
MySql数据库 优化
MySQL数据库优化方案
Mysql的优化,大体可以分为三部分:索引的优化,sql慢查询的优化,表的优化。
开启慢查询日志,可以让MySQL记录下查询超过指定时间的语句,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能。
Sql 慢查询优化步骤
先捕获低效SQL→慢查询优化方案→慢查询优化原则
MySQL数据库配置慢查询
参数说明:
1.查询慢查询配置
show variables like 'slow_query%';
slow_query_log 对应 开启状态
slow_query_log_file 对应 慢查询日志存放的位置(这个目录需要MySQL的运行帐号的可写权限,一般设置为MySQL的数据存放目录)
2.查询慢查询限制时间,查询超过多少秒才记录,默认是10s。
show variables like 'long_query_time';
3.将 slow_query_log 全局变量设置为“ON”状态
set global slow_query_log='ON';
4.查询超过1秒就记录
set global long_query_time=1;
5.查询日志,可根据自己查询出来的实际地址进行查看,该例子是以 linux 部署的 mysql 的日志存储位置。
cat /var/lib/mysql/localhost-slow.log
6. linux中 重启 mysql 命令
service mysqld restart
索引为什么会失效?注意那些事项?
1.索引无法存储null值
2.如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因) 要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
3.对于多列索引,不是使用的第一部分,则不会使用索引
4.like查询以%开头 5.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
6.如果mysql估计使用全表扫描要比使用索引快,则不使用索引
举栗子说明:
#### 创建表
CREATE TABLE `user_details` (
`id` int(11) not NULL,
`user_name` varchar(50) DEFAULT NULL,
`user_phone` varchar(11) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
select * from user_details;
#### 新建索引
ALTER TABLE `user_details` ADD INDEX user_name_index ( `user_name` );
### 查询索引
desc user_details;
insert into user_details values(1,'ming1','123456789');
insert into user_details values(2,'ming2','123456789');
insert into user_details values(3,'ming3','123456789');
insert into user_details values(4,'ming4','123456789');
insert into user_details values(5,'ming5','123456789');
insert into user_details values(6,'ming6','123456789');
### 全表扫描
explain select * from user_details where user_phone='123456789';
### 主键索引 type=const
EXPLAIN select * from user_details WHERE id=1
#### 普通索引 type=const
EXPLAIN select * from user_details WHERE id=1 and user_name='ming1';
#### 主键索引 不能使用 % 开头,全表扫描 type=all
EXPLAIN select * from user_details WHERE id like '%sss'
#### 主键索引 % 结尾 全表扫描 type=all
EXPLAIN select * from user_details WHERE id like '1%'
#### 普通索引 %开头 会导致 索引失效 type=all
EXPLAIN select * from user_details WHERE user_name like '%1'
#### 普通索引 %结果 会导致 索引不会失效 type=range
EXPLAIN select * from user_details WHERE user_name like '1%'
##### 条件字符串不加 '' 会导致索引失效 type=all
EXPLAIN select * from user_details WHERE user_name =1;
##### 索引不会失效 type=ref
EXPLAIN select * from user_details WHERE user_name ='1';
### 全表扫描 type=all
EXPLAIN select * from user_details WHERE id='1' or user_name='ming1';
联合索引为什么需要遵循左前缀原则?
如果在一张表中,存在联合索引的话,在根据条件查询的时候必须要加上第一个索引条件。
---索引生效
EXPLAIN select * from user_details WHERE id=1 and user_name=‘yushengjun1’;
索引是不生效的
EXPLAIN select * from user_details WHERE user_name=‘yushengjun1’;
举栗子说明:
###### 联合主键索引 id + user_name 组合索引 #########
#### 联合主键索引 只要 id + user_name 保证唯一即可
CREATE TABLE `userInfo` (
`id` int(11) not NULL,
`user_name` varchar(50) not NULL,
`user_phone` varchar(11) DEFAULT NULL,
PRIMARY KEY (id,user_name)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
SELECT * from userInfo;
insert into userInfo values(1,'明天','123456789');
insert into userInfo values(1,'小明','123456789');
insert into userInfo values(2,'小红','123456789');
insert into userInfo values(2,'大白','123456789');
insert into userInfo values(3,'小龙','123456789');
insert into userInfo values(3,'小菲','123456789');
#### 只能插入成功一条数据 ,因为 id + user_name 需要保证唯一性
insert into userInfo values(4,'小放','123456789');
insert into userInfo values(4,'小放','123456789');
####索引 有效 type=ref
EXPLAIN select * from userInfo WHERE id=1
####索引 有效 type=const
EXPLAIN select * from userInfo WHERE id=1 and user_name='明天';
#### 索引 无效 type=all
EXPLAIN select * from userInfo WHERE user_name='小明';
#### 索引有效 type=const
EXPLAIN select * from userInfo WHERE user_name='小明' and id=1
因为索引底层采用B+树叶子节点顺序排列,必须通过左前缀索引才能定位到具体的节点范围。
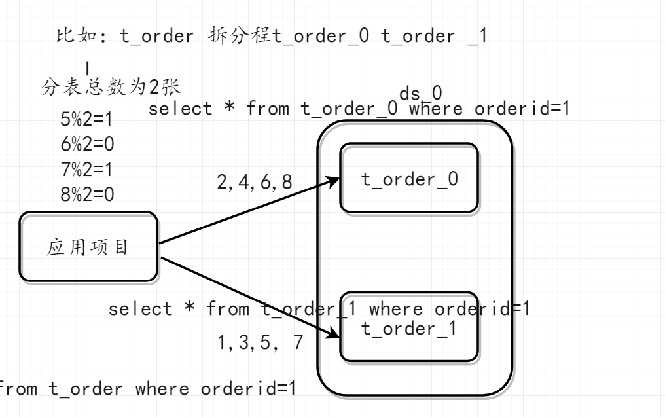
分表分库为什么能够提高数据库查询效率?
因为会将一张表的数据拆分成多个n张表进行存放,让后在使用第三方中间件(MyCat或者Sharding-JDBC)并行同时查询,让后在交给第三方中间进行组合返回给客户端。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号