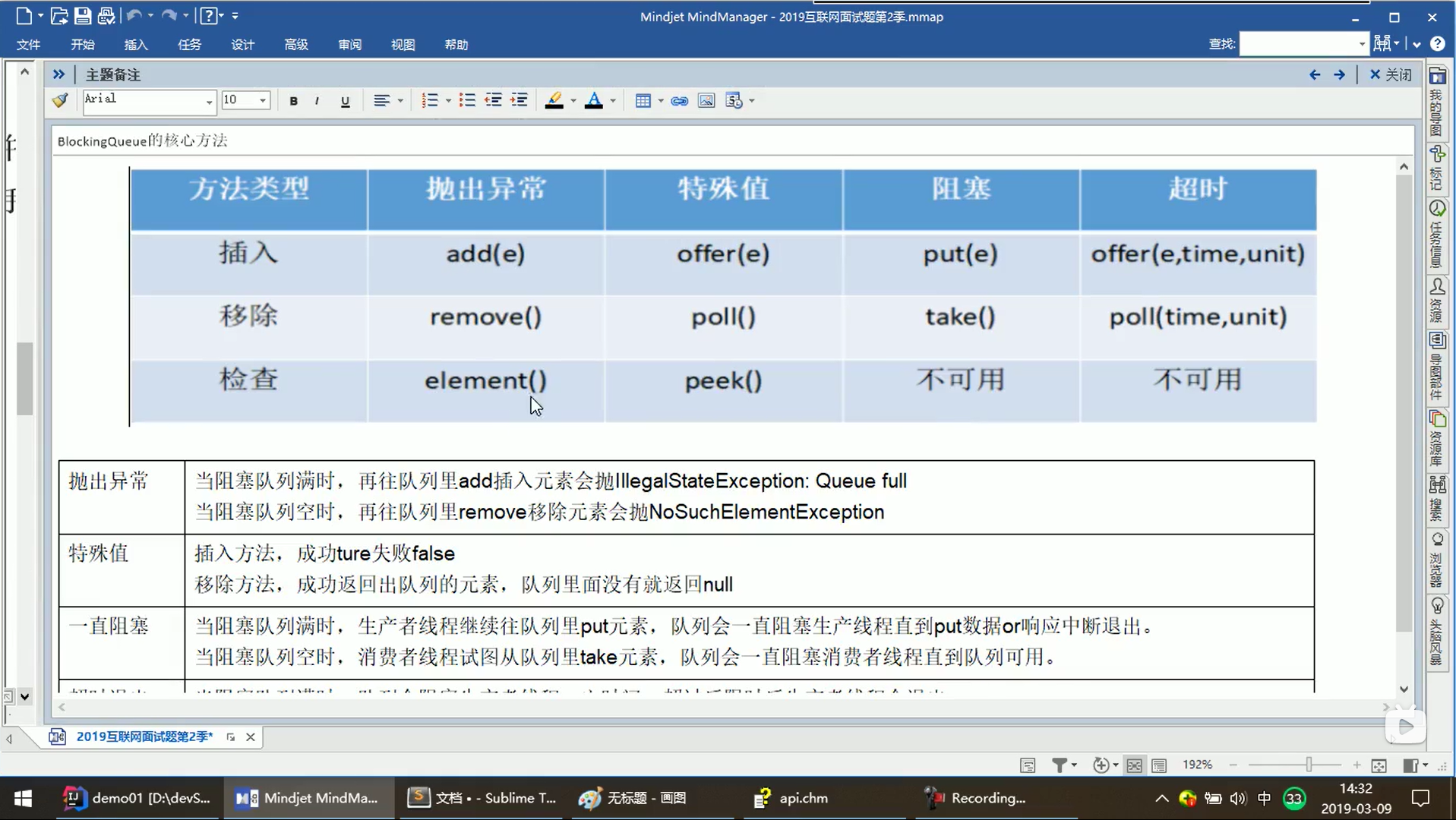
7.1 阻塞队列的种类:
ArrayBlockingQueue有界 // LinkedBlockingQueue 无界// SynchronousQueue 单个元素无容量 put() take() 不消费不生产// LinkedBlockingDeque双向阻塞队列

○ 7.2 阻塞队列用在哪:
1.生产者消费者模式 //2.线程池// 3.消息中间件
多线程的判断 用while 不能用if<2个线程>,线程多了会出错。 防止虚假唤醒
○ ○ 7.2.1 生产者消费者模式
lock.newCondition(); condition.await(); condition.signalAll();精确唤醒condition.signal(); finally{condition.unlock();}
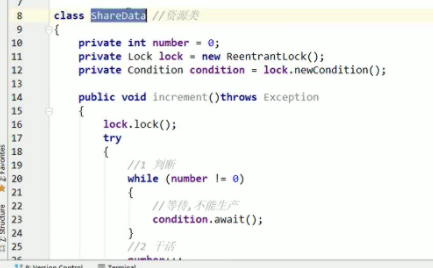

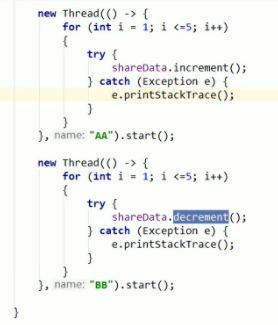
█ 8.线程 进程
Linux 系统中单个进程的最大线程数有其最大的限制 PTHREAD_THREADS_MAX。 1024<root是unlimited>
线程的 stack 所占用的内存,用 ulimit -s 可以查看默认的线程栈大小,一般情况下,这个值是8M=8192KB。
进程是资源分配的基本单位;线程是系统调用(cpui调度)的基本单位。
开发人员写的程序是 进程,进程是一系列线程和资源的统称,一个进程至少1个线程main,还可以new Thread 创建别的线程;;;
多线程:可以同时进行 调用共享变量 并发操作。
线程共享的环境 包括 1.进程代码段,2.进程的公有数据(利用这些共享的数据,线程间通信),3.堆中的数据、4.进程打开的文件描述符、5.进程ID和进程组ID。
○ 8.1 进线程区别
1、地址空间:同一进程的线程共享本进程的地址空间,而进程之间则是独立的地址空间。
2、资源拥有:同一进程内的线程共享本进程的资源,但是进程之间的资源是独立的。
3、一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
4、进程切换时,消耗的资源大,效率高。频繁的切换时,线程好:要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
5、执行过程:每个独立的进程程有一个程序运行的入口、顺序执行序列和程序入口。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
6、线程是处理器调度的基本单位,但是进程不是。
7、两者均可并发执行。
○ 8.2 进线程 优缺点:
线程执行开销小,但是不利于资源的管理和保护。线程适合在SMP机器(双CPU系统)上运行。
进程执行开销大,但是能够很好的进行资源管理和保护。进程可以跨机器前移。
○ 8.3 用到多线程 的场景
1.下载文件 操作文件 /// 2.后台线程 /// 3.分布式 /// 4.备份日志

○ 8.4 多线程 实现方法 callable
1.继承Thread类 // 2.Runnable接口无返回值不抛异常 // 3.callable有返回值抛异常 // 4.线程池

implements Runnable run()
implements Callable<Integer> call()
FutureTask<Integer> futureTask = new FutureTask<>(new MyThread());
while(!futureTask.isDone()){}
futureTask.get(); callable线程如果没有计算完,会堵塞,。公用的futureTask只计算一次。
多线程 实现同步方法
同步的实现方面有两种,分别是synchronized,wait与notify
wait():使一个线程处于等待状态,并且释放所持有的对象的lock。
sleep():使一个正在运行的线程处于睡眠状态,是一个静态方法,调用此方法要捕捉InterruptedException异常。
notify():唤醒一个处于等待状态的线程,注意的是在调用此方法的时候,并不能确切的唤醒某一个等待状态的线程,而是由JVM确定唤醒哪个线程,而且不是按优先级。
Allnotity():唤醒所有处入等待状态的线程,注意并不是给所有唤醒线程一个对象的锁,而是让它们竞争。
?????????○ 8.5 定位有问题的线程可以用如下命令
ps -mp pid -o THREAD,tid,time | more
2、查看JAVA进程的每个线程的CPU占用率
ps -Lp 5798 cu | more # 5798是查出来进程PID
3、追踪线程,查看负载过高的原因,使用JDK下的一个工具
jstack 5798 # 5798是PID
jstack -J-d64 -m 5798 # -j-d64指定64为系统
jstack 查出来的线程ID是16进制,可以把输出追加到文件,导出用记事本打开,再根据系统中的线程ID去搜索查看该ID的线程运行内容,可以和开发一起排查。
█ 9.线程池 ThreadPoolExecutor 要自定义
线程池特点:线程复用 ;控制最并发数 ; 管理线程。
线程池控制运行线程的数量,将任务放入队列。
优点: 1.降低资源消耗(创建销毁的) 2.提高相应速度(不要等创建) 3.提高线程的可管理性(统一分配 调用)
线程池通过Executor框架实现,用到了Executors ExecutorService,ThreadPoolExecutor这几个类
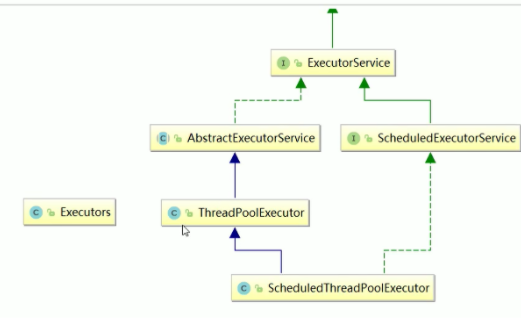
○ 9.1 线程池种类:
有5种线程池:Executors.newFixedThreadPool(int)一池固定数 // Executors.newSingleThreadExecutor()一池一个 // Executors.newCachedThreadPool()一池多线程
这几个请求队列都是Integer.MAX_VALUE OOM

○ 9.2 底层 线程池自定义
7大参数
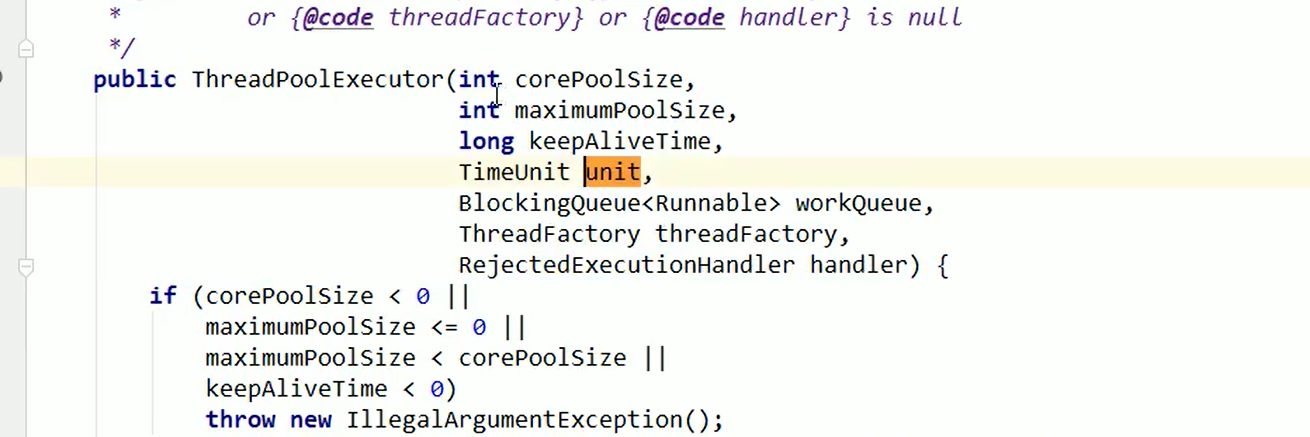
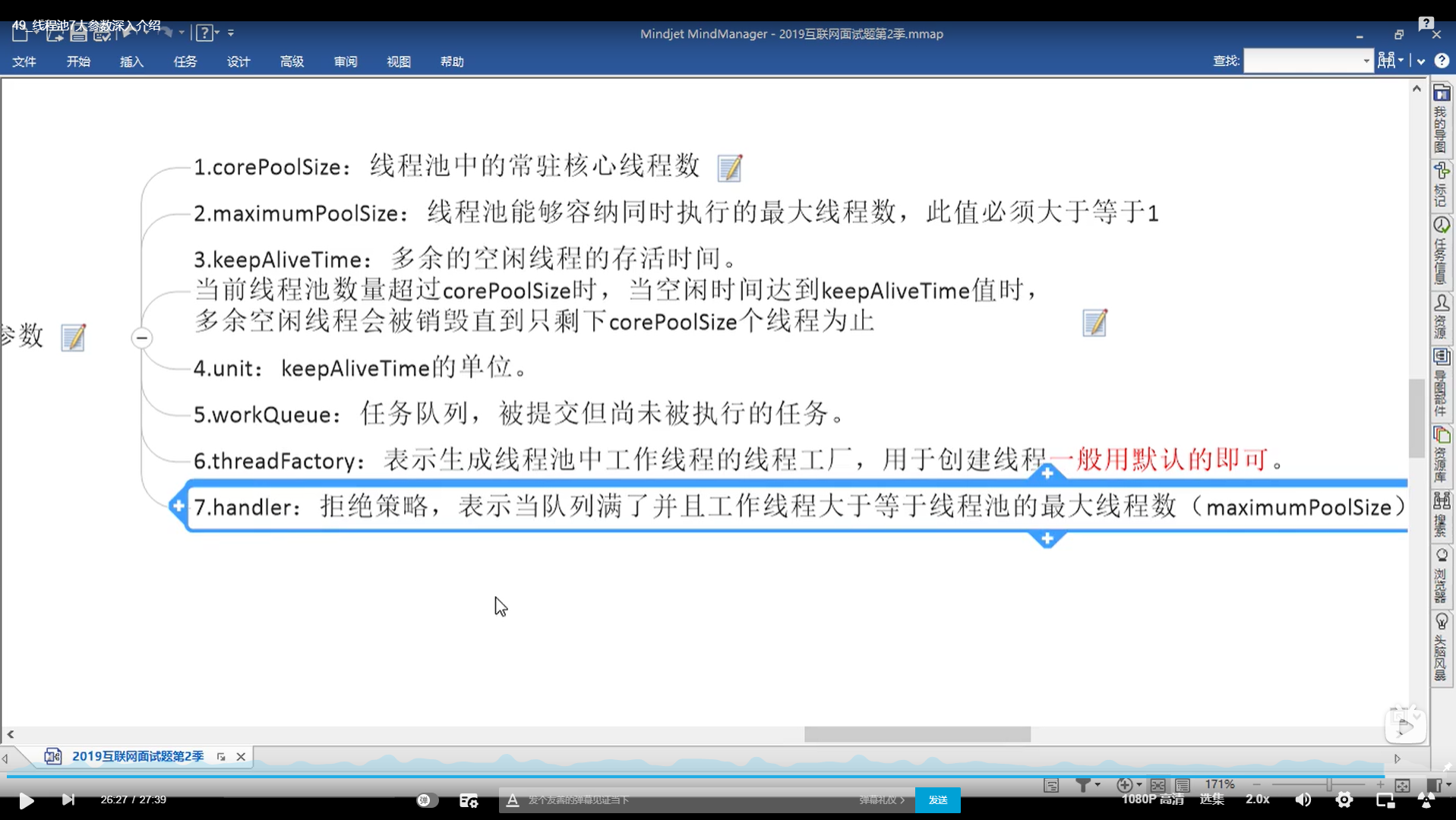
流程:
corePoolSize 不满,直接执行,,如果大于 放入队列;队列满了 maximunPoolsize开启;队列又满了,拒绝策略
○ 9.3 线程池拒绝策略

○ 9.4 合理配置线程池
先查CPU核数 System.out.println(Runtime.getRuntime().availableProcessors());
两种:
1.CPU密集型 < cpu核数+1 个线程 >
2.IO密集型 < cpu核数*2,因为有大量阻塞 还有一种 cpu核数/(1-阻塞系数0.8-0.9)>
█ 函数看CPU核数//内存
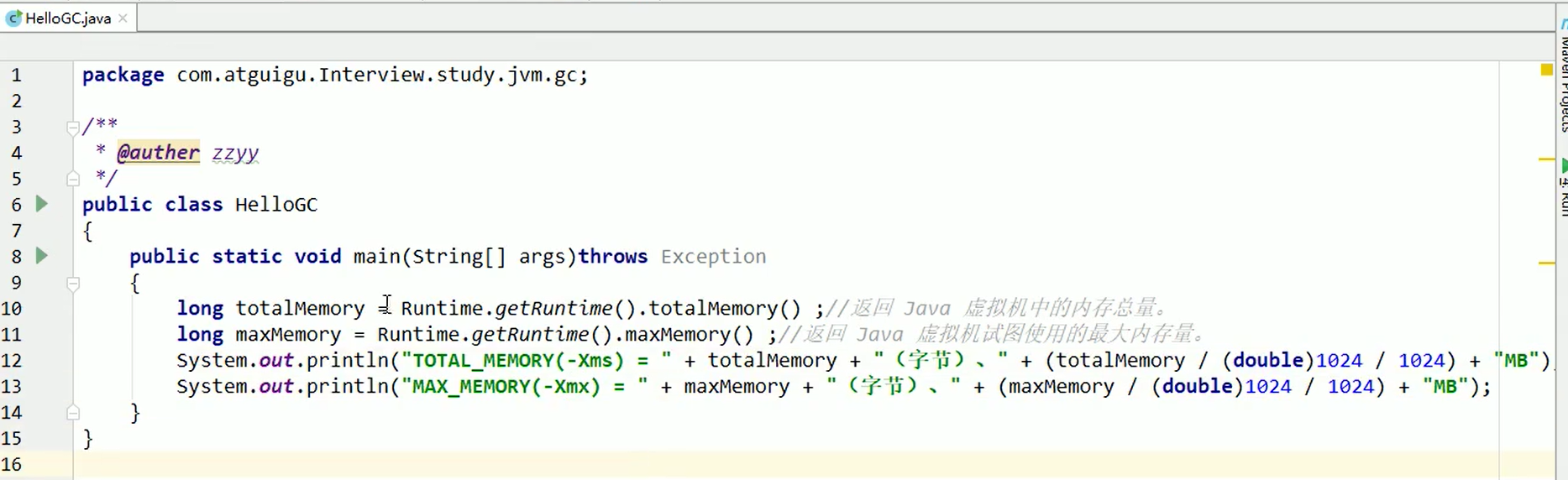
查看CPU的核数:System.out.println(Runtime.getRuntime().availableProcessors());
查看java虚拟机中的内存总量: Runtime.getRuntime().totalMemory();
虚拟机试图使用的最大内存量: Runtime.getRuntime().maxMemory();
█ 2 . CPU比较高的原因
1、首先查看是哪些进程的CPU占用率最高(如下可以看到详细的路径)
ps -aux --sort -pcpu | more
█ ?????????○ 8.5 定位有问题的线程可以用如下命令
ps -mp pid -o THREAD,tid,time | more
2、查看JAVA进程的每个线程的CPU占用率
ps -Lp 5798 cu | more # 5798是查出来进程PID
3、追踪线程,查看负载过高的原因,使用JDK下的一个工具
jstack 5798 # 5798是PID
jstack -J-d64 -m 5798 # -j-d64指定64为系统
jstack 查出来的线程ID是16进制,可以把输出追加到文件,导出用记事本打开,再根据系统中的线程ID去搜索查看该ID的线程运行内容,可以和开发一起排查。
█ 1. 提高并发性
1、提高CPU并发计算能力
(1)多进程&多线程
(2)减少进程切换,使用线程,考虑进程绑定CPU
(3)减少使用不必要的锁,考虑无锁编程
(4)考虑进程优先级
(5)关注系统负载
2、改进I/O模型
(1)DMA技术
(2)异步I/O
(3)改进多路I/O就绪通知策略,epoll
(4)Sendfile
(5)内存映射
(6)直接I/O

 浙公网安备 33010602011771号
浙公网安备 33010602011771号