

Elasticsearch 介绍及应用
Elasticsearch简单介绍
Elasticsearch (ES)是一个基于Lucene构建的开源、分布式、RESTful 接口全文搜索引擎。Elasticsearch 还是一个分布式文档数据库,其中每个字段均是被索引的数据且可被搜索,它能够扩展至数以百计的服务器存储以及处理PB级的数据。它可以在很短的时间内在存储、搜索和分析大量的数据。它通常作为具有复杂搜索场景情况下的核心发动机。es是由java语言编写的。
Elasticsearch就是为高可用和可扩展而生的。可以通过购置性能更强的服务器来完成。
Elasticsearch 应用场景
大型分布式日志分析系统 ELK elasticsearch(存储日志)+logstash(收集日志)+kibana(展示数据)
大型电商商品搜索系统、网盘搜索引擎等,主要用于大数据收集。
Elasticsearch优势
横向可扩展性:只需要增加台服务器,做一点儿配置,启动一下Elasticsearch就可以并入集群。
分片机制提供更好的分布性:同一个索引分成多个分片(sharding), 这点类似于HDFS的块机制;分而治之的方式可提升处理效率。
高可用:提供复制( replica) 机制,一个分片可以设置多个复制,使得某台服务器在宕机的情况下,集群仍旧可以照常运行,并会把服务器宕机丢失的数据信息复制恢复到其他可用节点上。
使用简单:共需一条命令就可以下载文件,然后很快就能搭建一一个站内搜索引擎。
Elasticsearch存储结构
Elasticsearch是文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{
"name":"yushengjun",
"sex":0,
"age":24
}
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
9200与9300端口号的区别
9300端口: ES节点之间通讯使用,是TCP协议端口号,ES集群之间通讯端口号。
9200端口: ES节点 和 外部 通讯使用,暴露ES RESTful接口端口号。浏览器访问时,例如:http://192.168.0.110:9200/myindex/user/3
倒排索引
正向索引
正排表是以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。
这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除。但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
尽管正排表的工作原理非常的简单,但是由于其检索效率太低,除非在特定情况下,否则实用性价值不大。
倒排索引
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
正排索引是从文档到关键字的映射(已知文档求关键字),倒排索引是从关键字到文档的映射(已知关键字求文档)。
文档内容:
|
序号 |
文档内容 |
|
1 |
小俊是一家科技公司创始人,开的汽车是奥迪a8l,加速爽。 |
|
2 |
小薇是一家科技公司的前台,开的汽车是保时捷911 |
|
3 |
小红买了小薇的保时捷911,加速爽。 |
|
4 |
小明是一家科技公司开发主管,开的汽车是奥迪a6l,加速爽。 |
|
5 |
小军是一家科技公司开发,开的汽车是比亚迪速锐,加速有点慢 |
倒排索引会对文档内容进行关键词分词,可以使用关键次直接定位到文档内容。
|
单词ID |
单词 |
倒排列表docId |
|
1 |
小 |
1,2,3,4,5 |
|
2 |
一家 |
1,2,4,5 |
|
3 |
科技公司 |
1,2,4,5 |
|
4 |
开发 |
4,5 |
|
5 |
汽车 |
1,2,4,5 |
|
6 |
奥迪 |
1,4 |
|
7 |
加速爽 |
1,3,4 |
|
8 |
保时捷 |
2,3 |
|
9 |
保时捷911 |
2 |
|
10 |
比亚迪 |
5 |
高级查询命令
GET _search
{
"query": {
"match_all": {}
}
}
##### 创建索引
PUT /myindex
##### 查询索引
GET myindex
##### 创建一个文档 /索引/类型/id
PUT /myindex/user/1
{
"name":"mingtian",
"age":24,
"sex":"男"
}
PUT /myindex/user/2
{
"name":"xiaoming",
"age":24,
"sex":"男"
}
PUT /myindex/user/3
{
"name":"校花",
"age":24,
"sex":"女"
}
PUT /myindex/user/4
{
"name":"小凤",
"age":22,
"sex":"女"
}
PUT /myindex/user/5
{
"name":"大白",
"age":22,
"sex":"男"
}
PUT /myindex/user/6
{
"name":"Summer",
"age":20,
"sex":"男"
}
PUT /myindex/user/7
{
"name":"Sun",
"age":18,
"sex":"男"
}
#### 查询文档
GET /myindex/user/1
##### 删除索引
DELETE /myindex
#### 查询索引
GET myindex
#### 高级查询 查询myindex 下面所有的文档信息
GET /myindex/user/_search
####根据多个id 查询
GET /myindex/user/_mget
{
"ids":["1","2"]
}
#### 查询年龄 24 的
GET /myindex/user/_search?q=24
### 查询区间 年龄18-23之间的 TO 必须大写
GET /myindex/user/_search?q=age[18 TO 23]
### 年龄18-23之间的、降序排列、从0条数据到第1条数据
GET /myindex/user/_search?q=age[18 TO 23]&sort=age:desc&from=0&size=2
### 查询区间 年龄18-29之间的 降序排列 、显示5条数据、 只显示 name、age字段
GET /myindex/user/_search?q=age[18 TO 29]&sort=age:desc&from=0&size=5&_source=name,age
Dsl语言查询与过滤
什么是DSL语言
es中的查询请求有两种方式,一种是简易版的查询,另外一种是使用JSON完整的请求体,叫做结构化查询(DSL)。
由于DSL查询更为直观也更为简易,所以大都使用这种方式。
DSL查询是POST过去一个json,由于post的请求是json格式的,所以存在很多灵活性,也有很多形式。
##term是代表完全匹配,即不进行分词器分析,文档中必须包含整个搜索的词汇。
#### term 精准查询 相当于 equals
GET /myindex/user/_search
{
"query":{
"term":{
"name":"xiaoming"
}
}
}
####match查询相当于模糊匹配,只包含其中一部分关键词就行.
#### match 精准查询 相当于 like,只对中文有效
GET /myindex/user/_search
{
"from":0,
"size":2,
"query":{
"match":{
"sex":"男"
}
}
}
使用filter过滤年龄
###### 使用filter 过滤 match_all 查询所有、flter range 表示 age大于17 小于24 、_source 表示显示的字段
GET /myindex/user/_search
{
"query":{
"bool":{
"must":[
{
"match_all":{
}
}
],
"filter":{
"range":{
"age":{
"gt":17,
"lte":24
}
}
}
}
},
"from":0,
"size":10,
"_source":[
"name",
"age"
]
}
Term与Match区别
Term查询不会对字段进行分词查询,会采用精确匹配。
Match会根据该字段的分词器,进行分词查询。
分词器
什么是分词器
因为Elasticsearch中默认的标准分词器分词器对中文分词不是很友好,会将中文词语拆分成一个一个中文的汉子。因此引入中文分词器-es-ik插件 。
standard分词器:
http://192.168.0.110:9200/_analyze
参数:
{
"analyzer":"standard",
"text":"小明"
}
结果为:
{
"tokens":[
{
"token":"小",
"start_offset":0,
"end_offset":1,
"type":"<IDEOGRAPHIC>",
"position":0
},
{
"token":"明",
"start_offset":1,
"end_offset":2,
"type":"<IDEOGRAPHIC>",
"position":1
}
]
}
由上面的结果可以看出来,这个分词器 "analyzer":"standard" 会把结果都拆分成一个个的中文汉字,这肯定是不对的,所以我们需要使用 ik 分词器。
ik 官方网站下载 https://github.com/medcl/elasticsearch-analysis-ik/releases
注意: es-ik分词插件版本一定要和es安装的版本对应
第一步:下载es的IK插件 ,可重命名文件名称。
第二步: 上传到/usr/local/elasticsearch-6.4.3/plugins
第三步: 重启elasticsearch即可
ik_smart 分词器:
http://192.168.0.110:9200/_analyze
参数:
{
"analyzer":"ik_smart",
"text":"小明"
}
结果为:
{
"tokens":[
{
"token":"小明",
"start_offset":0,
"end_offset":2,
"type":"CN_WORD",
"position":0
}
]
}
由上面结果可以看出 使用 ik 分词器 "analyzer":"ik_smart" 会把结果正确显示出来。
自定义扩展词
进入到 es 的安装目录下,找到 ik 插件目录。
cd /usr/local/es/elasticsearch-6.4.3/plugins/ik/config
在这个目录新建一个自定义扩展词放到一个新建文件中。
mkdir custom
vi vi new_word.dic
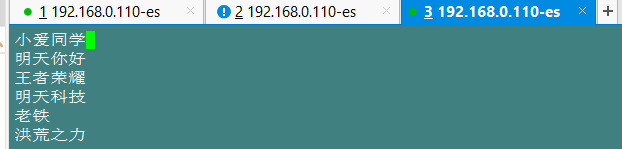

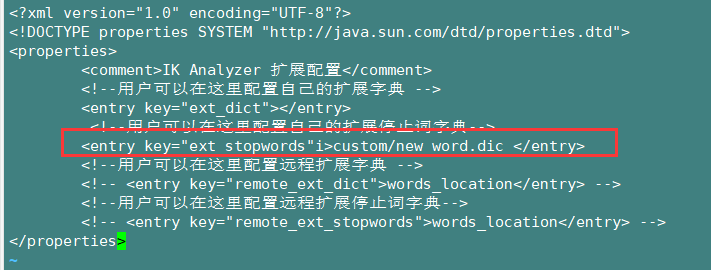
自定义分词器创建好之后,还需要在 ik 配置文件中 指定该分词器文件。
修改 ik 配置文件 ,指定自己新建的分词器文件。
cd /usr/local/es/elasticsearch-6.4.3/plugins/ik/config
vi IKAnalyzer.cfg.xml
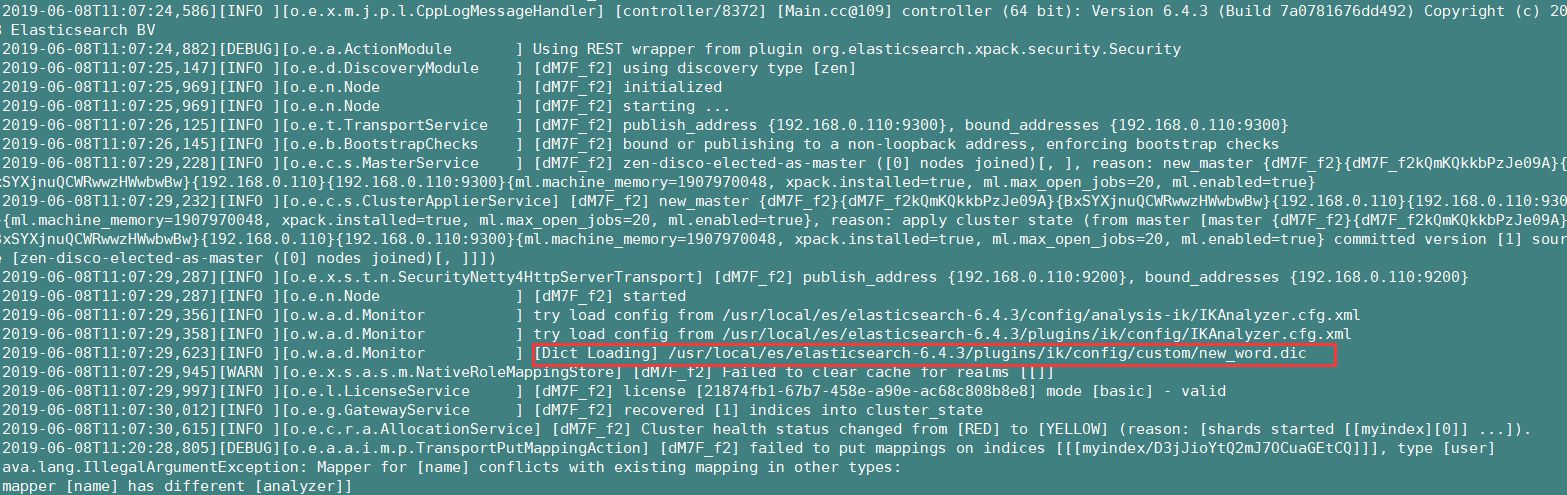
配置好之后,启动 es,如果看到如下图所示的 新建 的分词文件被加载,说明成功了,直接使用 postman 发送请求来验证。
postman 请求地址:http://192.168.0.110:9200/_analyze
参数:
{
"analyzer":"ik_smart",
"text":"小爱同学"
}
响应结果:
{
"tokens":[
{
"token":"小爱同学",
"start_offset":0,
"end_offset":4,
"type":"CN_WORD",
"position":0
}
]
}
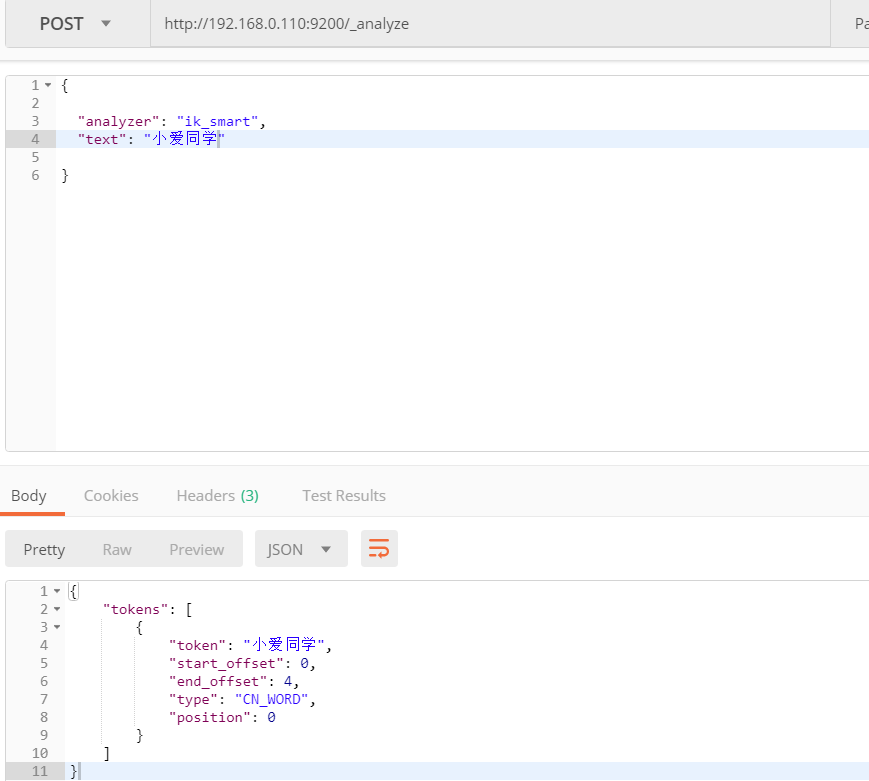
如上图所示,则表示我们配置的自定义分词器成功了。
文档映射
已经把ElasticSearch的核心概念和关系数据库做了一个对比,索引(index)相当于数据库,类型(type)相当于数据表,映射(Mapping)相当于数据表的表结构。ElasticSearch中的映射(Mapping)用来定义一个文档,可以定义所包含的字段以及字段的类型、分词器及属性等等。
文档映射就是给文档中的字段指定字段类型、分词器。
映射的分类
动态映射
我们知道,在关系数据库中,需要事先创建数据库,然后在该数据库实例下创建数据表,然后才能在该数据表中插入数据。而ElasticSearch中不需要事先定义映射(Mapping),文档写入ElasticSearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。默认映射为 long 类型。
静态映射
在ElasticSearch中也可以事先定义好映射,包含文档的各个字段及其类型等,这种方式称之为静态映射。
String 类型分为text、keyword。
text:会进行分词查询。
keywork:不会进行分词查询。
ES类型支持
基本类型
符串:string,string类型包含 text 和 keyword。
text:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,text类型不能用来排序和聚合。
keyword:该类型不需要进行分词,可以被用来检索过滤、排序和聚合,keyword类型自读那只能用本身来进行检索(不可用text分词后的模糊检索)。
注意: keyword类型不能分词,Text类型可以分词查询
数指型:long、integer、short、byte、double、float
日期型:date
布尔型:boolean
二进制型:binary
数组类型(Array datatype)
复杂类型
地理位置类型(Geo datatypes)
地理坐标类型(Geo-point datatype):geo_point 用于经纬度坐标
地理形状类型(Geo-Shape datatype):geo_shape 用于类似于多边形的复杂形状
特定类型(Specialised datatypes)
Pv4 类型(IPv4 datatype):ip 用于IPv4 地址
Completion 类型(Completion datatype):completion 提供自动补全建议
Token count 类型(Token count datatype):token_count 用于统计做子标记的字段的index数目,该值会一直增加,不会因为过滤条件而减少
mapper-murmur3 类型:通过插件,可以通过_murmur3_来计算index的哈希值
附加类型(Attachment datatype):采用mapper-attachments插件,可支持_attachments_索引,例如 Microsoft office 格式,Open Documnet 格式, ePub,HTML等
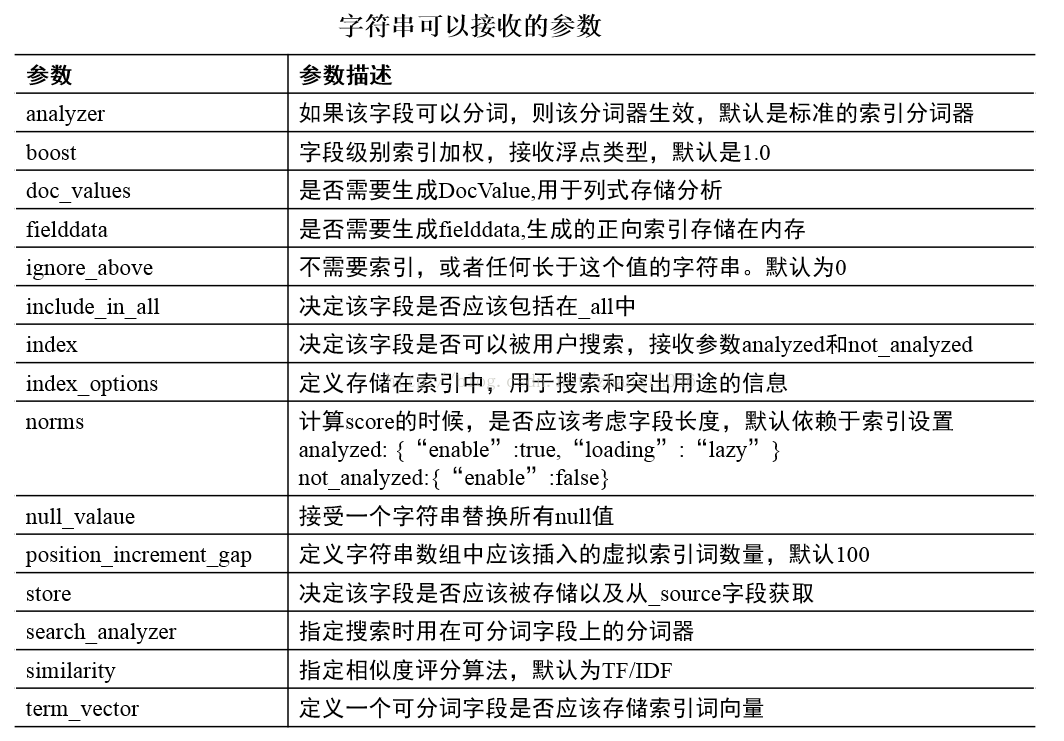
创建文档类型并且指定类型
##### 创建文档类型并且指定类型
POST /myindex/_mapping/user
{
"user":{
"properties":{
"age":{
"type":"integer"
},
"sex":{
"type":"text"
},
"name":{
"type":"text",
"analyzer":"ik_smart"
}
}
}
}
如果创建失败,需要先删除之前的索引,在重新新建即可。
未指定类型之前:
##### 查看映射类型
GET /myindex/user/_mapping
{
"myindex":{
"mappings":{
"user":{
"properties":{
"age":{
"type":"long"
},
"id":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"name":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"sex":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
}
}
}
}
}
}
指定类型之后:
##### 查看映射类型
GET /myindex/user/_mapping
{
"myindex":{
"mappings":{
"user":{
"properties":{
"age":{
"type":"integer"
},
"name":{
"type":"text",
"analyzer":"ik_smart"
},
"sex":{
"type":"text"
}
}
}
}
}
}
es 官网: https://www.elastic.co/cn/products/elasticsearch
es 使用文档:https://es.xiaoleilu.com/
es 下载地址:https://www.elastic.co/cn/downloads/elasticsearch
百度百科:https://baike.baidu.com/item/elasticsearch/3411206?fr=aladdin
什么是PB级别:https://baike.baidu.com/item/%E6%8B%8D%E5%AD%97%E8%8A%82/1453828?fromtitle=PetaByte&fromid=5910820

