MySql 索引
为什么要使用索引
MySql 官方对索引的定义为:索引(index)是帮助MySql高效获取数据的数据结构。
白话文:索引就像书的目录一样可以很快的定位到书的页码。
如果像MySql发送一条Sql 语句请求,查询的字段没有创建索引的话,可能会导致全表扫描,这样的话查询效率非常的低。也就是一条一条的去跟数据库存储的数据进行对比,这样效率很低。
全表扫描:会将整张表数据全部扫描一遍,这样的话效率非常低。
数据结构Hash算法
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
优点:查找可以直接根据key访问。
缺点: 不能进行范围查找。
index=Hash(key)。
Hash索引
优点:通过字段的值计算的hash值,定位数据非常快。
缺点:不支持范围查询。
为什么不支持范围查询?
因为底层数据结构是散列的,无法进行比较大小。
数据结构平衡二叉树
平衡二叉查树,又称 AVL树。 它除了具备二叉查找树的基本特征之外,还具有一个非常重要的特点:它 的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值(平衡因子 ) 不超过1。 也就是说AVL树每个节点的平衡因子只可能是-1、0和1(左子树高度减去右子树高度)。
平衡二叉树 会取一个中间值,中间值左边称为左子树 ,中间值右边称为右子树 。
左子树比中间小,右子树比中间值大。
优点:平衡二叉树算法基本与二叉树查询相同,效率比较高。
缺点: 插入操作需要旋转,支持范围查询。

平衡二叉树 查询原理
假设查询10 (需要经历4次IO操作)
1次 从硬盘中读取4 (内存),判断下10>4,取右指针
2次 从硬盘中读取8 (内存),判断下10>8,取右指针
3次 从硬盘中读取9 (内存),判断下10>,取右指针
4次 从硬盘中读取10 (内存),判断下10=10,定位到数据
平衡二叉树 查询效率还可以,说明:如果是全表扫描的话,需要查询10次,而使用平衡二叉树4次就查询出来结果了,所以效率比全表扫描要高很多的。
缺点:虽然支持范围查询,但是回旋查询效率低,需要先定位到本身然后在去右节点找比自己大的节点,导致回旋查询,所以效率比较低。
规律:如果树的高度越高,那么查询IO次数会越多。
数据结构B树
维基百科对B树的定义为“在计算机科学中,B树(B-tree)是一种树状数据结构,它能够存储数据、对其进行排序并允许以O(log n)的时间复杂度运行进行查找、顺序读取、插入和删除的数据结构。B树,概括来说是一个节点可以拥有多于2个子节点的二叉查找树。与自平衡二叉查找树不同,B-树为系统最优化大块数据的读和写操作。B-tree算法减少定位记录时所经历的中间过程,从而加快存取速度。普遍运用在数据库和文件系统。
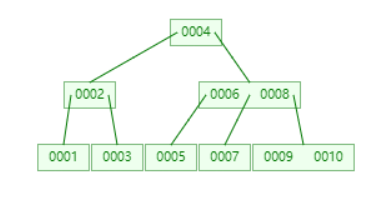
因为B树节点元素比平衡二叉树要多,所以B树数据结构相比平衡二叉树数据结构实现减少磁盘IO的操作。
如何去减少查询IO次数?
B树在平衡二叉树中,减少树的高度。
结论:B树比平衡二叉树减少了一次IO操作。由上面的平衡二叉树与B树的结构图可以得出该结论。
B树查询效率比平衡二叉树效率要高,因为B树的节点中可以有多个元素,从而减少树的高度,减少IO操作,从而提高查询效率。
缺点:范围查询效率还是比较低。
数据结构B+树
B+树相比B树,新增叶子节点与非叶子节点关系,叶子节点中包含了key和value,非叶子节点中只是包含了key,不包含value。 所有相邻的叶子节点包含非叶子节点,使用链表进行结合,有一定顺序排序,从而范围查询效率非常高。
B+树 解决范围查询问题、减少IO查询的操作。
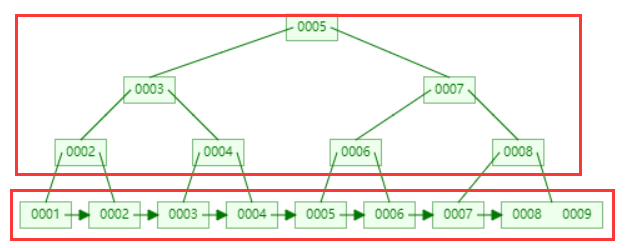
上面是非叶子节点,下面是叶子节点,我们查询是下面那一块的数据。
B+树相比B树,新增叶子节点与非叶子节点关系,叶子节点中包含了key和value,非叶子节点中只是包含了key,不包含value。
B+树算法: 通过继承了B树的特征,B+树相比B树,新增叶子节点与非叶子节点关系,叶子节点中包含了key和value,非叶子节点中只是包含了key,不包含value。通过非叶子节点查询叶子节点获取对应的value,所有相邻的叶子节点包含非叶子节点,使用链表进行结合,有一定顺序排序,从而范围查询效率非常高。
缺点:因为有冗余节点数据,会比较占硬盘大小。
索引文件如何查看
默认数据与索引文件位置: /var/lib/mysql
MyISAM引擎的文件: .myd 即 my data,表数据文件 .myi 即my index,索引文件 .log 日志文件。
InnoDB引擎的文件: 采用表空间(tablespace)来管理数据,存储表数据和索引, InnoDB数据库文件(即InnoDB文件集,ib-file set): ibdata1、ibdata2等:系统表空间文件,存储InnoDB系统信息和用户数据库表数据和索引,所有表共用。 .ibd文件:单表表空间文件,每个表使用一个表空间文件(file per table),存放用户数据库表数据和索引。
MyISAM和InnoDB对B-Tree索引不同的实现方式
主键索引: MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM主键索引的 这里设表一共有三列,假设我们以Col1为主键,图myisam1是一个MyISAM表的主索引(Primary key)示意。可以看出
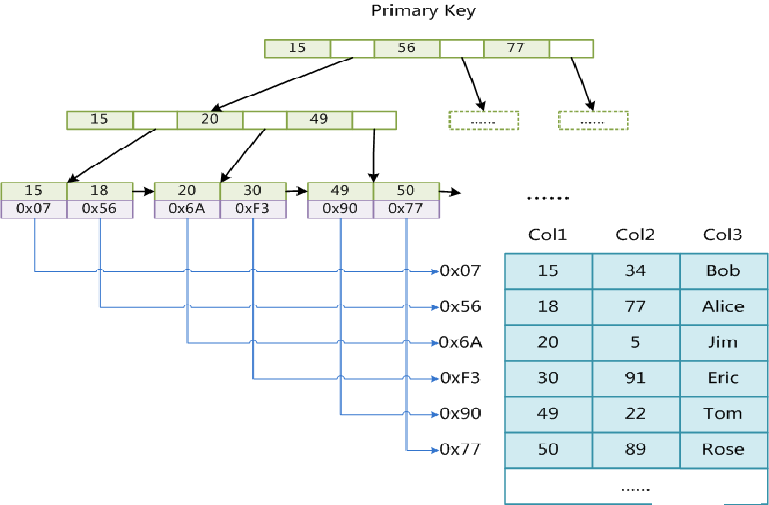
MyISAM和InnoDB对B-Tree索引不同的实现方式
InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同. MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。

MyISAM和InnoDB区别
MyISAM与InnoDB都是采用B+树进行实现的。
MyISAM 底层使用B+树 ,子节点value存放行数的地址,再通过行数定位到数据进行查询。
InnoDB 底层使用B+树,叶子节点value存放的是行的data数据,相比MyISAM效率要高一些,但是比较占硬盘内存。
MySQLb+树能够存放多少字节数据
局部性原理与磁盘预读
计算机科学中著名的局部性原理当一个数据被用到时, 其附近的数据也通常会马上被使用。
为了提高效率,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。
这里的-定长度叫做页,也就是操作系统操作磁盘时的基本单位。一般操作系统中.页的大小是4Kb (getconf PAGE_SIZE) 所以如果在磁盘中读取1kb,实际会读取4kb。
MySQLb+树能够存放多少字节数据
假设在B+树一个节点为1页 如果从磁盘读取超过1页大小,根据局部性原理与磁盘预读 会读出2页大小
如果从磁盘读取小于1页大小,根据局部性原理与磁盘预读 会读出1页大小
根据以上规则,如果读取整哈是页的倍数,这样就可以不用浪费,所以B+树的每一个节点是页的倍数是最佳的。
在MySQL中我们的InnoDB页的大小默认是16k,当然也可以通过参数设置:
show variables like 'innodb_page_size';
16384/1024=16kb;
MySQLb+树能够存放多少字节数据
假设一行为1kb,那么一页可以读取16行数据,一个叶子节点可以存放16条数据 那么非叶子节点存放多少条数据?
非叶子节点存放索引值(bigint 8b) 和 指针(6b) 那么一页16*1024/(8+6)=1170指针
B+树 高度为2 1170*16=18720 条数据
B+树 高度为3 1170*1170*16=21902400 条数据
所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。在查找数据时一次页的查找代表一次IO,所以通过主键索引查询通常只需要1-3次IO操作即可查找到数据。
文档目录:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
在线工具类:https://www.cs.usfca.edu/~galles/visualization/AVLtree.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号